目录
1、数据库的约束类型
1.1、not noll约束
1.2、unique(唯一性约束)
1.3、default默认值约束
1.4、primary key(主键约束)
1.4.1、自增主键(关键字auto_increment)
1.5、foreign key (外键约束)
2、表的设计
2.1、一对一
2.2、一对多
2.3、多对多
3、新增(查询和新增联合使用)
4、查询
4.1、聚合查询
4.1.1、聚合函数
4.1.2、聚合函数搭配表达式使用
4.1.3、分组查询(group by)
4.2、联合查询
4.2.1、 内连接(inner join)
4.2.2、外连接
4.2.3、自连接
4.2.4、子查询
4.2.5、合并查询
1、数据库的约束类型
| 约束条件 | 说明 |
| not null | 非空约束(数据表的某一列不能为空) |
| unique | 唯一性约束(让列的值是唯一的,不和别的行重复) |
| default | 默认值约束(表示这一列,没有被填写的时候默认填什么) |
| primary key | 主键约束(表示这一条记录的身份标识) |
| foreign key | 外键约束(两个表之间的关联) |
1.1、not noll约束
1️⃣创建表时,不指定not noll约束
我们可以看到不指定not noll约束,这样在插入数据的时候,表中两个字段的数据都可以为空。
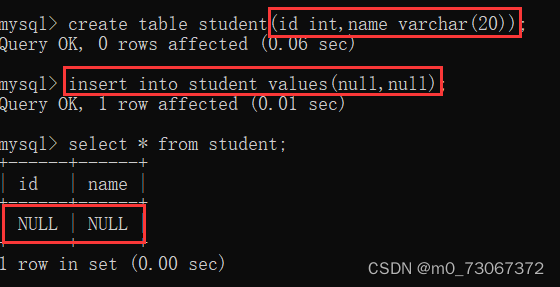
2️⃣创建表的时候,指定not null约束
在创建表的时候,指定表中的字段不能为空,在表中插入数据时,数据不能为空,为空则插入失败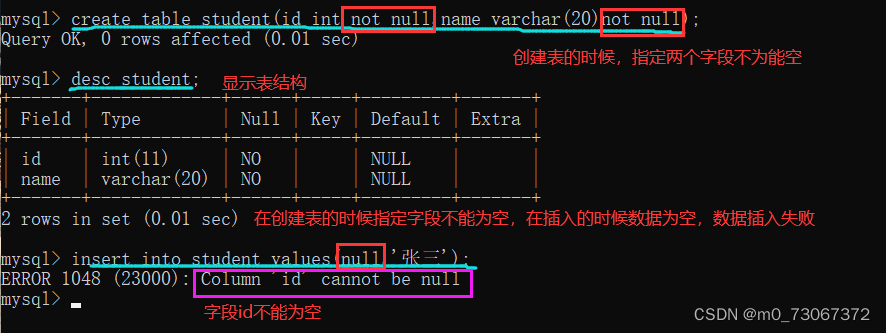
1.2、unique(唯一性约束)
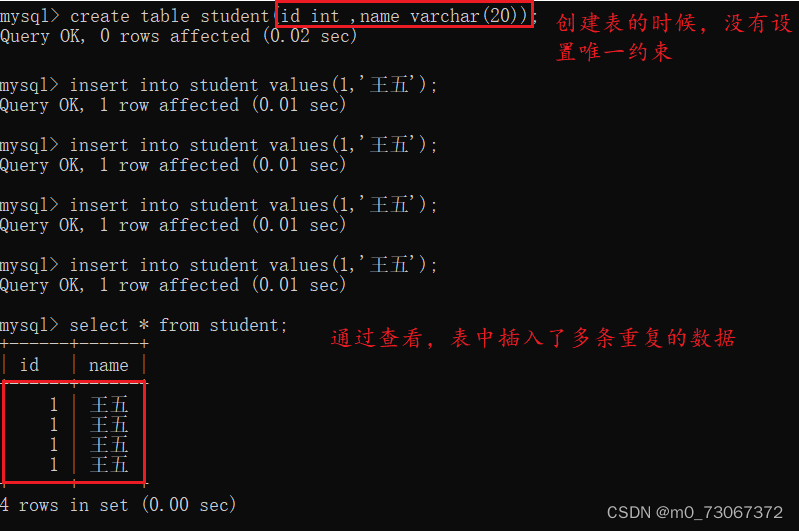
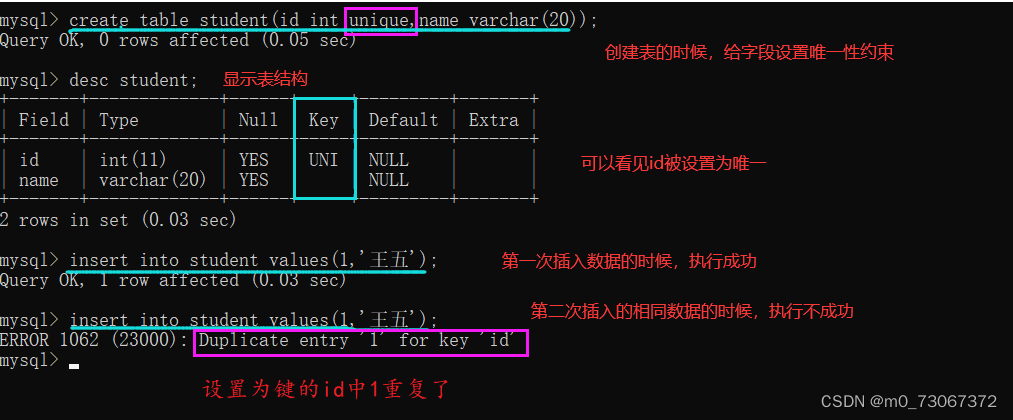
当在创建表的时候设置了unique约束,在插入或者修改数据的时候,先会进行查询,先看数据是否已经存在。如果不存在,就能插入数据或者数据修改成功,如果存在,则插入或者修改数据失败。
1️⃣创建表的时候,表中的字段没有指定唯一性约束
2️⃣创建表的时候,给表中的字段设置唯一性约束
1.3、default默认值约束
默认值是insert指定列插入的时候,其他未被指定到的列就是按照默认值来填充的。
1️⃣一张表,在不做默认值约束的时候,它默认的默认值为null,即初始情况下默认值为null
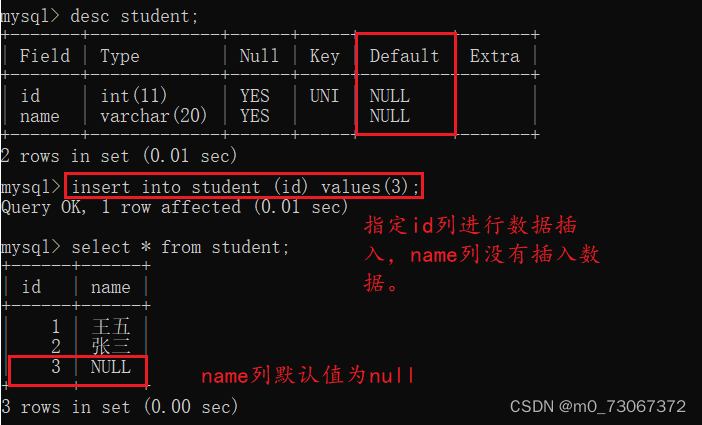
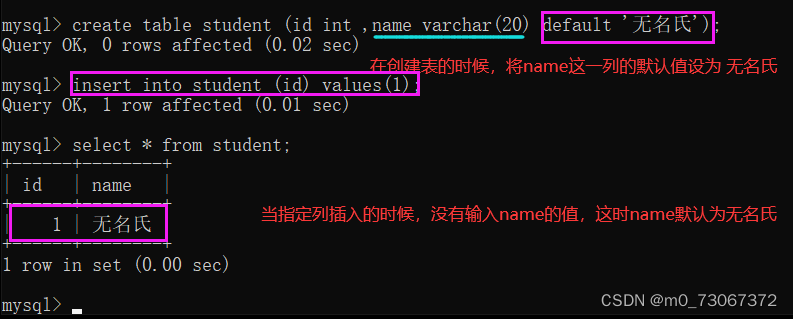
2️⃣ 当我们认为默认的默认值不够好的时候,我们可以自己设置默认值。
1.4、primary key(主键约束)
- 主键是一条记录在表中的“身份标识”,用来区分这条数据与其他数据的关键指标。例如,我们的身份证号码,学号,
- 主键要求唯一,并且不能为空,可以这样理解主键 = unique + not null,但不完全是,因为MySQL要求一个表中,只能有一个主键。
- 创建主键的时候,可以使用一个列作为主键,也可以使用多个列作为主键(复合主键)。
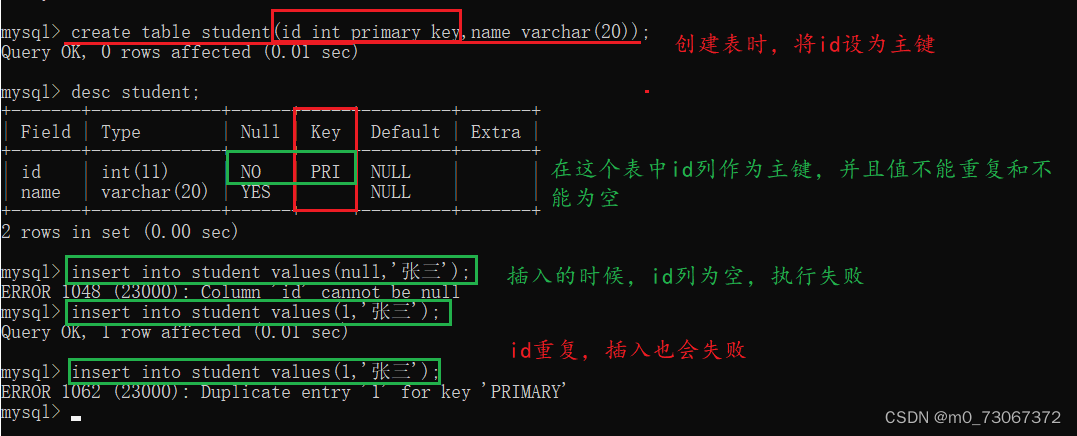
通过上述图片中的情况,可以看出来,主键它的约束情况 与unique+not null相似。
主键约束(primary key)在执行的时候与unique(唯一性约束)相似,都是在执行的时候,先查看一下表中是否有primary key约束的字段的数据与要插入的数据相同的,如果有相同的数据,则执行不成功,如果没有相同的数据,则插入成功。
1.4.1、自增主键(关键字auto_increment)
这里有一个重要的问题,我们在创建表的时候,怎样给表中的每条记录安排一个主键呢?
MySQL自身只是能够检查设置的主键中的数据是否重复,设置主键的时候还是得靠程序员来设置。MySQL提供了一个简单粗暴的做法,自增主键。
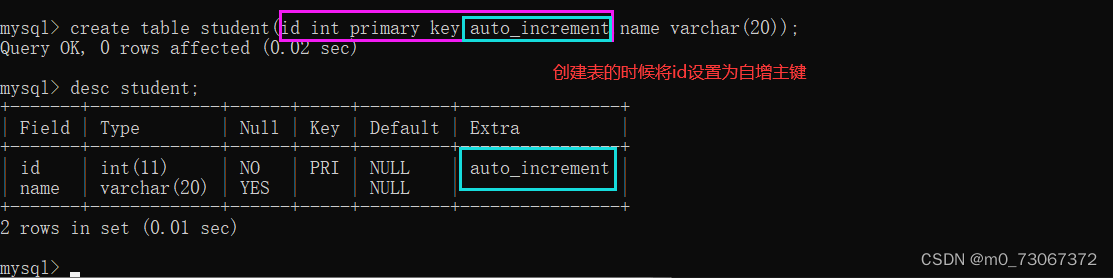
