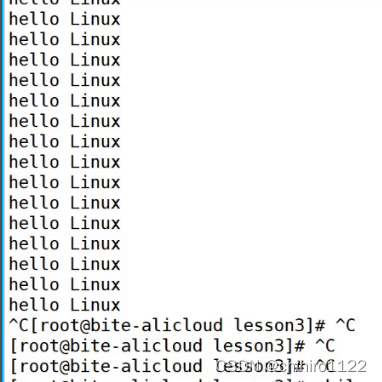
如果我们以后再Linux当中 写了一些命名,导致程序我们不能进行操作了,如这个死循环:
![]()
他就会一直输出 "hello Linux" ,我们就使用 ctrl + c 来终止因为程序或者指令异常,而导致我们无法进行指令输入:
* 通配符
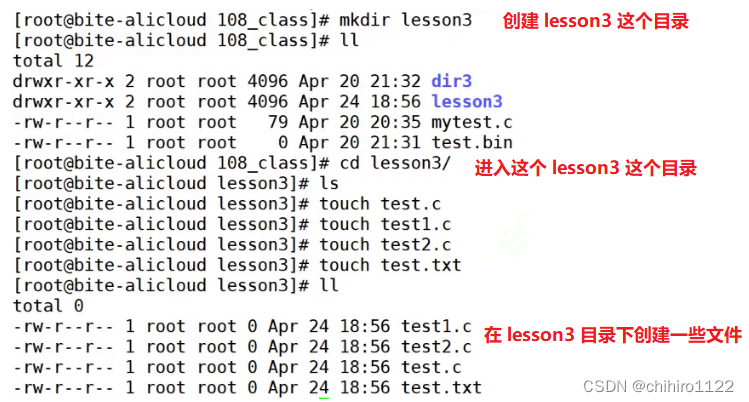
它的意思是所有,比如我们使用 ls 来访问当前路径下(除隐藏文件下)的所有文件:
他可以访问,当前路径下的所有文件。
例如:
我们使用 " * " 可以匹配任意 名称的文件:
*. xxx
访问以 xxx 为后缀的文件,例如:
![]()
上图中,就是访问 此路径下的所有以 .c 为后缀的文件。
xxx . *
访问所有 以xxx 为文件名的文件,例如:
![]()
上图中,就是访问 此路径下的 所有 文件名为 test 的文件。
rm * -rf
这样就可以删除本路径下的所有文件和文件夹:
![]()
此时 ls 无内容。
如上述的 rm -rf xxx.xxx 这个命名还可以 这样写 : rm xxx.xxx -rf 这样写,但是我们一般建议是按照第一种方式去书写,因为第二种方式的命令有些环境可能不兼容,如上述的rm xxx.xxx -rf 这个命令,在 macOS 当中 也有终端 这个终端也是 Linux 指令 ,可能就不兼容。
man指令
Linux的命令有很多的参数,我们可能会记不住,而 man指令可以帮我们查看联机手册获取帮助。
语法:
man [选项] [命名]比如现在我们来查看 rm 指令的联机手册:
man rm
man man 查看这个手册的使用方法:
手册:
- 1 是普通的命令
- 2 是系统调用,如open,write之类的(通过这个,至少可以很方便的查到调用这个函数,需要加什么文件)
- 3 是库函数,如printf,fread4是特殊文件,也就是/dev下的各种设备文件
- 5 是指文件的格式,比如passwd, 就会说明这个文件中各个字段的含义
- 6 是给游戏留的,由各个游戏自己定义
- 7 是附件还有一些变量,比如向environ这种全局变量在这里就有说明
- 8 是系统管理用的命令,这些命令只能由root使用,如ifconfig
我们发现当中有这 9 个接口,分别对应这不同的手册。
当我们 man pirntf 想去查看C语言的当中的 printf() 函数的时候,发现printf()不仅仅作为C语言当中的函数,还作为 Linux 当中的一条指令:

