目录
集合体系
Collection - List接口实现类
Collection - List接口对象的遍历
Collection - List - ArrayList
Collection - List - Vector
Collection - List - LinkedList
Collection - Set接口实现类
Collection - Set接口的遍历
Collection - Set - HashSet
HashSet - add源码解读
Collection - Set - TreeSet
Map接口实现类
Map接口对象遍历
Map接口实现类的特点
Map - HashMap
Map - Hashtable
Map - Properties extends Hashtable<Object,Object>
Map - TreeMap
Java集合框架实现类的扩容机制汇总
Java集合框架实现类的选用规则
Collections工具类
集合体系
✍Java中应用于集合体系的接口有Collection接口的和Map两种。集合体系图如下:

✍Collection接口下的集合为单列集合(单个对象组成的集合):
- 实现Collection的主要子接口有List和Set两个。
- 实现List的集合类主要有Arraylist、LinkedList、Vector
- 实现Set接口的集合类主要有HashSet、TreeSet
- 实现List的集合类主要有Arraylist、LinkedList、Vector
✍Map接口下的集合为双列集合(键值对集合):
- 实现Map接口的集合类主要有HashMap、TreeMap、Hashtable、Properties
✍集合接口以及集合类之间的关系和体系图如下:
- Collection (Interface)
- List (Interface)
- ArrayList (class)
- LinkedList (class)
- Vector (class)
- Set (Interface)
- HashSet (class)
- TreeSet (class)
- List (Interface)
- Map (Interface)
- HashMap (class)
- TreeMap (class)
- Hashtable (class)
- Properties (class)
Collection - List接口实现类
Collection - List接口对象的遍历
子接口List和Set都继承自Collection接口,因此实现上述接口的集合类对象都可以利用上象转型用Collection接口对象接收。下面是Collection接口集合对象的三种常用的遍历方法:
Iterator迭代器遍历/增强for循环遍历/普通for循环遍历(ArrayList对象为例)
import java.util.ArrayList; import java.util.Iterator; public class ArrayList_ { public static void main(String[] args) { ArrayList<Integer> arrayList = new ArrayList<Integer>(); for(int i=0;i<3;i++) { arrayList.add(i); } //Iterator迭代器遍历 Iterator<Integer> iterator = arrayList.iterator(); while (iterator.hasNext()) { Integer next = iterator.next(); System.out.println(next); } //增强for循环遍历 System.out.println("==========="); for (Integer integer: arrayList) { System.out.println(integer); } System.out.println("==========="); //普通for循环遍历 for (int i = 0; i < arrayList.size(); i++) { System.out.println(arrayList.get(i)); } } }
Collection - List - ArrayList对象
适用及特点:
- 适用单线程,ArrayList对象是线程不安全的,但效率高
- 需求需要大量改查时使用,效率高
- ArrayList对象的扩容机制
- 添加的元素是有序的,且可以添加重复的元素
Collection - List - Vector
使用及特点:
- 适用多线程,线程安全,但效率低
- 添加的元素是有序的,且可以添加重复的元素
- 扩容机制:
- 使用无参构造,初始化Vector对象维护的elementData的数组大小为10,伺候按照原来的2倍进行扩容
- 使用有参构造,初始化elementData数组的大小为参数值,此后2倍扩容。
- 可以在构造方法使用capacityIncrement参数指定每次扩容的数量
Collection - List - LinkedList
使用及特点:
- LInkedList的底层实现了双向链表和双端队列的特点
- 可以添加任意元素包括空
- 线程不安全,因此效率也高
- 在需求需要进行大量的增删时使用
Collection - Set接口实现类
Collection - Set接口的遍历
Set接口中的元素是无序的,因此不能通过get方法得到相应的元素。不能使用普通for循环进行遍历
Iterator<Person> iterator = hashSet.iterator();
//hashSet的两种遍历方式
while(iterator.hasNext()) {
Person s = iterator.next();
System.out.println(s);
}
for(Person p : hashSet) {
System.out.println(p);
}Collection - Set - HashSet
使用及特点:
- Set接口对象的元素无序,元素添加的顺序和取出的顺序不同,所以不能通过索引的方式遍历或者获得元素,但是元素取出的顺序是固定的
- Set接口的对象中的元素不允许重复,因此最多包含一个null,相同的元素相同时只能添加一个
Set - HashSet的扩容机制
使用默认无参构造器:
- 初始化的HashSet对象维护的HashMap对象中的table数组的大小为0.
