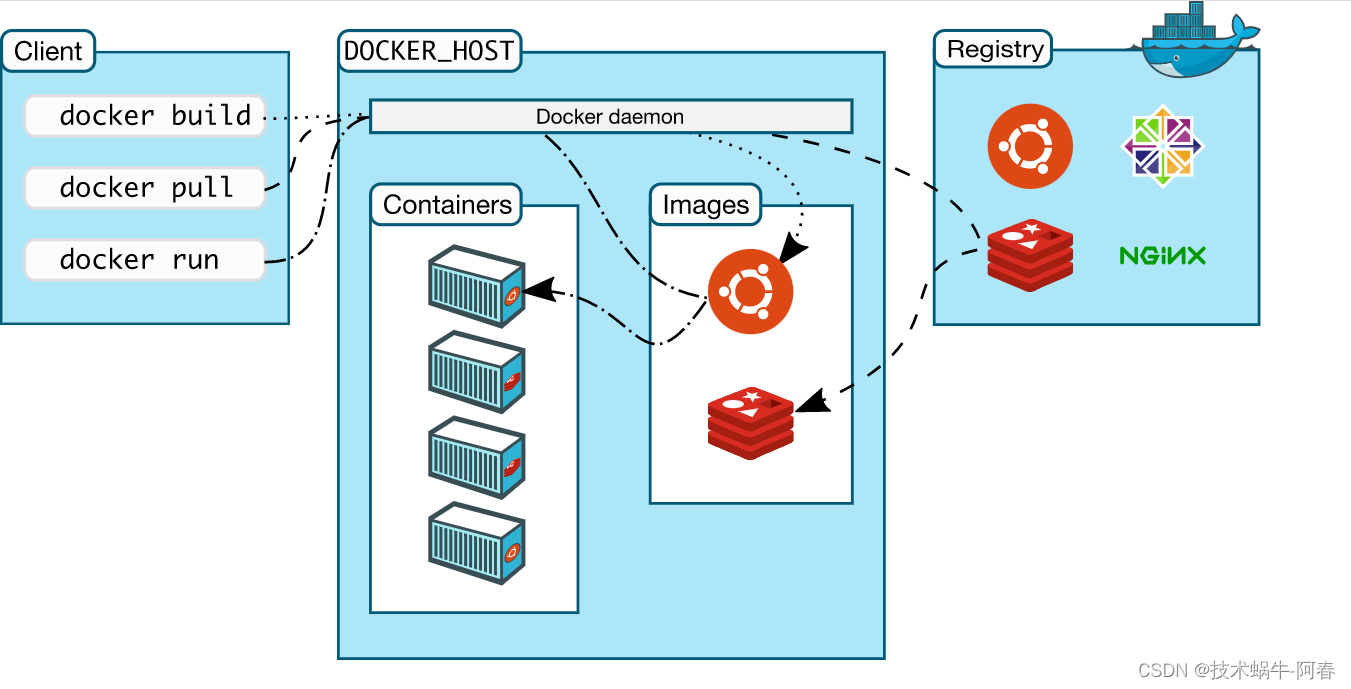
商城订单服务的实现
数据量
在设计系统,我们预估订单的数量每个月订单2000W,一年的订单数可达2.4亿。而每条订单的大小大致为1KB,按照我们在MySQL中学习到的知识,为了让B+树的高度控制在一定范围,保证查询的性能,每个表中的数据不宜超过2000W。在这种情况下,为了存下2.4亿的订单,我们似乎应该将订单表分为16(12往上取最近的2的幂)张表。
但是这样设计,有个问题,我们只考虑了订单表,没有考虑订单详情表。我们预估一张订单下的商品平均为10个,那既是一年的订单详情数可以达到24亿,同样以每表2000W记录计算,应该订单详情表为128(120往上取最近的2的幂)张,而订单表和订单详情表虽然记录数上是一对一的关系,但是表之间还是一对一,也就是说订单表也要为128张。经过再三分析,我们最终将订单表和订单详情表的张数定为32张。
这会导致订单详情表单表的数据量达到8000W,为何要这么设计呢?原因我们后面再说。
选择分片键
既然决定订单系统分库分表,则还有一个重要的问题,那就是如何选择一个合适的列作为分表的依据,该列我们一般称为分片键(Sharding Key)。选择合适的分片键和分片算法非常重要,因为其将直接影响分库分表的效果。
选择分片链有一个最重要的参考因素是我们的业务是如何访问数据的?
