目录
一、适用场景
二、业务需求
(1)原产品需求
(2)需求分析
① 需求漏洞
②「0 能力完好」分级标准问题答案组合
③「1 轻度受损」分级标准问题答案组合
④「2 中度受损」分级标准问题答案组合
⑤「3 重度受损」分级标准问题答案组合
⑥ 实际存在的全部问题答案组合
三、Python 文件
(1)创建文件
(2)代码示例
四、csv 文件
一、适用场景
实战场景:
- 问卷全部为单选题
- 问卷问题全部为必填
- 问题之间无关联关系
- 每个问题的答案分数不同
- 根据问卷全部问题得分生成总分数,仅显示不用于判断等级标准
- 根据问卷全部问题的某个答案得分组合,嵌套笛卡尔积组合,内含或非判断
- 根据问卷多问题答案的组合生成对应判断文案结果,显示判断等级名称和编号
- 生成 csv 文件表格需要设置固定表头
- 表格内容需要根据等级编号从小到大排列
二、业务需求
(1)原产品需求
感知觉与沟通评估表
| 1. 意识水平 | □ 分 | 0 分,神志清醒,对周围环境警觉 |
| 1 分,嗜睡,表现为睡眠状态过度延长。当呼唤或推动其肢体时可唤醒,并能进行正确的交谈或执行指令,停止刺激后又继续入睡 | ||
| 2 分,昏睡,一般的外界刺激不能使其觉醒,给予较强烈的刺激时可有短时的意识清醒,醒后可简短回答提问,当刺激减弱后又很快进入睡眠状态 | ||
| 3 分,昏迷,处于浅昏迷时对疼痛刺激有回避和痛苦表情;处于深昏迷时对刺激无反应(若评定为昏迷,直接评定为重度失能,可不进行以下项目的评估) | ||
| 2. 视力: 若平日带老花镜或近视镜,应在佩戴眼镜的情况下评估 | □ 分 | 0 分,能看清书报上的标准字体 |
| 1 分,能看清楚大字体,但看不清书报上的标准字体 | ||
| 2 分,视力有限,看不清报纸大标题,但能辨认物体 | ||
| 3 分,辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | ||
| 4分,没有视力,眼睛不能跟随物体移动 | ||
| 3. 听力: 若平时佩戴助听器,应在佩戴助听器的情况下评估 | □ 分 | 0 分,可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分,在轻声说话或说话距离超过2米时听不清 | ||
| 2 分,正常交流有些困难,需在安静的环静或大声说话才能听到 | ||
| 3 分,讲话者大声说话或说话很慢,才能部分听见 | ||
| 4 分,完全听不见 | ||
| 4. 沟通交流: 包括非语言沟通 | □ 分 | 0 分,无困难,能与他人正常沟通和交流 |
| 1 分,能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 | ||
| 2 分,表达需要或理解有困难,需频繁重复或简化口头表达 | ||
| 3 分,不能表达需要或理解他人的话 | ||
| 感知觉与沟通分级 | □ 级 | 0 能力完好:意识为清醒,且视力和听力评为 0 或 1,沟通评为 0 1 轻度受损:意识为清醒,但视力或听力中至少一项评为 2,或沟通评为 1 2 中度受损:意识为清醒,但视力或听力中至少一项评为 3,或沟通评为 2;或意识为嗜睡,视力或听力评定为 3 及以下,沟通评定为 2 及以下 3 重度受损:意识为清醒或嗜睡,但视力或听力中至少一项评为 4,或 沟通评为 3;或意识为昏睡/昏迷 |
感知觉与沟通分级标准
| 分级 | 分级名称 | 分级标准 |
| 0 | 能力完好 | 意识为清醒,视力和听力评定为 0 或 1,沟通评定为 0 |
| 1 | 轻度受损 | 意识为清醒,但视力或听力中至少一项评定为 2,或沟通评定为 1 |
| 2 | 中度受损 | 意识为清醒,但视力或听力中至少一项评定为 3,或沟通评定为 2; 或意识为嗜睡,视力或听力评定为 3 及以下,沟通评定为 2 及以下 |
| 3 | 重度受损 | 意识为清醒或嗜睡,视力或听力中至少一项评定为 4,或沟通评定为 3; 或意识为昏睡或昏迷 |
(2)需求分析
① 需求漏洞
文字描述等级标准的需求漏洞:
- 分级标准不是按照问题总分得到的,而是按照各个问题的某个答案、多问题答案组合得到一个等级,且是依据文字叙述,最后生成的笛卡尔积组合
- 会存在部分组合找不到等级标准的情况,这个需要找产品修改需求,或者按照文字描述,修改需求等级
- 会存在重复组合却是属于不同等级标准的情况
- 需要将文字叙述的分级标准,转化成具体问题评分的笛卡尔积组合,即可得到另一个等级标准问题得分组合表
- 需要根据等级标准问题组合,得到最后的等级
- 需要筛选出有等级名称与无等级名称的问题得分组合
- 需要找产品修改等级标准的判断,实现全部组合有唯一等级标准的需求
②「0 能力完好」分级标准问题答案组合
| 【0】【能力完好】分级标准: 意识为清醒,且视力和听力评为 0 或 1 ,沟通评为 0 | ||
| 分级标准 ① :意识水平为 0 分,视力和听力为 0 或 1 分,沟通交流为 0 分 | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 4. 沟通交流 | 0 分 | 无困难,能与他人正常沟通和交流 |
③「1 轻度受损」分级标准问题答案组合
| 【1】【轻度受损】分级标准: 意识为清醒,但视力或听力中至少一项评为 2,或沟通评为 1 | ||
| 分级标准 ① :意识水平为 0 分,视力为 2 分,听力和沟通交流默认全部(含视力和听力都为 2 的情况) | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 2. 视力 | 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 | |
| 3 分 | 讲话者大声说话或说话很慢,才能部分听见 | |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 0 分 | 无困难,能与他人正常沟通和交流 |
| 1 分 | 能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 | |
| 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 | |
| 3 分 | 不能表达需要或理解他人的话 | |
| 分级标准 ② :意识水平为 0 分,听力为 2 分,视力和沟通交流默认全部(含视力和听力都为 2 的情况) | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 | |
| 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 |
| 4. 沟通交流 | 0 分 | 无困难,能与他人正常沟通和交流 |
| 1 分 | 能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 | |
| 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 | |
| 3 分 | 不能表达需要或理解他人的话 | |
| 分级标准 ③ :意识水平为 0 分,沟通交流为 1 分,听力和视力默认全部 | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 | |
| 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 | |
| 3 分 | 讲话者大声说话或说话很慢,才能部分听见 | |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 1 分 | 能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 |