Linux当中的printf和C当中的printf()没有任何的关系,一个是指令,一个是函数。
使用 man 3 printf 就可以查这个printf的相关函数:

那么如果我们在使用man 指令再查的时候,后面都没有带 1 这样的手册,直接进行查指令的话,那么他会从 1 号手册开始查找,找到了就直接返回这个 手册当中的指令,如果没有找到,会按照 1 2 3 ······ 等等这样的顺序在 手册中进行查找。
如果上述都没有找到,那么就会说,没有这个指令:
![]()
当然,man 也是有 一些选项的,不过我们一般查的话,就是上述的几种方式来就差不多了。
man 的选项:
- -k 根据关键字搜索联机帮助
- num 只在第num章节找
- -a 将所有章节的都显示出来,比如 man printf 它缺省从第一章开始搜索,知道就停止,用a选项当按下q退出,他会继续往后面搜索,直到所有章节都搜索完毕
cp指令
作用是赋值 文件或者是目录。
语法:
cp [选项] 源文件或目录 目标文件或目录拷贝文件:
如这个例子:
上述两个文件的大小都是 24 ,大小是一样的。
上述我们拷贝到的新的文件中,这个文件可是原本就有的,也可以没有的,如果没有就会直接创建。
如果是已经存在的文件,加上 -i 选项就会问我们是否进行覆盖:
![]()
选择 y 就是代表覆盖。
如果我们没有使用 -i 选项,那么就会默认进行覆盖:
如上述例子,第二次拷贝的时候,没有提醒,但是这是在 普通用户下的,如果是root 用户他会默认来问我们是否覆盖。
同样的,如果拷贝的文件和被拷贝的文件是一样的,是不行的,这样是没有意义的;
![]()
那么上述是拷贝到当前目录下,如果我们想要拷贝到其他路径之下,我们可以这样操作:
目标文件不仅仅可以使用文件名,还可以使用绝对路径: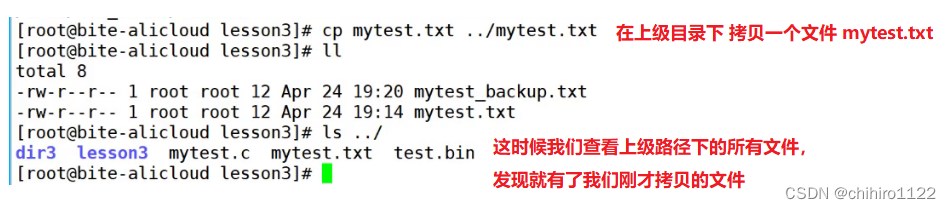
拷贝目录:

如上述的目录,我们也可以用 cp 来进行拷贝,但是不能像之前一样直接进行拷贝:
![]()
如何我们需要拷贝目录,需要 -r 选项:
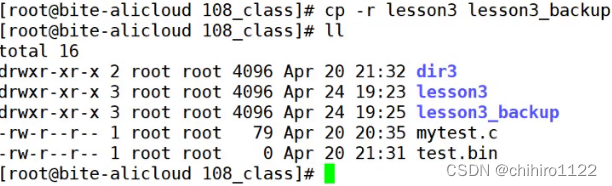
因为目录使用递归定义的,我们在拷贝的时候就需要使用递归的形式来进行拷贝。如上述,我们拷贝了一个 lesson3_backup。
我们使用 tree 来打印这个目录:
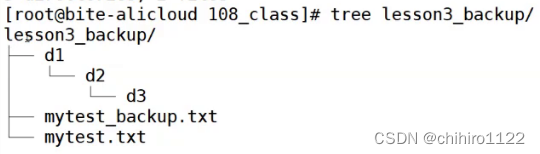
发现和 lesson3 目录是一样的。
总结
- f 或 --force 强行复制文件或目录, 不论目的文件或目录是否已经存在
- -i 或 --interactive 覆盖文件之前先询问用户
- -r递归处理,将指定目录下的文件与子目录一并处理。若源文件或目录的形态,不属于目录或符链
- 接,则一律视为普通文件处理
- -R 或 --recursive递归处理,将指定目录下的文件及子目录一并处理
echo指令
直接使用 echo 字符串 的话就会在屏幕上直接输出 这个字符串:
如果我们使用 echo 字符串 > 文件名.后缀 这样写的话,就会把这个字符串 流入 到这个文件当中:
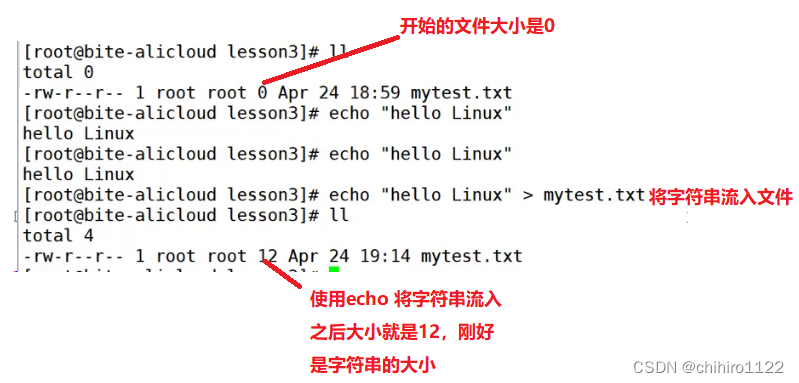
信息写入到文件中之后,就不会再屏幕上打印了。
而上述的 " > " 这个叫做 输出重定向,他会将本来应该显示在屏幕上的内容,打印到文件当中。
mv指令
用来移动文件或者将文件改名,经常用来备份文件或者目录。
语法:
mv [选项] 源文件或目录 目标文件或目录同路径下使用就是重命名,而我们可用mv指令实现剪切。
重命名:
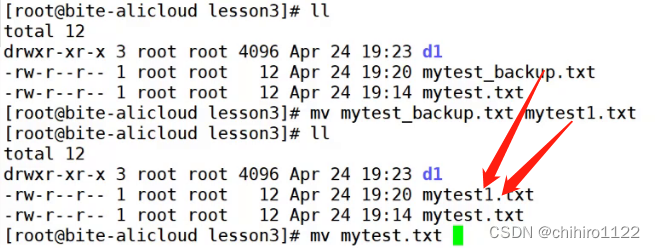
在同一路径下,这个文件名就被修改了。
我们也可以把这个文件剪切到其他路径下:
剪切并重命名:
![]()
我们可以这里理解这个 mv ,其实mv 所以的操作都是 剪切并重命名,如果我们有新的名字,就用新的名字,如果没有,就使用原本的名字,如果有新的路径,就使用新的路径,如果没有新的路径,就是默认是当前的这个路径。
当第二个参数是已存在的目录名称时,源文件或目录参数可以有多个,mv命令将各参数指定的源文件均移至目标目录中:
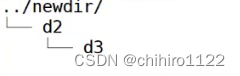
![]()
这个命令不是把 dir 这个目录 剪切覆盖 newdir 这个文件夹,当我们把查看这个上级目录发现,只是把dir 剪切到上级目录当中:
Linux 当中指令是什么
如果我们写一个 C 语言的 .c 源文件,那么我们进行 gcc 编译,然后生成可执行文件,假设是 a.out ,那么我们是 ./a.out 这样来执行的可执行文件的,而回想我们上述执行执行的时候,也是直接 输入指令,回车然后这个指令就执行了。
其实指令和可执行程序都是可以被执行的,其实指令就是可执行程序。
那么在Linux当中中的指令在哪儿呢?