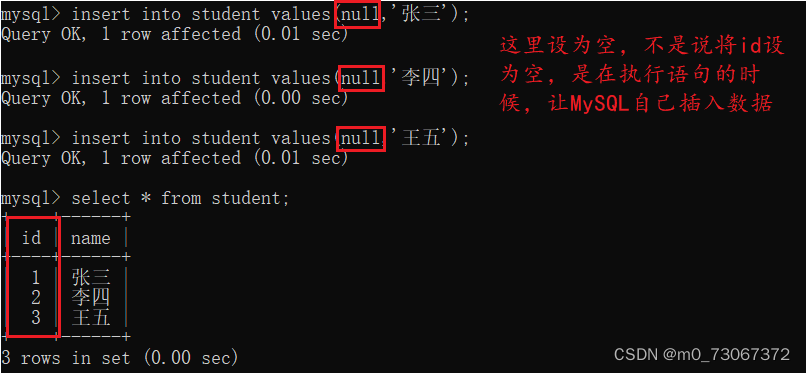
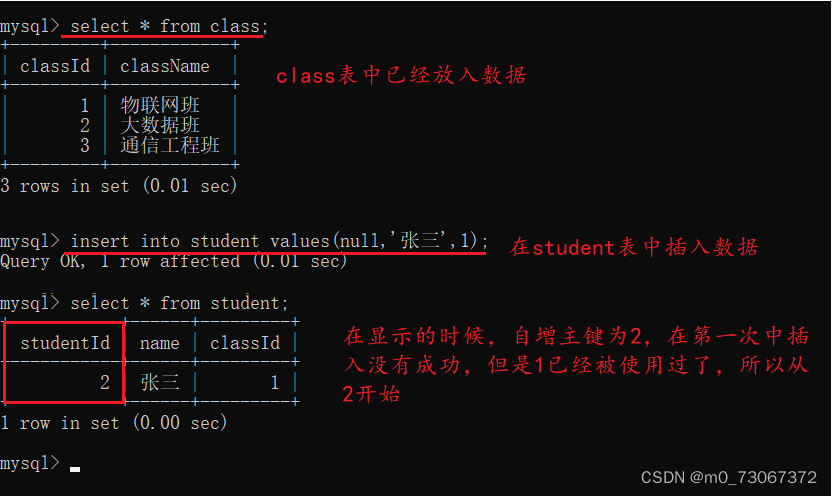
❗❗❗ 注意:给自增主键插入数据的时候,可以手动指定一个值,也可以让MySQL自己分配。
1️⃣如果要让MySQL自己分配,将设置的主键字段给值为null即可,在执行这条命令的时候,自增主键会自己生成一个数字。
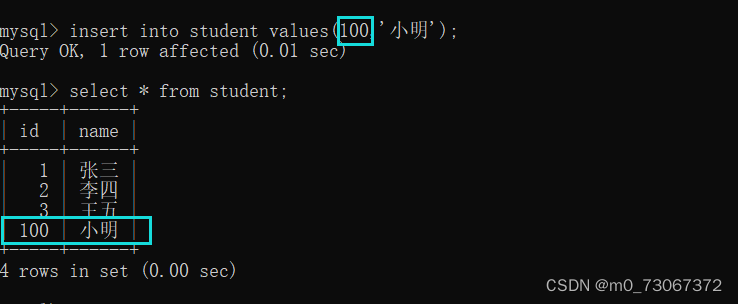
2️⃣在这个表中设置了自增主键并且在插入数据的时候已经使用了让MySQL自己加入数据的方式,再插入数据的时候,使用手动给值的方式,设置的自增主键,插入的数据会使你手动插入的数据
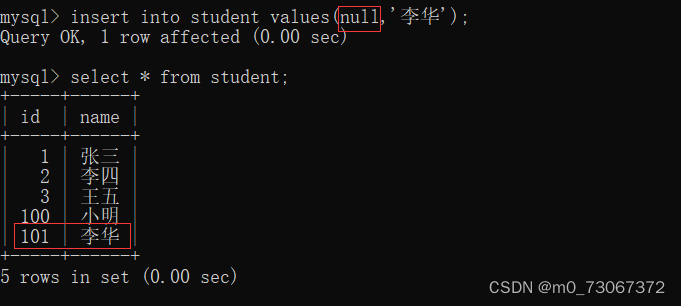
3️⃣但是再插入数据的时候,经过了上述两步操作之后,再接下来插入数据的时候,不给设置的自增主键手动给值时,MySQL自动产生的数据是从手动给的值的下一个值,开始为自增主键赋值。
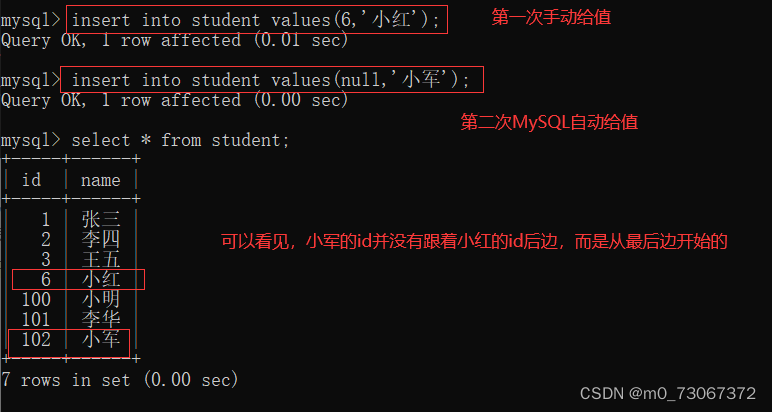
4️⃣当上述操作执行完成之后,再插入一个记录自增主键手动给一个小于100的值,然后再插入一个记录,这个记录中的自增主键让MySQL自己生成一个值。这时候,插入的第二个记录的自增主键的值是从哪里开始?
按照上面的操作,3~100之间的数字没有使用完,但是再次使用MySQL自己生成自增主键的时候,他会从数据的最后开始,这样的设计,是因为数据库的效率本来就不是很快,如果将每个数据都利用上,像上述的操作,随便手动给值的时候,没有按照顺序给值,这样数据库还要记录下来这些值,防止后面给值的时候重复,这样做只会更拖慢数据库的速度。这里只不过是浪费了序号而已,并没有浪费空间。
当然自增主键虽然说是解决了设置主键的问题,但是也不是全都解决,如果说我们的数据库是单机部署的,此时自增主键一般就够用了,但是如果是分布式部署的。使用多台服务器存放数据,每台服务器只能存放一部分数据,每台服务器不知道其他服务器的自增主键是多少了,所以上述的自增主键的方式,就不够用了。
1.5、foreign key (外键约束)
指的是两张表之间的关联这样的情况下,产生的约束
使用示例:我们创建两个表,一个为班级表,一个为学生表。
创建班级表
create table class(classId int primary key auto_increment,className varchar(20));创建一个学生表,学生所在班级的编号与班级表中的classId 建立关联
create table student(studentId int primary key auto_increment,name varchar(20),classId int,foregin key(classId) references class(classId));这里使用foregin key (字段) references 表名 (字段)。references是参照的意思,所以可以看到创建表时,指定外键约束,写在references 之后的表,用来约束要创建的表。所以上述的代码的意思为,班级表(class)约束学生表(student)。
student收到class的约束,就把class叫做student的父表(parent),student就是class的子表(child)(谁受到约束,谁就是子表。)
创建好这两张表之后,插入数据。
1️⃣现在两张表都是空表,先给学生表中插入数据,将学生划分在1班,由于class表中没有数据,所以插入不会成功 (这里相当于子表当中新增约束,新增父表class当中没有的数据,这是不能成功的)
2️⃣插入和修改student表当中的数据的时候,如果插入或者修改的值(例如:classId )外键约束中没有,则不会成功。(子表当中修改约束,约束是父表当中的数据,也是不能成功的)
3️⃣给class表中插入数据之后,再给student表中插入数据,在执行这条语句的时候MySQL会用这个记录中的classId与class表中的classId进行遍历比对,如果class表中存在这条记录当中的classId,那么就会插入成功,否则就会插入失败。


