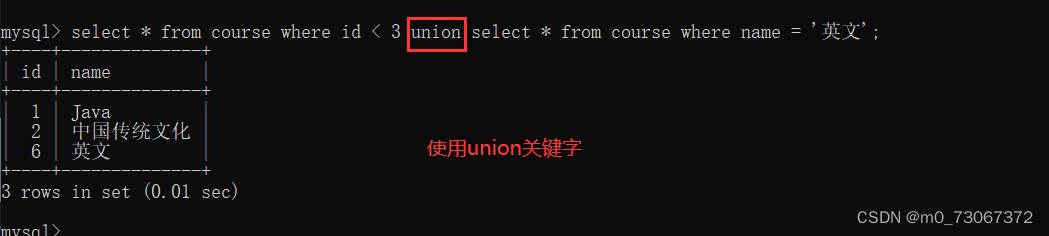
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

╱ 个人简介╱
张岸
新加坡国立大学NExT实验室博士后,主要研究Robust & Trustable AI。
个人主页:https://anzhang314.github.io/
01
内容简介
可微分的因果发现方法,是从观测数据中学习候选图,并利用一个提前定义好的平均分数函数,评估所有的候选图,从而学习到目标的有向无换图(DAG)。尽管这类方法在低维线性系统中取得了巨大的成功,但其有两个无法避免的劣势,
其一,大部分因果发现方法需要在严格的模型类型和分布假设下,但由于现实世界中异构数据的广泛存在,常见的同质性假设很容易被违反,当噪声分布变化时,会导致性能下降;其次据观察,这类方法由于使用平均的分数函数,故而过度利用了更容易拟合的样本,因此不可避免地学习了假边。在这篇文章,我们提出了一个简单而有效的模型框架,通过动态学习重加权评分函数(简称ReScore)来提高因果发现性能,其中自适应权重是根据每个样本的重要程度定量地学习的。直观地,我们利用双层优化方案交替训练一个标准DAG学习器和计算样本的权值。具体来讲,通过一个有权重的分数函数,而不是一个平均分数函数来评估候选图,着重提高DAG学习器无法拟合的样本的权重,降低DAG学习器容易从中提取虚假信息的样本的权重。我们在合成数据集和真实数据集上进行了大量实验,充分验证了ReScore的有效性。
同时,我们还观察到ReScore减轻了伪边的影响,从而使结构学习的表现得以持续而显著的提升。最后,我们进行了理论分析,以保证ReScore在线性系统中的结构可识别性和权值自适应特性。
02
Differentiable Score-based
Causal Discovery
What is Causal Discovery?
Causal Discovery即发现因果关系,就是确定变量之间的因果关系。在这里举一个简单的例子:吸烟会导致肺癌吗?这里的“导致”就在反映一种因果关系。用英文的方式解释:A causes B,即A会因果影响B,对A值的干预会影响B的分布。在真实事例中,这种因果关系是会更复杂的,就不再仅限于二元的形式。
Why we need Causal Discovery?
那我们为什么需要Causal Discovery呢?我们都知道现在的人工智能发展得非常好,而主要思想就是通过从大量的观测数据中拟合深度学习模型,提取数据之间的相关性。但是由相关性做出的预测会存在局限性,具体来讲,收集数据的过程中是无法穷尽所有现实生活中的数据的,并且世界是不断发展的,所以training和testing是一定是会差异的。这种差异,会极大的影响人工智能模型预测的准确性,也即构建在相关性上的深度模型往往缺乏很好的泛化能力。举一个例子,下图中,往往狮子生活在草原中,有绿色背景,而鬣狗生活在非洲,有他们的照片更偏向于黄色背景,背景颜色和动物类型就天然有了一种隐形的相关性。当模型学习到了这种相关关系,并将背景颜色作为区分鬣狗和狮子的一个标准时,再遇到狮子在黄色草原上就会分类错误。一只站在黄色草原上的狮子还是狮子,一群在绿色草原上的鬣狗也只是鬣狗。这说明,有些不稳定的相关性不应该作为模型学习的范式,而稳定的因果关系其实蕴含了本质的内核。人是通过因果关系去认识世界的,这种因果的本质将会极大地帮助模型改善可解释性、泛化性以及鲁棒性。

