世界上70%的相关性数据可以被储存为表格数据,即类似Excel,Csv类型的数据,如何去查询和分析相关性的数据?对于少量数据,我们可以使用Excel,更多一点数据,我们可以使用Python, pandas 处理大数据 ;那么亿万条数据,我们此时就需要借助 SQL,那么掌握常用的 SQL 需要对处理大型数据非常必要。
下面我将介绍10个SQL中常用的分析技巧,供大家学习参考。
1 SELECT all columns with LIMIT
一般,我们需要了解数据的大概,那么我们一般会选择前5行进行打印,看看具体内容包括哪些!SELECT 命令会选择所有的行、列,全部进行打印时,浪费时间、电脑内存,Limit命令可以查看数据中的前几行。
SELECT * FROM Customers LIMIT 3;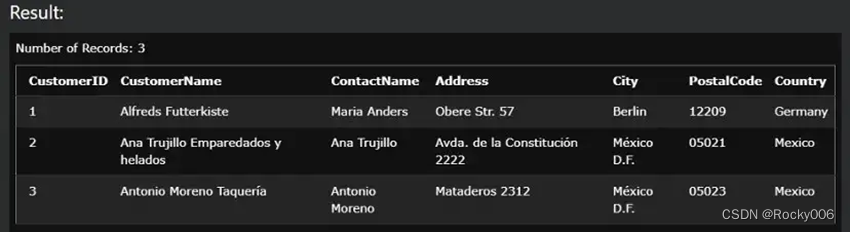
Limit在MySQL这种可以正常工作,在其他的SQL中可能需要使用TOP, FETCH FIRST ROWS ONLY
2 WHERE clause
WHERE可以对特定列的值进行过滤。例如,我们过滤来自西班牙的国家,并且返回对应的城市。
SELECT City
FROM Customers
WHERE Country = "Spain";
我们也可以对城市进行 Unique:
SELECT DISTINCT City
FROM Customers
WHERE Country = "Spain";
3 GROUP BY and HAVING clause
当我们想要对数据中相同观测值进行分组时,我们可以使用 GROUP BY, HAVING 可以用来过滤加总的数据,常用的包括 sum、count。
HAVING 用来处理加总数据,而WHERE用来处理非加总数据。
我们有世界各国的数据,想要输出人口大于500,000,000的洲:
SELECT continent, SUM(population)
FROM world
GROUP BY continent
HAVING SUM(population)>500000000. --filter the aggregated values
4 Order By clause
Order By 将数据按照选择的列进行升序或者排列:
将选择的数据按照人口降序排列:
SELECT name, population
FROM world
WHERE population > 200000000
ORDER BY population DESC;
5 Date Function
时间处理函数依赖于SQL的内核,不同SQL的时间处理函数有所差异,DATEPART 可以提取时间中的年月日。
提取时间中的年、月:
SELECT whn,
DATEPART(YEAR, whn) AS yr,
DATEPART(MONTH, whn) AS mnth
FROM eclipse
6 Joins
Joins 包括笛卡尔积、内积、外积、Self Join,接下来我们将介绍 Inner、left join 和 right join 。

inner
inner 可以输出两个表或者更多表中共同的行,类似数学中的韦恩图,取两个集合的交集。
当我们取两个集合共同id, 并且仅仅输出前五行:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers
ON Orders.CustomerID = Customers.CustomerID
LIMIT 5; 

left join
left join 仅仅输出左边表中的所有行,输出结果中右边表不存在的值为Null。
左连表, 按照 Customers.CustomerName进行升序排列:
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders
ON Customers.CustomerID=Orders.CustomerID
ORDER BY Customers.CustomerName
LIMIT 5;

right join
右连表与左连表相反,返回右表中的所有行,左表不存在的行将填充Null值。
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName
FROM Orders
RIGHT JOIN Employees
ON Orders.EmployeeID = Employees.EmployeeID
ORDER BY Orders.OrderID; 
7 Case When clause
Case When 可以让我们根据现有的数据生成一些新的列,类似于Python、Exce中的if-else语法。
例如,基于国家人口数据,生成新列population_bucket:
SELECT name, population
,CASE WHEN population<1000000 THEN 'small'
WHEN population<10000000 THEN 'medium'
ELSE 'large' --ELSE is executed if no condition is satisfied
END as population_bucket --name of the new column
FROM world
Remark: 没有else时,对应的输出将为 Null
8 Subqueries
子查询在SQL中尤为重要,一旦我们领悟,我们将读懂更为复杂的SQL语句。
例如,输出人口大于俄罗斯的国家的名字:
SELECT name FROM world
WHERE population >
(SELECT population FROM world
WHERE name='Russia')9 Window function
窗口函数包括以下三种:
加总函数(Aggregate functions):SUM, AVG, MAX, MIN等
排序函数(Ranking functions):RANK, ROW_NUMBER等
分析函数(Analytic functions):LEAD, LED等
另外,我们可以使用Over 语句去定义这些窗口函数,Over 语句和 PARTITION BY 常常联合使用。
例如,对每年每个党派的投票按照降序排列:
SELECT yr,party, votes,
RANK() OVER (PARTITION BY yr ORDER BY votes DESC) as posn
FROM ge
WHERE constituency = 'S14000021'
ORDER BY party,yr
10 Union
Union 常常用来竖直方向组合多个数据集,输入的数据应该具有以下两个特征:
列的的名字和数量是形同的
每列的数据类型是相同的
SELECT DISTINCT City
FROM
(SELECT City FROM Customers
UNION
SELECT City FROM Suppliers)
LIMIT 5;例如,组合消费者和供应者所在的城市: