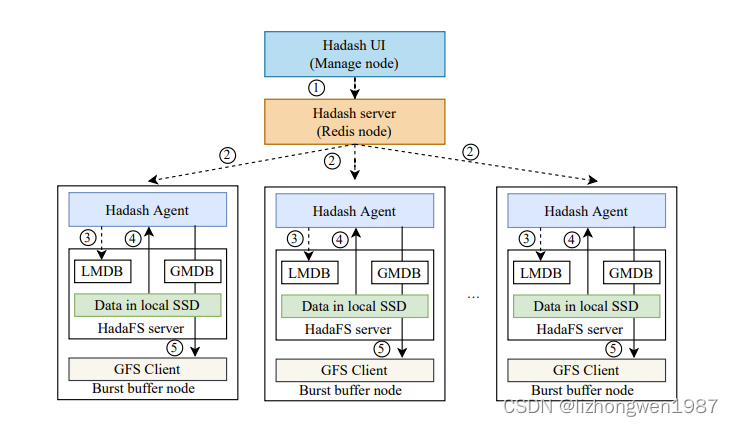
【VQ-VAE-2论文精读】Generating Diverse High-Fidelity Images with VQ-VAE-2
- 0、前言
- Abstract
- 1 Introduction
- 2 Background
- 2.1 Vector Quantized Variational AutoEncoder
- 3 Method
- 3.1 Stage 1: Learning Hierarchical Latent Codes
- 3.2 Stage 2: Learning Priors over Latent Codes
- 3.3 Trading off Diversity with Classifier Based Rejection Sampling
- 4 Related Works
- 5 Experiments
- 5.1 Modeling High-Resolution Face Images
- 5.2 Quantitative Evaluation
- 5.2.1 Negative Log-Likelihood and Reconstruction Error
- 5.2.2 Precision - Recall Metric
- 5.3 Classification Accuracy Score
- 5.3.1 FID and Inception Score
- 6 Conclusion
0、前言
论文地址:https://arxiv.org/abs/1906.00446
发表于2019年的NeurIPS。VQVAE的重要性就不谈了,学习latent diffusion model必须得了解这个。
NIPS(NeurIPS),全称神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),是一个关于机器学习和计算神经科学的国际会议。该会议固定在每年的12月举行,由NIPS基金会主办。NIPS是机器学习领域的顶级会议 。在中国计算机学会的国际学术会议排名中,NIPS为人工智能领域的A类会议。
来看看VQ-VAE-2相对于之前的版本有何异同之处吧。
总的来看这篇文章的新颖之处在于:
- 多层的VQVAE,顶部的层负责全局信息,底部的层负责局部细节。
- 架构的改进,例如self-attention的加入以及更好的稳定化方法、扩展tpu模型和在样品多样性和样品质量之间进行权衡的机制。
- 可以生成高分辨率的图像。
Abstract
研究了矢量量化变分自动编码器(VQ-VAE)模型在大规模图像生成中的应用。 为此,我们对VQ-VAE中使用的自回归先验进行了缩放和增强,以生成比以前更高的相干性和保真度的合成样本。
我们使用简单的前馈编码器和解码器网络,使我们的模型成为对编码和/或解码速度至关重要的应用的一个有吸引力的候选者。 另外,VQ-VAE只需要在压缩的潜在空间中对自回归模型进行采样,这比在像素空间中采样快一个数量级,特别是对于大图像。
我们证明了VQ-VAE的多尺度分层组织,加上对潜在代码的强大先验知识,能够在多层面数据集上生成与现有生成对抗网络相媲美的样本,同时不受GAN模式崩溃和缺乏多样性等已知缺点的影响。
1 Introduction
在Introduction中作者首先区分两种主要类型的生成模型:一是:基于似然的模型,包括VAEs、基于流和自回归模型;二是:隐式生成模型,如生成对抗网络。 每种模型都提供了几种折衷方案,如样本质量、多样性、速度等。
然后是分析了GAN的一些优缺点,然后又讲了likelihood based methods对于GANs的一些优点,然后是对于像素空间来优化负对数似然(NLL)的一些缺点。进而引导出本文提出的动机。
本文利用有损压缩的思想,将生成模型从可忽略信息的建模中解脱出来。
事实上,像JPEG[43]这样的技术已经表明,通常可以去除80%以上的数据,而不会明显改变感知的图像质量。
