简介
原文: MnasNet: Platform-Aware Neural Architecture Search for Mobile
来源: CVPR2019
作者: Google (Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, Quoc V. Le)
摘要: 使用神经结构搜索(neural architecture search)方法,将时延显式结合到模型优化目标中,在精度和速度之间得到折衷(trade-off)。提出了层级搜索空间(actorized hierarchical search space),使得灵活性和搜索空间大小适当。该模型在Pixel 手机上在ImageNet 分类任务中达到75.2%的准确率和78ms lantency,这比MobileNet快1.8倍,精度高0.5%,比NasNet快2.3倍,精度高1.2%。在COCO目标检测任务中,也比MobileNetv1,v2有更优的mAP。
特点
- Depthwise Convolution(深度卷积):模型使用更多 5x5 depthwise convolutions。
- Depthwise Separable Convolution(深度可分离卷积):对于 depthwise separable convolution, 一个 5x5 卷积核比两个 3x3 卷积核更高效。
- Inverted Residual Block(倒残差结构):深度卷积核的参数较多为0,也就是其卷积核没有发挥提取特征作用,MobileNetv1作者发现先通过1*1卷积将维度上升,再使用深度卷积,深度卷积的输入输出通道数更高,就能够提取更多的信息。
- SEnet: 通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。
- Bottleneck block: 降低参数量,许多轻量级网络都有使用。
创新点:
不对创新点的具体做法进行深究,只知道他们是做啥的就行
-
NAS(neural architecture search):
用一个强化学习来搜索一个深度卷积神经网络,但主要优化目标有两个,识别准确率和 CPU 运算延迟。
-
Actorized Hierarchical Search Space:
一种新颖的分解式层次搜索空间,将一个CNN模型分解为不同的块,然后针对每个块搜索操作和块与块的连接关系,因此允许不同块有不同的层结构。很多轻量化模型重复 block 架构,只改变滤波器尺寸和空间维度。论文提出的层级搜索空间允许模型的各个 block 包括不同的卷积层。一个块i的子搜索空间由以下选择组成:
-
卷积操作ConvOp:常规卷积(conv)、深度卷积(dconv)和移动倒置瓶颈卷积;
-
卷积核的kernel size:3×3,5×5;
-
Squeeze-and-Excitation ratio:0,0.25;
-
Skip操作SkipOp:池化,恒等残差块、no skip;
-
输出的filter;
-
每个块包含的层数
网络结构
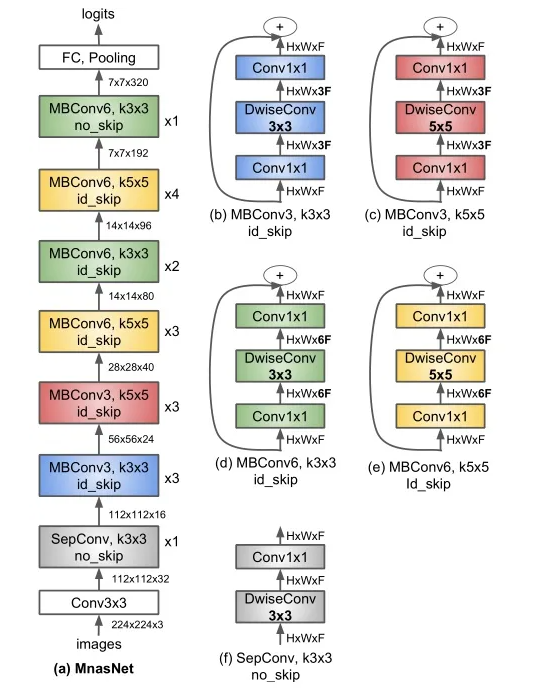
MnasNet
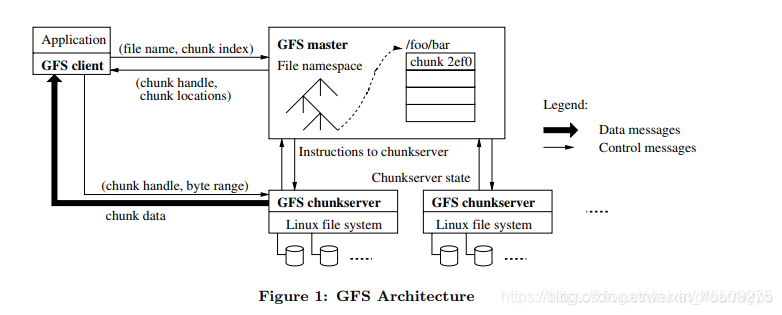
下图为搜索得到的Baseline以及5种baseblock,其中有两种block与MobileNetv1&v2中的block相同,分别为深度可分离卷积(f)和倒残差结构(d)。MBConv 表示 mobile inverted bottleneck conv,DwiseConv 表示 depthwise conv,3x3/5x5 表示kernel_size, BN is 批标准化, HxWxF
表示tensor shape (height, width, depth), and ×1/2/3/4 表示block 重复堆叠次数。
注意:
- 当 MBConv 模块是第一次出现时,其中 DwiseConv 的步长可以是任意的(通常是 1 或 2),但后面重复该模块时步长必须设为1。
- 和 MobileNet V2 不同的是,每个 MBConv 模块中的第二个 Conv 1x1 中的卷积核个数并不需要等于输入的通道数,从(a) 图中也能看出这一点。
- 和 MobileNet V2 一样,Mnasnet 用的激活函数也是 ReLU6(除了之后提及的 SE 模块),且 MBConv 模块中的第二个 Conv 1x1 之后不设置激活函数。
含有 SE 模块的 Mnasnet 结构
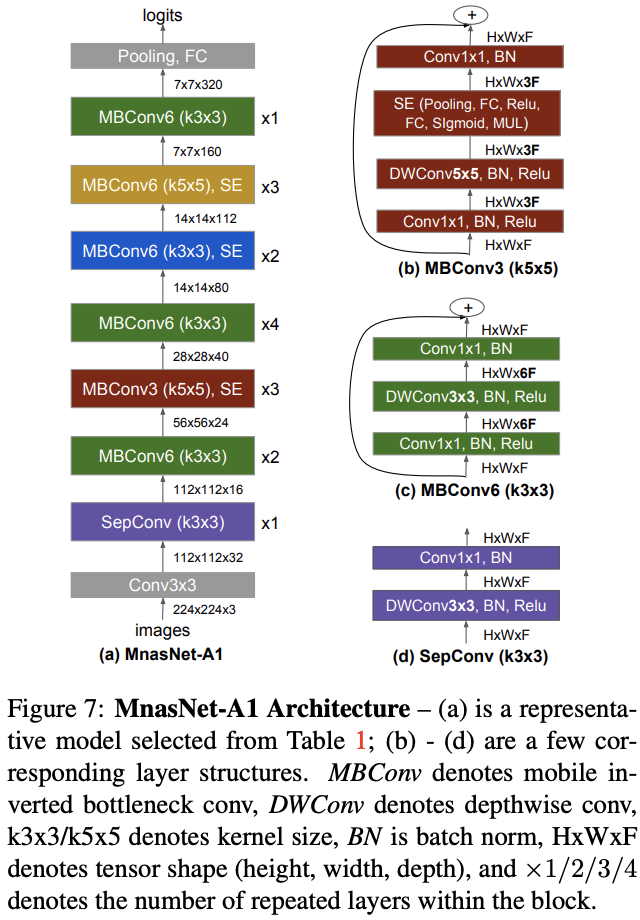
SEnet
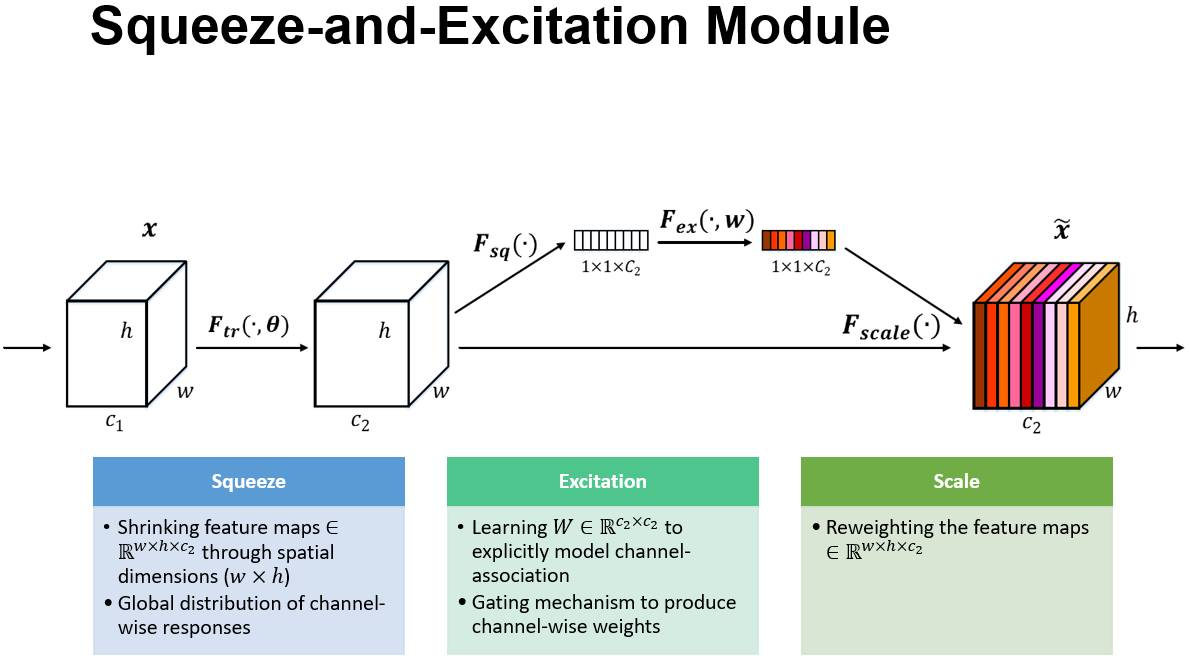
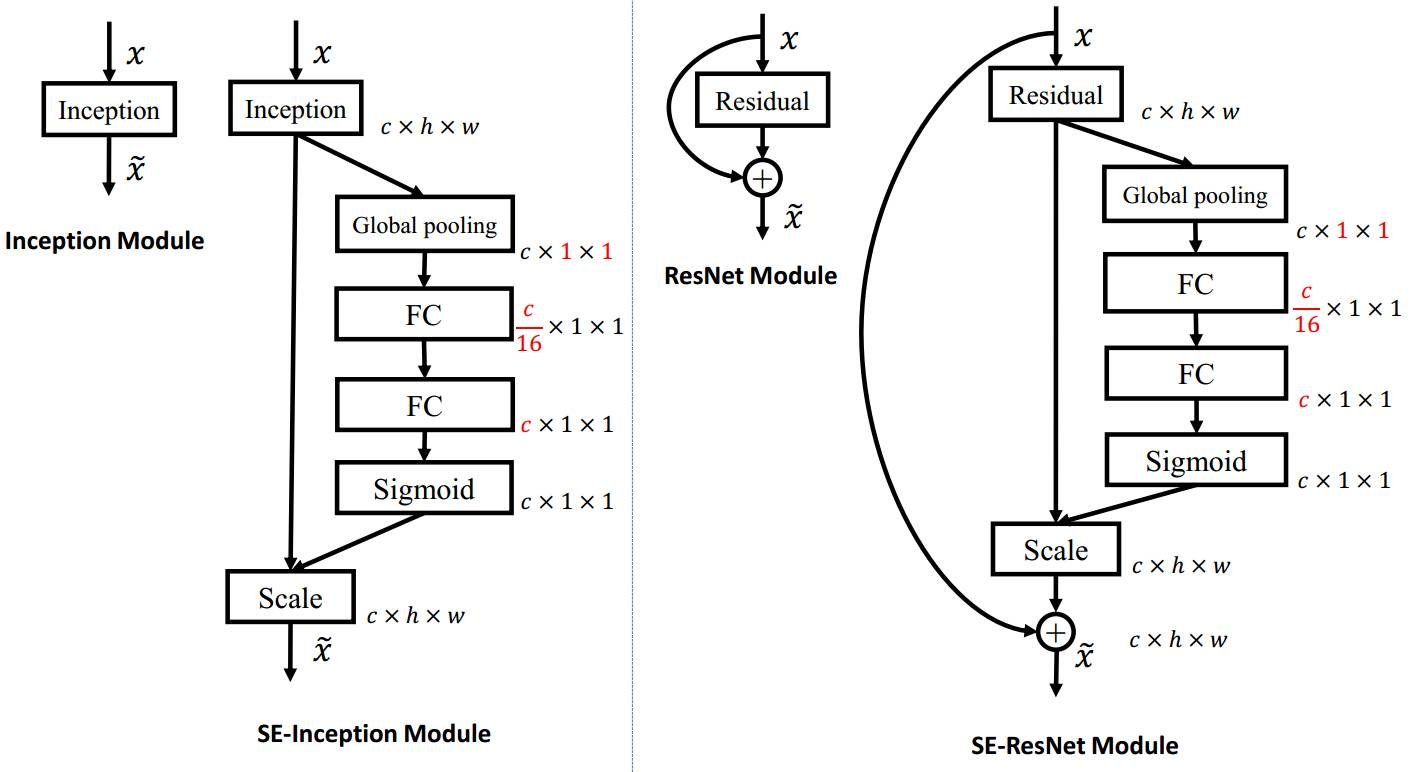