④「2 中度受损」分级标准问题答案组合
| 【2】【中度受损】等级标准: 意识为清醒,但视力或听力中至少一项评为 3 ,或沟通评为 2 ; 或意识为嗜睡,视力或听力评定为 3 及以下,沟通评定为 2 及以下 | ||
| 分级标准 ① :意识水平为 0 分,视力为 3 分,听力和沟通交流默认全部(含视力和听力都为 3 的情况) | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 2. 视力 | 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 | |
| 3 分 | 讲话者大声说话或说话很慢,才能部分听见 | |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 0 分 | 无困难,能与他人正常沟通和交流 |
| 1 分 | 能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 | |
| 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 | |
| 3 分 | 不能表达需要或理解他人的话 | |
| 分级标准 ② :意识水平为 0 分,听力为 3,视力和沟通交流默认全部(含视力和听力都为 3 的情况) | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 | |
| 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 3 分 | 讲话者大声说话或说话很慢,才能部分听见 |
| 4. 沟通交流 | 0 分 | 无困难,能与他人正常沟通和交流 |
| 1 分 | 能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 | |
| 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 | |
| 3 分 | 不能表达需要或理解他人的话 | |
| 分级标准 ③ :意识水平为 0 分,沟通交流为 2 分,视力和听力默认全部 | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 | |
| 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 | |
| 3 分 | 讲话者大声说话或说话很慢,才能部分听见 | |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 |
| 分级标准 ④ :意识水平为 1 分,视力为 3 或 4 分,沟通交流为 2 或 3 分,听力默认全部 | ||
| 1. 意识水平 | 1 分 | 嗜睡,表现为睡眠状态过度延长。当呼唤或推动其肢体时可唤醒,并能进行正确的交谈或执行指令,停止刺激后又继续入睡 |
| 2. 视力 | 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 | |
| 3 分 | 讲话者大声说话或说话很慢,才能部分听见 | |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 |
| 3 分 | 不能表达需要或理解他人的话 | |
| 分级标准 ⑤ :意识水平为 1 分,听力为 3 或 4 分,沟通交流为 2 或 3 分,视力默认全部 | ||
| 1. 意识水平 | 1 分 | 嗜睡,表现为睡眠状态过度延长。当呼唤或推动其肢体时可唤醒,并能进行正确的交谈或执行指令,停止刺激后又继续入睡 |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 | |
| 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 3 分 | 讲话者大声说话或说话很慢,才能部分听见 |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 |
| 3 分 | 不能表达需要或理解他人的话 | |
⑤「3 重度受损」分级标准问题答案组合
| 【3】【重度受损】分级标准: 意识为清醒或嗜睡,但视力或听力中至少一项评为4,或沟通评为3; 或意识为昏睡/昏迷 | ||
| 分级标准 ① :意识水平为 0 或 1 分,视力为 4 分,听力和沟通交流默认全部(含视力和听力都为 4 的情况) | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 1 分 | 嗜睡,表现为睡眠状态过度延长。当呼唤或推动其肢体时可唤醒,并能进行正确的交谈或执行指令,停止刺激后又继续入睡 | |
| 2. 视力 | 4 分 | 没有视力,眼睛不能跟随物体移动 |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 | |
| 3 分 | 讲话者大声说话或说话很慢,才能部分听见 | |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 0分 | 无困难,能与他人正常沟通和交流 |
| 1分 | 能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 | |
| 2分 | 表达需要或理解有困难,需频繁重复或简化口头表达 | |
| 3分 | 不能表达需要或理解他人的话 | |
| 分级标准 ② :意识水平为 0 或 1 分,听力为 4 分,视力和沟通交流默认全部(含视力和听力都为 4 的情况) | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 1 分 | 嗜睡,表现为睡眠状态过度延长。当呼唤或推动其肢体时可唤醒,并能进行正确的交谈或执行指令,停止刺激后又继续入睡 | |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 | |
| 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 4 分 | 完全听不见 |
| 4. 沟通交流 | 0 分 | 无困难,能与他人正常沟通和交流 |
| 1 分 | 能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 | |
| 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 | |
| 3 分 | 不能表达需要或理解他人的话 | |
| 分级标准 ③ :意识水平为 0 或 1 分,沟通交流为 3 分,听力和视力默认全部 | ||
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 1 分 | 嗜睡,表现为睡眠状态过度延长。当呼唤或推动其肢体时可唤醒,并能进行正确的交谈或执行指令,停止刺激后又继续入睡 | |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 | |
| 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 | |
| 3 分 | 讲话者大声说话或说话很慢,才能部分听见 | |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 3 分 | 不能表达需要或理解他人的话 |