正如[41]所提出的,我们通过向量量化自动编码器的中间表示,将图像压缩到一个离散的潜在空间中。 这些表示比原始图像小30倍以上,但仍然允许解码器在很小的失真下重建图像。 这些离散表示的先验可以用具有self-attention[42]的SOTA PixelCNN[39,40]建模,称为PixelSnail[7]。
当从这个先验采样时,解码图像也表现出同样的高质量和重建的一致性(见图1)。
此外,这种生成模型在离散潜在空间上的训练和采样也比直接应用于像素时快30倍,允许我们在更高分辨率的图像上训练。 最后,本文所使用的编码器和解码器保留了原VQ-VAE的简单性和速度,这意味着本文提出的方法对于需要快速、低开销的大图像编码和解码是一种有吸引力的解决方案。

2 Background
2.1 Vector Quantized Variational AutoEncoder
主要回顾了一下VQVAE的主要实现方法,包括三个损失函数,如下:

第一项是reconstruction error减小输入和输出直接的差异;
第二项是codebook loss让codebook学习来接近编码器的输出;
第三项是commitment loss让编码器的输出来学习以靠近codebook,即codebook学的太慢了,让编码器等等。以防止它从一个码向量到另一个码向量过于频繁地波动。而β是一个超参数,which controls the reluctance to change the code corresponding to the encoder output.
改变的地方是对codebook使用指数移动平均(exponential moving average)更新,即上面损失函数的第二项。
3 Method
本文提出的方法遵循两阶段的方法:
首先,我们训练一个分层的VQ-VAE(见图2a)将图像编码到一个离散的潜在空间,然后我们在所有数据诱导的离散潜在空间上拟合一个强大的PixelCNN先验。



3.1 Stage 1: Learning Hierarchical Latent Codes
与普通的VQ-VAE不同,在这项工作中,我们使用了矢量量化编码的层次结构来建模大型图像。这背后的主要动机是将局部信息(如纹理)与全局信息(如物体的形状和几何)分开建模。
因此,每个级别上的先验模型可以被裁剪,以捕获存在于该级别的特定相关性。
我们的多尺度分层编码器的结构如图2a所示,顶部潜码对全局信息进行建模,而底部潜码以顶部潜码为条件,负责表示局部细节(见图3)。
我们注意到,如果我们不将底部潜变量设置为以顶部潜变量为条件的话,那么顶部潜变量将需要对像素中的每个细节进行编码。
因此,我们允许层次中的每一层分别依赖像素,这鼓励在每个潜在映射中编码互补信息,这有助于减少解码器中的重构误差。
对于256 × 256的图像,我们使用两个层次的潜在层次。如图2a所示,编码器网络首先对图像进行变换,并将其以4的倍数下采样到64 × 64的表示,然后量化到我们的底层潜映射。
残差块的另一个堆栈则进一步将表示按2倍的比例缩小,在量化后产生一个顶级的32 × 32的潜在映射。
解码器类似地是一个前馈网络,以量化潜层次的所有层次作为输入。它由几个残余块和一些跨步转置卷积组成,将表示的图像上采样回原始图像大小。
3.2 Stage 2: Learning Priors over Latent Codes
为了进一步压缩图像,并能够从阶段1中学习的模型中进行采样,我们学习了潜在代码的先验。
利用神经网络从训练数据拟合先验分布已成为一种常见的实践,因为它可以显著提高潜在变量模型[6]的性能。
这一过程也减少了marginal posterior and the prior.之间的差距。
因此,在测试时间从学习的先验中采样的潜在变量接近于解码器网络在训练中观察到的,这导致了更相干的输出。
从信息论的角度来看,从一个可学习的后验中拟合一个先验的过程可以被认为是对潜在空间进行无损压缩,方法是将潜在变量重新编码为一个更接近其真实分布的分布,从而使比特率bit rates更接近香农熵Shannon’s entropy。
