Grounded Action Transformation for Robot Learning in Simulation
发表于AAAI 2017
仿真机器人学习中的接地动作变换
Hanna J, Stone P. Grounded action transformation for robot learning in simulation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2017, 31(1).
介绍
接地模拟学习(Grounded Simulation Learning, GSL)框架:使用从现实环境中搜集的轨迹优化模拟环境,再使用优化后的模拟环境训练策略。该框架假设模拟器是可修改的。
GSL算法包含以下步骤:
- 在模拟环境中使用强化学习算法训练一个控制策略。
- 将该策略应用于物理机器人,并记录其执行过程中的状态和动作序列。
- 使用这些数据来校准模拟器,使其更好地匹配物理机器人的动力学特性。
- 重复步骤1-3,直到在模拟环境中训练出一个更好的控制策略。
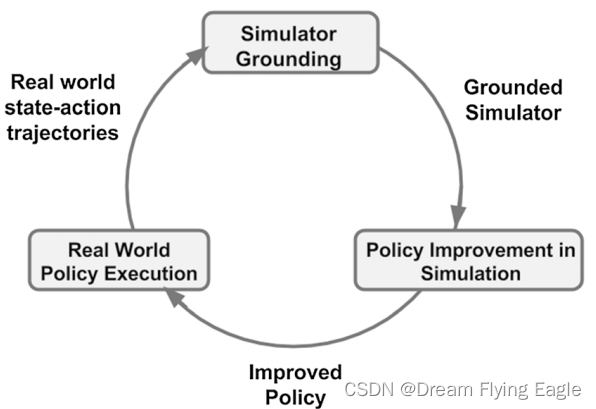
本文介绍了一种基于GSL框架的模拟器接地新算法——接地动作转换(Grounded Action Transformation, GAT)。用少量的真实世界和模拟数据来学习一个接地函数,允许模拟器在较少依赖人工系统识别的情况下进行修改。
此外,通过修改被模拟机器人的动作,他们可以将模拟器视为一个黑盒子,不需要访问模拟器的内部参数。
相关工作
他们将虚实迁移的文献分为四类:模拟器修改,模拟器随机化,模拟器作为先验知识,以及虚实感知学习。
模拟器修改:他们将尝试使用真实世界经验来修改模拟器。
模拟器作为先验知识:最初在模拟中进行训练,使用模拟器训练机器人的低维度行为(例如如何保持平衡),从而使机器人具有先验知识。然后在真实环境中进行最后一段学习,学习高维度动作。
方法
变换函数
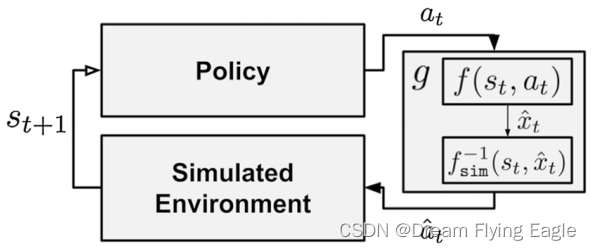
GAT算法学习两个函数
设 x x x 是状态分量 s s s 的子集,也就是对任务有突出贡献的状态向量。
设 X \mathcal{X} X 是所有 x x x 可能值的集合。
f : S × A → X f:\mathcal{S}\times\mathcal{A}\to\mathcal{X} f:S×A→X,它预测在现实环境中执行某动作对重要的状态变量的影响。
f s i m − 1 : S × X → A f^{-1}_{sim}:\mathcal{S}\times\mathcal{X}\to\mathcal{A} fsim−1:S×X→A,它预测在模拟环境中再现该效果所需的动作。
总变换函数
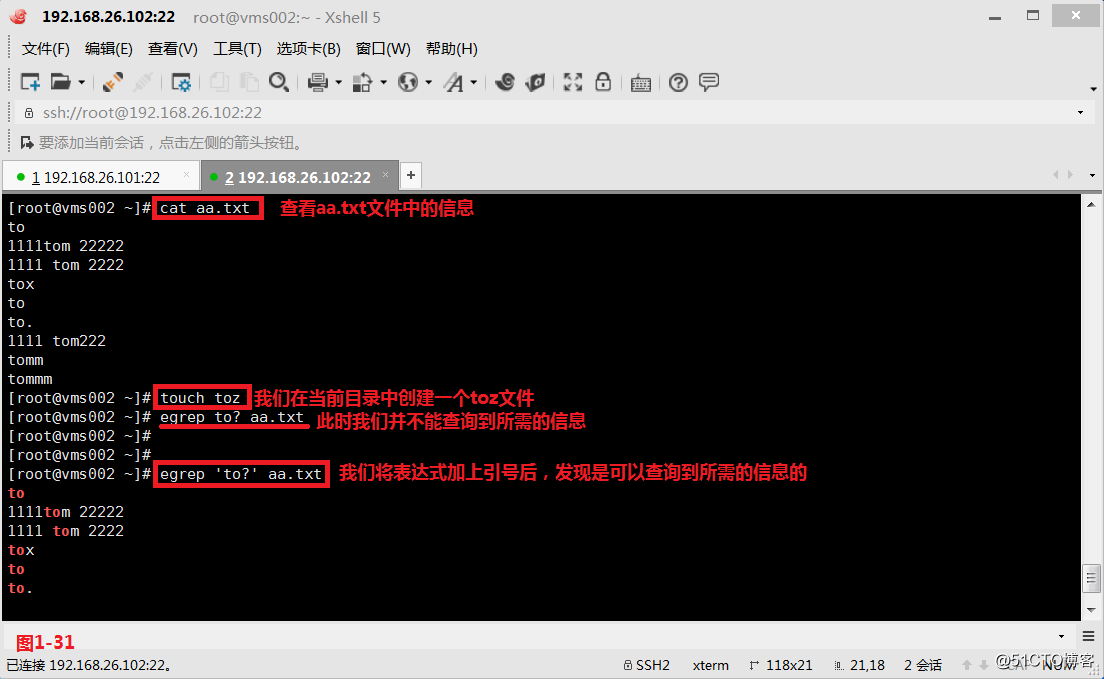
g ( s , a ) : = f s i m − 1 ( s , f ( s , a ) ) g(s,a):=f^{-1}_{sim}(s,f(s,a)) g(s,a):=fsim−1(s,f(s,a)),作用是将当前状态和动作映射到一个新的动作,以便在仿真环境中更好地模拟真实世界中的行为。