| 分级标准 ④ :意识水平为 2 或 3 分,听力、视力、沟通交流默认全部 | ||
| 1. 意识水平 | 2 分 | 昏睡,一般的外界刺激不能使其觉醒,给予较强烈的刺激时可有短时的意识清醒,醒后可简短回答提问,当刺激减弱后又很快进入睡眠状态 |
| 3 分 | 昏迷,处于浅昏迷时对疼痛刺激有回避和痛苦表情;处于深昏迷时对刺激无反应(若评定为昏迷,直接评定为重度失能,可不进行以下项目的评估) | |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 | |
| 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 | |
| 3 分 | 讲话者大声说话或说话很慢,才能部分听见 | |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 0 分 | 无困难,能与他人正常沟通和交流 |
| 1 分 | 能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 | |
| 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 | |
| 3 分 | 不能表达需要或理解他人的话 | |
⑥ 实际存在的全部问题答案组合
| 1. 意识水平 | 0 分 | 神志清醒,对周围环境警觉 |
| 1 分 | 嗜睡,表现为睡眠状态过度延长。当呼唤或推动其肢体时可唤醒,并能进行正确的交谈或执行指令,停止刺激后又继续入睡 | |
| 2 分 | 昏睡,一般的外界刺激不能使其觉醒,给予较强烈的刺激时可有短时的意识清醒,醒后可简短回答提问,当刺激减弱后又很快进入睡眠状态 | |
| 3 分 | 昏迷,处于浅昏迷时对疼痛刺激有回避和痛苦表情;处于深昏迷时对刺激无反应(若评定为昏迷,直接评定为重度失能,可不进行以下项目的评估) | |
| 2. 视力 | 0 分 | 能看清书报上的标准字体 |
| 1 分 | 能看清楚大字体,但看不清书报上的标准字体 | |
| 2 分 | 视力有限,看不清报纸大标题,但能辨认物体 | |
| 3 分 | 辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状 | |
| 4 分 | 没有视力,眼睛不能跟随物体移动 | |
| 3. 听力 | 0 分 | 可正常交谈,能听到电视、电话、门铃的声音 |
| 1 分 | 在轻声说话或说话距离超过2米时听不清 | |
| 2 分 | 正常交流有些困难,需在安静的环静或大声说话才能听到 | |
| 3 分 | 讲话者大声说话或说话很慢,才能部分听见 | |
| 4 分 | 完全听不见 | |
| 4. 沟通交流 | 0 分 | 无困难,能与他人正常沟通和交流 |
| 1 分 | 能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助 | |
| 2 分 | 表达需要或理解有困难,需频繁重复或简化口头表达 | |
| 3 分 | 不能表达需要或理解他人的话 |
三、Python 文件
(1)创建文件
PerceptualCommunicateForm.py
(2)代码示例
以下代码主要用于生成和编辑 CSV 文件。具体来说,它包含以下几个功能:
1. 生成一个 CSV 文件,其中包含所有可能的问题答案组合。
2. 从一个 CSV 文件中提取出重复的行数据,并将它们保存到另一个 CSV 文件中。
3. 从一个 CSV 文件中去除重复的行数据,只保留第一条相同行数据,并将结果保存到另一个 CSV 文件中。
4. 对比两个 CSV 文件,找出它们中相同的行数据,并将结果保存到另一个 CSV 文件中。
5. 对比两个 CSV 文件,找出它们中不同的行数据,并将结果保存到另一个 CSV 文件中。
6. 编辑一个 CSV 文件,按照表格的第 3-7 列从小到大的顺序排序行数据。
import os
import csv
from itertools import product
# 感知觉与沟通评估表
Score_1 = [0, 1, 2, 3]
Score_2 = [0, 1, 2, 3, 4]
Score_3 = [0, 1, 2, 3, 4]
Score_4 = [0, 1, 2, 3]
'''
【0】【能力完好】分级标准:
意识为清醒,且视力和听力评为 0 或 1 ,沟通评为 0
-- 分级标准 ① :意识水平为 0 分,视力和听力为 0 或 1 分,沟通交流为 0 分
'''
# 分级标准 ①
Score_1_01 = [0]
Score_2_01 = [0, 1]
Score_3_01 = [0, 1]
Score_4_01 = [0]
'''
【1】【轻度受损】分级标准:
意识为清醒,但视力或听力中至少一项评为 2,或沟通评为 1
-- 分级标准 ① :意识水平为 0 分,视力为 2 分,听力和沟通交流默认全部(含视力和听力都为 2 的情况)
-- 分级标准 ② :意识水平为 0 分,听力为 2 分,视力和沟通交流默认全部(含视力和听力都为 2 的情况)
-- 分级标准 ③ :意识水平为 0 分,沟通交流为 1 分,听力和视力默认全部
'''
# 分级标准 ①
Score_1_11 = [0]
Score_2_11 = [2]
Score_3_11 = [0, 1, 2, 3, 4]
Score_4_11 = [0, 1, 2, 3]
# 分级标准 ②
Score_1_12 = [0]
Score_2_12 = [0, 1, 2, 3, 4]
Score_3_12 = [2]
Score_4_12 = [0, 1, 2, 3]
# 分级标准 ③
Score_1_13 = [0]
Score_2_13 = [0, 1, 2, 3, 4]
Score_3_13 = [0, 1, 2, 3, 4]
Score_4_13 = [1]
'''
【2】【中度受损】等级标准:
意识为清醒,但视力或听力中至少一项评为 3 ,或沟通评为 2 ;
或意识为嗜睡,视力或听力评定为 3 及以下,沟通评定为 2 及以下
-- 分级标准 ① :意识水平为 0 分,视力为 3 分,听力和沟通交流默认全部(含视力和听力都为 3 的情况)
-- 分级标准 ② :意识水平为 0 分,听力为 3,视力和沟通交流默认全部(含视力和听力都为 3 的情况)
-- 分级标准 ③ :意识水平为 0 分,沟通交流为 2 分,视力和听力默认全部
-- 分级标准 ④ :意识水平为 1 分,视力为 3 或 4 分,沟通交流为 2 或 3 分,听力默认全部
-- 分级标准 ⑤ :意识水平为 1 分,听力为 3 或 4 分,沟通交流为 2 或 3 分,视力默认全部
'''
# 分级标准 ①
Score_1_21 = [0]
Score_2_21 = [3]
Score_3_21 = [0, 1, 2, 3, 4]
Score_4_21 = [0, 1, 2, 3]
# 分级标准 ②
Score_1_22 = [0]
Score_2_22 = [0, 1, 2, 3, 4]
Score_3_22 = [3]
Score_4_22 = [0, 1, 2, 3]
# 分级标准 ③
Score_1_23 = [0]
Score_2_23 = [0, 1, 2, 3, 4]
Score_3_23 = [0, 1, 2, 3, 4]
Score_4_23 = [2]
# 分级标准 ④
Score_1_24 = [1]
Score_2_24 = [3, 4]
Score_3_24 = [0, 1, 2, 3, 4]
Score_4_24 = [2, 3]
