一、HashMap是什么
HashMap是一个存储key-value键值对的哈希表,表中每个元素的key都是唯一的(通过equals方法判断),查询时通过key的hashcode值即可定位到元素的存储地址,因此HashMap在理想情况下查询时间复杂度为O(1)
二、HashMap底层原理
1. 存储下标计算方法
HashMap底层通过Entry数组来存储元素,插入元素和查询元素时首先需要计算元素在数组中的存储下标,方法如下:
- 通过key的hashCode()方法获取其hashcode值
- 将这个hashcode值再通过hash()方法进行计算得到值h。这个方法会使最终获取的存储位置尽量分布均匀
- 最后将这个h值和length-1进行与运算得到最终的存储下标

2. 哈希冲突
但是由于数组长度有限,不同哈希值计算出的存储下标可能会相同,这就是哈希冲突。通过拉链法解决。
解决哈希冲突的本质就是在哈希冲突后,即计算出的存储下标已经有元素了,如何确定下一个可能的位置。
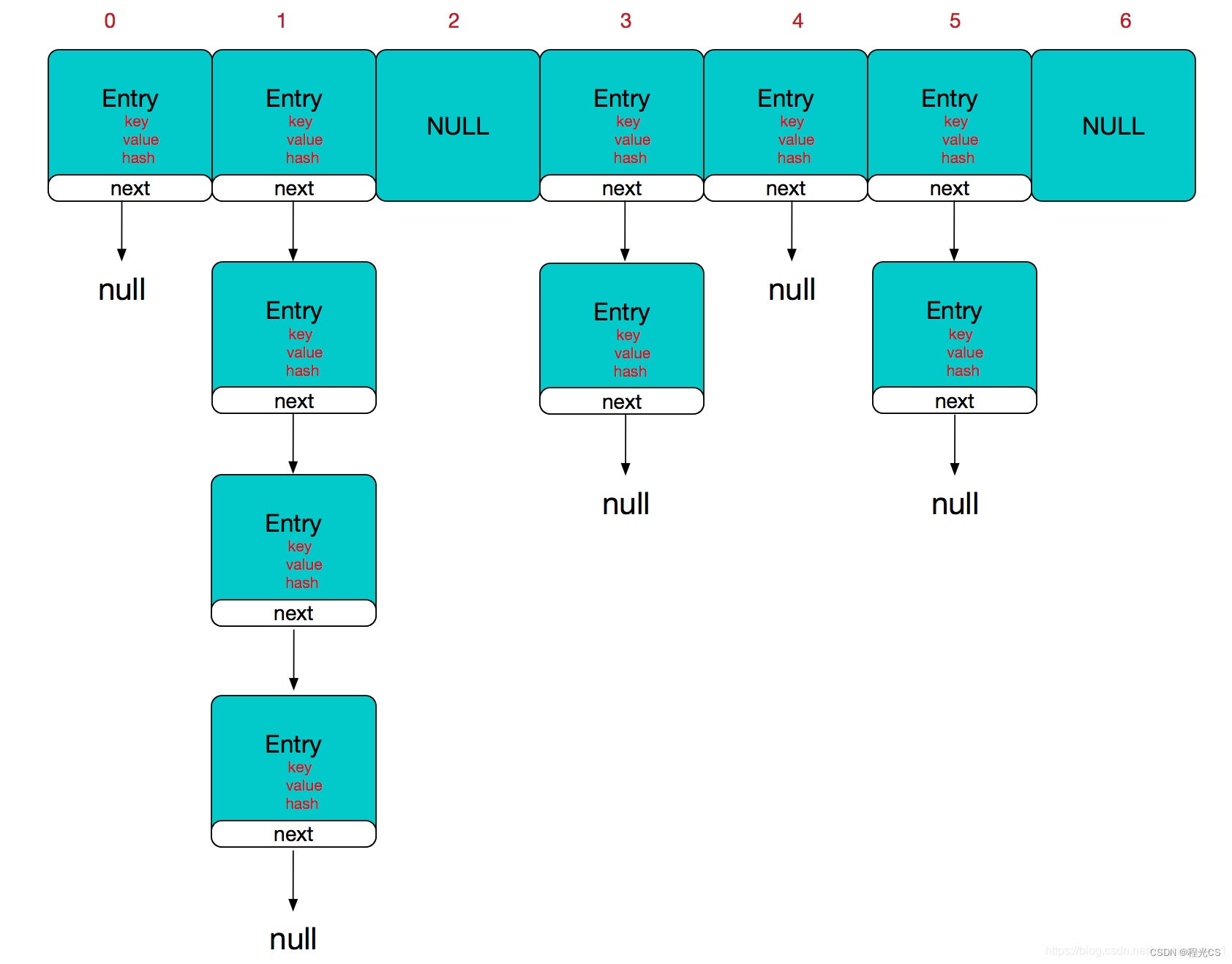
3. 扩容机制
扩容机制:当HashMap中已使用容量达到负载因子*容量后,会调用resize()方法自动进行扩容,将容量扩大为原来的2倍,并重新计算元素在数组中的位置,然后将元素复制到新数组中。
(1)为什么负载因子设计为0.75?
如果负载因子设计大了,则容易发生哈希冲突降低效率,如果设计小了,则不能充分利用空间,0.75这个值是通过数学中的泊松分布计算出来的,在“冲突的概率”与“空间利用率”之间可以达到一个最好的平衡折中。
(2)为何HashMap的数组长度一定是2的次幂?
数组长度设计为2的次幂主要是为了优化取模运算,在最后计算存储下标时如果通过h % length取模来计算存储下标的话效率不高,如果数组长度为2的次幂,那么length-1的二进制的数值位就全为1,那么就可以像源码中那样通过与运算h & (length-1)来计算存储下标,效率更高。
三、JDK1.8中HashMap的性能优化 —— 红黑树
假如一个数组槽位上链上数据过多(即拉链过长的情况)导致性能下降该怎么办?
JDK1.8在JDK1.7的基础上针对增加了红黑树来进行优化。即当链表超过8时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。
参考:
- Java集合之一—HashMap
- https://blog.csdn.net/weixin_43591980/article/details/115490019