上期文章我们分享了JAX的概念,Jax 是来自 Google 的一个相对较新的机器学习库。它更像是一个 autograd 库,可以区分每个本机 python 和 NumPy 代码。
“Python+NumPy 程序的可组合转换:微分、向量化、JIT 到 GPU/TPU 等等”。该库利用 grad 函数转换将函数转换为返回原始函数梯度的函数。Jax 还提供了一个函数转换 JIT,用于对现有函数进行即时编译,并分别提供了用于矢量化和并行化的 vmap 和 pmap

JAX 是Autograd和XLA的结合,JAX 本身不是一个深度学习的框架,他是一个高性能的数值计算库,更是结合了可组合的函数转换库,用于高性能机器学习研究。深度学习只是其中的一部分而已,但是你完全可以把自己的深度学习移植到JAX 上面。
自2018 年底谷歌的 JAX出现以来,它的受欢迎程度一直在稳步增长。DeepMind 202年宣布使用 JAX 来加速自己的相关研究,越来越多来自Google 大脑与其他项目也在使用 JAX。随着JAX越来越火,似乎 JAX 是下一个大型深度学习框架?虽然JAX并不是一个神经网络框架,但是随着JAX的发展,很多深度学习相关的研究也可以使用JAX来实现,本来tensorflow与pytorch 2个主流框架已经争的热火朝天,现在Google又加了一把火,让JAX进军深度学习。

上期文章我们也分享了JAX 与numpy 的速度对比,相比没有JAX加速的numpy,其速度远远落后于JAX,本期我们就使用JAX训练第一个机器学习模型。

使用JAX训练第一个机器学习模型
在使用JAX之前,我们需要安装JAX,好在JAX可以使用pip进行安装,但是JAX目前无法在Windows平台使用,小伙伴们可以使用Linux虚拟机进行体验。
pip install jaxpip install autogradpip install numpypip install jaxlib
首先我们需要安装上JAX等相关的第三方库,并import相关的第三方库。
import numpy as npimport jax.random as randomimport jaxfrom jax import numpy as jnpfrom jax import make_jaxprfrom jax import grad, jit, vmap, pmapimport matplotlib.pyplot as plt
然后我们建立一个y=ax+b的一个线性函数,其中参数a是直线的一个斜率,b是直线在Y轴方向的移动参数,并使用random随机函数生成一个随机的X数据,这样我们就得到了一个完成的y=ax+b线性函数,我们可以使用matplotlib来显示此函数的曲线。
key = random.PRNGKey(56)x = random.normal(key, shape=(128, 1))a = 3.0b = 5.0ys = (a*xs) + bplt.scatter(xs, ys)plt.xlabel("xs")plt.ylabel("ys")plt.title("Linear F(x)")plt.show()
运行以上代码后,我们就得到了一个y=ax+b的线性函数。
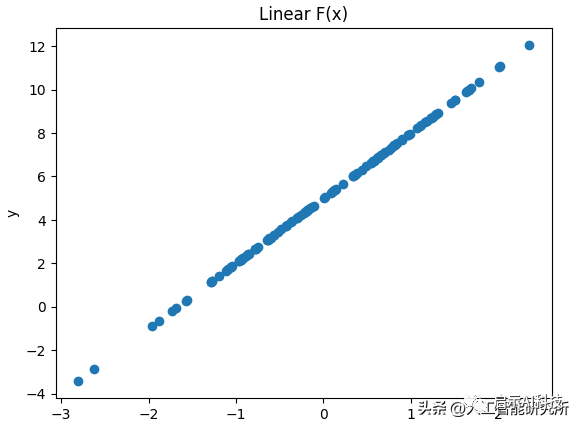
有了以上的线性函数,我们就搭建一个线性模型,使用机器学习的方式,来预测此条直线。
def linear(theta, x):weight, bias = thetapred = x * weight + biasreturn pred
然后我们再定义一个线性函数,此函数也是同样有2个参数,一个weight(权重),一个bias(偏差),训练的目的是找到一个合适的weight与bias参数,以便来预测上面的线性函数。当然,我们还需要建立一个loss函数,以便后期进行训练时,让loss逐渐减小。这里使用均方差作为损失函数来计算预测值与真实值的损失。
def p_loss(theta, x, y):pred = linear(theta, x)loss = jnp.mean((y - pred)**2)return loss@jitdef update_step(theta, x, y, lr):loss, gradient = jax.value_and_grad(p_loss)(theta, x, y)updated_theta = theta - lr * gradientreturn updated_theta, loss
然后使用jax.value_and_grad函数来更新loss,lr参数是神经网络的学习效率,这里我们可以随机一个比较小的值即可。有了以上的函数,我们就可以进行一个机器学习的模型训练了。
weight = 0.0bias = 0.0theta = jnp.array([weight, bias])epochs = 20000for item in range(epochs):theta, loss_p = update_step(theta, xs, ys, 1e-4)if item % 1000 == 0 and item != 0:print(f"item {item} | loss {loss_p:.4f}")
我们初始化weight与bias参数,使用for循环来训练神经网络,使loss越来越来越小,这里我们每隔1000步来打印一下loss参数。
item 1000 | loss 23.4526item 2000 | loss 15.4000item 3000 | loss 10.1152item 4000 | loss 6.6459item 5000 | loss 4.3678item 6000 | loss 2.8714item 7000 | loss 1.8883item 8000 | loss 1.2422item 9000 | loss 0.8174item 10000 | loss 0.5380item 11000 | loss 0.3543item 12000 | loss 0.2333item 13000 | loss 0.1538item 14000 | loss 0.1013item 15000 | loss 0.0668item 16000 | loss 0.0441item 17000 | loss 0.0291item 18000 | loss 0.0192item 19000 | loss 0.0127
从以上loss参数,我们可以看到,其模型的loss逐渐缩小,说明我们的设计的线性机器学习模型是有效的。我们也可以打印一下训练20000步后的模型输出函数。
plt.scatter(xs, ys, label="true")plt.scatter(xs, linear(theta, xs), label="pred")plt.legend()plt.show()
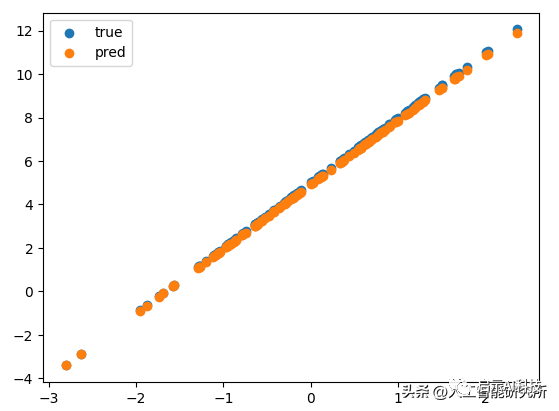
可以看到,其模型随着训练,其loss逐渐减小,当训练20000步后,其预测的y=ax+b函数与输入的初始函数值几乎重合,当然你也可以增加训练步骤,让loss再次缩小。
JAX虽然目前不被称之为一个神经网络的模型框架,但是随着pytorch,paddlepaddle以及mindSpore相关框架的加入,加剧神经网络框架之争,说不定Google会把JAX发展成下一代神经网络框架也不一定。
ChatGPT的大火,
带动了人工智能学习的热潮,
小编建立了一个AI学习圈,
分享相关人工智能技术,
大家一起学习。
https://wx2.expostar.cn/qz/pages/manor/index?id=1137&share_from_id=79482&sid=24
更多transformer模型
VIT模型
swin transformer模型
参考头条号:人工智能研究所