来源 | 新智元 微信号:AI-era
先是ChatGPT的发布给世界带来了一点小小的NLP震撼,随后发布的GPT-4更是破圈计算机视觉,展现了非凡的多模态能力。
不光能读懂人类的梗,给个手绘草图甚至可以直接写出网站的代码,彻底颠覆了对语言模型、视觉模型能力边界的认知。

GPT-4:图里的这个「Lighting充电线」,看起来就是个又大又过气的VGA接口,插在这个又小又现代的智能手机上,反差强烈。
不过像GPT-4这么好的模型,CloseAI选择闭源,让广大AI从业者实在是又爱又恨。
最近,来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队开源了GPT-4的平民版MiniGPT-4,从效果上看已经基本具备GPT-4所展现出的多个功能,包括手写网页示意图生成代码、解读图像中的梗等。

论文链接:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
项目链接:https://minigpt-4.github.io/
代码链接:https://github.com/Vision-CAIR/MiniGPT-4
想要本地部署,一行代码即可搞定!
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml默认加载选项为8bit Vicuna模型以节省GPU内存,beam search的宽度为1,大约需要23G显存。
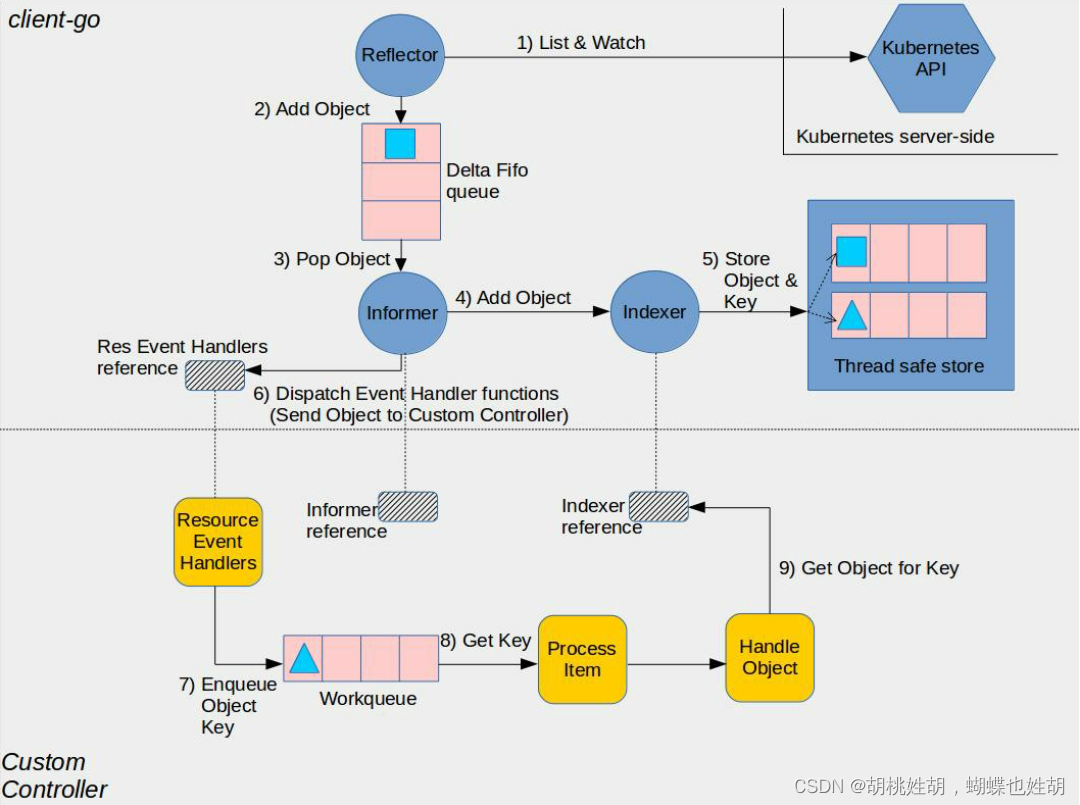
为了实现有效的MiniGPT-4,研究人员提出了一个两阶段的训练方法,先在大量对齐的图像-文本对上对模型进行预训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。
文中的研究结果表明,MiniGPT-4具有许多与 GPT-4类似的能力,如通过手写草稿生成详细的图像描述和创建网站;还可以观察到 MiniGPT-4的其他新功能,包括根据给定的图像创作故事和诗歌,为图像中显示的问题提供解决方案,教用户如何根据食物照片烹饪等。