# 分级标准 ⑤
Score_1_25 = [1]
Score_2_25 = [0, 1, 2, 3, 4]
Score_3_25 = [3, 4]
Score_4_25 = [2, 3]
'''
【3】【重度受损】分级标准:
意识为清醒或嗜睡,但视力或听力中至少一项评为4,或沟通评为3;
或意识为昏睡/昏迷
-- 分级标准 ① :意识水平为 0 或 1 分,视力为 4 分,听力和沟通交流默认全部(含视力和听力都为 4 的情况)
-- 分级标准 ② :意识水平为 0 或 1 分,听力为 4 分,视力和沟通交流默认全部(含视力和听力都为 4 的情况)
-- 分级标准 ③ :意识水平为 0 或 1 分,沟通交流为 3 分,听力和视力默认全部
-- 分级标准 ④ :意识水平为 2 或 3 分,听力、视力、沟通交流默认全部
'''
# 分级标准 ①
Score_1_31 = [0, 1]
Score_2_31 = [4]
Score_3_31 = [0, 1, 2, 3, 4]
Score_4_31 = [0, 1, 2, 3]
# 分级标准 ②
Score_1_32 = [0, 1]
Score_2_32 = [0, 1, 2, 3, 4]
Score_3_32 = [4]
Score_4_32 = [0, 1, 2, 3]
# 分级标准 ③
Score_1_33 = [0, 1]
Score_2_33 = [0, 1, 2, 3, 4]
Score_3_33 = [0, 1, 2, 3, 4]
Score_4_33 = [3]
# 分级标准 ④
Score_1_34 = [2, 3]
Score_2_34 = [0, 1, 2, 3, 4]
Score_3_34 = [0, 1, 2, 3, 4]
Score_4_34 = [0, 1, 2, 3]
'''
[感知觉与沟通评估表问卷问题及答案(得分)]
-- Score_1:问题 1 评分
-- Score_2:问题 2 评分
-- Score_3:问题 3 评分
-- Score_4:问题 4 评分
第 1 题:[意识水平]()
a.神志清醒,对周围环境警觉
b.嗜睡,表现为睡眠状态过度延长。当呼唤或推动其肢体时可唤醒,并能进行正确的交谈或执行指令,停止刺激后又继续入睡
c.昏睡,一般的外界刺激不能使其觉醒,给予较强烈的刺激时可有短时的意识清醒,醒后可简短回答提问,当刺激减弱后又很快进入睡眠状态
d.昏迷,处于浅昏迷时对疼痛刺激有回避和痛苦表情;处于深昏迷时对刺激无反应(若评定为昏迷,直接评定为重度失能,可不进行以下项目的评估)
-- 评分标准
a.0 分
b.1 分
c.2 分
d.3 分
第 2 题:[视力]若平日带老花镜或近视镜,应在佩戴眼镜的情况下评估()
a.能看清书报上的标准字体
b.能看清楚大字体,但看不清书报上的标准字体
c.视力有限,看不清报纸大标题,但能辨认物体
d.辨认物体有困难,但眼睛能跟随物体移动,只能看到光、颜色和形状
f.没有视力,眼睛不能跟随物体移动
-- 评分标准
a.0 分
b.1 分
c.2 分
d.3 分
f.4 分
第 3 题:[听力]若平时佩戴助听器,应在佩戴助听器的情况下评估()
a.可正常交谈,能听到电视、电话、门铃的声音
b.在轻声说话或说话距离超过2米时听不清
c.正常交流有些困难,需在安静的环静或大声说话才能听到
d.讲话者大声说话或说话很慢,才能部分听见
f.完全听不见
-- 评分标准
a.0 分
b.1 分
c.2 分
d.3 分
f.4 分
第 4 题:[沟通交流]包括非语言沟通()
a.无困难,能与他人正常沟通和交流
b.能够表达自己的需要及理解别人的话,但需要增加时间或给予帮助
c.表达需要或理解有困难,需频繁重复或简化口头表达
d.不能表达需要或理解他人的话
-- 评分标准
a.0 分
b.1 分
c.2 分
d.3 分
'''
'''
[感知觉与沟通分级标准]
-- 等级标准:根据 4 个问题所选答案的组合分级
0 能力完好:意识为清醒,视力和听力评定为 0 或 1,沟通评定为 0
1 轻度受损:意识为清醒,但视力或听力中至少一项评定为 2,或沟通评定为 1
2 中度受损:意识为清醒,但视力或听力中至少一项评定为 3,或沟通评定为 2;或意识为嗜睡,视力或听力评定为 3 及以下,沟通评定为 2 及以下
3 重度受损:意识为清醒或嗜睡,视力或听力中至少一项评定为 4,或沟通评定为 3;或意识为昏睡或昏迷
'''
# 配置文件:配置csv文件表格基本参数
# 文件路径和文件名称
filename_1 = r'E:\ScoreGradeForm\CSVFiles\感知觉与沟通评估表(分级标准).csv'
filename_2 = r'E:\ScoreGradeForm\CSVFiles\感知觉与沟通评估表(全).csv'
filename_3 = r'E:\ScoreGradeForm\CSVFiles\感知觉与沟通评估表(分级组合相同).csv'
filename_4 = r'E:\ScoreGradeForm\CSVFiles\感知觉与沟通评估表(分级组合不同).csv'
filename_5 = r'E:\ScoreGradeForm\CSVFiles\感知觉与沟通评估表(全与等级相同).csv'
filename_6 = r'E:\ScoreGradeForm\CSVFiles\感知觉与沟通评估表(全与等级不同).csv'
# 表头
csvheader = ['感知觉与沟通分级', '等级编号', '感知觉与沟通总分', '问题 1 评分[意识水平]', '问题 2 评分[视力]',
'问题 3 评分[听力]', '问题 4 评分[沟通交流]']
# 删除文件:检查是否已存在该csv文件,如已存在则先删除
if os.path.exists(filename_1):
os.remove(filename_1)
if os.path.exists(filename_2):
os.remove(filename_2)
if os.path.exists(filename_3):
os.remove(filename_3)
if os.path.exists(filename_4):
os.remove(filename_4)
if os.path.exists(filename_5):
os.remove(filename_5)
if os.path.exists(filename_6):
os.remove(filename_6)
# 新建文件:生成csv文件,表格内容未排序(等级标准全组合:含重复组合但等级不同的、不全等于全部组合)
with open(filename_1, 'a+', encoding='utf-8-sig', newline='') as csvfile_0:
# 生成表头
header = csvheader
writer = csv.writer(csvfile_0)
writer.writerow(header)
# 生成表格内容
for scoreGroup in product(Score_1_01, Score_2_01, Score_3_01, Score_4_01):
writer.writerow(["能力完好", "0", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_11, Score_2_11, Score_3_11, Score_4_11):
writer.writerow(["轻度受损", "1", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_12, Score_2_12, Score_3_12, Score_4_12):
