使用 Python 创建端到端聊天机器人
- 1. 效果图
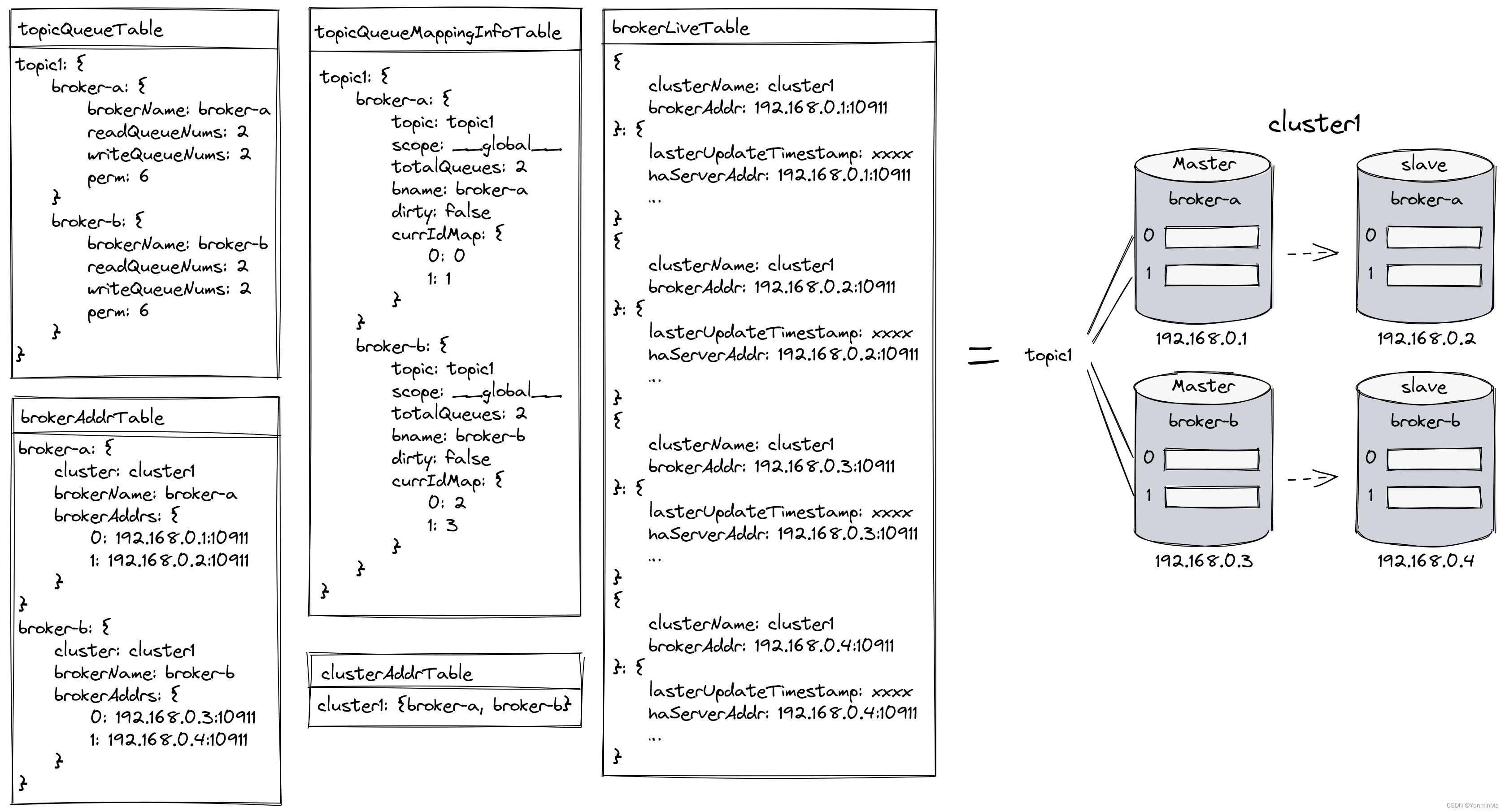
- 2. 原理
- 2.1 什么是端到端聊天机器人?