当我们输入一条 Linux 当中没有的指令的时候,他会报 command not found 这样的错,也就是说,如果我们想要执行一条指令,那么先要找到这条指令。找到了就执行。
所以指令一定是在系统当中的某一个位置存在的,一般的指令是在 根目录下的 usr 的 bin 目录下的:
/usr/bin/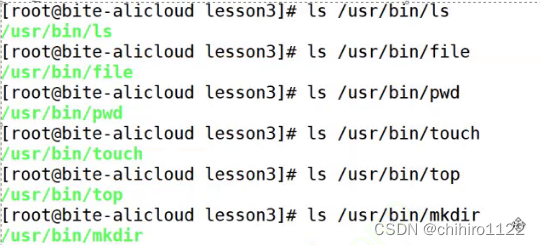
指令是在系统的特定路径下存在的,这些指令一定是某种 shell 脚本,c,c++,python等等实现的可执行程序。
那么我们之前写的 a.out 这也是一个执行程序啊,如果我们把这个 a.out 可执行程序放进这个/usr/bin/ ,bin 目录下,那么我们是不是也可以写一个指令了呢?
答案是可以的。
如下图所示:
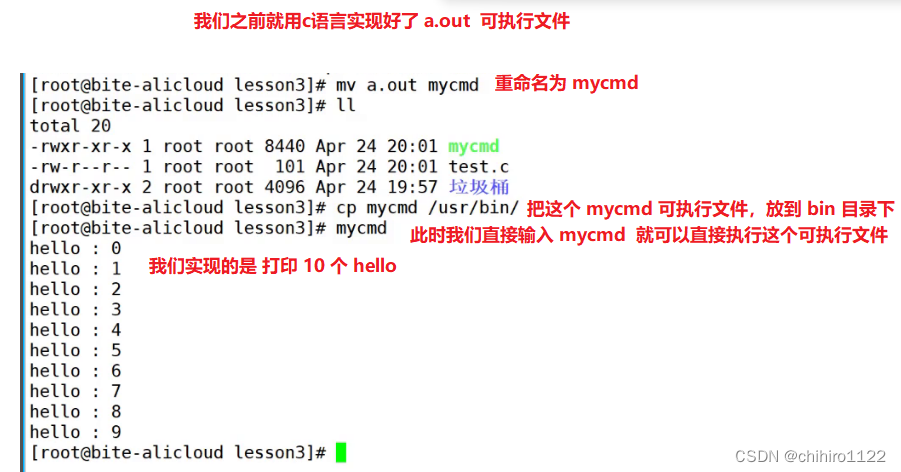
这种行为,就叫做安装软件。也就是把我们写好的 可执行程序,放到 bin 目录下,这样我们在调用这个 可执行文件的时候,就可以不用 用路径来访问这个可执行文件了。
那么对应的 ,如果我们使用 rm 来删除我们刚刚写入的 mycmd 这个可执行文件,在Linux 当中就叫做 卸载。如下图所示:
![]()
此时编译器就不能使用这个指令了:

alias 指令
给指令取别名,如下面这个例子:![]()
把 ' ls -l -i -a -n ' 这个指令 取了一个 108_cmd 这个别名,那么以后我们在使用 ' ls -l -i -a -n ' 这个指令的时候,就可以直接 使用 108_cmd 这个别名来调用,两个实现的效果是一样的l:
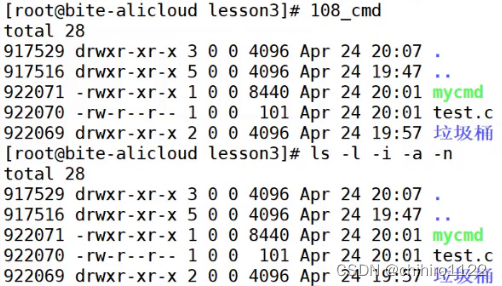
如果我们没有取别名,那么我们使用 108_cmd 这个是会报错的。
我们使用 which 来查看这个一个指令的 所在路径和 属性:

发现上述就有 alias 这个定义了。
如果有一天,我们不想用这个 别名了,那么我们就可以再用一次 alias 把这个108_cmd 置空:
然后,当我们调用 108_cmd 这个时候,就什么都没有了,而且我们使用which 查看这个 属性的时候,发现是空的,如上图所示。
那么如果我们写了 alias xxx = " "; 这样的命名,那么如果之前这个别名是有用的,当我们这个Linux 操作系统的之后(上述是在 xshell 上登录的云服务器,就重启 xshell ),那么我们再次调用这个别名,发现就会报错了:

cat指令
在Linux当中,一切都可以认为是文件
比如显示器,键盘,普通文件····这些都可以看做是 文件。
在显示器当中,可以认为有 一个 向显示器文件当中书写函数 ->fwrite(),但是显示器当中有读这个函数->fread(),但是这个读函数当中的实现是空的,因为显示只负责向我们显示数据。那么我们在使用 scanf()这样的函数在输入的数据的时候,在屏幕上我们也是能看到我们输入的数据啊,那么显示器不是接收这个数据,也就是在读这个数据吗?
