显式映射相比较动态映射(Dynamic mapping)是需要我们在索引创建时就定义字段及其类型。这个和我们传统的 RDMS 数据库一样,在我们写入数据到数据库之前,我们需要工整地定义好每个字段及其类型和长度。Elasticsearch 既可以使用显式映射也可以同时使用动态映射。在许多的应用场景中,如果我们事先知道索引的字段及其类型,那么使用显式映射无疑会使得我们提供索引的速度,因为 Elasticsearch 不会为额外推算新字段的类型而花费时间以及节点之间的同步。这样会减少主节点的计算量。
Elasticsearch 可以智能地根据我们的文档导出映射信息,但是,有可能会以错误的模式定义结束。 幸运的是,Elasticsearch 为我们(用户)提供了方式和方法,以我们想要的方式以索引和映射 API 的形式指定映射定义。
下面列出了两种显式创建(或更新)模式(schema)的可能方法。
- 索引 API:为此,我们可以使用 create index API(不是 mapping API,注意)在创建索引时创建模式定义。 创建索引 API 需要一个包含 JSON 文档形式的所需 schema 定义的请求。 这样,一个新的索引和它的映射定义都是一次性创建的。
- 映射 API:随着我们的数据模型的成熟,有时需要使用新属性更新模式定义。 Elasticsearch 提供了一个 _mapping 端点来执行此操作,允许我们添加其他字段及其数据类型。 我们也可以第一次使用此 API 将模式添加到新创建的索引中。
例如,请看下图,它演示了如何使用这两个 API 创建 movies 索引。

使用索引 API 进行映射
在创建索引时创建映射定义相对简单。 我们只需在索引名称后发出一个 PUT 命令,并将包含所有必填字段及其详细信息的映射对象作为请求的主体传递。 下图直观地解释了成分。
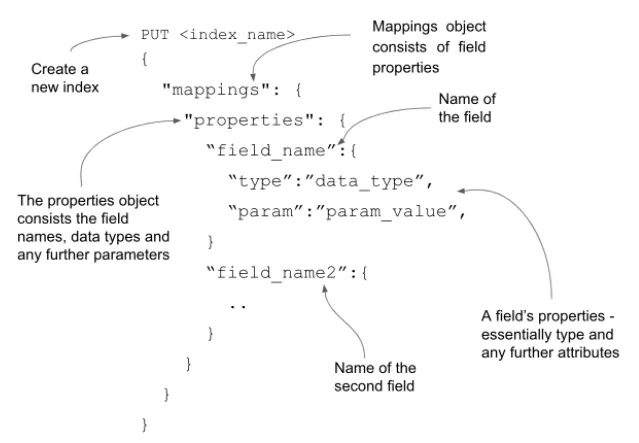
让我们为 employee 模型开发一个映射模式 —— 员工信息被建模为一堆字段,如 name、age、email 和 address。
我们通过 HTTP PUT 操作调用映射 API,将包含这些字段的文档索引到 employees 索引中。 请求正文封装了我们字段的属性,如下所示。
# Creating an employees schema upfront
PUT employees
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"mmail": {
"type": "keyword"
},
"address": {
"properties": {
"street": {
"type": "text"
},
"country": {
"type": "text"
}
}
}
}
}
}脚本准备就绪后,使用 Kibana 的 DevTools 执行此命令。 你应该会收到一个成功的响应,表明索引已创建。 在这个例子中,我们将类型指定给 Elasticsearch; 现在我们可以控制模式。
你是否注意到列表中的 address 字段? 它是一种对象类型,由附加字段、street 和 country 组成。 需要注意的一件重要事情是,adress 字段的类型并没有被提及为对象(object)类型,尽管我们说它是封装其他数据字段的对象。 这样做的原因是 Elasticsearch 默认为任何内部对象推导出对象数据类型。 此外,包含在地址中的子字段 properties 对象有助于定义内部对象的更多属性。
现在我们在生产中有了我们的 employees 索引,假设我们想要扩展模型以具有更多属性,例如部门、电话号码等。 为了满足这一要求,我们需要在实时索引上使用 _mapping API 添加这些附加字段。
使用 mapping API 更新模式
随着我们项目的成熟,数据模型无疑也会发生变化。 对于我们的员工文档,我们可能想要添加几个属性,如以下代码片段中所示的 joining_date 和 phone_number。
# Additional data to the existing Employee document
{
"name":"John Smith",
"joining_date":"01-05-2021",
"phone_number":"01234567899"
...