- 2.2 创建端到端聊天机器人步骤
- 3. 源码
- 3.1 streamlit安装
- 3.2 源码
- 参考
聊天机器人是一种计算机程序,它了解您的查询意图以使用解决方案进行回答。聊天机器人是业内最受欢迎的自然语言处理应用。因此,如果您想构建端到端聊天机器人,本文适合您。在本文中,我将带您了解如何使用 Python 创建端到端聊天机器人。
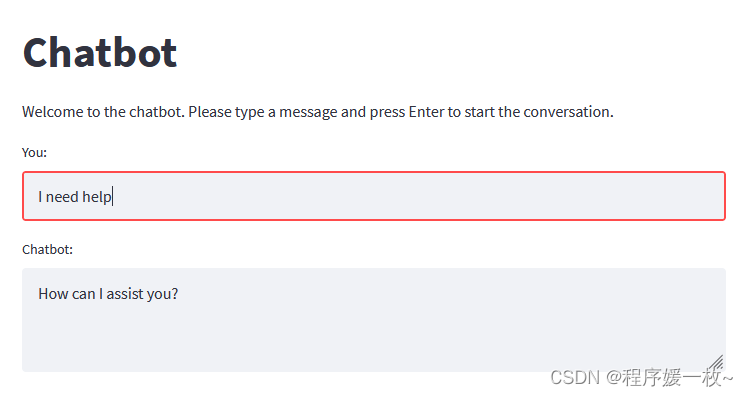
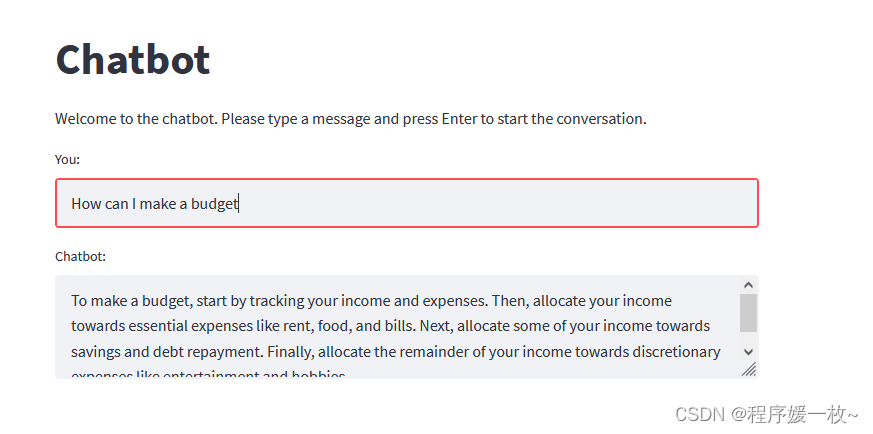
1. 效果图
训练的意图及回复越多,机器人将越灵活准确。
用例少不准确或者基本是提供的内容的回答。
2. 原理
2.1 什么是端到端聊天机器人?
端到端聊天机器人是指可以在不需要人工帮助的情况下从头到尾处理完整对话的聊天机器人。
要创建端到端聊天机器人,需要编写一个计算机程序,该程序可以理解用户请求,生成适当的响应,并在必要时采取行动。这包括收集数据,选择编程语言和NLP工具,训练聊天机器人,以及在将其提供给用户之前对其进行测试和完善。 部署后,用户可以通过向聊天机器人发送多个请求来与聊天机器人进行交互,聊天机器人可以自行处理整个对话。
2.2 创建端到端聊天机器人步骤
- 定义意向
- 创建训练数据
- 训练聊天机器人
- 构建聊天机器人
- 测试聊天机器人
- 部署聊天机器人
3. 源码
3.1 streamlit安装
python3.7.6+ streamlit 0.68.0,1.20.0,1.21.0 都不行,只有1.9版本ok
pip install streamlit==1.9
3.2 源码
# 端到端聊天机器人
# streamlit run ete_chatbot.py
import os
import nltk
import ssl
import streamlit as st
import random
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
ssl._create_default_https_context = ssl._create_unverified_context
nltk.data.path.append(os.path.abspath("nltk_data"))
nltk.download('punkt')
# 定义聊天机器人的一些意图。可以添加更多意图,使聊天机器人更有用且功能更强大
intents = [
{
"tag": "greeting",
"patterns": ["Hi", "Hello", "Hey", "How are you", "What's up"],
"responses": ["Hi there", "Hello", "Hey", "I'm fine, thank you", "Nothing much"]
},
{
"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "Take care"],
"responses": ["Goodbye", "See you later", "Take care"]
},
{
"tag": "thanks",
"patterns": ["Thank you", "Thanks", "Thanks a lot", "I appreciate it"],
"responses": ["You're welcome", "No problem", "Glad I could help"]
},
{
"tag": "about",
"patterns": ["What can you do", "Who are you", "What are you", "What is your purpose"],
"responses": ["I am a chatbot", "My purpose is to assist you", "I can answer questions and provide assistance"]
},
{
"tag": "help",
"patterns": ["Help", "I need help", "Can you help me", "What should I do"],
"responses": ["Sure, what do you need help with?", "I'm here to help. What's the problem?", "How can I assist you?"]