比如我们把订单ID作为分片键来诉分订单表。那么拆分之后,如果按照订单ID来查询订单,就需要先根据订单ID和分片算法,计算所要查的这个订单具体在哪个分片上,也就是哪个库的哪张表中,然后再去那个分片执行查询操作即可。
但是当用户打开“我的订单”这个页面的时候,它的查询条件是用户ID,由于这里没有订单ID,因此我们无法知道所要查询的订单具体在哪个分片上,也就没法查了。如果要强行查询的话,那就只能把所有的分片都查询一遍,再合并查询结果,这个过程比较麻烦,而且性能很差,对分页也很不友好。
那么如果是把用户ID作为分片键呢?答案是也会面临同样的问题,使用订单ID作为查询条件时无法定位到具体的分片上。
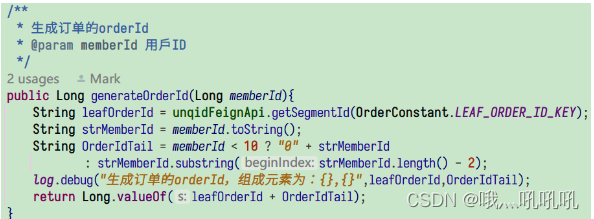
这个问题的解决办法是,在生成订单ID的时候,把用户ID的后几位作为订单ID的一部分。这样按订单ID查询的时候,就可以根据订单ID中的用户ID找到分片。 所以在我们的系统中订单ID从唯一ID服务获取ID后,还会将用户ID的后两位拼接,形成最终的订单ID。
然而,系统对订单的查询万式,肯定不只是按订单ID或按用户ID查询两种方式。比如如果有商家希望查询自家家店的订单,有与订单相关的各种报表。对订单做了分库分表,就没法解决了。这个问题又该怎么解决呢?
一般的做法是,把订单里数据同步到其他存储系统中,然后在其他存储系统里解决该问题。比如可以再构建一个以店铺ID作为分片键的只读订单库,专供商家使用。或者数据同步到Hadoop分布式文件系统(HDFS)中,然后通过一些大数据技术生成与订单相关的报表。
在分片算法上,我们知道常用的有按范围,比如时间范围分片,哈希分片,查表法分片。我们这里直接使用哈希分片,对表的个数32直接取模

一旦做了分库分表,就会极大地限制数据库的查询能力,原本很简单的查询,分库分表之后,可能就没法实现了。分库分表一定是在数据量和并发请求量大到所有招数都无效的情况下,我们才会采用的最后一招。
具体实现
如何在代码中实现读写分离和分库分表呢?一般来说有三种方法。
1)纯手工方式:修改应用程序的DAO层代码,定义多个数据源,在代码中需要访问数据库的每个地方指定每个数据库请求的数据源。
2)组件方式:使用像Sharding-JDBC 这些组件集成在应用程序内,用于代理应用程序的所有数据库请求,并把请求自动路由到对应的数据库实例上。
3)代理方式:在应用程序和数据库实例之间部署一组数据库代理实例,比如Atlas或Sharding-Proxy。对于应用程序来说,数据库代理把自己伪装成一个单节点的MySQL实例,应用程序的所有数据库请求都将发送给代理,代理分离请求,然后将分离后的请求转发给对应的数据库实例。
在这三种方式中一般推荐第二种,使用分离组件的方式。采用这种方式,代码侵入非常少,同时还能兼顾性能和稳定性。如果应用程序是一个逻辑非常简单的微服务,简单到只有几个SQL,或者应用程序使用的编程语言没有合适的读写分离组件,那么也可以考虑通过纯手工的方式。
不推荐使用代理方式(第三种方式),原因是代理方式加长了系统运行时数据库请求的调用链路,会浩成一定的性能损失,而且代理服务本身也可能会出现故障和性能瓶颈等问题。代理方式有一个好处,对应用程序完全透明。