其实不是的,因为我们输入的数据是从键盘输入的,而显示器只是把我们输入的数据再显示器上在显示出来,让我们知道我们输入的数据是多少。
而键盘当中就有读这个函数->fread(),相当于是从键盘设备中读取数据,但是他只负责输入,不负责输出,那么键盘当中我们可以认为有写这个函数-> ->fwrite(),但是这个函数中的实现是空的。
那么在普通文件当中,既可以写入,也可以读出,那么它fwrite()fread()这样两个函数都是有实现的。
那么在Linux 当中,只要是能被读,或者是被写的,都可以看做是文件,都可以有读写访问,称为IO。
那么在电脑上还有很多的设备,比如网卡,等等这些都可以看做是文件,网卡也是需要抒发数据的。
比如我们写入下面这个C代码:
int main()
{
int a = 10;
printf("请输入数字\n");
sacnf("%d",&a);
printf("%d",a);
}我们在键盘上输入数据,和在显示器上输出,都是文件在输出会让输入。
那么之前写的 echo 字符串,是把字符串输出到显示器文件当中;echo 字符串 > xxx.txt 就是把原本需要输出到显示器当中的字符串输入到 xxx.txt 这个文件当中。
那么上述的行为,就被认为是重定向。上述就是把原本要输入到显示器当中的字符串输出到文件当中。
当我们直接写 cat ,如下所示,我们发现,我们输入什么,屏幕上就会打印什么:

如果我们cat 后面什么都不写,他会默认从键盘读取数据,然后默认在显示器上进行打印(输出)
-n 选项
把输出结果的每一行搞一个编号:
-b 选项
给非空的行创建编号:
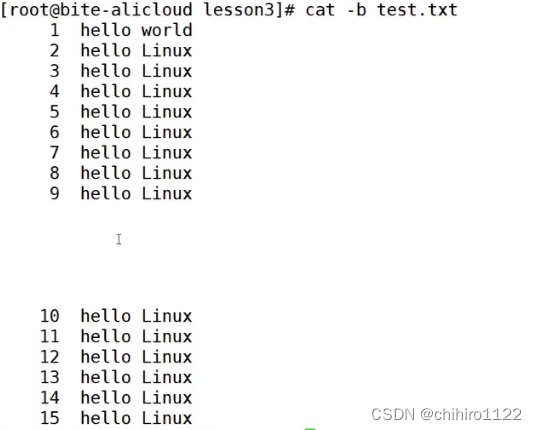
发现非空行就有编号,而空行就没有编号。
-s 选项
不输出多行的空行:
如上述例子:

发现上述的多个空行,输出了一行空行。
cat不适合看大文本,适合看小文本:
写一个简单脚本,生成 1- 10000 个 "hello Linux i" 到text.txt 文件当中:
cnt=1; while [$cnt - le 10000]; do echo "hello Linux $cnt"; let cnt++; done > text.txt如上述的大文本,看起来很不方便。
echo 和 cat 的区别
echo 后面跟的是一个字符串,而cat 后面跟的是一个文件,看下面这个例子就知道区别在哪了:
cat out.txt
#输出
hello Linuxecho out.txt
#输出
out.txt我们发现 cat 输出的是文件当中内容,而echo 输出的是 out.txt 这个字符串。
> 和 >>
> : 输出重定向
当我们使用 多次 echo 向同一个文件当中,输入相同的字符串,然后使用cat 来 输出文件当中内容,我们发现,只输出了一个字符串:
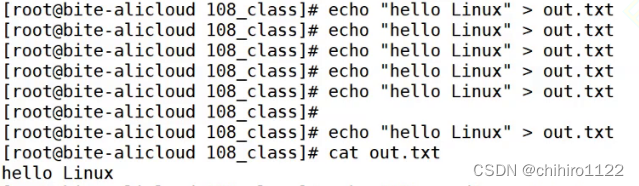
而且,在上述之后,我们在 用 echo输入 别的字符串,发现之前写的 hello Linux 这个字符串都不在了,打印的是新输入的字符串:

这是因为,这里的 " > " 输出重定向,这个操作符,在使用的时候,都是像 文件当中的开头位置,开始覆盖式的写入的,也就是说,我们上述的行为,每一次都是在原文件内容的基础之上,在开头位置进行覆盖式的写入,把原本的数据给覆盖掉。
而且上述的覆盖式分为两步:
- 首先要把文件当中内容给清空
- 然后再把内容输入到文件中
所以,我们可以使用这个 ">" 清空的特性来把文件当中的内容给清空:
>out.txt 
如果我们不想删除文件当中本来的内容,直接在之后输入,那么我们可使用 " >> " 追加重定向
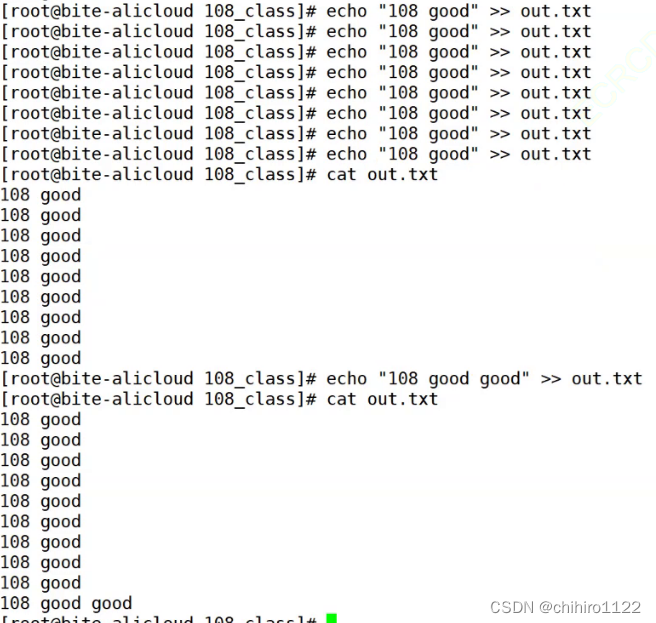
如上图,我们插入了多个 108 good 。
" >> " 追加重定向这个操作都是在文件的结尾来进行写入。
如果我们以后想创建一个新的文件,不需要使用 touch 类似的命令,直接像下述一样写也可以创建文件: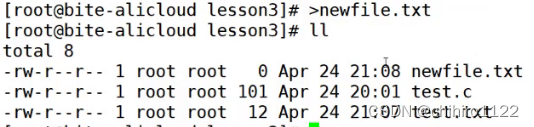
<