论文作者朱德尧来自泉州,目前是阿卜杜拉国王科技大学(KAUST)的博士生,主要研究方向包括多模态大语言模型、预测模型和强化学习。
论文共同一作Jun Chen目前是阿卜杜拉国王科技大学 Vision-CAIR 研究小组的博士生,主要研究方向为多模态学习、自监督学习和大规模预训练模型。
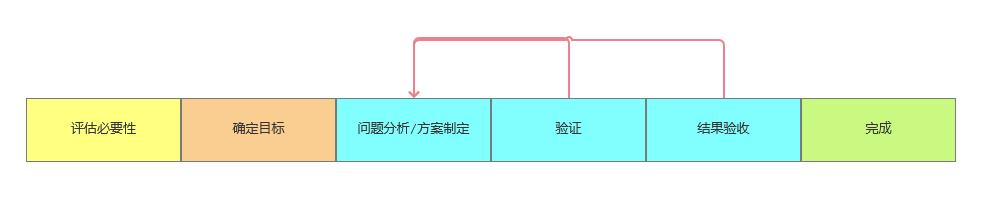
MiniGPT-4模型架构
研究人员认为,「GPT-4强大的多模态生成能力主要来自于更强的语言模型」。
为了验证这点,研究人员选择固定住语言模型和视觉模型的参数,然后只用投影层将二者对齐:MiniGPT-4的语言解码器使用Vicuna(基于LLaMA构建),视觉感知部分使用与BLIP-2相同的视觉编码器。
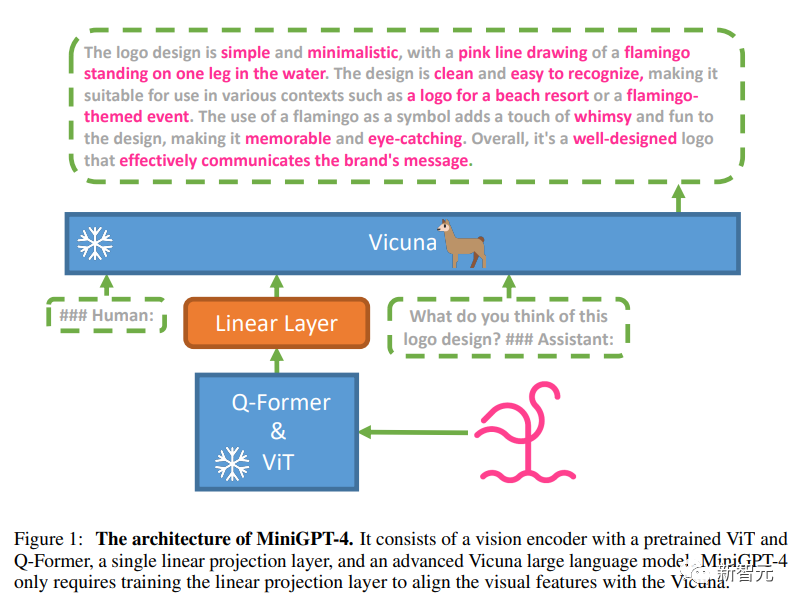
1. 预训练阶段
为了从大量对齐的图像-文本对中获取视觉-语言知识,研究人员把注入投影层的输出看作是对语言模型的软提示(soft prompt),促使它生成相应的ground-truth文本;并且预训练的视觉编码器和视觉编码器在预训练阶段始终保持参数不变,只训练线性投影层。
训练数据集包括Conceptual Caption, SBU和LAION,使用4张A100(共80GB显存) GPU以256的batch size训练了20000步,覆盖了大约500万个图像-文本对。
虽然在预训练后,MiniGPT-4已经展现了丰富的知识,并能够对人类的query提供合理的回复。
不过还是可以观察到MiniGPT-4仍然很难生成连贯的语言输出,比如经常会生成重复的词或句子、零散的句子或不相关的内容,这些问题也阻碍了MiniGPT-4与人类进行流畅的视觉对话的能力。
还可以注意到GPT-3也存在类似的问题:即便在大量的语言数据集上进行了预训练,GPT-3还是不能直接生成符合用户意图的语言输出;但通过指令微调和从人类反馈中进行强化学习的过程后,GPT-3就成功蜕变为了GPT-3.5,并能够生成对人类更友好的输出。
所以只对MiniGPT-4进行预训练是不够的。
2. 高质量的视觉-语言对齐数据集