g
g
g 的近似为机器人的运动引入了噪声。为了保证稳定的运动,GAT使用平滑参数
α
\alpha
α。动作转换函数定义为:
g
(
s
t
,
a
t
)
:
=
α
f
s
i
m
−
1
(
s
t
,
f
(
s
t
,
a
t
)
)
+
(
1
−
α
)
a
t
g(s_t,a_t):=\alpha f^{-1}_{sim}(s_t,f(s_t,a_t))+(1-\alpha)a_t
g(st,at):=αfsim−1(st,f(st,at))+(1−α)at
在他们的实验中,他们将
α
\alpha
α 设得尽可能高,以保持行走稳定。
基于变换函数的增强模拟器
策略计算一个动作,然后传递给动作接地模块。这个模块首先预测在现实世界中所采取的动作所对应的状态变量的值。然后,该模块使用逆动力学模型 f s i m − 1 f^{−1}_{sim} fsim−1 来计算在模拟中产生相同效果的动作。最后,将策略的操作替换为预测的操作,并将修改后的操作传递给模拟器。
在修改模拟器时, f f f 网络接收 s t s_t st 和 a t a_t at 作为输入, f s i m − 1 f^{-1}_{sim} fsim−1 网络接收 s t s_t st 和 f f f 的输出作为输入。 f s i m − 1 f^{-1}_{sim} fsim−1 的最终输出是替换 操作一个 a t ^ \hat{a_t} at^。
函数的实现
GAT使用两个神经网络来近似 f f f 和 f s i m − 1 f^{-1}_{sim} fsim−1。每个函数都是一个三层网络,第一层有200个隐藏单元,第二层有180个隐藏单元。
a t a_t at 是一个期望关节角度的向量, f f f 的动作输入和 f s i m − 1 f^{-1}_{sim} fsim−1 的动作输出被编码为 x t x_t xt 的期望变化,这被发现可以提高预测。他们让 f f f 预测在 s t s_t st 处执行引起的关节加速度,而不是直接预测 s t + 1 s_{t+1} st+1。然后,加速度可以被积分并加到 s t + 1 s_{t+1} st+1 上,从而产生下一个状态。
函数的训练
函数 f f f 和 f s i m − 1 f^{-1}_{sim} fsim−1 是通过监督学习来训练的。具体而言,函数 f f f 是通过收集一小部分真实世界轨迹并构建一个监督学习数据集来学习的。该数据集包含输入状态和输出动作的对应关系,即 { ( s i , a i ) } → { x i } \{(s_i,a_i)\}→\{x_i\} {(si,ai)}→{xi}。类似地,函数 f s i m − 1 f^{-1}_{sim} fsim−1 是通过收集模拟轨迹并构建一个监督学习数据集来学习的。该数据集包含输入状态和输出状态的对应关系,即 { ( s i , x i ′ ) } → { a i } \{(s_i,x'_i)\}→\{a_i\} {(si,xi′)}→{ai}。
