最近做一个数据同步任务,从hive仓库同步数据到pg,Hive有4000w多条数据,但datax只同步了280w就结束了,也没有任何报错。
看了下datax源码,找到HdfsReader模块DFSUtil核心实现源码读取orc格式的文件方法:
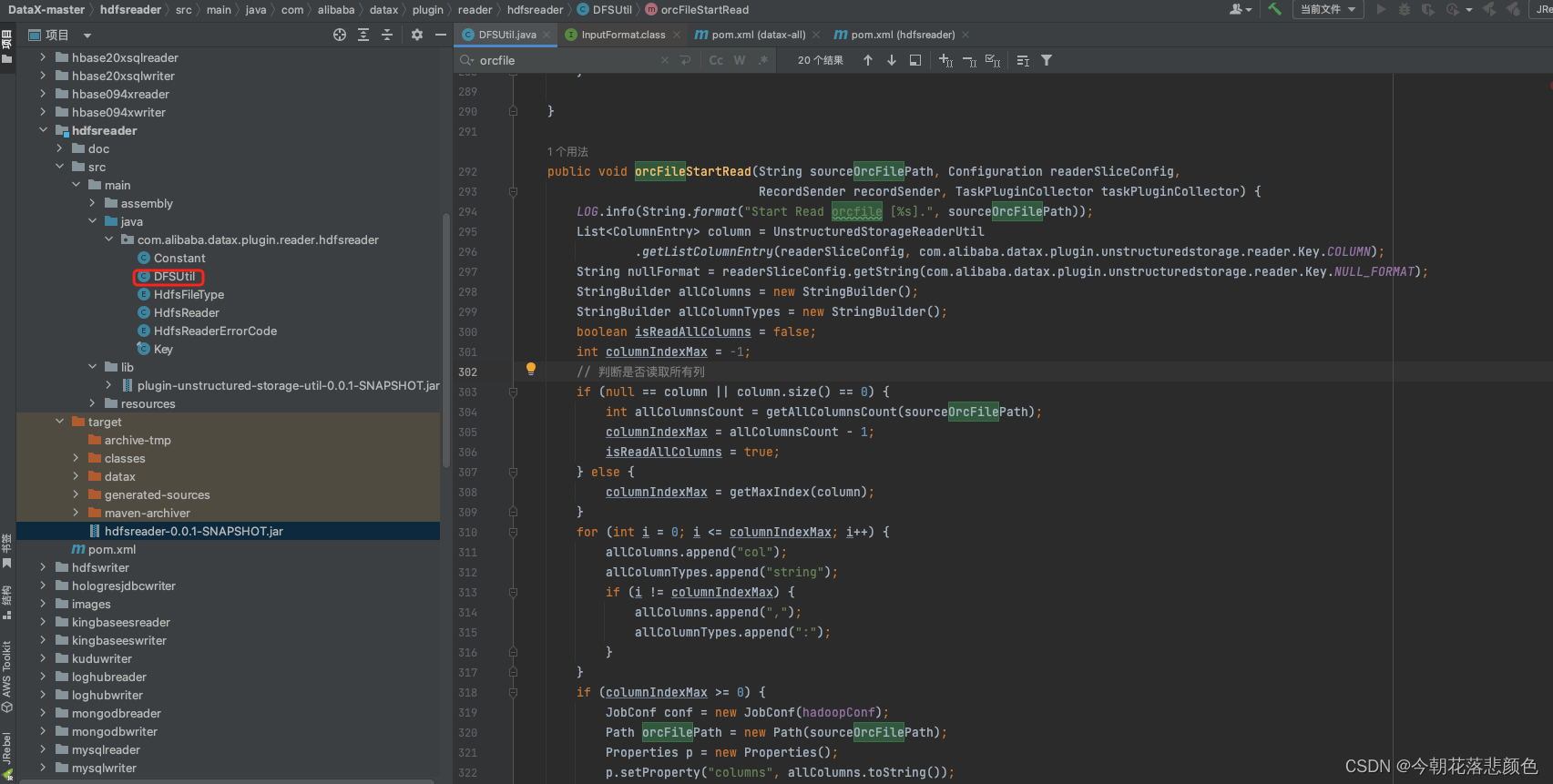
public void orcFileStartRead(String sourceOrcFilePath, Configuration readerSliceConfig,
RecordSender recordSender, TaskPluginCollector taskPluginCollector) {
LOG.info(String.format("Start Read orcfile [%s].", sourceOrcFilePath));
List<ColumnEntry> column = UnstructuredStorageReaderUtil
.getListColumnEntry(readerSliceConfig, com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COLUMN);
String nullFormat = readerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.NULL_FORMAT);
StringBuilder allColumns = new StringBuilder();
StringBuilder allColumnTypes = new StringBuilder();
boolean isReadAllColumns = false;
int columnIndexMax = -1;
// 判断是否读取所有列
if (null == column || column.size() == 0) {
int allColumnsCount = getAllColumnsCount(sourceOrcFilePath);
columnIndexMax = allColumnsCount - 1;
isReadAllColumns = true;
} else {
columnIndexMax = getMaxIndex(column);
}
for (int i = 0; i <= columnIndexMax; i++) {
allColumns.append("col");
allColumnTypes.append("string");
if (i != columnIndexMax) {
allColumns.append(",");
allColumnTypes.append(":");
}
}
if (columnIndexMax >= 0) {
JobConf conf = new JobConf(hadoopConf);
Path orcFilePath = new Path(sourceOrcFilePath);
Properties p = new Properties();
p.setProperty("columns", allColumns.toString());
p.setProperty("columns.types", allColumnTypes.toString());
try {
OrcSerde serde = new OrcSerde();
serde.initialize(conf, p);
StructObjectInspector inspector = (StructObjectInspector) serde.getObjectInspector();
InputFormat<?, ?> in = new OrcInputFormat();
FileInputFormat.setInputPaths(conf, orcFilePath.toString());
//If the network disconnected, will retry 45 times, each time the retry interval for 20 seconds
//Each file as a split
//TODO multy threads
InputSplit[] splits = in.getSplits(conf, -1);
RecordReader reader = in.getRecordReader(splits[0], conf, Reporter.NULL);
Object key = reader.createKey();
Object value = reader.createValue();
// 获取列信息
List<? extends StructField> fields = inspector.getAllStructFieldRefs();