- 向HashSet对象中添加元素时,table数组的大小被初始化为16
- 当table数组中的元素个数达到数组大小的乘以默认加载因子LoadFactor(默认0.75)倍后,数组进行扩容,扩容的倍数为原来的两倍
使用带有参数的构造器:
- 初始化的HashSet对象维护的HashMap对象中的table数组的大小为0.
- 向Hashset中添加元素时,table数组的大小被初始化为比指定的initCapacity大的最小的2的倍数的大小
initCapacity:1, table.length:2
initCapacity:9, table.length:16- 如果指定加载因子,则将table数组中的元素个数达到table.length * loadFactor时进行2倍扩容。
Set接口的HashSet对象源码解读:
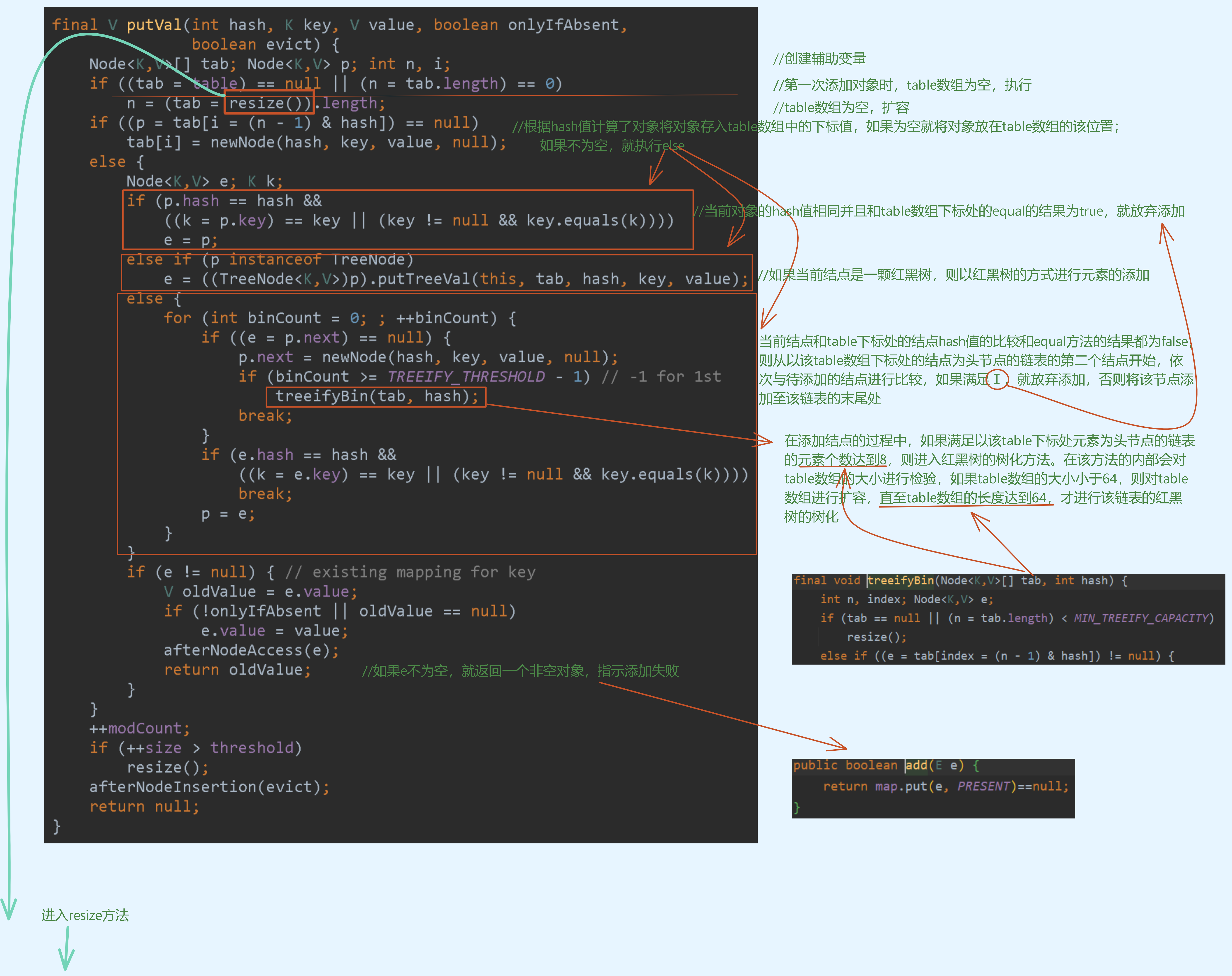
- HashSet的底层是HashMap
- 向HashSet集合中添加元素时,会通过由该元素得到的hash值转换成的索引值作为下标将数据元素存入所对应的table数组。
- 在将数据元素存入table数组时,如果此下标处为空,则将数据元素直接加入;如果有数据元素,调用equals与以该数据元素作为头节点的链表的数据元素进行比较,如果有一个数据元素与其相同则放弃添加,如果没有与其相同的元素,则将数据元素添加至该链表的末尾。
- 在Java8中,如果一条链表的个数超过 TREEIFY_THRESHOLD(默认为8),并且table数组的大小(包括横向和竖向添加的元素) >= MIN_TREEIFT_CAPACITY(默认为64),就会对table中的链表的头节点进行树化(红黑树)
面试题:
1. HashSet<String> hashSet = new HashSet<String>(); System.out.println(hashSet.add(new String("Java")));//true System.out.println(hashSet.add(new String("Java")));//false 2. HashSet<Person> personHashSet = new HashSet<>(); System.out.println(personHashSet.add(new Person("LiMing",18)));//true System.out.println(personHashSet.add(new Person("LiMing",18)));//true
- 1原因:通过new 一个相同的字符串值得到的hash值相同,从而通过处理后得到的要存入的table数组的下标也相同,又有equals在String类的内部进行了重写,在存入调用字符串的equals方法返回的结果为true,从而第二次添加失败
- 2原因:2个Person对象为不同的对象得到的hash值也不同,直接存入不同下标的table数组中。此时即使对Person类中的hashCode方法进行重写使Person的实例化对象产生相同的hash值和相同的下标,但由于没有对Person中的equal方法进行重写,两个new出来的不同的Person对象依然会被添加进table数组中,只不过下标相同,是两个相邻的结点:
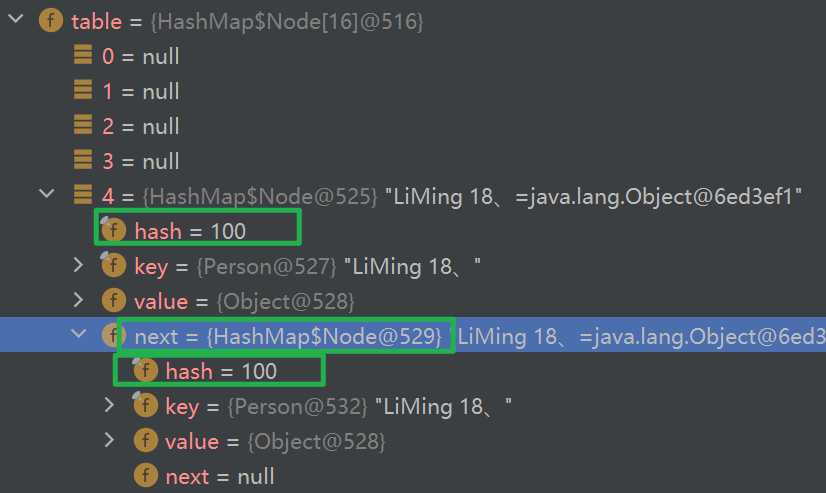
HashSet - add源码解读
//借助一个自定义Person类来追踪HashSet的源码机制 //Person类具有私有的age和name属性并且覆写了equals方法和具备name和age属性的hashCode方法 @Override class Person { private int age; private String name; public Person(int age,String name) { this.name = name; this.age = age; } //getter、setter略 // 重写equals和hashCode方法使得出现hash冲突,将对应的数据元素链式存入相同的table数组的下表中 @Override public boolean equals(Object o) { if(this == o) { return true; } if(o == null || this.getClass() != o.getClass()) { return false; } Person p = (Person) o; return this.name.equals((p.getName())) && this.age == p.getAge(); } @Override public int hashCode() { return Objects.hash(age,name); } @Override public String toString() { return "Person{" + "age=" + age + ", name='" + name + '\'' + '}'; } }


Collection - Set - TreeSet
- 对数据对象有排序需求时使用
- TreeSet的底层时TreeMap,数据存放在Entry对象中
- TreeSet中不能添加null,会抛出NulPointerException异常对象
- TreeSet提供了带有Comparator比较器的接口,传入覆写过compare方法匿名内部类对象供内部使用
例如现在需求要求将传入的字符串对象按照长度升序排列:
public class TreeSet_ { public static void main(String[] args) { TreeSet<String> treeSet = new TreeSet<>(new Comparator<String>() { @Override public int compare(String o1, String o2) { return o1.length() - o2.length(); } }); treeSet.add("huawei"); treeSet.add("alibabaAlipay"); treeSet.add("tencent"); treeSet.add("MI"); treeSet.add("alibaba"); System.out.println(treeSet); } } //输出:[MI, huawei, tencent, alibabaAlipay]但是!!!会发现"alibaba"这个字符串并没有添加进集合中,这是因为在add方法在添加对象调用compare方法的所返回的结果为0时,并没有进行传入对象的添加:

Map接口实现类
Map接口对象遍历
//取出所有的key值遍历(keySet)
Set<String> strings = hashMap.keySet();
//增强for循环
for(String s : strings) {
System.out.println(s + " " + hashMap.get(s));
}
//Iterator遍历器
System.out.println("======Iterator遍历器======");
Iterator<String> iterator = strings.iterator();
while(iterator.hasNext()) {
String key = iterator.next();
System.out.println(key + " " + hashMap.get(key));
}
//取出所有的value值遍历(values)
Collection<Person> col = hashMap.values();
//增强for和迭代器遍历
for(Person p : col) {
System.out.println(p);
}
//迭代器
Iterator<Person> personIterator = col.iterator();
while(personIterator.hasNext()) {
System.out.println(personIterator.next());
}
for(int i=0;i<col.size();i++) {
System.out.println();
}
//取出所有的关系遍历
Set<Map.Entry<String, Person>> entries = hashMap.entrySet();