❗❗❗注意
外键约束并不是单向的,父表在约束子表的时候,子表也在约束父表
当我们要删除父表当中的记录的时候,由于外键约束是不能成功的。
当两个表产生了外键约束。对于子表,不能新增或者修改这个约束(子表新增或者修改的数据不能超过父表的范围),对于父表不能删除或者修改这个约束(已经被孩子依赖的数据是不能删除掉的)。

但是针对上述的描述如果一条数据没有实际意义了,我们怎样将他删除掉。
就像淘宝一样,他这个网站最基本的数据库应该存在商品表和订单表。我们根据商品表买了一件商品之后,产生了一个订单。这样商品表就和订单表产生了联系。但是这个商品商家下架了,商品表中这个数据要删除,但是订单表中,还要能看见我们的商品信息,这个时候,该怎样删除商品表中的商品数据。
这里了解一下,我们采用逻辑删除,并不是真的在商品表中将其删除。可以在商品表中增加一个列,用来表示是否下架商品,如果下架,使用update 将这个记录修改为下架。
2、表的设计
两个步骤
- 梳理需求中的“实体”,与Java当中的对象同理。
- 梳理实体之间的关系,存在什么约束。
2.1、一对一
就我们学生而言,一个学生只能有一个学信网账号,一个账号只能共一个人使用。
这里有三种创建表的方式:
1️⃣创建一个表,包含学生信息和账号信息
accout-student(accountId,username,password,studentName...)2️⃣创建两个表,按照业务,把相关字段拆分成两个表,为两个表建立主外键关系
account(accountId,username,password); student(studentId,name,accountId);
2.2、一对多
以学生和班级的关系为例;
一个班级可以有很多的学生,一个学生只能有一个班级。
学生一方,可以和班级表建立外键关系。
class(classId,name);
student(studentId,name,classId);2.3、多对多
就学生和课程的关系为例:
一个学生可以选择多个课程,一个课程也可以提供给多个学生。