How to do Causal Discovery?
相关性并不意味着因果关系,但是相关性可以告诉我们很多信息。如果A和B是相关的,那么会存在3种情况:A导致B,B导致A,A和B共享潜在的原因。也就是说只要有相关性,那么他们中间一定是存在因果关系的,而我们的工作就是去挖掘这种因果关系。
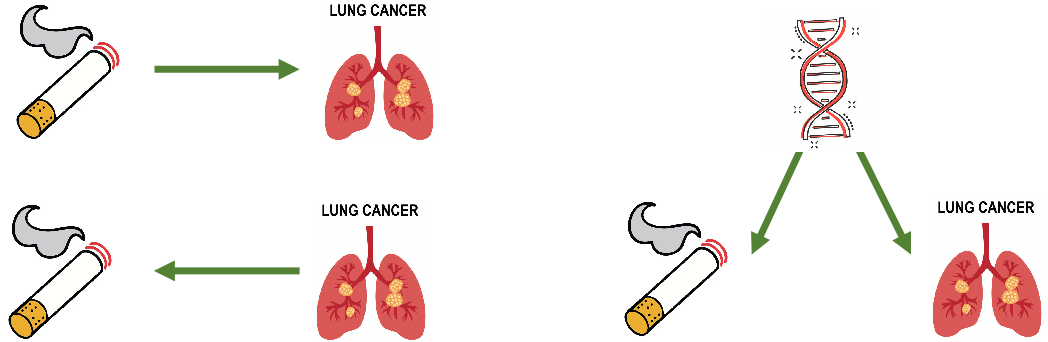
专家可以通过已有的变量假设一个因果关系图,我们拥有的是大量的观测数据,我们能不能将观测数据与因果图联系起来,通过观测数据得到因果关系图呢?这就需要一定的等价性假设。

基本的假设是,如果图中具有可分离的性质,那么一定暗示着在数据中包含一些条件独立性,这就把图和观测数据联系在了一起。这也自然而然地启发了第一类因果发现方法——基于约束的因果发现,即测试数据中的条件独立性,并找到编码它们的有向无环图(DAG),这种方法在理论上是漂亮的,但是又存在几个弊端:
(1)我们现在想要考察的变量数量非常多,在这种情况下需要做的条件独立性分析也会相应地增长,算力条件往往不允许;
(2)其次,基于约束的因果发现方法找到的是马尔可夫等价类。
另一类方法叫基于分数的因果发现,即在严格的模型类型和变量分布假设下,在平均得分函数上评估候选图,这种方法是我们这篇文章讨论的重点。现今所有的基于分数的因果发现都是采用平均分数的方式,也就是说对每一个观测数据样本计算损失值,然后再取平均值。
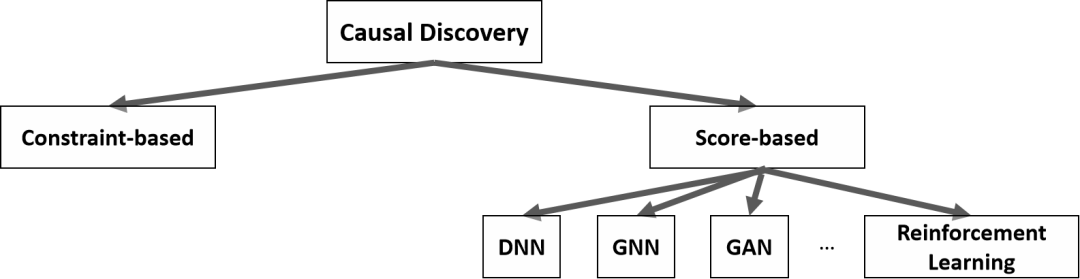
03
ReScore–Reweighted Score Function
DAG learner overly exploits easier-to-fit samples
目前很多的深度学习模型都被应用在基于分数的因果发现之中,但是也存在着很多问题。第一个问题是DAG学习器过度利用了易于拟合的样本,即收集到的观测数据存在着分布不平衡的现象。现实数据中,一定会有一些样本是少量的,非常重要,而另外一些样本是大量的,没有那么重要的,这是很正常的现象。然而基于分数的因果发现方法是通过计算平均值来衡量候选图的,这就会导致偏向学习大量简单的样本而去忽视复杂的含信息量大的样本;第二个问题是数据来自不同的领域,噪声分布会发生变化,具有数据异质性的特点,但是这种特点会使基于分数的因果发现中的基本假设不成立,就无法确定找到的DAG是否是目标。
Differentiable Causal Discovery Methods & Limitations
我们回到现在已有的因果发现方法来简单地总结一下,早期是传统的不适用深度学习的基于分数的方法和基于约束的因果发现方法的天下,2018年以来,可微分的基于分数的因果发现方法有了新的发展,提出了第一个和深度学习网络相结合的NOTEARS。针对数据异质性的问题,近些年,研究者们提出了各式各样的多领域因果发现方法。但是这四类方法都有一定的局限性,前三类方法都依赖于数据同质性的假设,这在现实世界中很容易违反;而第四类现有的多领域方法需要显示的域标签,这通常是很难获取的信息。