}入职日期(joining_date)是一个 date 类型,因为我们要进行与日期相关的操作,比如按入职日期对员工进行排序。 电话号码应按原样存储,因此它符合 keyword 数据类型。 为了使用这些附加字段修改现有员工的模式定义,我们在现有索引上调用 _mapping 端点,在请求对象中声明新字段,如下面的清单所示。
# Updating the existing index with additional fields
PUT employees/_mapping
{
"properties":{
"joining_date":{
"type":"date",
"format":"dd-mm-yyyy"
},
"phone_number":{
"type":"keyword"
}
}
}如果你仔细查看请求正文,就会发现 properties 对象是在根级别定义的,这与使用索引 API 创建模式的方法相反,在索引 API 这种方法中,properties 对象被包装在根级别 mappings 对象中。
更新空索引
我们也可以使用相同的原则在空索引上更新架构。 空索引是在没有任何模式映射的情况下创建的索引 —— 例如,执行 PUT books 命令会创建一个没有模式关联的空 books 索引。
PUT books类似于通过调用具有所需模式定义的 _mapping 端点来更新索引的机制,我们也可以对空索引使用相同的方法。 以下代码片段使用几个字段更新 departments 索引的模式:
# Adding the mapping schema to an empty index
PUT departments/_mapping
{
"properties":{
"name":{
"type":"text"
}
}
}我们已经看到了使用附加字段更新模式的附加情况。 但是如果我们想改变现有字段的数据类型怎么办?
不允许修改现有字段
一旦索引生效(索引是用一些数据字段创建的并且可以运行),就禁止对实时索引上的现有字段进行任何修改。 例如,如果一个字段被定义为 keyword 数据类型并被索引,则它不能更改为不同的数据类型(例如,从 keyword 到 text 数据类型)。 不过,这是有充分理由的。
数据使用现有模式定义进行索引,因此存储在索引中。 如果数据类型已被修改,则对该字段数据的搜索将失败,这会导致错误的搜索体验。 为了避免搜索失败,Elasticsearch 不允许我们修改已有的字段。
那么,你可能会问,还有什么选择呢? 业务需求随着技术需求的变化而变化。 我们如何在实时索引上修复数据类型(也许,我们一开始就错误地创建了它们)? 重新索引是我们的朋友。
在有些情况下,加入你已经定了一个 text 类型的字段,但是你在之后想对这个字段进行聚合。那么你该怎么办呢?你可以详细阅读文章 “Elasticsearch:如何使 Elasticsearch 和 Kibana 中的文本字段可聚合?”。
重新索引数据
这是我们使用重新索引(reindex)技术的地方。 重新索引操作将数据从原始索引获取到具有更新模式定义的新索引。 我们的想法是:
- 使用更新的模式定义创建新索引。
- 使用 reindex API 将数据从旧索引复制到新索引中。 一旦重新索引完成,具有新模式的新索引就可以使用了。 索引对读取和写入操作都是开放的。
- 一旦新索引准备就绪,我们的应用程序就会切换到新索引。
- 一旦我们确认新索引按预期工作,我们就会搁置旧索引。
重新索引是一项功能强大的操作。你可以详细阅读文章 “Elasticsearch: Reindex 接口”。但让我简要介绍一下 API 的工作原理。 假设我们希望将数据从现有(source)索引迁移到目标(dest)索引,我们发出重建索引调用,如下面的代码所示:
# Migrating data to a new index with new schema
POST _reindex
{
“source”: {“index”: “orders”},
“dest”: {“index”: “orders_new”}
}新索引 orders_new 可能是通过对模式的更改创建的,然后来自旧索引(orders)的数据被迁移到这个新创建的索引并更新了声明。
别名在迁移中起着重要作用
如果你的应用程序与现有索引紧密相关,则迁移到新索引可能需要更改代码或配置。 例如,在上面的例子中,所有指向 orders 索引的查询现在都将针对新创建的 orders_new 索引执行 —— 这可能需要更改代码。
避免这种情况的理想方法是使用别名。 别名是给索引的替代名称。 别名帮助我们在索引之间无缝切换,停机时间为零。 你可以详细阅读文章 “Elasticsearch:如何轻松安全地对实时 Elasticsearch 索引重新索引你的数据”。
类型强制 - type coercion
有时,在为文档建立索引时,数据的类型可能不正确 —— 整数定义的字段可能会使用字符串值进行索引。 Elasticsearch 尝试转换这种不一致的类型,从而避免索引问题。 这是一个称为类型强制(type coercion)的过程
举个例子:一个 float 类型的 rating 字段可能收到一个用字符串括起来的值:"rating": "4.9" 而不是 "rating": 4.9。 Elasticsearch 在遇到数据类型的不匹配值时是宽容的。 它通过提取值并将其存储在原始数据类型中来索引文档。请详细阅读文章 “Elasticsearch:Elasticsearch 中的数据强制匹配”。
在本文中,我们研究了如何为我们拥有的数据模型控制和创建映射模式。