3、新增(查询和新增联合使用)
把查询结果作为新增的数据。
语法格式:
insert into 表名1 select * from 表名2;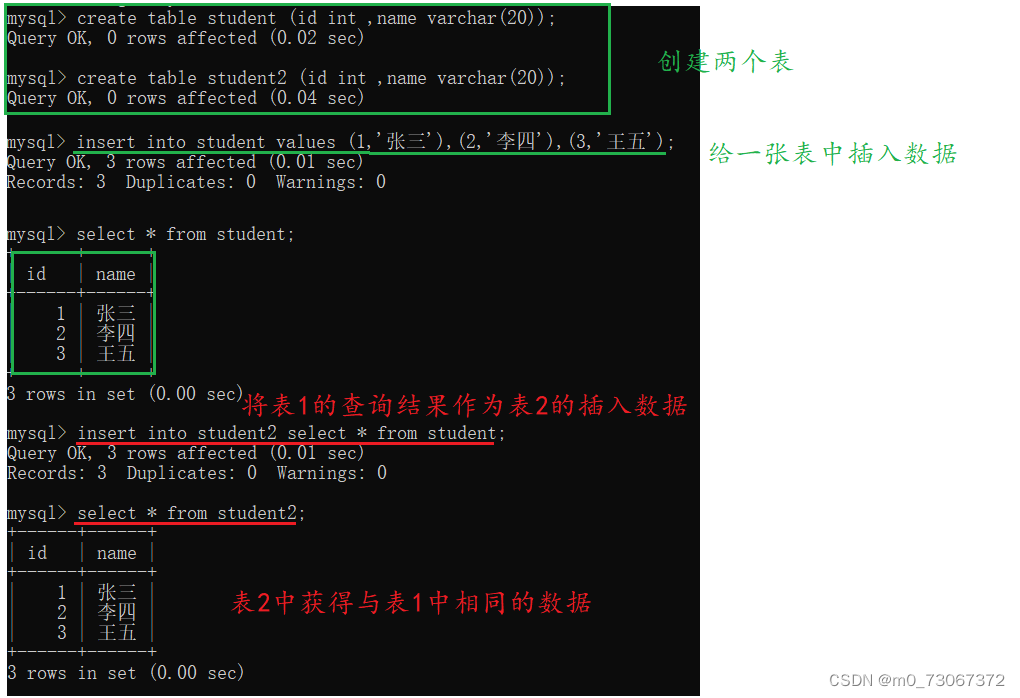
❗❗❗ 注意:
使用这种插入数据的方式,必须是表2中的列的个数和列的数据类型与表1中的列的个数和列的数据类型得匹配。这两个条件不能满足,则插入不会成功。
4、查询
4.1、聚合查询
把查询过程中,表的行和行之间进行一定的运算。
4.1.1、聚合函数
| 函数 | 说明 |
| count([distinct] expr) | 返回查询到的数据的数量 |
| sum([distinct] expr) | 返回查询到的数据的总和,查询的数据如果不是数字,则没有意义。 |
| avg([distinct] expr) | 返回查询到的数据的平均值,查询的数据如果不是数字,则没有意义。 |
| max([distinct] expr) | 返回查询到的数据的最大值,查询的数据如果不是数字,则没有意义。 |
| min([distinct] expr) | 返回查询到的数据的最小值,查询的数据如果不是数字,则没有意义。 |
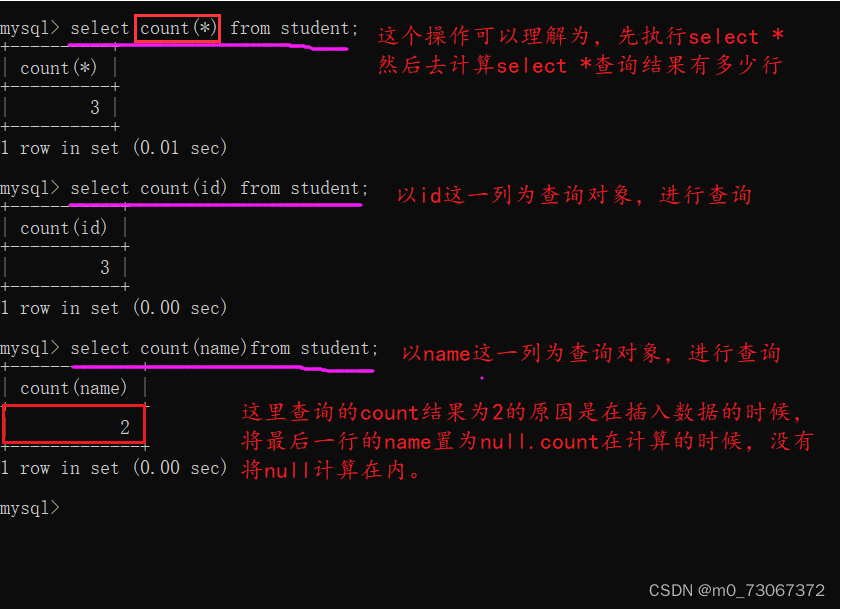
1️⃣count,查询数据的数量。
2️⃣sum求和:只是针对数字列有效
聚合函数在运算的时候遇到null会自定跳过。

聚合函数不能用数字之外的类型数据进行运算。
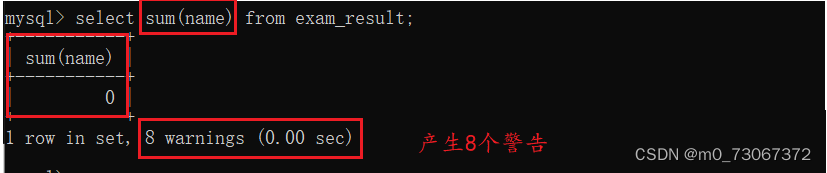
可以使用show warnings来查看警告。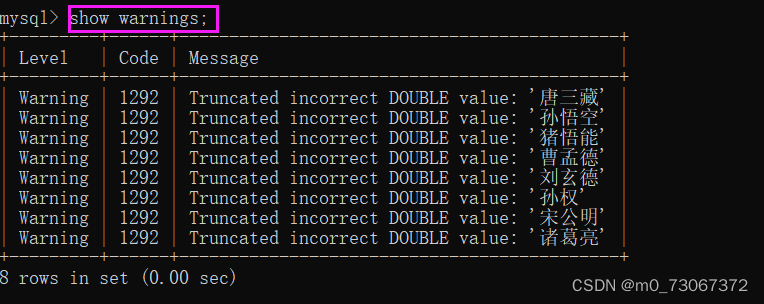
3️⃣max、min的使用

4.1.2、聚合函数搭配表达式使用
求总分的平均分。
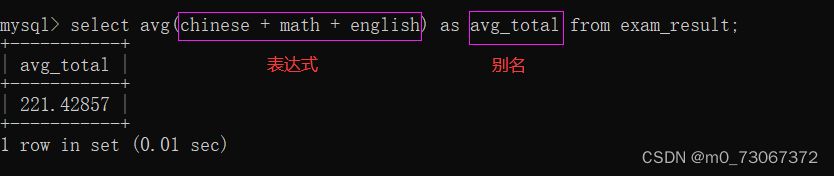
❗❗❗ 注意事项:
聚合函数使用的时候,函数名和()之间没有空格,如果加空格,执行时会出错。
4.1.3、分组查询(group by)
select中使用group by子句可以 对指定列进行分组查询。
需要满足:使用group by进行分组查询时,select指定的字段必须是“分组依据字段”,其他字段若想要出现在select中则必须包含在聚合函数中。
格式:
select column1, sum(column2), .. from table group by column1,column3;
计算每个岗位的平均薪资。我们使用group by来进行分组,按照职位划分,将相同职位的划分到一组,这里使用role划分。

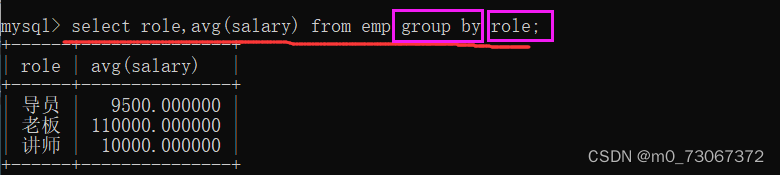
分组的时候,还可以指定条件筛选(分组前筛选、分组后筛选)
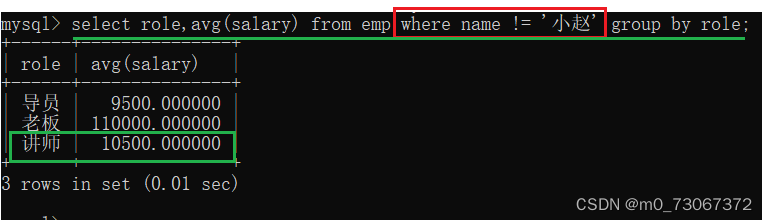
1️⃣分组前筛选,使用where条件。
举例:计算讲师的平均薪资,但是小赵不计算在内。
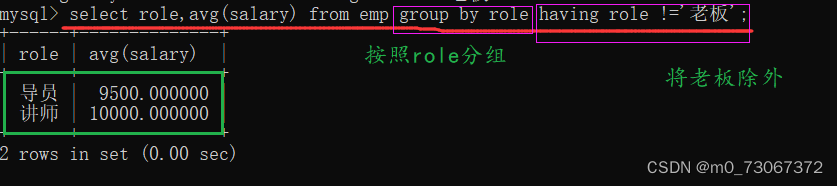
2️⃣分组后筛选,使用having条件
举例:计算每个岗位的平均薪资,除去老板。
3️⃣可以同时在分组前和分组后筛选
举例:分组前去除小赵,分组后去除老板同时进行