我们之前说过了,如果cat 后面什么都不跟,那么他会默认从键盘上读取数据,那么如果我们在后面输入 " < xxx.txt" 这个,就会从 xxx.txt 这个指定的文件当中读取数据。
> : 输入重定向

more 指令
more和cat的功能差不多,但是:
我们之前说过,cat 指令不适合来看大文本,那么查看大文本,我们就可以使用 more指令来看:![]()
这样我们就可以查看 这个文档了:
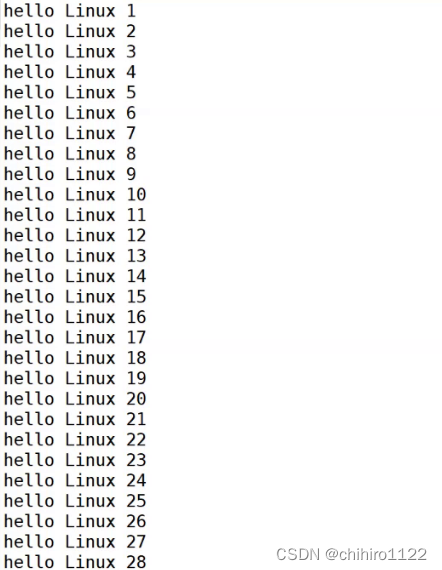
他会把文件当中的内容,在屏幕上打印出来,把屏幕占满,然后就不在打印了。这个时候,我们按下 Enter 他会自动往下翻,比较适合我们自顶向下的来查看。按q就可以退出。
我们可以在more场景当中使用 /数字 这种形式来直接跳到某行。
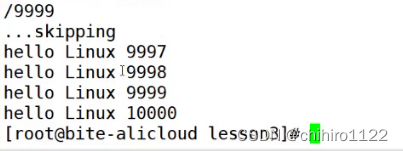
-数字
使用 -数字 这种方式就可以直接显示到文件当中的直接行数:
![]()
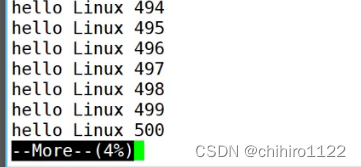
less指令
less的功能和more有些重叠,但是less功能更加强大。按↑他是上翻,按↓他是下翻,所以less他支持上下翻动。
相关选项:
- -i 忽略搜索时的大小写
- -N 显示每行的行号
- /字符串:向下搜索“字符串”的功能
- ?字符串:向上搜索“字符串”的功能
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
- q:quit
关于大文本
我们上述的 less 和 more 都是在查看 大文本,那么我们为什么要看一个大文本呢?什么属于大文本呢?
在大型项目中,我们想要查找我们想要的一些代码段等等,都可以用到大文件的查看;还有日志,比如你有一个服务器,这个服务器挂掉了,那么可以查看日志来查看它为什么挂掉了。
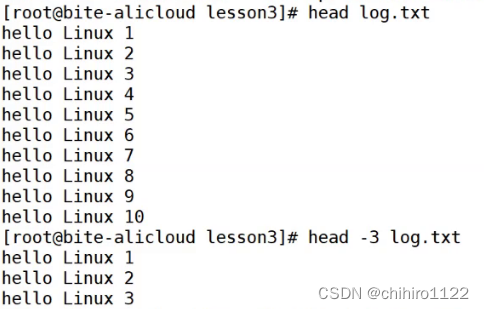
head指令
也是用于查看文件,只不过他是只给我们查看前 n 行内容。
其中的 n 默认是10,我们也可以 用 - 数字 的选项来规定 n 的大小。
tail指令
