ES官方博客:https://elasticstack.blog.csdn.net/?type=blog
一、rolloverAPI
https://elasticstack.blog.csdn.net/article/details/102728987
1.1 rollover命令
POST /log_alias/_rollover
{
"conditions":{
"max_age":"7d",
"max_docs":1400,
"max_size":"5gb"
}
}显示的结果是:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"old_index" : "logs-2019.10.21-1",
"new_index" : "logs-2019.10.21-000002",
"rolled_over" : true,
"dry_run" : false,
"conditions" : {
"[max_docs: 1400]" : true,
"[max_size: 5gb]" : false,
"[max_age: 7d]" : false
}
}
1.2 配合 ILM 一起使用
Rollover 在实战中,我们可以配合 ILM 一起使用。我们可以定义如下的一个 ILM policy:
PUT _ilm/policy/50gb_30d_delete_90d_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50GB",
"max_age": "30d",
"max_docs": 10000
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}
在上面,我们定义了如下的一个 policy:
- 当一个索引的文档数超过 10000,或者文档的时间超过 30 天,或者索引的大小超过 50G,之后摄入的文档就会自动 rollover
- 文档超过 90 天,就会被自动删除
我们接着就定义如下的 index template:
PUT _index_template/timeseries_template
{
"index_patterns": [
"myindex-*"
],
"data_stream": {},
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "50gb_30d_delete_90d_policy"
}
}
}
之后,所有新创建的以 myindex- 为开头的索引将会自动采纳 50gb_30d_delete_90d_policy 策略,也就是该索引将会根据 50gb_30d_delete_90d_policy 所定义的条件自动 rollover。针对上面的 data_stream,我们可以采用如下的方式来创建索引:
PUT _data_stream/myindex-ds
更多关于 data stream 的知识可以参考文章 “Elastic:Data stream 在索引生命周期管理中的应用”https://elasticstack.blog.csdn.net/article/details/110528838。
ILM 可以通过简单的设置更新轻松集成到现有索引中。 要将策略添加到现有索引,你必须仅提供策略名称:
PUT myindex/_settings
{
"index": {
"lifecycle": {
"name": "50gb_30d_delete_90d_policy"
}
}
}
1.3 其他参数
rollover 发生时间:indices.lifecycle.poll_interval