4.2、联合查询
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表联合查询是对多张表的数据取笛卡尔积。联合查询是针对多张表一起查询,聚合查询是针对一张表中的数据进行查询。
取笛卡尔积,得到更大的一张表。这个表的列数是两个列数之和,行数是两个表行数之积。

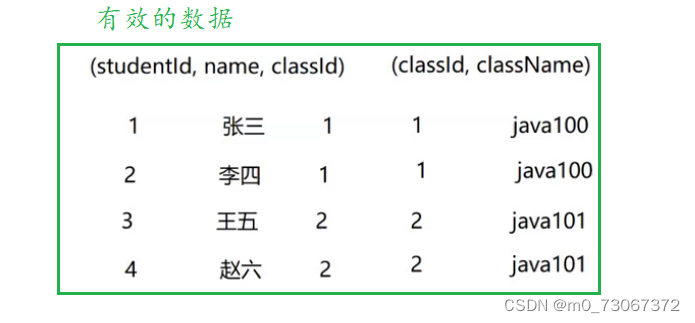
笛卡尔积获取的数据有些是有效的有些是无效的。像上述的表中这些数据才是有效的
在取笛卡尔积之前学生表中的classId和班级表中的classId,必须相同才是有效数据(与外键相似)
像上述的筛选“两个classId对的上”就可以使用where子句的条件来描述
基于笛卡尔积+条件查询,此时就是联合查询/多表查询。
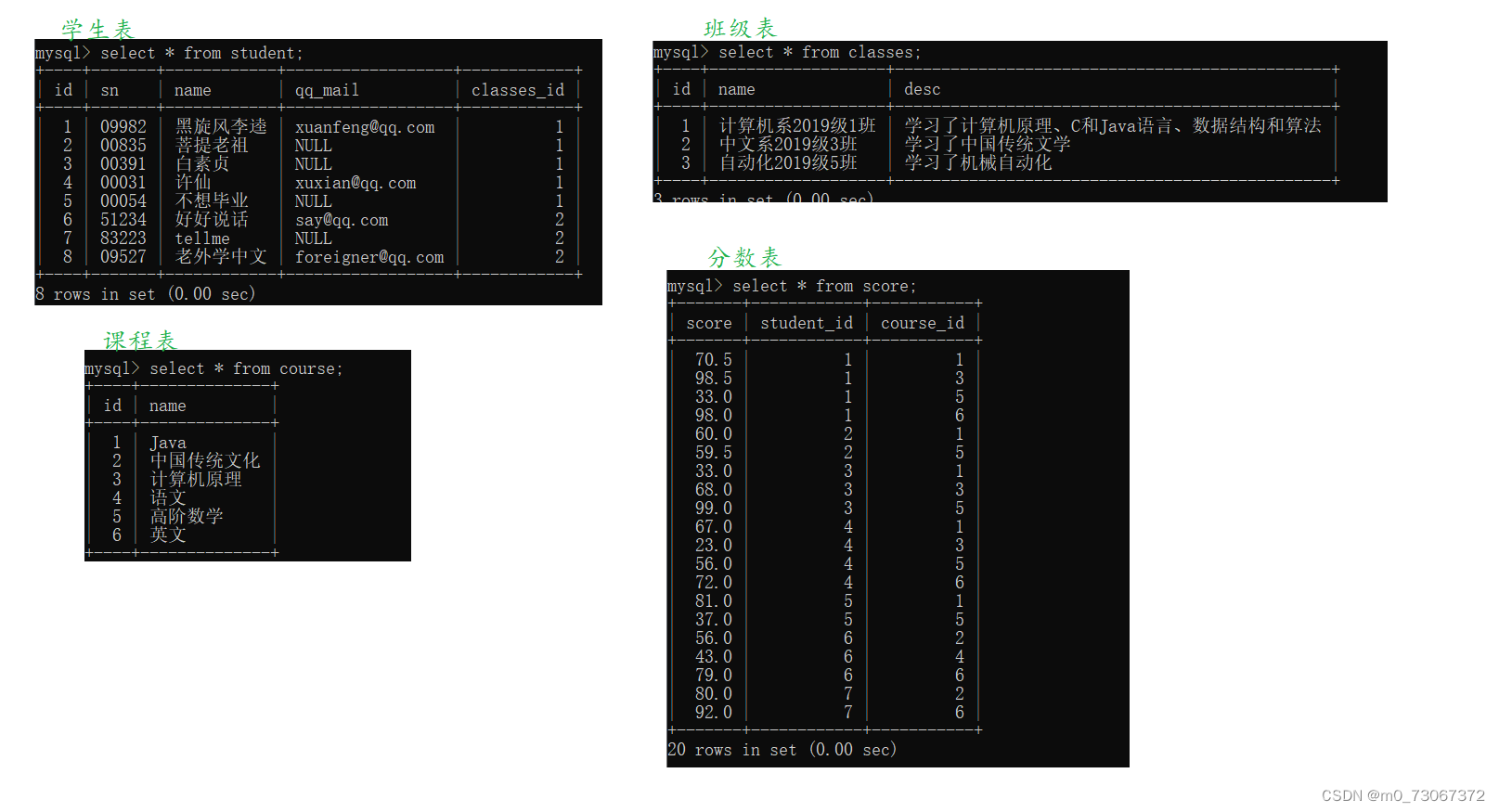
学习联合查询之前先要创建多个表,这里有三个实体,创建四个表
学生和班级是一对多的关系
学生和课程是多对多的关系
score是一个关联表。score不仅表示分数,也将学生表和课程表关联起来了
班级和课程之间并没有直接的关联关系,这里认为他们没关系。
4.2.1、 内连接(inner join)
这里的语法是根据第一题的过程写的,具体语法我们可以更具需求自己添加。这里主要是区别一下取笛卡尔积两种写法。
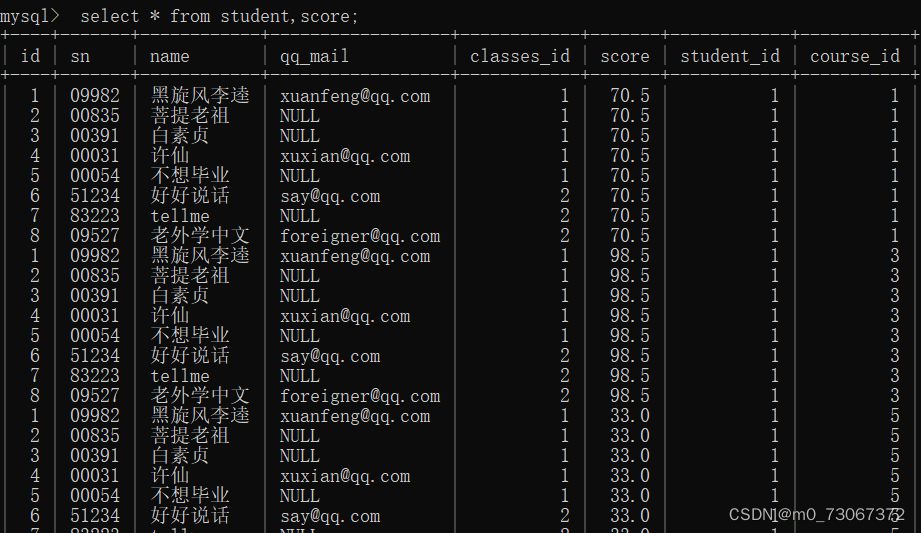
1️⃣取笛卡尔积
取笛卡尔积的代码格式
1、select * from 表名1,表名2; //示例:select * from student,score;student表在前产生笛卡尔积的时候,student的列在前。 2、使用join关键字,取笛卡尔积 select * from 表名1 join 表名2; //示例:select * from student join score;2️⃣获取笛卡尔积的有效数据
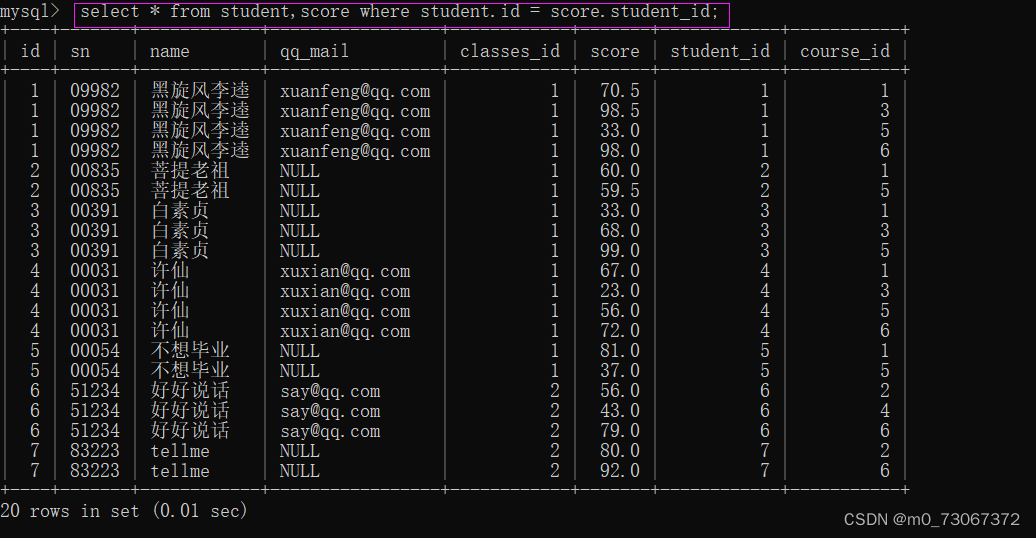
获取有效数据的代码格式
1、select * from 表名1,表名2 where 表名1.列名 = 表名2.列名; //示例:select * from student,score where student.id = score.student_id; 2、针对使用join取笛卡尔积之后,进行条件筛选的时候,不是使用where关键字了而是使用on select * from 表名1 join 表名2 on 表名1.列名 = 表名2.列名; //示例:select * from student,score on student.id = score.student_id;
(1)查询“许仙”同学的 成绩
许仙 名字只能在学生表中查找,成绩需要在score中查找。两个关键信息存在于两个不同的表中。这就需要联合查询了。
主要分3步:
- 先把student和score取笛卡尔积
- 去掉无效数据
- 按照许仙的名字来筛选
1️⃣.取student表和score表的笛卡尔积
这里数据之截取了一部分,用作展示
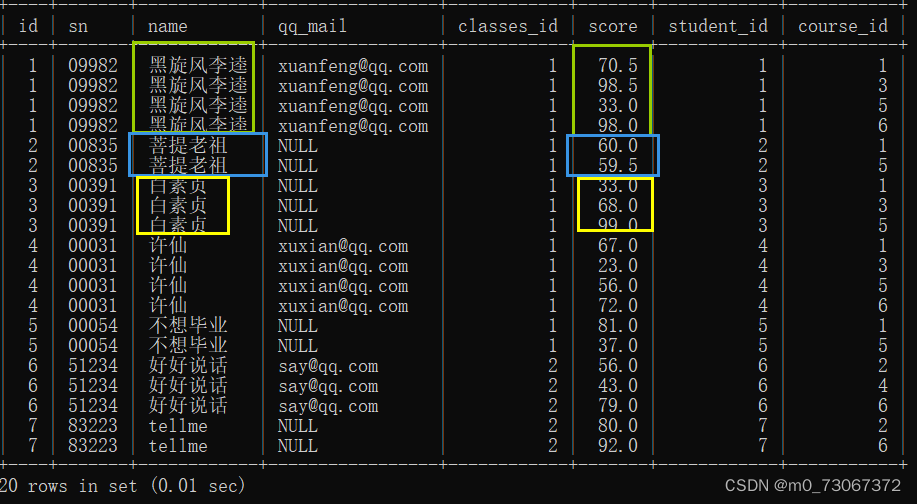
2️⃣去除无效数据
3️⃣按照许仙的名字来筛选
4️⃣ 将所得到的结果的列精简一下
上述三部操作已经得到我们想要的数据了,但是还可以针对得到的结果的列精简一下。