因此,真实熵和学习到的先验的负对数似然之间的差距越小,人们就能从解码潜在样本中得到更真实的图像样本。
在VQ-VAE框架中,这种辅助先验是用强大的自回归神经网络(如PixelCNN)在事后的第二阶段建模的。
在top的潜在map上的先验负责结构的全局信息。因此,我们如在[7,26]中为它装备了多头自我注意层,这样它就可以从更大的接受域中受益,以捕捉图像中距离很远的空间位置的相关性。
相比之下,编码局部信息的底层的条件先验模型将以更大的分辨率运行。
由于内存的限制,在前面的顶层中使用自我注意层是不实际的。
因此,对于这一先验信息,我们发现使用大的调节堆栈(来自top的先验信息)可以产生良好的性能(见图2b)。
层次分解还允许我们训练更大的模型:我们分别训练每个先验的模型,从而利用硬件加速器上所有可用的计算和内存。有关架构和超参数的详细信息,请参阅附录A。
3.3 Trading off Diversity with Classifier Based Rejection Sampling
与GANs不同,用最大似然目标训练的概率模型被迫对所有训练数据分布进行建模。这是因为MLE目标可以表示为数据和模型分布之间的正向KL散度,如果训练数据中的一个例子的质量为零,则该散度将被驱动到无穷大。
虽然覆盖数据分布中的所有模式是这些模型的一个吸引人的特性,但这项任务比对抗性建模要困难得多,因为基于似然的模型需要适合数据中出现的所有模式。
此外,来自自回归模型的祖先抽样ancestral sampling在实践中会导致错误,这些错误会在长序列中累积,并导致样本质量下降。
最近的GAN框架[5,2]提出了样本选择的自动化程序,以权衡多样性和质量。
在这项工作中,我们还提出了一种自动的方法来权衡样本的多样性和质量,基于直觉,我们的样本越接近真实的数据流形,它们就越有可能被一个预先训练的分类器分类到正确的类标签。
具体来说,我们使用一个在ImageNet上训练的分类器网络,根据分类器分配给正确类的概率,从我们的模型中对样本进行评分。
请注意,在本文中,我们只将这个分类器用于定量度量(如FID、IS、Precision、Recall),以平衡多样性与质量。
本手稿中的所有样本都没有使用这个分类器进行采样(请点击附录部分的链接查看)。
4 Related Works
本文是基于VQVAE框架的,先验网络是基于Gated PixelCNN并且经过self-attention增强的。
并提出灵感来自BigGAN,改进包括架构、self-attention、更好的稳定化方法、扩展tpu模型,以及在样品多样性和样品质量之间进行权衡的机制。
作者还提及了相同时期的类似的工作,以及与他们的异同点。
5 Experiments
生成模型的客观评价和比较,特别是跨模型族的模型,仍然是一个挑战。
目前的图像生成模型在样本质量和多样性(或精度与召回率[32])之间进行权衡。在本节中,我们展示了在ImageNet 256 × 256上训练的模型的定量和定性结果。
从图5中提供的类条件样本中可以看出,在几个具有代表性的类中,样本质量确实是高而尖锐的。在多样性方面,我们将我们模型中的样本与BigGAN-deep[5]的样本并置,图5中是GAN模型4的SOTA。从这些并排比较中可以看出,VQ-VAE能够提供保真度相当、多样性较高的样品。

5.1 Modeling High-Resolution Face Images
为了进一步评估我们的多尺度方法在获取数据中极长距离依赖关系方面的有效性,我们在FFHQ数据集[15]上训练了一个1024 × 1024分辨率的三级层次模型。
这个数据集包含了7万张高质量的人体肖像,性别、肤色、年龄、姿势和服装都相当多样化。
虽然与ImageNet相比,人脸建模通常被认为不那么困难,但在如此高的分辨率下,也有独特的建模挑战,可以以有趣的方式探索生成模型。
例如,面部的对称需要能够捕获长期依赖关系的模型:接受域受限的模型可能会分别为每只眼睛选择合理的颜色,但可能会错过相距几百像素的两只眼睛之间的强烈相关性,从而产生眼睛颜色不匹配的样本。
5.2 Quantitative Evaluation
在本节中,我们将报告基于几个指标的定量评估结果,这些指标旨在衡量样本的质量和多样性。
5.2.1 Negative Log-Likelihood and Reconstruction Error
使用基于似然生成模型的主要动机之一是,测试和训练集上的负对数似然(NLL)为泛化提供了一个客观的度量,并允许我们监测过度拟合。
我们强调,其他常用的性能指标,如FID和Inception Score完全忽略了泛化的问题;一个简单地记忆训练数据的模型可以在这些指标上获得完美的分数。
同样的问题也适用于一些最近提出的指标,如Precision-Recall[32, 19]和Classification Accuracy Scores[28]。这些基于样本的度量只提供了样本质量和多样性的代理,但忽略了对被屏蔽图像的泛化。
请注意,图1中报告的我们的顶部和底部先验的NLL值,对于训练和验证来说是接近的,表明这两个网络都没有过拟合。
我们注意到,这些NLL值仅在使用相同的预先训练的VQ-VAE编码器和解码器的先验模型之间具有可比性。
5.2.2 Precision - Recall Metric
Precision和Recall度量被提议作为评价GANs性能的FID和Inception评分的替代方法[32,19]。
这些度量旨在明确地量化覆盖率(召回率)和质量(精度)之间的权衡。
我们使用改进的精确召回版本,将我们的模型中的样本与BigGAN- deep获得的样本进行比较,过程与ImageNet中所有1000个类的[19]中概述的步骤相同。
图7b显示了VQ-VAE和BigGan使用基于分类器的拒绝抽样(“critic”,见3.3节)对不同的拒绝率和不同截断水平的BigGan-deep结果的精度-召回结果。VQ-VAE结果的精度水平略低,但召回值较高。

5.3 Classification Accuracy Score
我们还使用最近提出的Classification Accuracy Score (CAS)[28]来评估我们的方法,该方法只需要对来自候选模型的样本训练ImageNet分类器,然后对来自测试集的真实图像评估其分类精度,从而衡量样本质量和多样性。
我们对这个指标的评估结果如表2所示。对于VQ-VAE, ImageNet分类器只对样本进行训练,样本中缺少高频信号、噪声等(由于压缩)。对测试图像的VQ-VAE重建进行评价,可以消除“域差距”,提高CAS评分,而无需重新训练分类器。

5.3.1 FID and Inception Score
比较GANs的两个最常见的指标是Inception Score[34]和Fréchet Inception Distance (FID)[13]。
注意到这些度量标准存在一些已知的缺陷[3,32,19],我们在图7a中报告了我们的结果。
我们使用基于分类器的拒绝抽样rejection sampling来权衡多样性和质量(章节3.3)。对于VQ-VAE,这提高了IS和FID评分,FID从大约30到10。
对于BigGAN -deep,拒绝采样(被称为批评家)比BigGAN论文[5]中提出的截断方法更好。
我们观察到,初始分类器对VQ-VAE重建中引入的事件最轻微的模糊或其他扰动非常敏感,正如在简单压缩原始数据时,FID ~ 10而不是~ 2所示。
因此,我们也计算了VQ-VAE样本和重建之间的FID(我们表示为FID*),表明初始网络统计数据比FID所建议的更接近真实图像数据。
6 Conclusion
我们提出了一种简单的方法来生成不同的高分辨率图像使用VQ-VAE与强大的自回归模型作为先验。
我们的编码器和解码器架构保持简单和轻量级的原始VQ-VAE,唯一的区别是,我们使用了一个分层多尺度潜映射来提高分辨率。
我们的最佳类条件样本的保真度可与最先进的生成对抗网络相媲美,在几个类中具有更广泛的多样性,将我们的方法与gan的已知局限性进行了对比。
尽管如此,样品质量和多样性的具体措施仍处于起步阶段,目视检查仍然是必要的。
最后,我们相信我们的实验证明vindicate,潜空间中的自回归模型是学习大规模生成模型的一个简单而有效的目标。