虽然在自然语言处理领域,指令微调数据集和对话相关数据集很容易获得,但对于视觉语言领域来说,并不存在对应的数据集,所以为了让MiniGPT-4在生成文本时更自然、更有用,还需要设计一个高质量的、对齐的图像-文本数据集。
在初始阶段,使用预训练后得到的模型来生成对给定图像的描述,为了使模型能够生成更详细的图像描述,研究人员还设计了一个符合Vicuna语言模型的对话格式的提示符。
###Human: <Img><ImageFeature></Img> Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
其中<ImageFeature>表示线性投影层生成的视觉特征,如果生成的描述不足80个tokens,就添加额外的提示符「#Human:Continue#Assistant:」继续生成。
最后从Conceptual Caption中随机选择了5000幅图像,并生成对应的描述。
数据后处理
目前生成的图像描述仍然包含许多噪音和错误,如重复的单词、不连贯的句子等,研究人员使用ChatGPT来完善描述。
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
修正给定段落中的错误。删除重复的句子、无意义的字符、不是英语的句子等等。删除不必要的重复。重写不完整的句子。直接返回结果,无需解释。如果输入的段落已经正确,则直接返回,无需解释。
最后为了保证数据质量,手动验证每个图像描述的正确性,并得到了3500个图像-文本对。
3. 微调阶段
研究人员使用预定义的模板提示来优化预训练模型。
###Human: <Img><ImageFeature></Img> <Instruction> ###Assistant
其中<Instruction>表示从预定义指令集中随机抽样的指令,包含各种形式的指令,例如「详细描述此图像」或「您能为我描述此图像的内容吗」等。
需要注意的是,微调阶段没有计算特定文本-图像提示的回归损失,所以可以生成更自然、可靠的回复。
MiniGPT-4的微调过程非常高效,batch size为12的话,只需要400个训练步,使用单个A100 GPU训练7分钟即可。
示例
MiniGPT-4表现出了与GPT-4类似的多模态能力。
给一张图片,可以让模型生成非常详细的图像描述。