(2)、查询所有同学的总成绩,及同学的个人信息; (联合查询与聚合查询联合使用)
前两步和第一题的操作一样,先取笛卡尔积;再去除无效数据。
要查询所有同学的总成绩,更具前两步得到的表中,成绩不是一列一列的在表格中呈现,而是一行一行的在表格中呈现。所以我们要得到总成绩,就需要使用聚合查询(针对行进行运算)。还需要按照姓名/学号进行分组(group by),在针对每个组,进行求和。

4.2.2、外连接
内连接和外连接都是进行笛卡尔积,但是细节上有所差异。
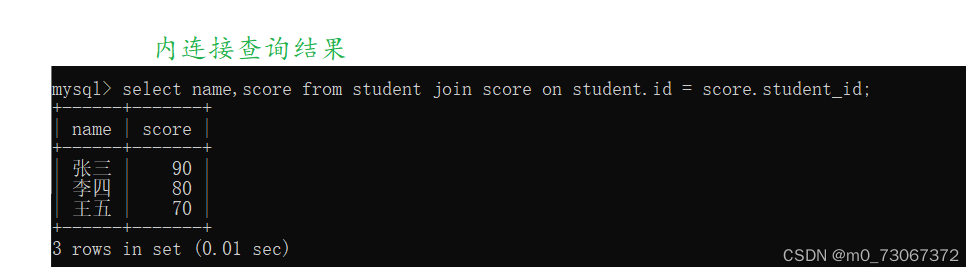
1️⃣内连接和外连接的查询结果相同
两个表中的数据都是一一对应的,第一个表中的每个记录,在第二个表中都有体现,第二个表中的每个记录,在第一个表中也都有体现。此时内连接和外连接查询的结果都是相同的。
内连接查询结果
📕左外连接和右外连接
可以看出外连接的结果和内连接的结果相同,没有什么变化。

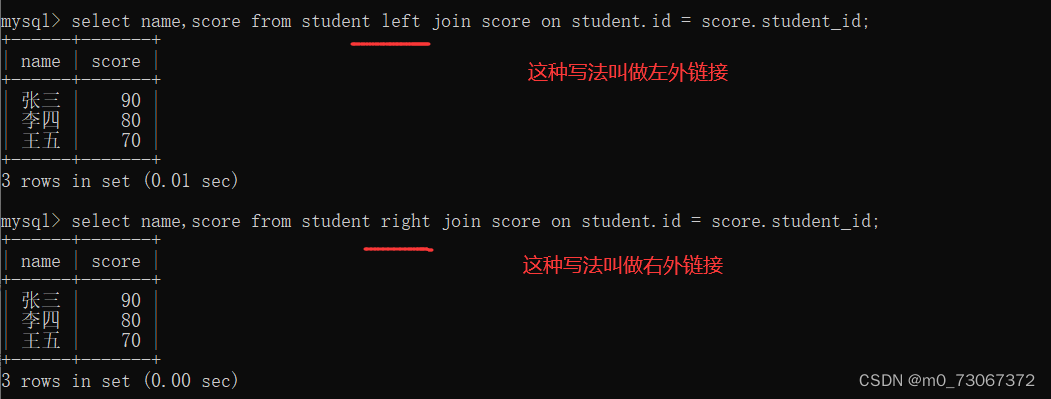
2️⃣内连接和外连接查询的结果不同
✅内连接
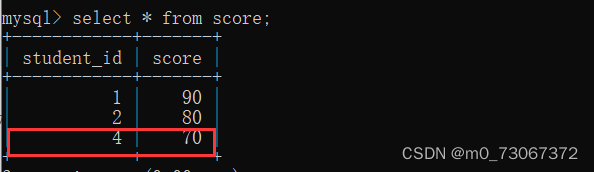
我们将成绩表中的student_id列中最后一行的数据改为4.
两个表中的数据不在一一对应了,此时进行内链接,结果就只是两个表中共有的部分被呈现。