writer.writerow(["轻度受损", "1", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_13, Score_2_13, Score_3_13, Score_4_13):
writer.writerow(["轻度受损", "1", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_21, Score_2_21, Score_3_21, Score_4_21):
writer.writerow(["中度受损", "2", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_21, Score_1_22, Score_3_22, Score_4_22):
writer.writerow(["中度受损", "2", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_21, Score_2_23, Score_3_23, Score_4_23):
writer.writerow(["中度受损", "2", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_24, Score_2_24, Score_3_24, Score_4_24):
writer.writerow(["中度受损", "2", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_25, Score_2_25, Score_3_25, Score_4_25):
writer.writerow(["中度受损", "2", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_31, Score_2_31, Score_3_31, Score_4_31):
writer.writerow(["重度受损", "3", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_32, Score_2_32, Score_3_32, Score_4_32):
writer.writerow(["重度受损", "3", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_33, Score_2_33, Score_3_33, Score_4_33):
writer.writerow(["重度受损", "3", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
for scoreGroup in product(Score_1_34, Score_2_34, Score_3_34, Score_4_34):
writer.writerow(["重度受损", "3", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
# 新建文件:生成csv文件,表格内容未排序(问题答案全组合:全部组合,无具体等级归类)
with open(filename_2, 'a+', encoding='utf-8-sig', newline='') as csvfile_1:
# 生成表头
header = csvheader
writer = csv.writer(csvfile_1)
writer.writerow(header)
# 生成表格内容
for scoreGroup in product(Score_1, Score_2, Score_3, Score_4):
writer.writerow(["", "", sum(scoreGroup), scoreGroup[0], scoreGroup[1], scoreGroup[2], scoreGroup[3]])
# 编辑文件:将已存在的csv文件进行调整,先按表格第2列从小到大排序、再按第3列从小到大排序内容
with open(filename_1, 'r', encoding='utf-8-sig') as csvfile_2:
rows = list(csv.reader(csvfile_2))
rows[1:] = sorted(rows[1:], key=lambda x: (int(x[1]), int(x[2])))
with open(filename_1, 'w', encoding='utf-8-sig', newline='') as csvfile_3:
writer = csv.writer(csvfile_3)
writer.writerows(rows)
# 编辑文件:将已存在的csv文件进行调整,按表格第3列从小到大排序内容
with open(filename_2, 'r', encoding='utf-8-sig') as csvfile_4:
rows = list(csv.reader(csvfile_4))
rows[1:] = sorted(rows[1:], key=lambda x: int(x[2]))
with open(filename_2, 'w', encoding='utf-8-sig', newline='') as csvfile_5:
writer = csv.writer(csvfile_5)
writer.writerows(rows)
# 新建表格:1个表数据,新建不同行数据表(单表对比:取重新建表,将单表数据中第 3~7 列数据行重复的数据新建到另一个表中)
def duplicate_data(file_1, file_2):
# 打开输入文件
with open(file_1, 'r', encoding='utf-8-sig') as input_csv:
# 读取 CSV 文件数据
reader = csv.reader(input_csv)
# 初始化一个字典用于存储重复数据
duplicate_data0 = {}
# 遍历 CSV 文件中的每一行数据
for row in reader:
# 从第3列到第7列的数据
row_data = row[2:7]
# 将数据转换为字符串,用于作为字典的键
key = ','.join(row_data)
# 如果该数据已经出现过,将该行数据添加到字典中
if key in duplicate_data0:
duplicate_data0[key].append(row)
# 如果该数据第一次出现,创建一个新的列表来存储该数据的行
else:
duplicate_data0[key] = [row]
# 打开输出文件
with open(file_2, 'w', encoding='utf-8-sig', newline='') as output_csv:
# 生成表头
header0 = csvheader
# 创建 CSV 写入器
writer0 = csv.writer(output_csv)
# 写入 CSV 文件头部
writer0.writerow(header0)
# 遍历重复数据字典,将重复数据写入输出文件
for key, rows0 in duplicate_data0.items():
# 如果该数据有重复的行
if len(rows0) > 1:
for row in rows0:
# 写入每一行数据
writer0.writerow(row)
# 新建表格:1个表数据,新建不同行数据表(单表对比:去重留一新建表)
def remove_duplicate_rows(file_1, file_2):
# 读取原始表格数据
with open(file_1, 'r', encoding='utf-8-sig') as f:
reader = csv.reader(f)
rows_0 = list(reader) # 将所有行数据读入一个列表
# 利用字典去重,只保留第1条相同行数据
unique_rows = {}
for row in rows_0:
key = tuple(row[2:7]) # 取第3-7列作为去重的关键字
if key not in unique_rows:
unique_rows[key] = row
# 将去重后的数据保存到新表格中
with open(file_2, 'w', encoding='utf-8-sig', newline='') as f:
writer_0 = csv.writer(f)
for row in unique_rows.values():
writer_0.writerow(row)
# 新建表格:对比表数据,新建相同行数据表(两表对比:取重新建表)
def compare_csv_files_1(file_1, file_2, file_3):
# 打开第一个 csv 文件
with open(file_1, 'r', encoding='utf-8-sig') as f1:
reader1 = csv.reader(f1)
# 跳过表头
next(reader1)
# 将第一个 csv 文件中的数据存储到一个列表中
data1 = [row for row in reader1]
# 打开第二个 csv 文件
with open(file_2, 'r', encoding='utf-8-sig') as f2:
reader2 = csv.reader(f2)
# 跳过表头
next(reader2)
# 将第二个 csv 文件中的数据存储到一个列表中
data2 = [row for row in reader2]
# 定义一个空列表,用于存储两个 csv 文件中第3/4/5/6/7列数据相同的行
same_rows = []
# 遍历第一个 csv 文件中的每一行
for row1 in data1:
# 遍历第二个 csv 文件中的每一行
for row2 in data2:
# 如果两行的第3/4/5/6/7列数据都相同,则将这两行数据存入 same_rows 列表中
if row1[2:7] == row2[2:7]:
same_rows.append(row1)
same_rows.append(row2)
# 去除重复的行数据
same_rows = list(set(tuple(row) for row in same_rows))
# 将结果保存到新的 csv 文件中
with open(file_3, 'w', encoding='utf-8-sig', newline='') as f3:
# 生成表头
header_1 = csvheader
writer_1 = csv.writer(f3)
writer_1.writerow(header_1)
# 写入相同的行数据
for row in same_rows:
writer_1.writerow(row)
# 新建表格:对比表数据,新建不同行数据表(两表对比:去重留一新建表)
def compare_csv_files_2(file_1, file_2, file_3):
# 打开第一个csv文件
with open(file_1, 'r', encoding='utf-8-sig') as f1:
reader1 = csv.reader(f1)
rows1 = list(reader1)
# 打开第二个csv文件
with open(file_2, 'r', encoding='utf-8-sig') as f2:
reader2 = csv.reader(f2)
rows2 = list(reader2)
# 获取表头
header_1 = rows1[0]
# 获取需要对比的列索引
compare_columns = [2, 3, 4, 5, 6]
# 存储不同的行数据
different_rows = []
# 存储相同的行数据
same_rows = []
# 遍历第一个csv文件的每一行
for row1 in rows1[1:]:
# 遍历第二个csv文件的每一行
for row2 in rows2[1:]:
# 判断需要对比的列是否相同
is_same = True
for column in compare_columns:
if row1[column] != row2[column]:
is_same = False
break
# 如果需要对比的列都相同
if is_same:
# 如果第二个csv文件中已经保存了相同的行数据,则跳过
if row2 in same_rows:
break
# 如果第二个csv文件中没有保存相同的行数据,则保存第二个csv文件中的行数据
same_rows.append(row2)
# 如果第二个csv文件中的行数据第二列有数值,则保存到不同的行数据中
if row2[1]:
different_rows.append(row2)
break
else:
# 如果第二个csv文件中没有相同的行数据,则保存第一个csv文件中的行数据
different_rows.append(row1)
# 将不同的行数据写入新表中
with open(file_3, 'w', encoding='utf-8-sig', newline='') as f:
writer_2 = csv.writer(f)
writer_2.writerow(header_1)
for row in different_rows:
writer_2.writerow(row)
# 编辑文件:将已存在的csv文件进行调整,先按表格第3列从小到大排序、再按第4列、第5列、第6列从小到大排序内容
def csv_files(file_1):
with open(file_1, 'r', encoding='utf-8-sig') as csvfile_6:
rows3 = list(csv.reader(csvfile_6))
rows3[1:] = sorted(rows3[1:], key=lambda x: (int(x[2]), int(x[3]), int(x[4]), int(x[5]), int(x[6])))
with open(file_1, 'w', encoding='utf-8-sig', newline='') as csvfile_7:
writer3 = csv.writer(csvfile_7)
writer3.writerows(rows3)
duplicate_data(filename_1, filename_3)
remove_duplicate_rows(filename_1, filename_4)
compare_csv_files_1(filename_2, filename_4, filename_5)
compare_csv_files_2(filename_2, filename_5, filename_6)
csv_files(filename_3)
csv_files(filename_4)
csv_files(filename_5)
csv_files(filename_6)
四、csv 文件
生成如下结果表格:
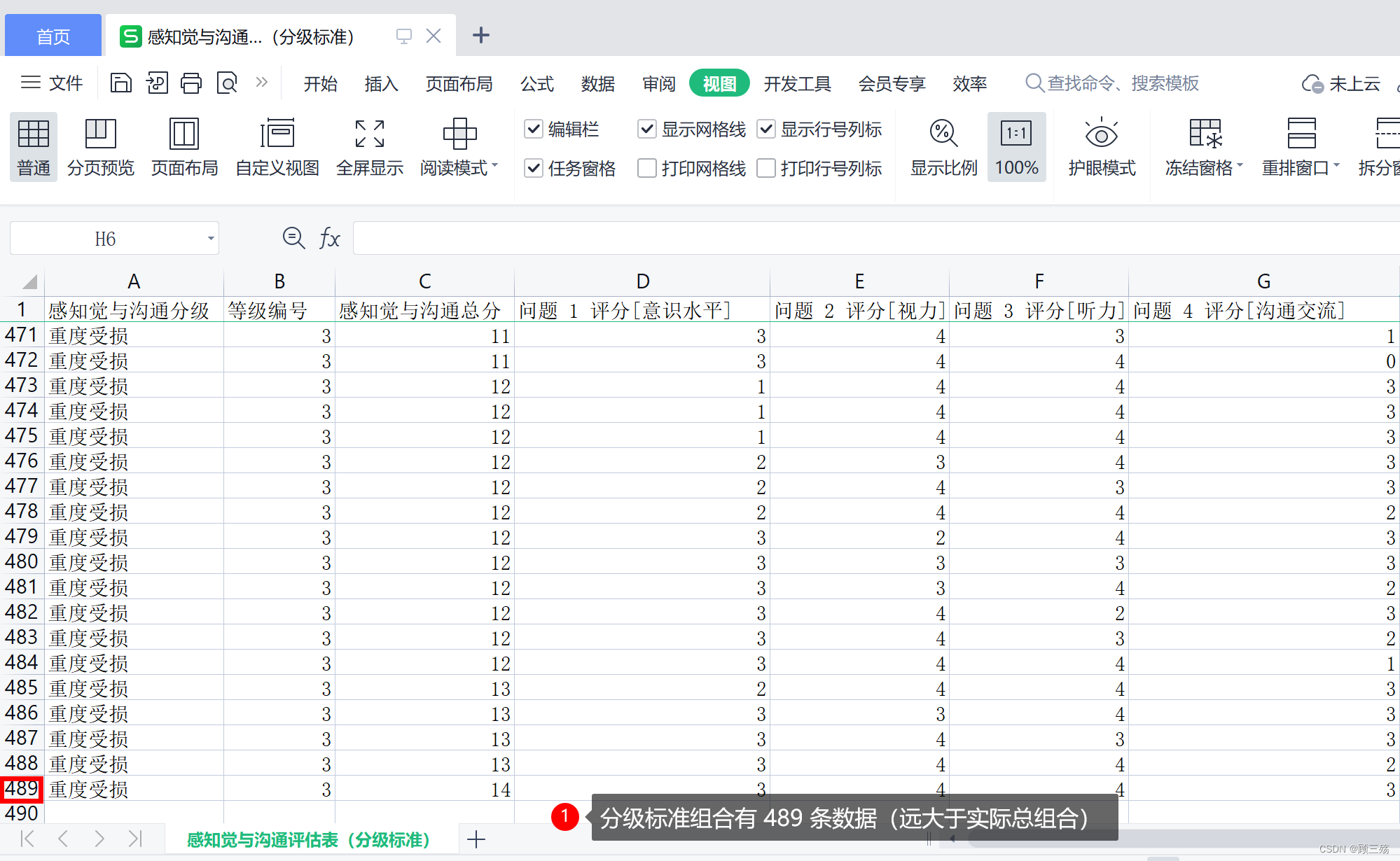
感知觉与沟通评估表(分级标准):基础表,这个是按分级标准生成的全部组合,里面存在重复组合,因为按照文字描述,会存在等级标准不一样,但是问题答案组合一样的情况,即一个组合多个等级归属,属于产品漏洞,需要产品修改需求,比如重复组合提示,由医生人工判断,或者修改等级标准为按总分数分级或者按某个重点问题选项分级,以便改为任意组合均有唯一的等级标准