从文件的末尾开始查看文件,查看末尾的后 n 行内容,
同样n 默认是10,我们也可以 用 - 数字 的选项来规定 n 的大小。
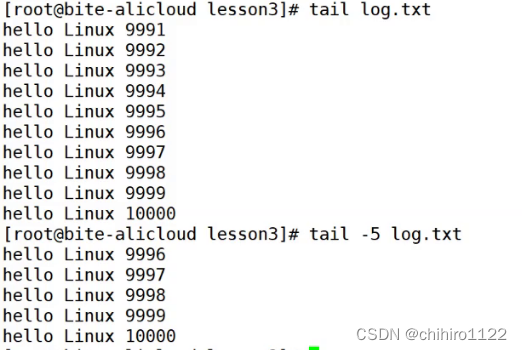
tail 指令常用与查看日志,假设日志已经写了 10 万行了,那么我们不可能从头开始看,这时候就可以用 tail 来查看后面的日志。
tail和head的妙用
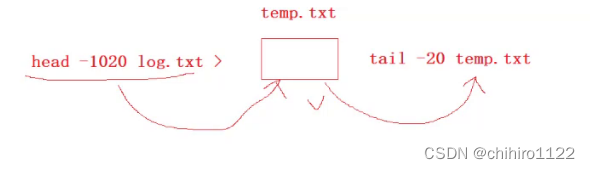
假设现在有 10000 行的内容,但是我们想查找其中的 1000 - 1020 行的数据,我们当然可以用 less 进去用 / 1000 来访问到1000行,但是其实还可以用 tail和head 结合使用来实现:
先用head 把前 1020 行内容重定向到一个新的文件的当中:
![]()
然后再用 tail 访问这个 文件的 后 20 行就可以得到 1000 - 1020 行的数据了: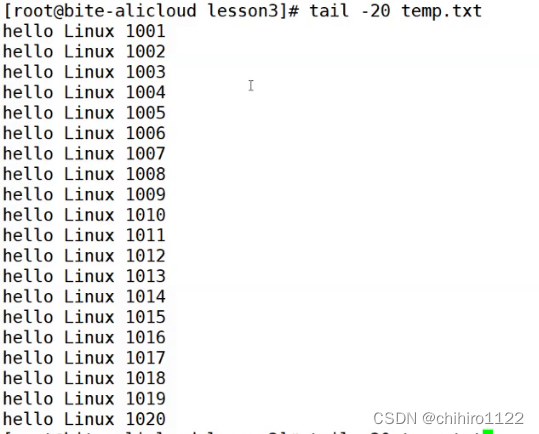
|
| : 管道文件
那么对于上述的tail和head,还可以这样使用:
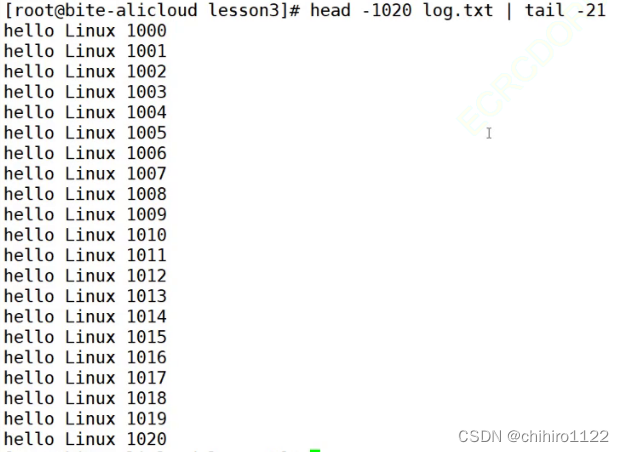
| 就是一种符号,后面会被“系统”解释称为管道文件,这个管道文件不是在磁盘里存在的,而是一种内存级的文件,其对于的执行逻辑如下图所示:

这里管道的意思就是用来传输资源的。
我们知道,当我们在访问文件的时候,因为文件是在磁盘中的,要先把磁盘中文件对应的内存拷贝到内存来进行访问,而磁盘当中文件,在访问完之后,要把内容重新刷到磁盘上吗,而内存级的不用。

wc -l 数计算行数的命令,像上述的操作,就是 管道 支持的流水线操作。
他可以把数据,一步一步进行加工,从而拿到我们想要的内容。


![Linux学习[8]文件权限深入2 默认权限umask SUID/SGID/SBIT file指令](https://img-blog.csdnimg.cn/66aba701252e48298be2171c0fec7c59.png)