在分片键的选择上,订单信息的查询往往会指定订单的ID或者用户ID,所以order的分片键为表中的id、member_id两个字段。而order_item表通过order_id字段和order的id进行关联,所以它的分片键选择为order_id。对应在代码中有专门的分片算法实现类:OrderShardingAlgorithm和OrderItemShardingAlgorithm,分别用于对订单和订单详情进行分片。
其中的OrderShardingAlgorithm负责对订单进行分片,在实现上获得订单的Id或者member_id的后两位,然后对表的个数进行取模以定位到实际的物理order表。OrderItemShardingAlgorithm负责对订单详情进行分片,实现上与OrderShardingAlgorithm类似。
MySQL应对海量数据
归档历史数据
订单数据会随着时间一直累积的数据,前面我们说过预估订单的数量每个月订单2000W,一年的订单数可达2.4亿,三年可达7.2亿。
数据量越大,数据库就会越慢,这是为什么?我们需要理解造成这个问题的根本原因。无论是“增、删、改、查”中的哪个操作,其本质都是查找数据,因为我们需要先找到数据,然后才能操作数据。
无论采用的是哪种存储系统,一次查询所耗费的时间,都取决于如下两个因素。
- 查找的时间复杂度
- 数据总量。
查找的时间复杂度又取决于如下两个因素。
- 查找算法。
- 存储数据的数据结构。
大多数做业务的系统,采用的都是现成的数据库,数据的存储结构和查找算法都是由数据库来实现的,对此,业务系统基本上无法做出任何改变。我们知道MySQL 的 InnoDB存储引擎,其存储结构是B+树,查找算法大多数时候是对树进行查找,查找的时间复杂度就是O(log n),这些都是固定的。我们唯一能改变的就是数据总量了。
所以,解决海量数据导致存储系统慢的问题,方法非常简单,就是一个“拆”字,把大数据拆分成若干份小数据,学名称为“分片”( Shard)。拆开之后,每个分片里的数据就没那么多了,然后让查找尽量落在某一个分片上,以此来提升查找性能。
存档历史订单数据
订单数据一般保存在MySQL 的订单表里,说到拆分MySQL 的表,前面我们不是已经将到了“分库分表”吗?其实分库分表很多的时候并不是首选的方案,应该先考虑归档历史数据。
以京东为例
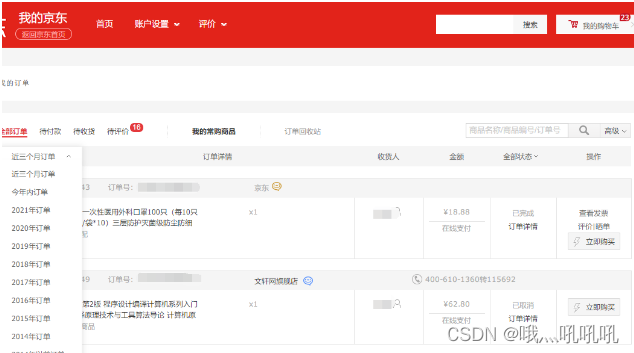
可以看到在“我的订单”中查询时,分为了近三个月订单、今年内订单、2021年订单、2020年订单等等,这就是典型的将订单数据归档处理。
所谓归档,也是一种拆分数据的策略。简单地说,就是把大量的历史订单移到另外一张历史订单表或数据存储中。为什这么做呢?订单数据有个特点:具备时间属性的,并且随着系统的运行,数据累计增长越来越多。但其实订单数据在使用上有个特点,最近的数据使用最频繁,超过一定时间的数据很少使用,这被称之为热尾效应。
因为新数据只占数据息量中很少的一部分,所以把新老数据分开之后,新数据的数据量就少很多,查询速度也会因此快很多。虽然与之前的总量相比,老数据没有减少太多,但是因为老数据很少会被访问到,所以即使慢一点儿也不会有太大的问题,而且还可以使用其他的存储系统提升查询速度。
这样拆分数据的另外一个好处是,拆分订单时,系统需要改动的代码非常少。对订单表的大部分操作都是在订单完成之前执行的,这些业务逻辑都是完全不用修改的。即使是像退货退款这类订单完成之后的操作,也是有时限的,这些业务逻辑也不需要修改,还是按照之前那样操作订单即可。