Reweighted Score function (ReScore)
可微分的基于分数的因果发现问题可以数学表示为如下图所示的形式:
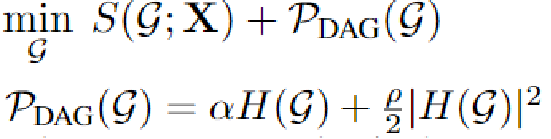
如果假设我们和上帝一样,已知样本的重要性,那么就可以将目标函数自然而然地改写成如下图所示:
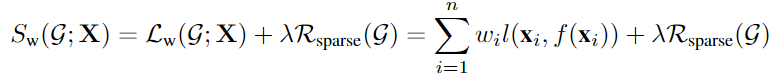
就能更好地得到损失估计。但事实上weights是不天然存在的,那我们如何估计样本对于某一DAG学习器的重要程度呢?
我们可以用复杂样本挖掘的启发式方法去学习样本的权重!DAG学习器是容易陷于易拟合的样本之中的,不可避免地会学习到虚假边缘,这就说明相对不那么容易拟合的样本是更重要的,所以我们认为损失值越大的样本往往更重要,需要匹配一个相对更大的权重。而在每次迭代中动态的分配权重,可以动态的估计样本的重要性,将不容易拟合样本的影响扩大。基于此,我们提出了双层优化的结构学习模型和自适应加权模型,数学表达式如下图所示:
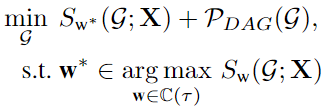
但是,在优化和推理的过程中,还需要将约束的自适应权值限制在一定的阈值内,数学表示如下:
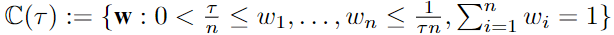
具体的算法过程如下图所示。算法过程分为两个部分,在外循环中,更新DAG学习器,修正加权模型;在内循环中,更新加权模型,固定DAG学习器。

Theoretical Properties of ReScore
我们也证明了一些Rescore的理论性质,第一点是可识别性。如果可微分的基于分数的因果发现方法具有可识别的性质,那么Rescore方法是可以继承这种性质的。