MnasNet block中加入了SEnet(Squeeze and excitation networks), Squeeze-and-Excitation Networks(简称 SENet)是 Momenta 提出的新的网络结构,利用SENet,一举取得最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。其作用是:
Sequeeze: 顺着空间维度进行特征压缩,将(HxWxC)的特征图压缩成(1x1xC)的实数序列。
每个实数都具有HxW的全局感受野,具体做法是求全局均值池化(GlobalAveragePool)。
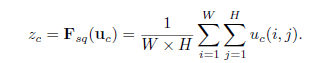
Excitation: 基于特征通道间的相关性,每个特征通道生成一个权重,用来代表特征通道的重要程度。Excitation部分是用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量,第二个全连接再恢复回C个通道,r是指压缩的比例。
Reweight: 将Excitation输出的重要性权重加权相乘到特征层,完成通道重要性标定。
如下图所示,将senet插入到InceptionNet和ResNet block中。
代码
在这里插入代码片
参考
https://arxiv.org/abs/1807.11626
https://zhuanlan.zhihu.com/p/42474017
https://www.zhihu.com/question/287988785/answer/469932620
https://zhuanlan.zhihu.com/p/70703846
https://blog.csdn.net/TheDayIn_CSDN/article/details/91411511
https://blog.csdn.net/qq_38156104/article/details/107585874
https://blog.csdn.net/qq_36758914/article/details/106918983



![[Spring]第二篇:IOC控制反转](https://img-blog.csdnimg.cn/661ffdcff6cf4f03911c2e5044fdd0c5.png)