List<Object> recordFields;
while (reader.next(key, value)) {
recordFields = new ArrayList<Object>();
for (int i = 0; i <= columnIndexMax; i++) {
Object field = inspector.getStructFieldData(value, fields.get(i));
recordFields.add(field);
}
transportOneRecord(column, recordFields, recordSender,
taskPluginCollector, isReadAllColumns, nullFormat);
}
reader.close();
} catch (Exception e) {
String message = String.format("从orcfile文件路径[%s]中读取数据发生异常,请联系系统管理员。"
, sourceOrcFilePath);
LOG.error(message);
throw DataXException.asDataXException(HdfsReaderErrorCode.READ_FILE_ERROR, message);
}
} else {
String message = String.format("请确认您所读取的列配置正确!columnIndexMax 小于0,column:%s", JSON.toJSONString(column));
throw DataXException.asDataXException(HdfsReaderErrorCode.BAD_CONFIG_VALUE, message);
}
}读文件时 由于hdfs文件存储 是block 形式的。当单个文件 大于 单个block 的size时,出现一个文件 多个block 存储,仅读取了第一个block,造成了数据的部分丢失。
改成如下,用for循环分割块读取数据
public void orcFileStartRead(String sourceOrcFilePath, Configuration readerSliceConfig,
RecordSender recordSender, TaskPluginCollector taskPluginCollector) {
LOG.info(String.format("Start Read orcfile [%s].", sourceOrcFilePath));
List<ColumnEntry> column = UnstructuredStorageReaderUtil
.getListColumnEntry(readerSliceConfig, com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COLUMN);
String nullFormat = readerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.NULL_FORMAT);
StringBuilder allColumns = new StringBuilder();
StringBuilder allColumnTypes = new StringBuilder();
boolean isReadAllColumns = false;
int columnIndexMax = -1;
// 判断是否读取所有列
if (null == column || column.size() == 0) {
int allColumnsCount = getAllColumnsCount(sourceOrcFilePath);
columnIndexMax = allColumnsCount - 1;
isReadAllColumns = true;
} else {
columnIndexMax = getMaxIndex(column);
}
for (int i = 0; i <= columnIndexMax; i++) {
allColumns.append("col");
allColumnTypes.append("string");
if (i != columnIndexMax) {
allColumns.append(",");
allColumnTypes.append(":");
}
}
if (columnIndexMax >= 0) {
JobConf conf = new JobConf(hadoopConf);
Path orcFilePath = new Path(sourceOrcFilePath);
Properties p = new Properties();