✅左外连接
进行左外链接,就是以左侧的表为准,左侧表中的所有数据都能体现出来。
由于成绩表中学号为1,2,4;学生表中学号为1,2,3.
以左侧表(学生表)为主,筛选两个表中学号相同的数据,放在这个临时表(名字,成绩)中呈现出来。由于学生表中没有4号,成绩表中没有3号。所以以学生表为主创建的临时表中3号学生王五的成绩在这里呈现出来的结果为null.
左外链接会将左侧表中所有的数据展现出来。右侧表中 没有对应的左侧表中的数据,就使用null表示。


✅右外连接
以右侧表(成绩表)为主,4号同学学生表中没有,所以姓名的列中用null表示4号同学
右外链接就是以右侧的表为主。将右侧的表全部展现出来。左侧表中没有对应的右侧表中的数据,就使用null表示


4.2.3、自连接
自连接的过程与上述的内连接和外连接相似,只不过是自己和自己之间取笛卡尔积,并筛选有效数据。
自连接的时候,要使用别名,将表区分开。
- 一张表自己和自己链接,自己和自己做笛卡尔积。这种操作本质上是把“行”转成“列”。
- 因为在sql中进行条件查询的时候,都是指定某一列或者多个列之间进行关系运算,无法行和行之间进行关系运算。有时候为了实现这种行之间的比较,就需要把行关系转成列关系。
❓❓❓显示所有"计算机原理"成绩比"java"成绩高的成绩信息
先来查看一下计算机原理和Java对应的id号为3和1,成绩表中每个学号(student_id)所对应的选课(课程id)。
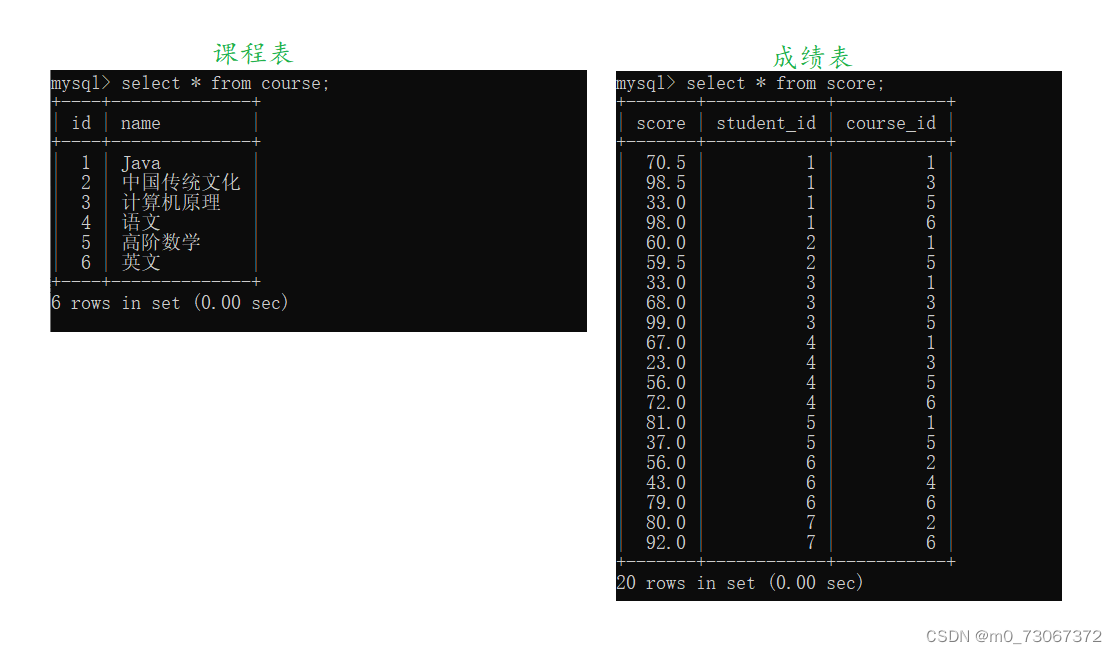
1️⃣再将成绩表进行自连接。
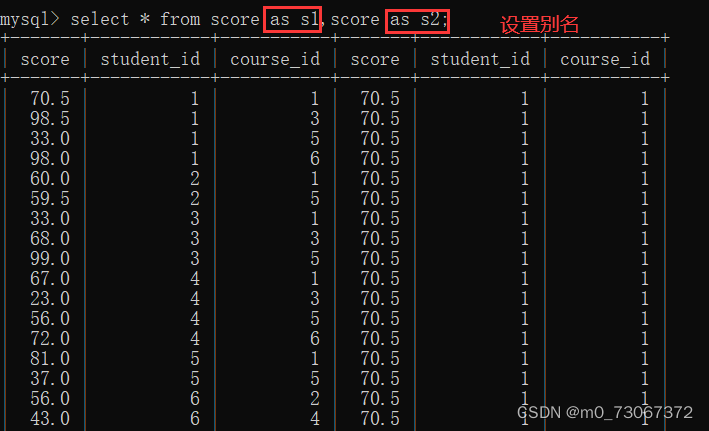
2️⃣筛选有效数据通过学生id
我们以学生id=1为例,展开说明。student_id为1的学生只选择了课程id为1,3,5,6的课程,所以课程表在取笛卡尔积的时候进行的排列组合只会从1,3,5,6这些编号中进行排列组合。
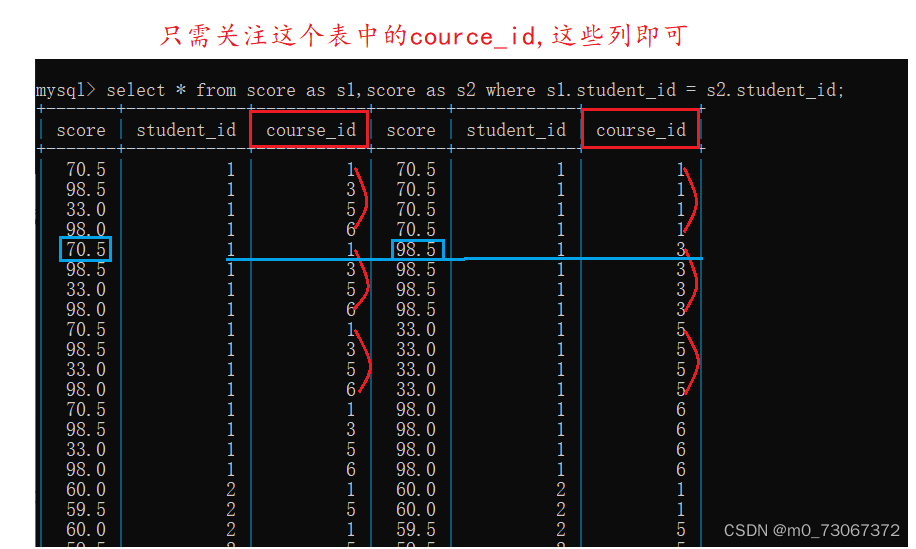
观察course_id就可以看到是在进行排列组合,组合过程中,一定存在,左侧course_id是1,右侧course_id是3的情况。这里只需要存在这一种情况即可,如果再找左侧为3右侧为1的情况,会出现重复计算的情况。
3️⃣再筛选出选择这两门课的同学。