基本上只有查询统计类的功能会查到历史订单,这些都需要稍微做些调整。按照查询条件中的时间范围,选择去订单表还是历史订单中查询就可以了。很多大型互联网电商在逐步发展壮大的过程中,长达数年的时间采用的都是这种订单拆分的方案,正如我们前面看到的京东就是如此。
商城历史订单服务的实现
商城历史订单的归档由tulingmall-order-history服务负责,其中比较关键的是三个Service
既然是历史订单的归档,归档到哪里去呢?我们可以归档到另外的MySQL数据库,也可以归档到另外的存储系统,这个看自己的业务需求即可,在我们的系统中,我们选择归档到MongoDB数据库。
对于数据的迁移归档,我们总是在MySQL中保留3个月的订单数据,超过三个月的数据则迁出。前面我们说过,预估每月订单2000W,一张订单下的商品平均为10个,如果只保留3个月的数据,则订单详情数为6亿,分布到32个表中,每个表容纳的记录数刚好在2000W左右,这也是为什么前面的分库分表将订单表设定为32个的原因。
分布式事务?
考察迁移的过程,我们是逐表批次删除,对于每张订单表,先从MySQL从获得指定批量的数据,写入MongoDB,再从MySQL中删除已写入MongoDB的部分,这里存在着一个多源的数据操作,为了保证数据的一致性,看起来似乎需要分布式事务。但是其实这里并不需要分布式事务,解决的关键在于写入订单数据到MongoDB时,我们要记住同时写入当前迁入数据的最大订单ID,让这两个操作执行在同一个事务之中。
在MySQL执行数据迁移时,总是去MongoDB中获得上次处理的最大OrderId,作为本次迁移的查询起始ID
当然数据写入MongoDB后,还要记得删除MySQL中对应的数据。
在这个过程中,我们需要注意的问题是,尽量不要影响线上的业务。迁移如此大量的数据,或多或少都会影响数据库的性能,因此应该尽量选择在闲时迁移而且每次数据库操作的记录数不宜太多。按照一般的经验,对MySQL的操作的记录条数每次控制在10000一下是比较合适,在我们的系统中缺省是2000条。更重要的是,迁移之前一定要做好备份,这样的话,即使不小心误操作了,也能用备份来恢复。
如何批量删除大量数据
在迁移历史订单数据的过程中,还有一个很重要的细节间题:如何从订单表中删除已经迁走的历史订单数据?
虽然我们是按时间迁出订单表中的数据,但是删除最好还是按ID来删除,并且同样要控制住每次删除的记录条数,太大的数量容易遇到错误。
这样每次删除的时候,由于条件变成了主键比较,而在MySQL的InnoDB存储引擎中,表数据结构就是按照主键组织的一棵B+树,同时B+树本身就是有序的,因此优化后不仅查找变得非常快,而且也不需要再进行额外的排序操作了。
为什么要加一个排序的操作呢?因为按ID排序后,每批删除的记录基本上都是ID连续的一批记录,由于B+树的有序性,这些ID相近的记录,在磁盘的物理文件上,大致也是存放在一起的,这样删除效率会比较高,也便于MySQL回收页。
关于大批量删除数据,还有一个点需要注意一下,执行删除语句后,最好能停顿一小会,因为删除后肯定会牵涉到大量的B+树页面分裂和合并,这个时候MySQL的本身的负载就不小了,停顿一小会,可以让MySQL的负载更加均衡。