第二点是自适应权重的Oracle属性,ReScore不是平等对待所有样本,而是倾向于提高困难但信息丰富的样本的重要性,同时降低对更容易拟合样本的依赖。

Empirical Results of ReScore
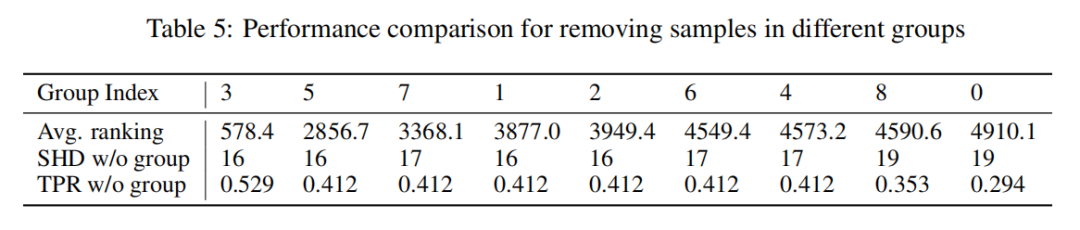
Sachs是一个常用的因果发现的真实数据集,包含9个domain,第一行的Avg ranking是通过ReScore方法计算出来的,ReScore认为Index 0中的样本最复杂,是最重要的一组,Index 3是最简单的一组样本。我们通过SHD和TPR的方法来验证难样本的重要性。我们从这9组数据中随机地去除掉500个相应group下的样本,比如对于第一列index 3的数据,我们去除index 3中随机的500个数据,然后再剩余的数据中用NOTEARS得到预测的DAG的准确性。如果去掉的这500个数据是重要的,那往往,准确性会极大的下降。我们发现,性能的下降程度和ReScore判断的样本重要程度是成正比的,也即Index 0的性能是明显下降的,这就证明了真实数据中确实存在一些非常重要的样本,而且ReScore判断的样本重要性是有一定科学性的。
在下面的实验中,我们在原有的SOTA方法中加入ReScore,性能上都有一定的提升,这就说明ReScore方法学习到的自适应权重是样本重要性最真实的反映。
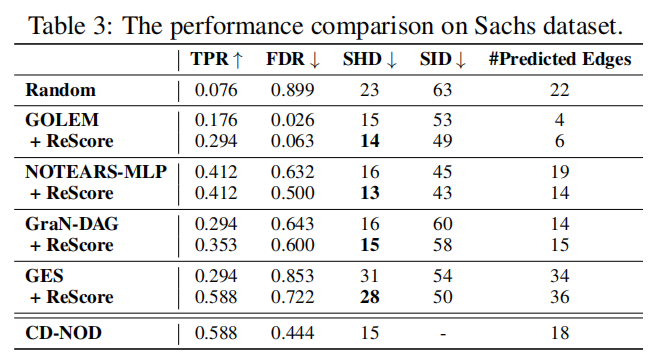
为了评估ReScore是否可以通过自动识别和增加信息样本的权重来处理异构数据而不需要组注释,我们将baseline+ReScore与CD-NOD和DICD进行了比较,这两种SOTA因果发现方法依赖于域注释并且是专门为异构数据开发的。此外,还考虑了一种称为基线+IPS的非自适应重新加权方法,其中样本权重与域大小成反比。具体来说,我们将整个观察分为两个子域。显然,来自弱势域的单个样本无疑比来自优势域的样本提供更多信息,从而更为重要,因为它提供了额外的洞察力来描述因果关系。
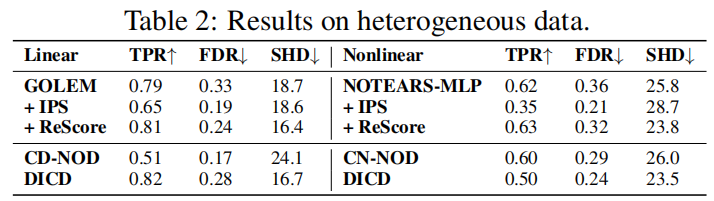
如下图所示,红色和蓝色代表了来自不同的域,不同颜色的点在训练开始时混合在一起。经过内循环和外循环的多次迭代训练,所有数据都显示出明显的积极趋势,即代表性不足的样本倾向于学习更大的权重,同时与具有相同适应度的蓝点相比,来自弱势群体的红点逐渐被识别和挑选出来并分配给相对较大的权重。这充分说明了ReScore的有效性,也解释了其在处理异构数据时的性能提升。这些结果验证了定理2中自适应权重的性质。
整理:陈研
审核:张岸
提
醒
点击“阅读原文”跳转到55:10可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1000多位海内外讲者,举办了逾500场活动,超500万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!