在本文中,作者使用了神经网络,并使用梯度下降算法在均方误差损失上进行训练。
实验
实验设置
策略训练
他们在双足机器人行走任务中评估了GAT。行走采用范围为 [ 0 , 1 ] [0,1] [0,1] 的目标前进速度参数。他们将这个参数设置为0.75,他们发现这是稳定可靠的最快步行。机器人以这个速度向目标前进。如果机器人与目标的夹角大于5度,它会在继续前进的同时转向目标。在所有环境中, J ( θ ) J(θ) J(θ)是执行 θ θ θ 时平均向前行走速度的负数。

在物理机器人上,一旦机器人走了4米或摔倒,就停止搜集轨迹。 θ 0 θ_0 θ0 产生的轨迹在机器人上持续大约20.5秒。在模拟环境中,在固定时间间隔后或机器人摔倒时停止搜集轨迹。
以前的工作表明,当使用从数据估计的模型时,最好使用更短的动作轨迹,以避免对不准确的模型过拟合。即使对于相同的 s t s_t st 和 a t a_t at,虚拟环境中的 s t + 1 s_{t+1} st+1 也很可能与现实环境中的 s t + 1 s_{t+1} st+1 不同。由于 s t s_t st 点的状态误差会向前传播到 s t + 1 s_{t+1} st+1,因此这种误差在运行过程中会叠加。
作者使用了协方差矩阵适应进化策略(Covariance Matrix Adaption-Evolutionary Strategy, CMA-ES)算法来优化策略参数 θ \theta θ。具体来说,他们使用CMA-ES算法从一个高斯分布中采样150个候选策略参数,并根据这些参数生成一组新的策略。然后,他们在模拟器中用每个策略的20条轨迹评估这些策略,并选择最好的k个策略用于更新采样分布。更新采样分布是通过最好的k个策略参数的加权平均值来实现的。具体来说,每个策略参数都被赋予一个权重,该权重与该策略在评估中获得的成绩成正比。然后,这些加权策略参数被用于计算新的采样分布,并用于生成下一代候选。作者将此过程重复10次,以找到最佳的 θ \theta θ 值。
sim-to-sim实验
由于很难在物理机器人上进行大量的试验,他们提出了一项使用Gazebo作为现实世界替代品的GAT研究。
作者对比了三种方法:
- 没有接地的学习方法。
- 使用噪声包围盒(NOISE-ENVELOPE)的接地方法,这是一种在模拟器中注入噪声来接地模拟器的方法。具体来说,该方法将标准高斯噪声添加到未grounded模拟器中的机器人动作中,以鼓励CMA-ES算法提出更加鲁棒的策略。这种方法可以减少模拟偏差,并防止策略改进算法过度适应模拟器动力学。
- 该文提出的Grounded Action Transformation(GAT)算法。
作者通过在模拟器中注入噪声来评估这些方法,并比较它们在改进策略方面的效果以及需要多少次迭代才能达到最佳策略。结果表明,GAT算法相对于其他两种方法具有更好的性能,可以更有效地接地模拟器,并且可以更快地找到改进后的策略。
sim-to-real实验