4️⃣ 显示所有"计算机原理"成绩比"java"成绩高的成绩信息 
4.2.4、子查询
- 子查询是将多个sql语句嵌入其他sql语句中,也叫嵌套查询。在实际开发中建议慎重使用,它的使用并不危险,但是多次嵌套之后会使代码读不懂。增大开发难度。
- 子查询分为单行子查询和多行子查询。
📕单行子查询
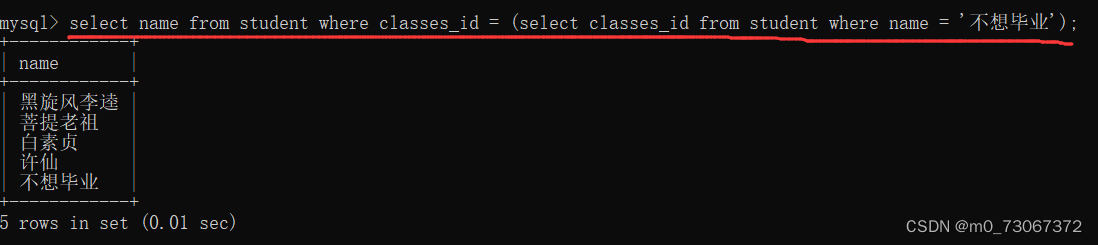
1、查询与"不想毕业"同学的同班同学
在查询之前,先通过观察来确定与不想毕业同学同班的同学,用来和接下来的查询做对比。查询学生表,来查看那些同学的班级id与不想毕业同学的班级id相同。
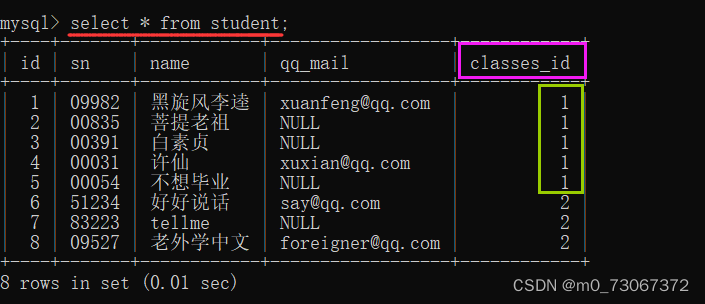
1️⃣ 不使用子查询的写法
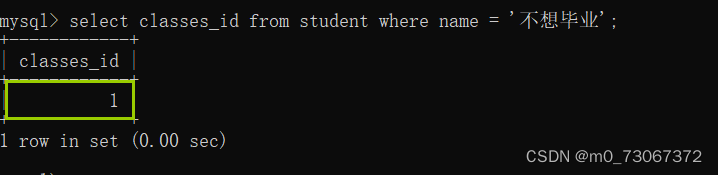
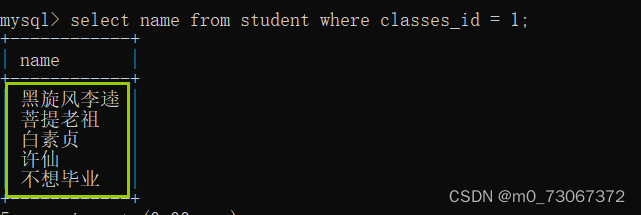
首先在学生表中找到"不想毕业"同学的班级id
通过班级id在学生表中查找班级id为1的同学。
2️⃣使用子查询
将上述两句代码合为一句。
📕多行子查询(关键字in)
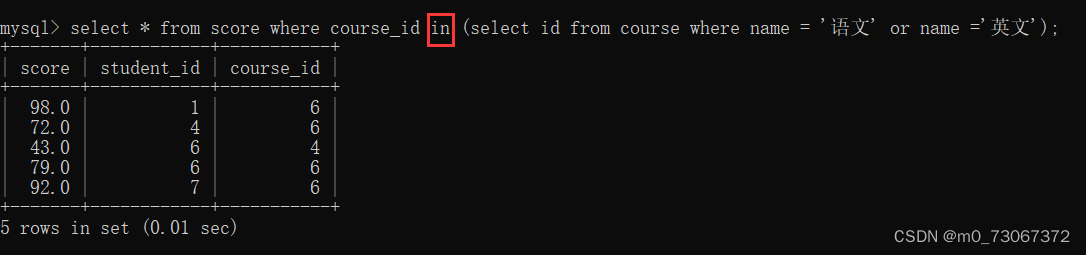
使用关键字in可以实现多行查询
1、查询"语文"或"英语"课程的成绩信息
1️⃣不使用多行子查询的方式
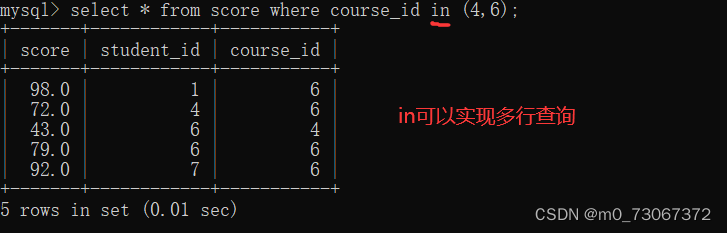
先在成绩表中,查询语文和英语对应的课程id
在根据语文和英文的课程id筛选出对应选了这门课的同学的成绩

2️⃣使用多行子查询的方式
4.2.5、合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符union、union all。使用union和union all时,前后查询的结果集中,字段需要一致。
1️⃣关键字 union
- union可以把多个表的查询结果进行合并(要求多个结果的列得对应)。
- 该操作符用于取得两个结果集的并集。使用时会自动去掉结果集中的重复行。
案例:查询id小于3,或者名字为“英文”的课程;
不使用union关键字
使用union关键字
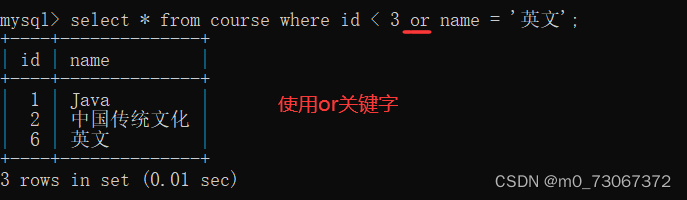
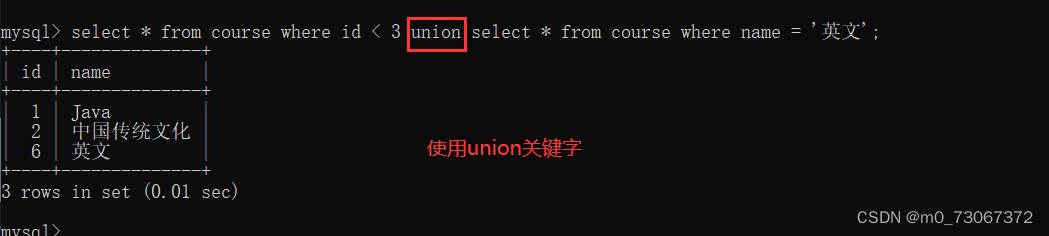
算然说这个例子中使用union和使用or效果是一样的,但是or只能在一张表中使用,而union可以在两张表中使用,取两个表的并集。 使用union取两个表的并集,得到的这个表中的字段个数和类型,要和使用union时两个表的字段个数和字段类型相匹配。
2️⃣union all关键字
union all 关键字的用法与union相似,但是他在使用的时候不会去掉结果集中的重复行。