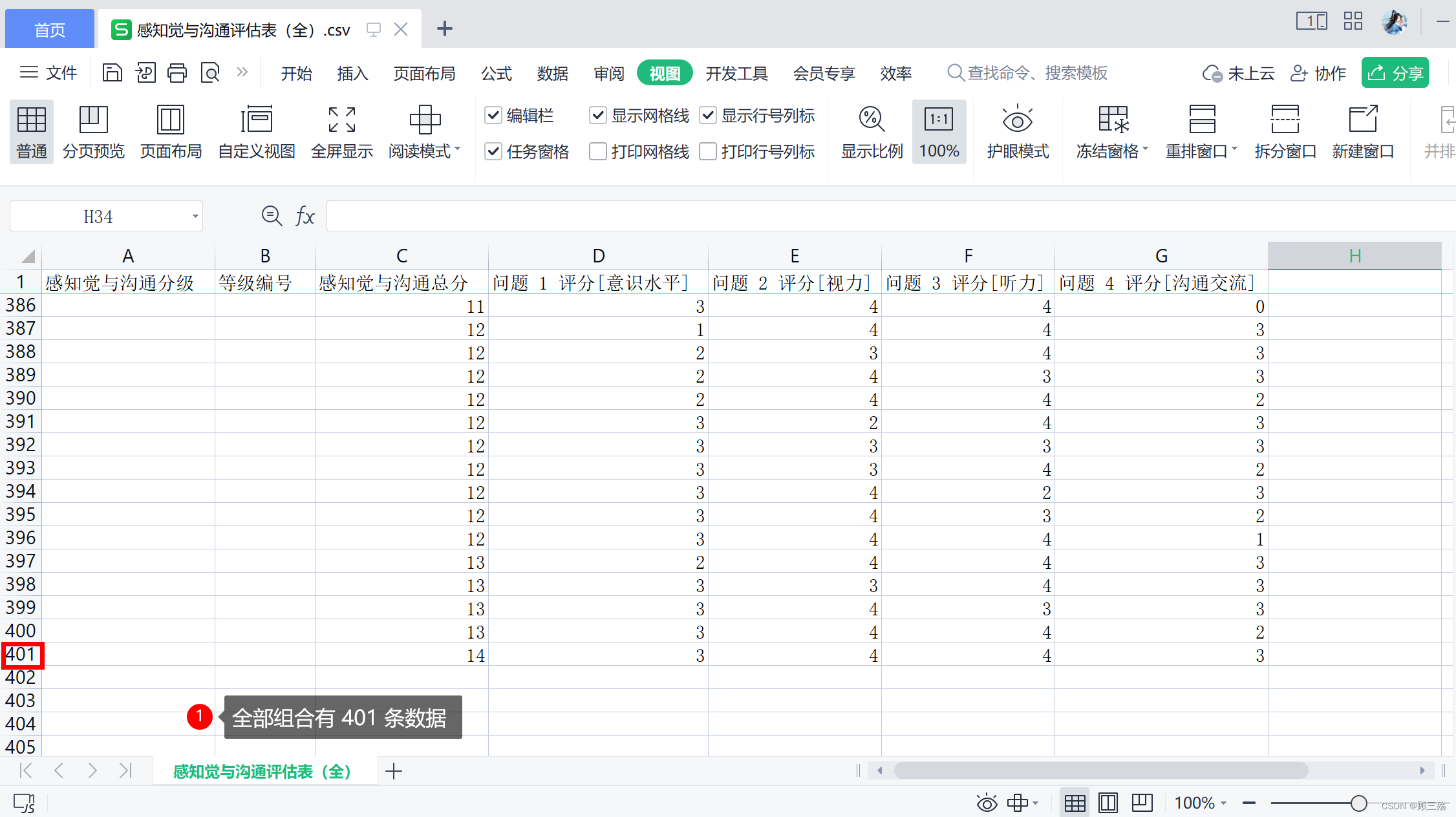
感知觉与沟通评估表(全):基础表,这个是按问题答案默认生成的全部组合,实际应该存在的最全组合,这个表没有等级标准归属,仅仅是笛卡尔积组合
感知觉与沟通评估表(分级组合相同):按照 “感知觉与沟通评估表(分级标准)” 过滤得到,按分级标准生成的重复组合独立新建的表
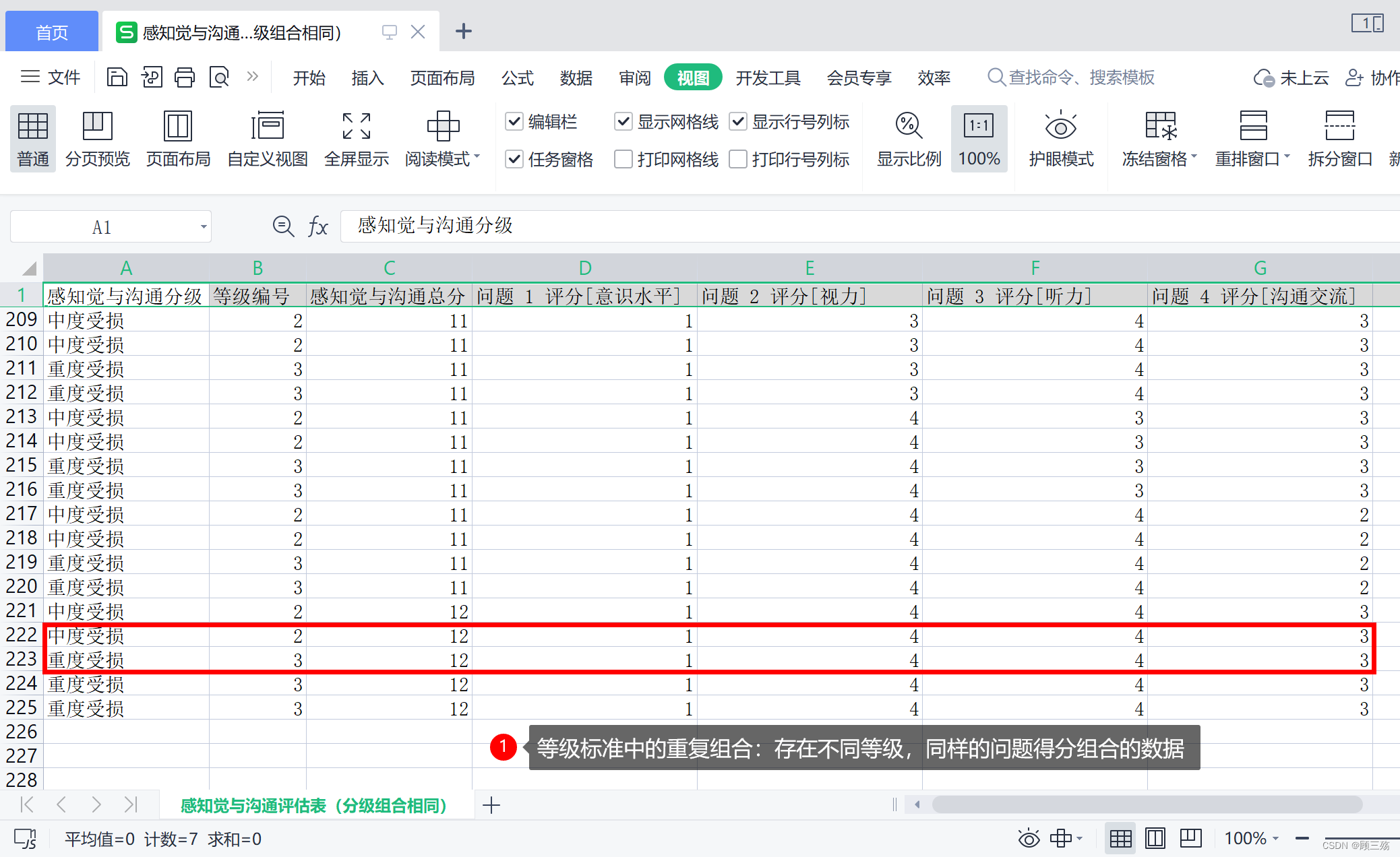
感知觉与沟通评估表(分级组合不同):按照 “感知觉与沟通评估表(分级标准)” 过滤得到,按分级标准生成的不同组合,相同组合仅留第 1 条,独立新建的表,不是最标准的组合,但可以过滤掉重复组合,也不是符合产品需求的处理办法,仅做参考
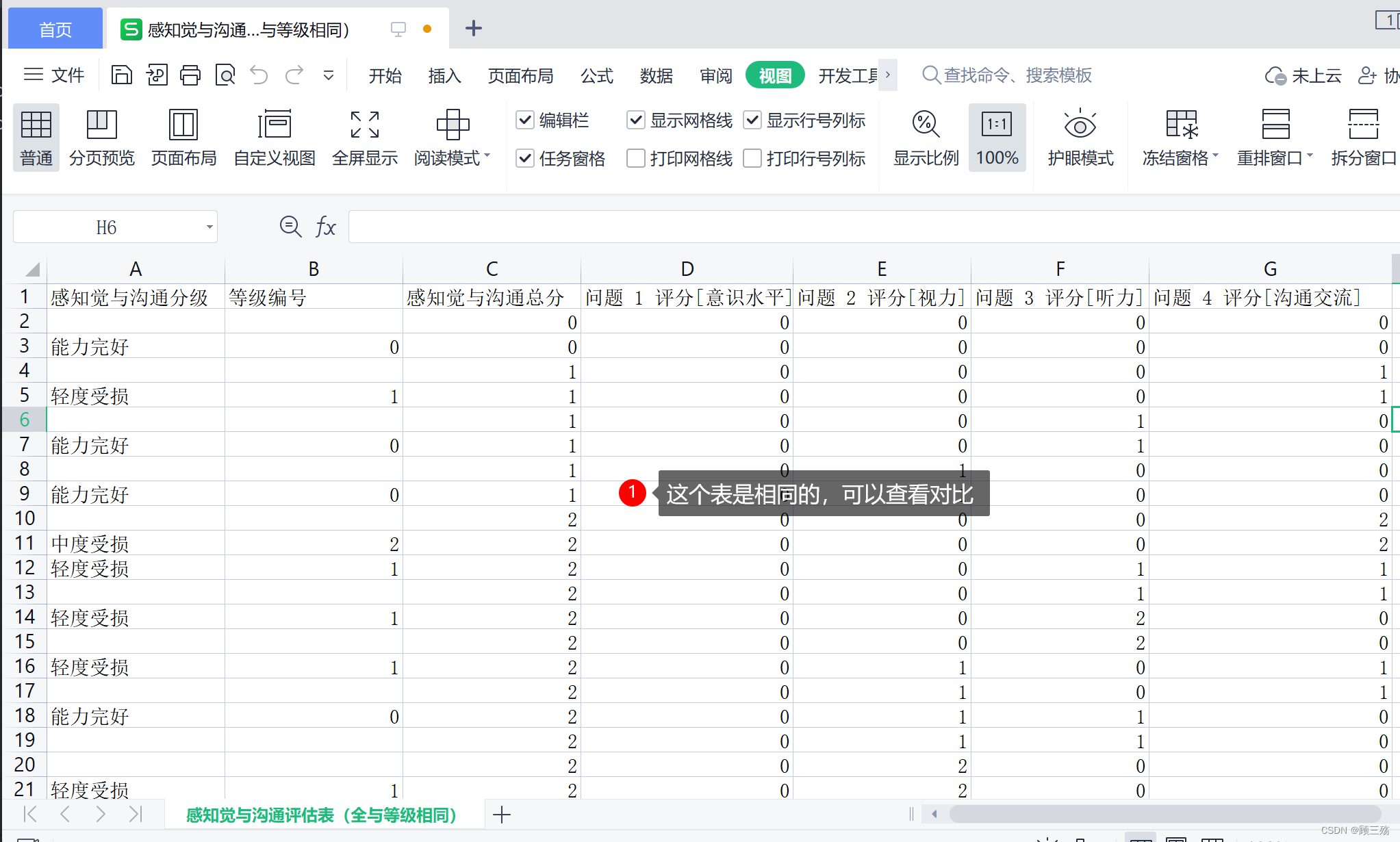
感知觉与沟通评估表(全与等级相同):按照 “感知觉与沟通评估表(分级标准)” 和 “感知觉与沟通评估表(全)” 过滤得到,取出两个表对比后的重复组合独立新建的表
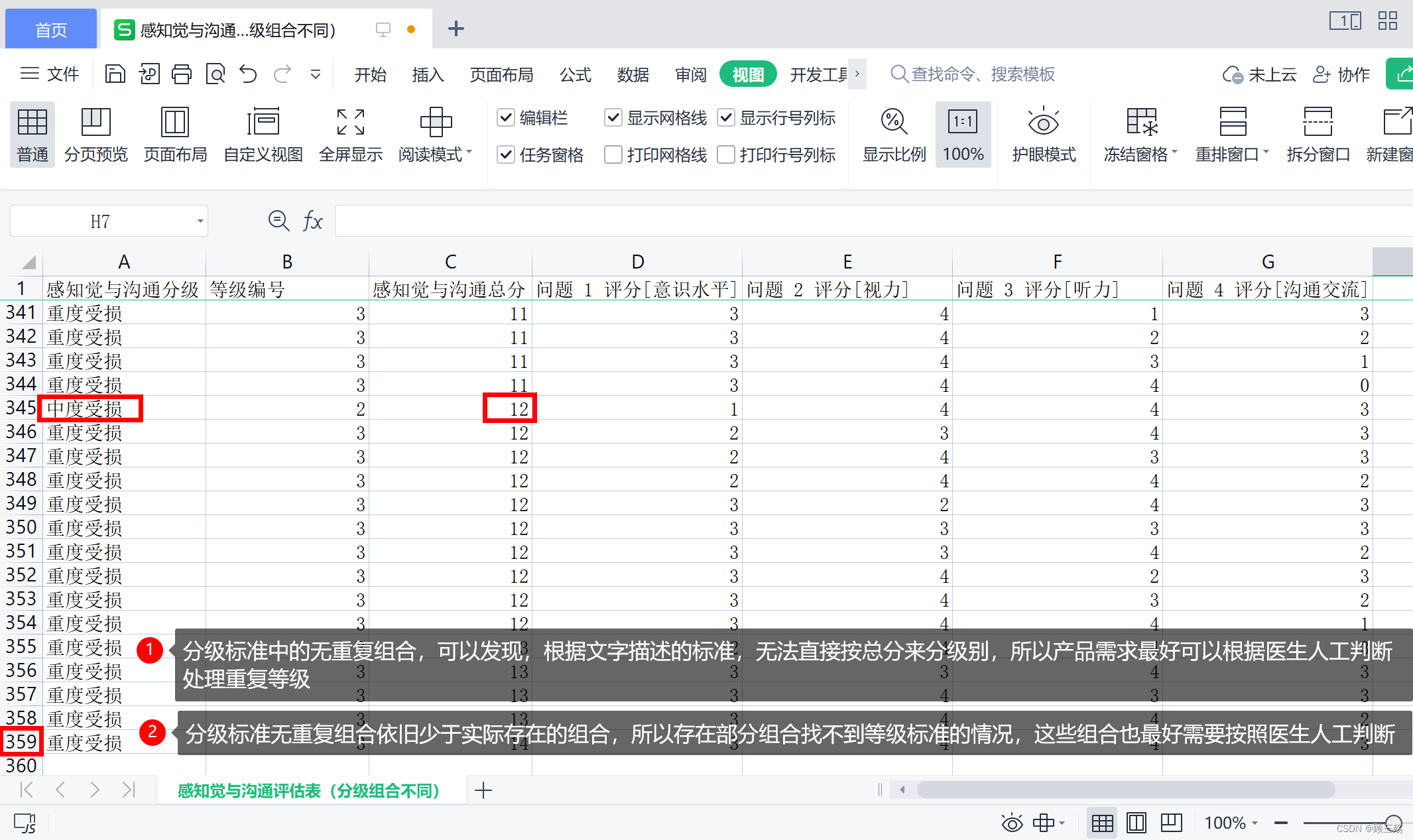
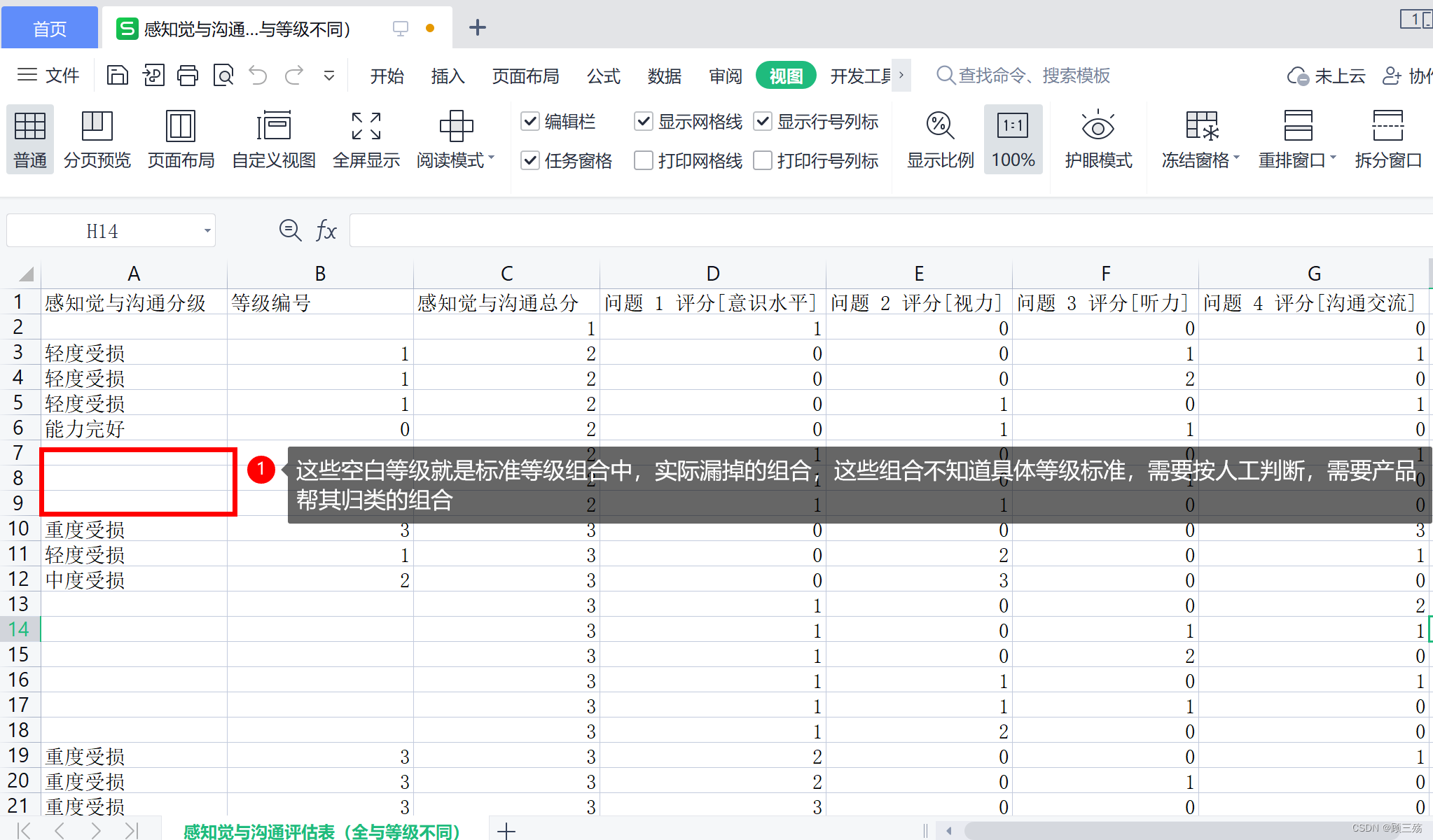
感知觉与沟通评估表(全与等级不同):按照 “感知觉与沟通评估表(分级标准)” 和 “感知觉与沟通评估表(全)” 过滤得到,取出两个表对比后的不同组合独立新建的表
示例表格结果如下,因篇幅限制展示不全,完整表格请用代码生成:
| 感知觉与沟通分级 | 等级编号 | 感知觉与沟通总分 | 问题 1 评分[意识水平] | 问题 2 评分[视力] | 问题 3 评分[听力] | 问题 4 评分[沟通交流] |
| 能力完好 | 0 | 0 | 0 | 0 | 0 | 0 |
| 能力完好 | 0 | 1 | 0 | 0 | 1 | 0 |
| 能力完好 | 0 | 1 | 0 | 1 | 0 | 0 |
| 能力完好 | 0 | 2 | 0 | 1 | 1 | 0 |
| 轻度受损 | 1 | 1 | 0 | 0 | 0 | 1 |
| 轻度受损 | 1 | 2 | 0 | 2 | 0 | 0 |
| 轻度受损 | 1 | 2 | 0 | 0 | 2 | 0 |
| 轻度受损 | 1 | 2 | 0 | 0 | 1 | 1 |
| 轻度受损 | 1 | 2 | 0 | 1 | 0 | 1 |
| 轻度受损 | 1 | 3 | 0 | 2 | 0 | 1 |
| 轻度受损 | 1 | 3 | 0 | 2 | 1 | 0 |
| 轻度受损 | 1 | 3 | 0 | 0 | 2 | 1 |
| 轻度受损 | 1 | 3 | 0 | 1 | 2 | 0 |
| 轻度受损 | 1 | 3 | 0 | 0 | 2 | 1 |
| 轻度受损 | 1 | 3 | 0 | 1 | 1 | 1 |
| 轻度受损 | 1 | 3 | 0 | 2 | 0 | 1 |
| 轻度受损 | 1 | 4 | 0 | 2 | 0 | 2 |
| 轻度受损 | 1 | 4 | 0 | 2 | 1 | 1 |
| 轻度受损 | 1 | 4 | 0 | 2 | 2 | 0 |
| 轻度受损 | 1 | 4 | 0 | 0 | 2 | 2 |
| 轻度受损 | 1 | 4 | 0 | 1 | 2 | 1 |
| 轻度受损 | 1 | 4 | 0 | 2 | 2 | 0 |
| 轻度受损 | 1 | 4 | 0 | 0 | 3 | 1 |
| 轻度受损 | 1 | 4 | 0 | 1 | 2 | 1 |
| 轻度受损 | 1 | 4 | 0 | 2 | 1 | 1 |
| 轻度受损 | 1 | 4 | 0 | 3 | 0 | 1 |
| 轻度受损 | 1 | 5 | 0 | 2 | 0 | 3 |
| 轻度受损 | 1 | 5 | 0 | 2 | 1 | 2 |
| 轻度受损 | 1 | 5 | 0 | 2 | 2 | 1 |
| 轻度受损 | 1 | 5 | 0 | 2 | 3 | 0 |
| 轻度受损 | 1 | 5 | 0 | 0 | 2 | 3 |
| 轻度受损 | 1 | 5 | 0 | 1 | 2 | 2 |
| 轻度受损 | 1 | 5 | 0 | 2 | 2 | 1 |
| 轻度受损 | 1 | 5 | 0 | 3 | 2 | 0 |
| 轻度受损 | 1 | 5 | 0 | 0 | 4 | 1 |
| 轻度受损 | 1 | 5 | 0 | 1 | 3 | 1 |
| 轻度受损 | 1 | 5 | 0 | 2 | 2 | 1 |
| 轻度受损 | 1 | 5 | 0 | 3 | 1 | 1 |
| 轻度受损 | 1 | 5 | 0 | 4 | 0 | 1 |
| 轻度受损 | 1 | 6 | 0 | 2 | 1 | 3 |
| 轻度受损 | 1 | 6 | 0 | 2 | 2 | 2 |
| 轻度受损 | 1 | 6 | 0 | 2 | 3 | 1 |
| 轻度受损 | 1 | 6 | 0 | 2 | 4 | 0 |
| 轻度受损 | 1 | 6 | 0 | 1 | 2 | 3 |
| 轻度受损 | 1 | 6 | 0 | 2 | 2 | 2 |
| 轻度受损 | 1 | 6 | 0 | 3 | 2 | 1 |
| 轻度受损 | 1 | 6 | 0 | 4 | 2 | 0 |
| 轻度受损 | 1 | 6 | 0 | 1 | 4 | 1 |
| 轻度受损 | 1 | 6 | 0 | 2 | 3 | 1 |
| 感知觉与沟通分级 | 等级编号 | 感知觉与沟通总分 | 问题 1 评分[意识水平] | 问题 2 评分[视力] | 问题 3 评分[听力] | 问题 4 评分[沟通交流] |
| 0 | 0 | 0 | 0 | 0 | ||
| 1 | 0 | 0 | 0 | 1 | ||
| 1 | 0 | 0 | 1 | 0 | ||
| 1 | 0 | 1 | 0 | 0 | ||
| 1 | 1 | 0 | 0 | 0 | ||
| 2 | 0 | 0 | 0 | 2 | ||
| 2 | 0 | 0 | 1 | 1 | ||
| 2 | 0 | 0 | 2 | 0 | ||
| 2 | 0 | 1 | 0 | 1 | ||
| 2 | 0 | 1 | 1 | 0 | ||
| 2 | 0 | 2 | 0 | 0 | ||
| 2 | 1 | 0 | 0 | 1 | ||
| 2 | 1 | 0 | 1 | 0 | ||
| 2 | 1 | 1 | 0 | 0 | ||
| 2 | 2 | 0 | 0 | 0 | ||
| 3 | 0 | 0 | 0 | 3 | ||
| 3 | 0 | 0 | 1 | 2 | ||
| 3 | 0 | 0 | 2 | 1 | ||
| 3 | 0 | 0 | 3 | 0 | ||
| 3 | 0 | 1 | 0 | 2 | ||
| 3 | 0 | 1 | 1 | 1 | ||
| 3 | 0 | 1 | 2 | 0 | ||
| 3 | 0 | 2 | 0 | 1 | ||
| 3 | 0 | 2 | 1 | 0 | ||
| 3 | 0 | 3 | 0 | 0 | ||
| 3 | 1 | 0 | 0 | 2 | ||
| 3 | 1 | 0 | 1 | 1 | ||
| 3 | 1 | 0 | 2 | 0 | ||
| 3 | 1 | 1 | 0 | 1 | ||
| 3 | 1 | 1 | 1 | 0 | ||
| 3 | 1 | 2 | 0 | 0 | ||
| 3 | 2 | 0 | 0 | 1 | ||
| 3 | 2 | 0 | 1 | 0 | ||
| 3 | 2 | 1 | 0 | 0 | ||
| 3 | 3 | 0 | 0 | 0 | ||
| 4 | 0 | 0 | 1 | 3 | ||