他们在实际的NAO机器人上测试在模拟器中优化得到的策略参数。具体来说,作者使用了15条轨迹来收集在实际NAO机器人上初始姿态下行走的数据集D。然后,对于每个迭代,CMA-ES算法会从高斯分布中采样一组参数向量,并使用这些向量生成一组策略。接着,算法会对每个策略进行10代进化,并评估每代中表现最好的策略。最后,将表现最好的策略应用于实际NAO机器人上,并使用5条轨迹来评估其性能。如果该策略在任何一条轨迹上导致机器人摔倒,则认为该策略不稳定。
实验结果
sim-to-sim实验

- “% Improve”指的是每种方法在训练过程中,相对于初始策略,平均最大奖励值提高的百分比。
- “Failures”指的是每种方法在训练过程中,无法找到稳定行走策略的次数。具体来说,算法会在初始策略上进行一定次数的迭代优化,并记录每次迭代后是否找到了稳定行走策略。如果算法无法找到稳定行走策略,则将此次数记录为“Failures”。
- “Best Gen”指的是每种方法在训练过程中,找到最佳策略时所需的迭代次数。
GAT有最好的实验效果。
表1还显示,随着策略改进的进行,策略开始过度适应虚拟环境的动力学。没有接地的环境几乎立即就会过拟合。噪声包围盒对过拟合具有更强的鲁棒性,因为它所提出的策略在有噪声的虚拟环境中都取得了良好的性能。GAT算法所做的基础性工作是将仿真环境与真实环境之间进行校准,使得在仿真环境中执行的动作能够在真实环境中得到相似的结果。但是,这种校准是基于初始策略参数 θ 0 θ_0 θ0 的轨迹分布进行的,因此当策略参数 θ θ θ 在改进过程中发生变化时,动作转换函数可能无法产生更加逼真的仿真器。
sim-to-real实验
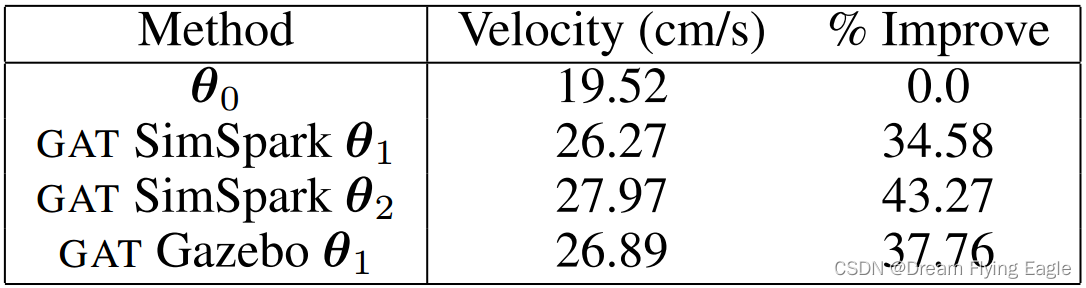
作者使用了SimSpark仿真环境来进行初始策略的学习,并将学到的策略应用于真实的NAO机器人上。作者比较了在仿真环境中使用GAT算法和未使用GAT算法时,NAO机器人行走速度的差异。
结果表明,在经过两次迭代后,使用SimSpark和GAT算法可以将NAO机器人的行走速度从19.52厘米/秒提高到27.97厘米/秒,相对于初始策略参数 θ 0 θ_0 θ0 而言,提高了43.27%。同时,在SimSpark和Gazebo两种仿真环境下,使用GAT算法都可以将行走速度提高30%以上。这些结果表明,该方法具有一定的通用性,可以在不同的仿真环境中得到良好的效果。
总结与展望
本文提出的算法GAT有一些局限性,主要在于其决策学习一个动作修改函数g的假设,即对于所有可能在物理机器人上观察到的状态转移 ( s t , a t , s t + 1 ) (s_t, a_t, s_{t+1}) (st,at,st+1),存在一个动作 a t ^ \hat{a_t} at^,当用 a t ^ \hat{a_t} at^ 代替 a t a_t at 时会产生相同的状态转移。这个假设通常是成立的,因为可以在仿真中以更多或更少的力执行 a t ^ \hat{a_t} at^ 以达到所需的响应。但是,在接触动力学下,外部力会阻碍机器人的行动,这个假设可能会失效。其他任务可能会引入其他形式的模拟器偏差,GAT目前无法处理。