识别图像中的梗,比如解释「一到周一,人就像图里的小狗一样,一周中最令人恐惧的一天」。

还可以发现图像中不寻常的内容,比如「狼和小羊在同一片草地」。

还可以根据手绘图生成一个网站的代码。

MiniGPT-4还可以识别图像中的问题并提供解决方案,比如「洗衣机冒出了大量泡泡」是因为过载等原因,可以检查洗衣液是不是放多了、清理一下排水管或是看看洗衣机是不是坏了。

创作以图像为主题的诗歌或说唱歌曲。
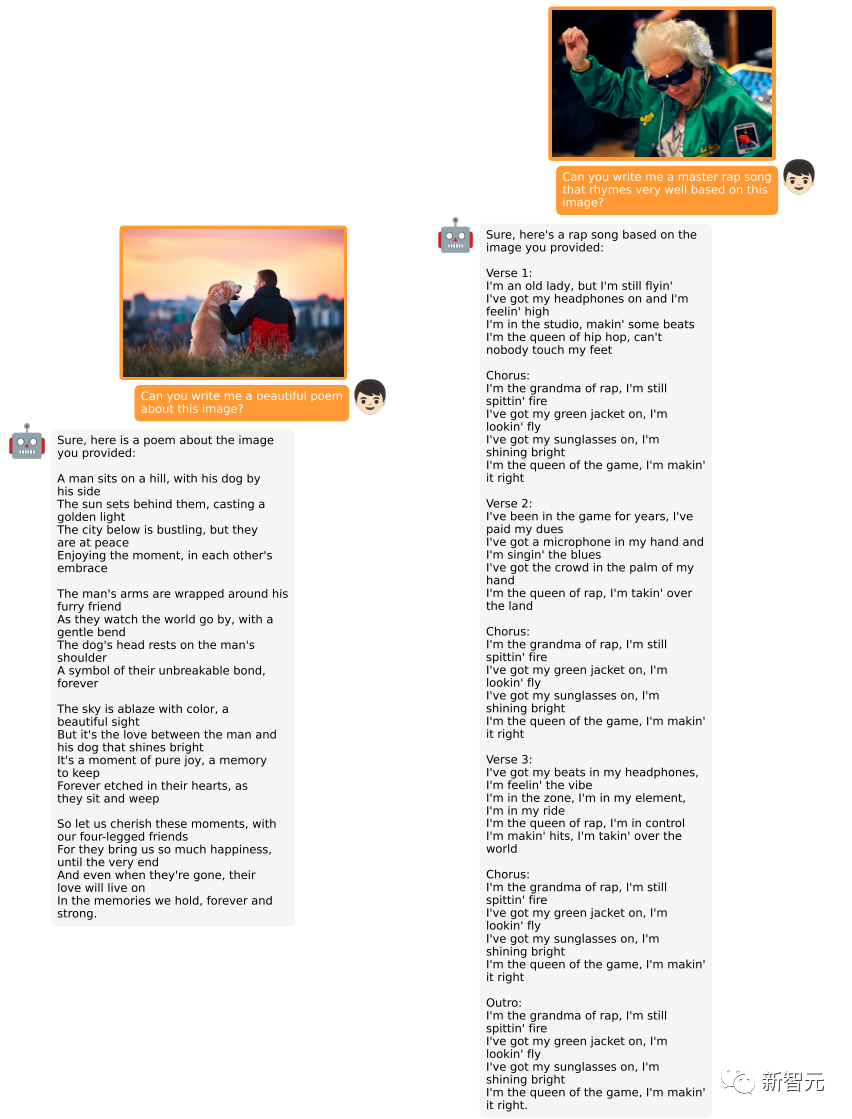
编写图像背后的故事。

为图像中的产品写广告词。

甚至还可以知道换头表情包里的人是Tesla和Space X的CEO马斯克。

提供一些有深度的图像评论。

检索与图像相关的事实,比如给个《教父》的截图就可以让模型检索到对应的电影信息。

甚至给个食物的照片,可以让模型输出一份菜谱。
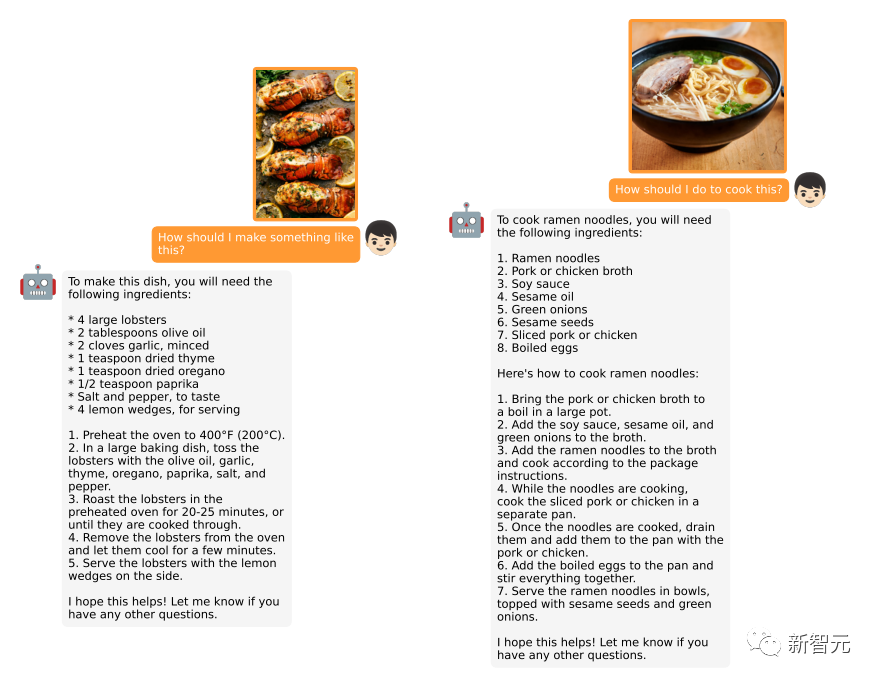
更多强大的功能等你解锁!
参考资料:
https://minigpt-4.github.io/