| 4 | 0 | 0 | 2 | 2 | ||
| 4 | 0 | 0 | 3 | 1 | ||
| 4 | 0 | 0 | 4 | 0 | ||
| 4 | 0 | 1 | 0 | 3 | ||
| 4 | 0 | 1 | 1 | 2 | ||
| 4 | 0 | 1 | 2 | 1 | ||
| 4 | 0 | 1 | 3 | 0 | ||
| 4 | 0 | 2 | 0 | 2 | ||
| 4 | 0 | 2 | 1 | 1 | ||
| 4 | 0 | 2 | 2 | 0 | ||
| 4 | 0 | 3 | 0 | 1 | ||
| 4 | 0 | 3 | 1 | 0 | ||
| 4 | 0 | 4 | 0 | 0 |
| 感知觉与沟通分级 | 等级编号 | 感知觉与沟通总分 | 问题 1 评分[意识水平] | 问题 2 评分[视力] | 问题 3 评分[听力] | 问题 4 评分[沟通交流] |
| 轻度受损 | 1 | 3 | 0 | 0 | 2 | 1 |
| 轻度受损 | 1 | 3 | 0 | 0 | 2 | 1 |
| 轻度受损 | 1 | 3 | 0 | 2 | 0 | 1 |
| 轻度受损 | 1 | 3 | 0 | 2 | 0 | 1 |
| 轻度受损 | 1 | 4 | 0 | 0 | 2 | 2 |
| 中度受损 | 2 | 4 | 0 | 0 | 2 | 2 |
| 轻度受损 | 1 | 4 | 0 | 0 | 3 | 1 |
| 中度受损 | 2 | 4 | 0 | 0 | 3 | 1 |
| 轻度受损 | 1 | 4 | 0 | 1 | 2 | 1 |
| 轻度受损 | 1 | 4 | 0 | 1 | 2 | 1 |
| 轻度受损 | 1 | 4 | 0 | 2 | 0 | 2 |
| 中度受损 | 2 | 4 | 0 | 2 | 0 | 2 |
| 轻度受损 | 1 | 4 | 0 | 2 | 1 | 1 |
| 轻度受损 | 1 | 4 | 0 | 2 | 1 | 1 |
| 轻度受损 | 1 | 4 | 0 | 2 | 2 | 0 |
| 轻度受损 | 1 | 4 | 0 | 2 | 2 | 0 |
| 轻度受损 | 1 | 4 | 0 | 3 | 0 | 1 |
| 中度受损 | 2 | 4 | 0 | 3 | 0 | 1 |
| 轻度受损 | 1 | 5 | 0 | 0 | 2 | 3 |
| 感知觉与沟通分级 | 等级编号 | 感知觉与沟通总分 | 问题 1 评分[意识水平] | 问题 2 评分[视力] | 问题 3 评分[听力] | 问题 4 评分[沟通交流] |
| 能力完好 | 0 | 0 | 0 | 0 | 0 | 0 |
| 轻度受损 | 1 | 1 | 0 | 0 | 0 | 1 |
| 能力完好 | 0 | 1 | 0 | 0 | 1 | 0 |
| 能力完好 | 0 | 1 | 0 | 1 | 0 | 0 |
| 中度受损 | 2 | 2 | 0 | 0 | 0 | 2 |
| 轻度受损 | 1 | 2 | 0 | 0 | 1 | 1 |
| 轻度受损 | 1 | 2 | 0 | 0 | 2 | 0 |
| 轻度受损 | 1 | 2 | 0 | 1 | 0 | 1 |
| 能力完好 | 0 | 2 | 0 | 1 | 1 | 0 |
| 轻度受损 | 1 | 2 | 0 | 2 | 0 | 0 |
| 重度受损 | 3 | 2 | 2 | 0 | 0 | 0 |
| 重度受损 | 3 | 3 | 0 | 0 | 0 | 3 |
| 中度受损 | 2 | 3 | 0 | 0 | 1 | 2 |
| 轻度受损 | 1 | 3 | 0 | 0 | 2 | 1 |
| 中度受损 | 2 | 3 | 0 | 0 | 3 | 0 |
| 中度受损 | 2 | 3 | 0 | 1 | 0 | 2 |
| 轻度受损 | 1 | 3 | 0 | 1 | 1 | 1 |
| 轻度受损 | 1 | 3 | 0 | 1 | 2 | 0 |
| 轻度受损 | 1 | 3 | 0 | 2 | 0 | 1 |
| 感知觉与沟通分级 | 等级编号 | 感知觉与沟通总分 | 问题 1 评分[意识水平] | 问题 2 评分[视力] | 问题 3 评分[听力] | 问题 4 评分[沟通交流] |
| 0 | 0 | 0 | 0 | 0 | ||
| 能力完好 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | ||
| 轻度受损 | 1 | 1 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 | ||
| 能力完好 | 0 | 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 0 | ||
| 能力完好 | 0 | 1 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 0 | 2 | ||
| 中度受损 | 2 | 2 | 0 | 0 | 0 | 2 |
| 轻度受损 | 1 | 2 | 0 | 0 | 1 | 1 |
| 2 | 0 | 0 | 1 | 1 | ||
| 轻度受损 | 1 | 2 | 0 | 0 | 2 | 0 |
| 2 | 0 | 0 | 2 | 0 | ||
| 轻度受损 | 1 | 2 | 0 | 1 | 0 | 1 |
| 2 | 0 | 1 | 0 | 1 | ||
| 能力完好 | 0 | 2 | 0 | 1 | 1 | 0 |
| 2 | 0 | 1 | 1 | 0 | ||
| 2 | 0 | 2 | 0 | 0 | ||
| 轻度受损 | 1 | 2 | 0 | 2 | 0 | 0 |
| 感知觉与沟通分级 | 等级编号 | 感知觉与沟通总分 | 问题 1 评分[意识水平] | 问题 2 评分[视力] | 问题 3 评分[听力] | 问题 4 评分[沟通交流] |
| 1 | 1 | 0 | 0 | 0 | ||
| 轻度受损 | 1 | 2 | 0 | 0 | 1 | 1 |
| 轻度受损 | 1 | 2 | 0 | 0 | 2 | 0 |
| 轻度受损 | 1 | 2 | 0 | 1 | 0 | 1 |
| 能力完好 | 0 | 2 | 0 | 1 | 1 | 0 |
| 2 | 1 | 0 | 0 | 1 | ||
| 2 | 1 | 0 | 1 | 0 | ||
| 2 | 1 | 1 | 0 | 0 | ||
| 重度受损 | 3 | 3 | 0 | 0 | 0 | 3 |
| 轻度受损 | 1 | 3 | 0 | 2 | 0 | 1 |
| 中度受损 | 2 | 3 | 0 | 3 | 0 | 0 |
| 3 | 1 | 0 | 0 | 2 | ||
| 3 | 1 | 0 | 1 | 1 | ||
| 3 | 1 | 0 | 2 | 0 | ||
| 3 | 1 | 1 | 0 | 1 | ||
| 3 | 1 | 1 | 1 | 0 | ||
| 3 | 1 | 2 | 0 | 0 | ||
| 重度受损 | 3 | 3 | 2 | 0 | 0 | 1 |
| 重度受损 | 3 | 3 | 2 | 0 | 1 | 0 |
| 重度受损 | 3 | 3 | 3 | 0 | 0 | 0 |
| 轻度受损 | 1 | 4 | 0 | 1 | 2 | 1 |
| 4 | 0 | 1 | 3 | 0 | ||
| 重度受损 | 3 | 4 | 1 | 0 | 0 | 3 |






![[2021.11.9]lighteffect架构优化详细设计文档](https://img-blog.csdnimg.cn/b53a6e66ede848ea85d5a4c8a4570bfa.png)