p.setProperty("columns", allColumns.toString());
p.setProperty("columns.types", allColumnTypes.toString());
try {
OrcSerde serde = new OrcSerde();
serde.initialize(conf, p);
StructObjectInspector inspector = (StructObjectInspector) serde.getObjectInspector();
InputFormat<?, ?> in = new OrcInputFormat();
FileInputFormat.setInputPaths(conf, orcFilePath.toString());
//If the network disconnected, will retry 45 times, each time the retry interval for 20 seconds
//Each file as a split
//TODO multy threads
InputSplit[] splits = in.getSplits(conf, -1);
for (InputSplit split : splits) {
RecordReader reader = in.getRecordReader(split, conf, Reporter.NULL);
Object key = reader.createKey();
Object value = reader.createValue();
// 获取列信息
List<? extends StructField> fields = inspector.getAllStructFieldRefs();
List<Object> recordFields;
while (reader.next(key, value)) {
recordFields = new ArrayList<Object>();
for (int i = 0; i <= columnIndexMax; i++) {
Object field = inspector.getStructFieldData(value, fields.get(i));
recordFields.add(field);
}
transportOneRecord(column, recordFields, recordSender,
taskPluginCollector, isReadAllColumns, nullFormat);
}
reader.close();
}
} catch (Exception e) {
String message = String.format("从orcfile文件路径[%s]中读取数据发生异常,请联系系统管理员。"
, sourceOrcFilePath);
LOG.error(message);
throw DataXException.asDataXException(HdfsReaderErrorCode.READ_FILE_ERROR, message);
}
} else {
String message = String.format("请确认您所读取的列配置正确!columnIndexMax 小于0,column:%s", JSON.toJSONString(column));
throw DataXException.asDataXException(HdfsReaderErrorCode.BAD_CONFIG_VALUE, message);
}
}
然后重新打包成jar,替换datax引擎的hdfsreader-0.0.1-SNAPSHOT.jar
注意:打包的时候可能会提示maven仓库找不到plugin-unstructured-storage-util-0.0.1-SNAPSHOT.jar
解决办法:从datax引擎hdfsreader/lib中拷贝出plugin-unstructured-storage-util-0.0.1-SNAPSHOT.jar,在hdfsreader模块下面建一个lib目录放进去,然后在pom中本地引用。
<dependency>
<groupId>com.unstrucatured</groupId>
<artifactId>unstrucatured</artifactId>
<version>200</version>
<scope>system</scope>
<systemPath>${basedir}/src/main/lib/plugin-unstructured-storage-util-0.0.1-SNAPSHOT.jar</systemPath>
</dependency>
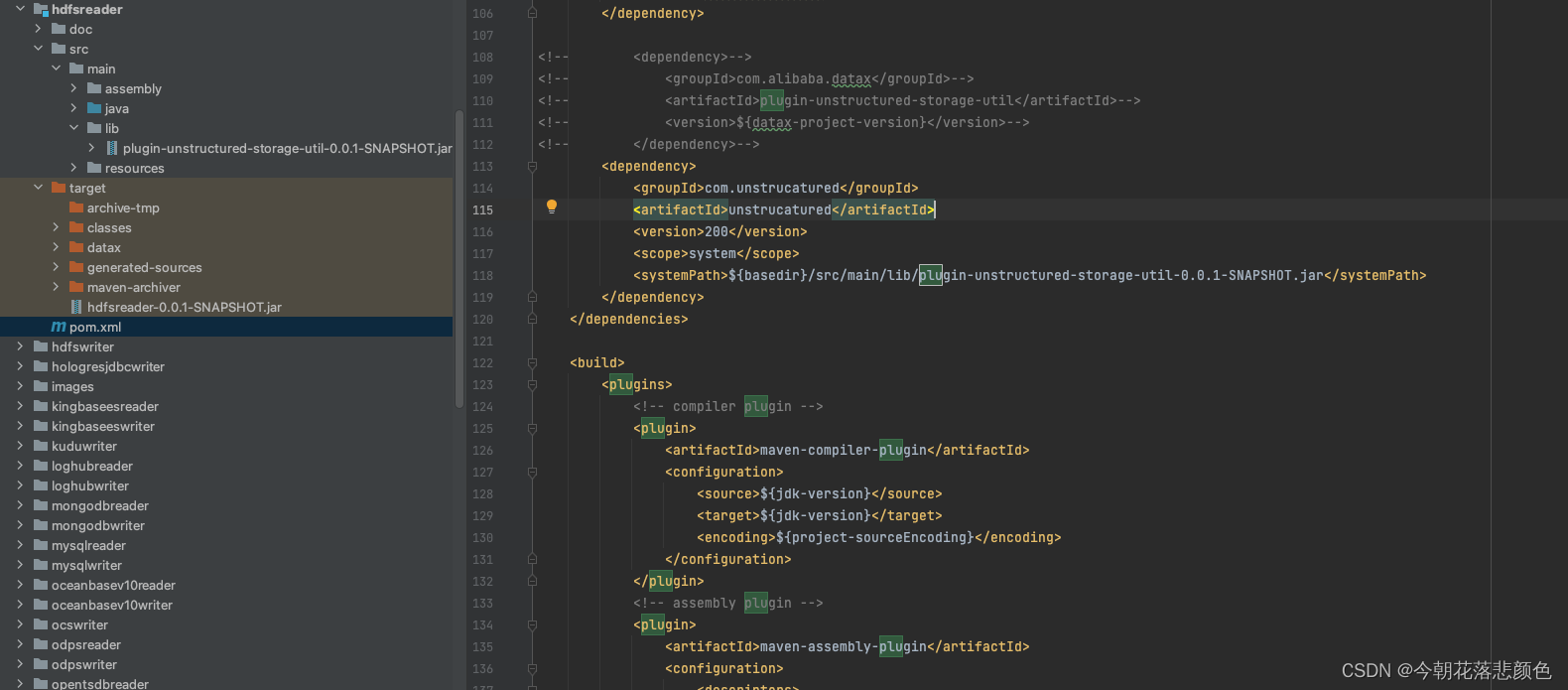
改完后实测完美解决!