PUT _cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "10s"
}
}
二、冷热数据
2.1 配置分片分配感知
标记节点温度
通过phases 定义冷热数据管理周期
运行两个 node 的 Elasticsearch 集群
我们可以参考文章 Elasticsearch:运用 shard 过滤器来控制索引分配给哪个节点_Elastic 中国社区官方博客的博客-CSDN博客运行起来两个 node 的 cluster。其实非常简单,当我们安装好 Elasticsearch 后,打开一个 terminal,并运行如下的命令:
./bin/elasticsearch -E node.name=node1 -E node.attr.data=hot -Enode.max_local_storage_nodes=2
它将运行起来一个叫做 node1 的节点。同时在另外 terminal 中运行如下的命令:
./bin/elasticsearch -E node.name=node2 -E node.attr.data=warm -Enode.max_local_storage_nodes=2
它运行另外一个叫做 node2 的节点。我们可以通过如下的命令来进行查看:
GET _cat/nodes?v
显示两个节点:

我们可以用如下的命令来检查这两个 node 的属性:
GET _cat/nodeattrs?v&s=name

显然其中的一个 node 是 hot,另外一个是 warm。
2.2 配置 ILM 策略
ILM 策略分为四个主要阶段 - 热、温、冷和删除。(还可以试用 滚动更新操作用于管理每个索引的大小或寿命。强制合并操作可用于优化索引。冻结操作可用于减少集群中的内存压力。)
基本操作
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}
这个策略规定,在索引存储时间达到 30 天后或者索引大小达到 50GB(基于主分片)时,就会滚动更新该索引并开始写入一个新索引。
ILM 和索引模板
关联ILM索引和模板
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
对于包括滚动更新操作的策略,还必须在创建索引模板后使用写入别名启动索引。
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}
配置用于采集的 ILM 策略
Beats 和 Logstash 都支持 ILM,并在启用后将设置一个类似上例所示的默认策略。此外,Beats 和 Logstash 还将处理滚动更新操作的所有要求。这就意味着,当为 Beats 和 Logstash 启用 ILM 时,除非您的每天索引量很大(大于 50GB/天),否则索引大小将可能是确定何时创建新索引的主要因素(这是一件好事!)。从 7.0.0 开始,带有滚动更新的 ILM 将是 Beats 和 Logstash 的默认配置。
不过,由于针对热温冷架构没有一成不变的设置,因此,Beats 和 Logstash 将不会随附热温冷策略。我们可以制定一个适用于热温冷的新策略,并在这一过程中进行一些优化。
我们虽然可以更新 Beats 或 Logstash 默认策略,但这会模糊默认值和定制值之间的界限。此外,更新默认策略还会增加未来版本无法应用正确策略的风险(7.0+ 的 Beats 模板默认值将会有更改)。我们可以使用 Beats 和 Logstash 配置,通过其各自的配置来定义定制策略。这种方法也未尝不可,但您可能需要更改数百(或数千)个 Beats 的配置才能更改 ILM 策略。这里描述的第三种方法,通过利用多模板匹配来允许 Elasticsearch 保持对 ILM 策略的完全控制。