for (Map.Entry<String,Person> stringPersonEntry : entries) {
System.out.println(stringPersonEntry.getKey() + stringPersonEntry.getValue());
}
Iterator<Map.Entry<String, Person>> iterator1 = entries.iterator();
while(iterator1.hasNext()) {
System.out.println(iterator1.next());
}Map接口实现类的特点
- Map与Collection并列存在,用于保存具有映射关系的数据(Key - Value)
- Map中的Key和Value在不指定时可以是任何的引用数据类型,会被封装到HashMap$Node对象中
- Map中的Key不能重复,原因和HashSet相同,但是Value可以重复
- Map中的Key和Value都可以为空
- 常用String类作为Map的Key值
- Key 和 Value之间存在一 一对应关系,通过指定的key总能找到对应的Value,但是因为底层是hash表实现的,因此不保证映射的顺序
- 当key相同value不同时,第二个value值会覆盖第一个value值
- HashMap没有实现同步,因此是线程不安全的(无synchronized)
Map - HashMap
HashMap的扩容机制其实就是HashSet的扩容机制,见Collection - Set - HashSet。
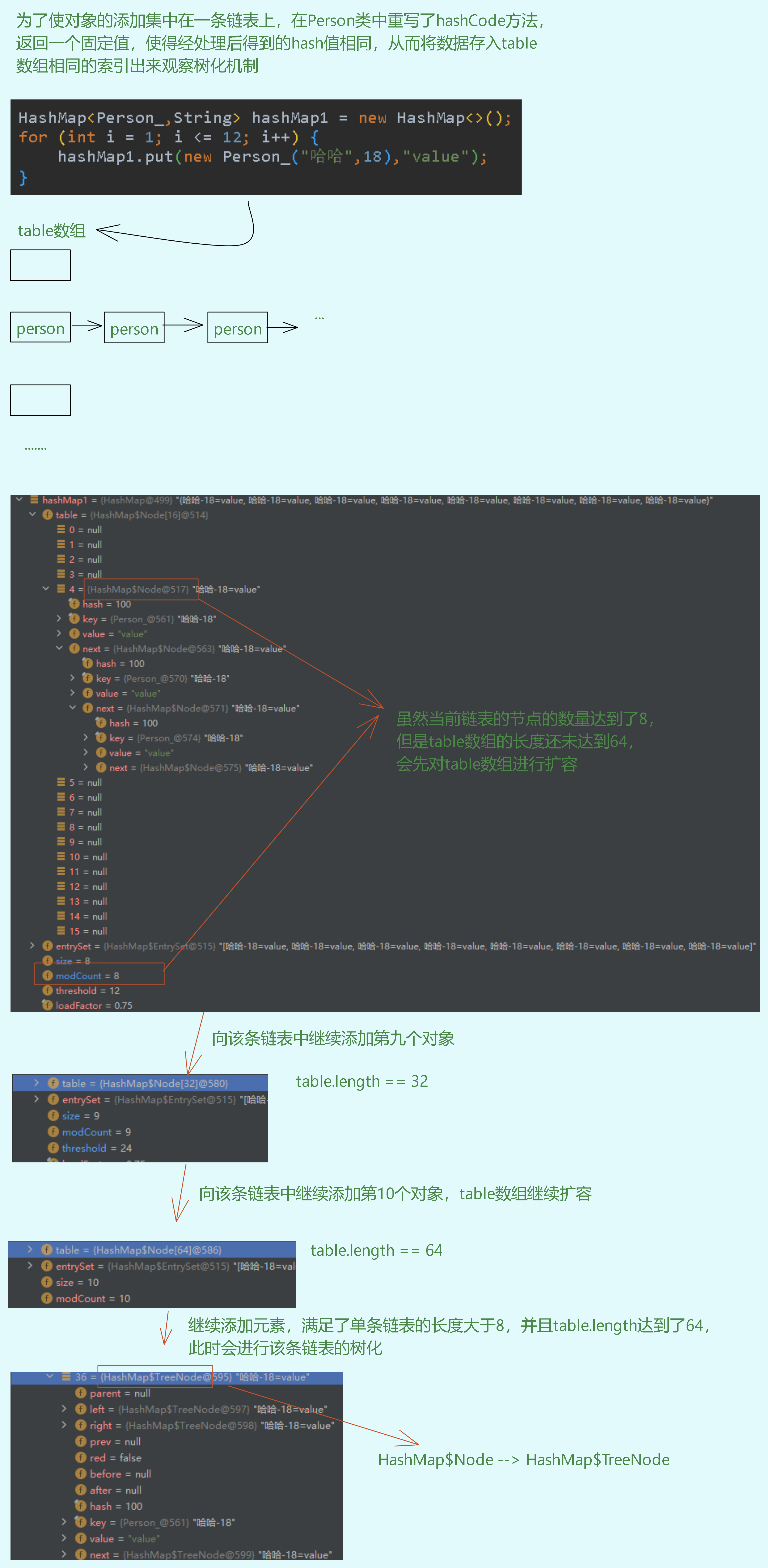
HashMap在进行底层哈希表table数组中以某个节点为头结点的节点的红黑树树化时,需要满足:
- 单条链表的长度超过8
- table数组的长度达到64
Map - Hashtable
- Hashtable中的键以及值不允许出现null,会抛出NullPointerException异常
- Hashtable是线程安全的,也因此效率较低
- 当键相同,值不同时会发生值得替换
- 扩容机制:
Hashtable的底层维护了一个Hashtable$Entry类型的table数组,初始化table数组的大小为11,临界值为floor(11*0.75) = 8,当table数组的容量达到临界值时,进行原大小2倍+1的容量扩充。
Map - Properties extends Hashtable<Object,Object>
Properties常用于从.properties文件中加载数据到properties类对象进行数据的读取和修改,工作后properties文件通常作为配置文件,常用于IO流编程
Map - TreeMap
- TreeMap的原理和TreeSet一致
- 在向TreeMap中添加键值时,应结合排序时比较原理注意添加的规则。