},
{
"tag": "age",
"patterns": ["How old are you", "What's your age"],
"responses": ["I don't have an age. I'm a chatbot.", "I was just born in the digital world.", "Age is just a number for me."]
},
{
"tag": "weather",
"patterns": ["What's the weather like", "How's the weather today"],
"responses": ["I'm sorry, I cannot provide real-time weather information.", "You can check the weather on a weather app or website."]
},
{
"tag": "budget",
"patterns": ["How can I make a budget", "What's a good budgeting strategy", "How do I create a budget"],
"responses": ["To make a budget, start by tracking your income and expenses. Then, allocate your income towards essential expenses like rent, food, and bills. Next, allocate some of your income towards savings and debt repayment. Finally, allocate the remainder of your income towards discretionary expenses like entertainment and hobbies.", "A good budgeting strategy is to use the 50/30/20 rule. This means allocating 50% of your income towards essential expenses, 30% towards discretionary expenses, and 20% towards savings and debt repayment.", "To create a budget, start by setting financial goals for yourself. Then, track your income and expenses for a few months to get a sense of where your money is going. Next, create a budget by allocating your income towards essential expenses, savings and debt repayment, and discretionary expenses."]
},
{
"tag": "credit_score",
"patterns": ["What is a credit score", "How do I check my credit score", "How can I improve my credit score"],
"responses": ["A credit score is a number that represents your creditworthiness. It is based on your credit history and is used by lenders to determine whether or not to lend you money. The higher your credit score, the more likely you are to be approved for credit.", "You can check your credit score for free on several websites such as Credit Karma and Credit Sesame."]
}
]
# Create the vectorizer and classifier 创建矢量化器和分类器
vectorizer = TfidfVectorizer()
clf = LogisticRegression(random_state=0, max_iter=10000)
# 准备意图数据并训练模型
tags = []
patterns = []
for intent in intents:
for pattern in intent['patterns']:
tags.append(intent['tag'])
patterns.append(pattern)
# 训练模型
x = vectorizer.fit_transform(patterns)
y = tags
clf.fit(x, y)
def chatbot(input_text):
input_text = vectorizer.transform([input_text])
tag = clf.predict(input_text)[0]
for intent in intents:
if intent['tag'] == tag:
response = random.choice(intent['responses'])
return response
# 为了部署聊天机器人,将使用 Python 中的 streamlit 库,它提供了惊人的功能,只需几行代码即可为机器学习应用程序创建用户界面
counter = 0
def main():
global counter
st.title("Chatbot")
st.write("Welcome to the chatbot. Please type a message and press Enter to start the conversation.")
counter += 1
user_input = st.text_input("You:", key=f"user_input_{counter}")
if user_input:
response = chatbot(user_input)
st.text_area("Chatbot:", value=response, height=100, max_chars=None, key=f"chatbot_response_{counter}")
if response.lower() in ['goodbye', 'bye']:
st.write("Thank you for chatting with me. Have a great day!")
st.stop()
if __name__ == '__main__':
main()
参考
- https://thecleverprogrammer.com/2023/03/27/end-to-end-chatbot-using-python/