针对热温冷优化 ILM 策略
首先,让我们创建一个针对热温冷架构优化的 ILM 策略。再次强调,这不是一刀切的设置,您的要求将有所不同。
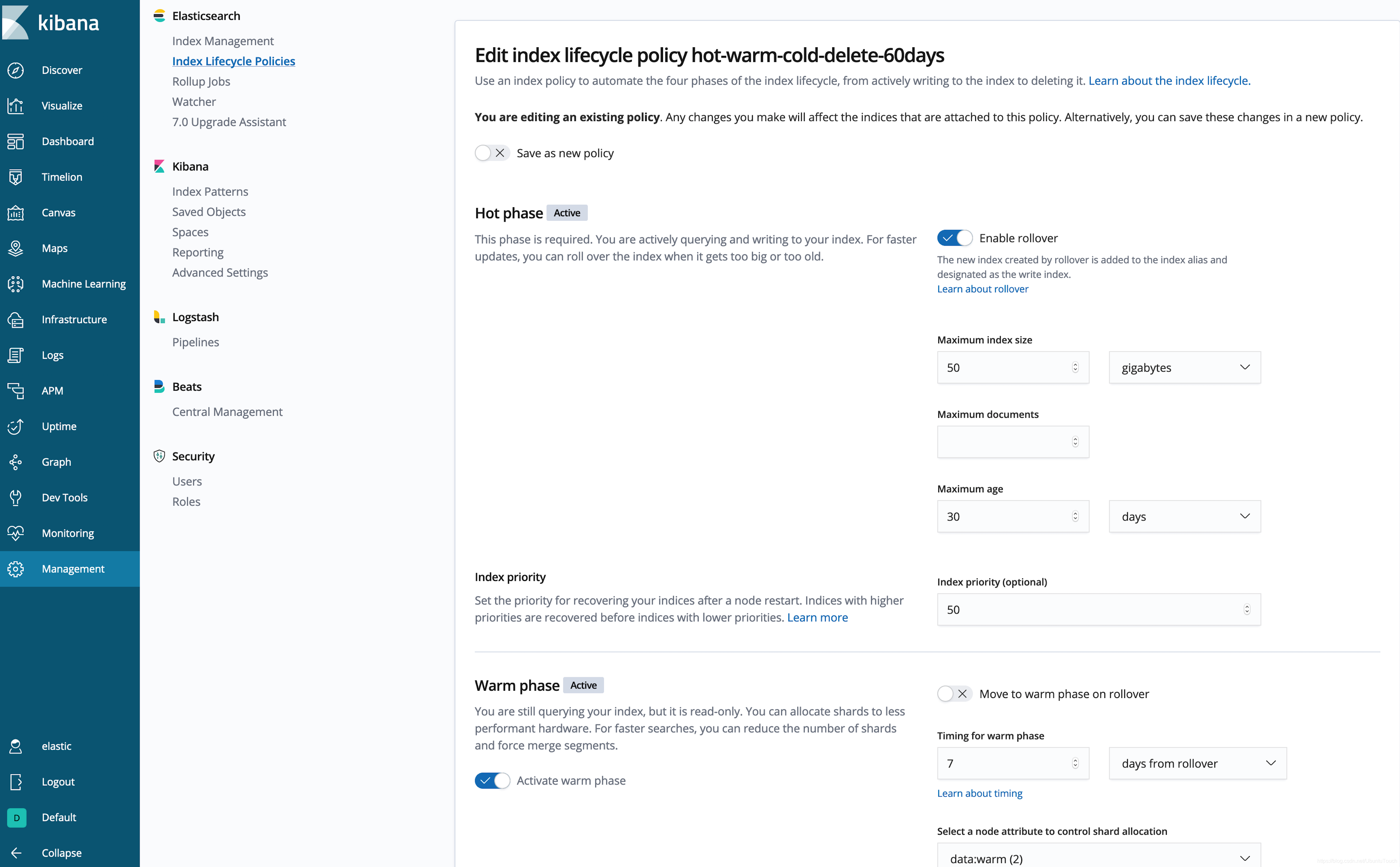
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size":"50gb",
"max_age":"30d"
},
"set_priority": {
"priority":50
}
}
},
"warm": {
"min_age":"7d",
"actions": {
"forcemerge": {
"max_num_segments":1
},
"shrink": {
"number_of_shards":1
},
"allocate": {
"require": {
"data": "warm"
}
},
"set_priority": {
"priority":25
}
}
},
"cold": {
"min_age":"30d",
"actions": {
"set_priority": {
"priority":0
},
"freeze": {},
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age":"60d",
"actions": {
"delete": {}
}
}
}
}
}
热
这个 ILM 策略首先会将索引优先级设置为一个较高的值,以便热索引在其他索引之前恢复。30 天后或达到 50GB 时(符合任何一个即可),该索引将滚动更新,系统将创建一个新索引。该新索引将重新启动策略,而当前的索引(刚刚滚动更新的索引)将在滚动更新后等待 7 天再进入温阶段。
温
索引进入温阶段后,ILM 会将索引收缩到 1 个分片,将索引强制合并为 1 个段,并将索引优先级设置为比热阶段低(但比冷阶段高)的值,通过分配操作将索引移动到温节点。完成该操作后,索引将等待 30 天(从滚动更新时算起)后进入冷阶段。
冷
索引进入冷阶段后,ILM 将再次降低索引优先级,以确保热索引和温索引得到先行恢复。然后,ILM 将冻结索引并将其移动到冷节点。完成该操作后,索引将等待 60 天(从滚动更新时算起)后进入删除阶段。
删除
我们还没有讨论过这个删除阶段。简单来说,删除阶段具有用于删除索引的删除操作。在删除阶段,您将始终需要有一个 min_age 条件,以允许索引在给定时段内待在热、温或冷阶段。
在 Kibana 中创建 ILM 策略
不喜欢写一大堆 JSON? (我也是。) 让我们使用 Kibana UI 来检查或创建策略:
三、别名应用
3.1 创建测试索引:
PUT my_test_index
响应结果:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my_test_index"
}
3.2 创建索引别名:
POST _aliases
{
"actions": [
{
"add": {
"index": "my_test_index",
"alias": "my_test_index_alias"
}
}
]
}
响应结果:
{
"acknowledged" : true
}
3.3 删除索引别名
POST _aliases
{
"actions": [
{
"remove": {
"index": "my_test_index",
"alias": "my_test_index_alias"
}
}
]
}
响应效果:
{"acknowledged" : true}