例如添加的Key值俄日String对象,比较方法为字符串长度,这样进行添加时当Key值相同时,只会发生value值得替换而不会将新的Key值加入
Java集合框架实现类的扩容机制汇总
- ArrayList
构造器初始化的elementData数组的大小为0。使用无参构造初始化的ArrayList对象中维护的elementData数组在第一次添加对象时的大小被初始化为10;使用有参构造初始化的ArrayList对象在第一次添加对象时elementData数组的大小初始化为指定值,此后按照原数组的1.5倍大小进行扩容 - Vector
默认无参构造器初始化的elementData数组的大小为10,也可以使用带有参数的构造器指定大小,此后进行2倍扩容。也可以使用capacityIncrement参数指定每次扩容的基数 - HashSet/HashMap
使用无参构造初始化的table数组的大小为0.在第一次添加数组时table数组的大小倍初始化为16.默认的加载因子为0.75.当容量达到size*loadFactor时进行2倍扩容。也可以在使用构造器时指定table数组的默认大小和加载因子 - Hashtable
初始化Hashtable对象中的table数组的大小为11,加载因子为0.75,当数组中的容量达到size*loadFactor时进行二倍+1的扩容
Java集合框架实现类的选用规则

Collections工具类
- Collections.reverse(List<?> list)
将List接口对象中的数据逆序存放- Collections.shuffle(List<?> list)
随机打乱list集合中的元素的顺序- Collections.sort(List<?> list,Comparator<? super Object>)
将List集合中的数据元素按照比较器的原则进行排序- Collections.swap(List<?> list,int i,int j)
将list集合索引i和j上的数据元素互换位置- Collections.max/min(Collection<? extends T> coll)
取出自然顺序中的最大/最小元素,也可以指定比较器:
Comparator<? super T> comp- Collections.copy(List<? super T> dest,List<? extends T> src)
将src集合中的数据拷贝到dest集合中
在拷贝时应当给dest集合 >= src集合的中的数据元素的空间,否则会抛出IndexOutOfBoundsException异常对象- Collections.replaceAll(List<Object> list,Object oldVal,Object newVal)
将list集合中值为oldVal的元素替换为newVal