坚持看完,结尾有思维导图总结
链表对指针的操作要求不低
- 链表的概念
- 链表的特性
- 链表的功能(最重要)
- 定义和初始化
- 头插头删
- 细节说明
- 尾插尾删
- 寻找链表元素与打印链表
- 在 某位置后插入删除
- 在某位置的插入删除
- 销毁链表
链表的概念
什么是链表
官方概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
解释一下
通俗的链表解释是 通过箭头链接的
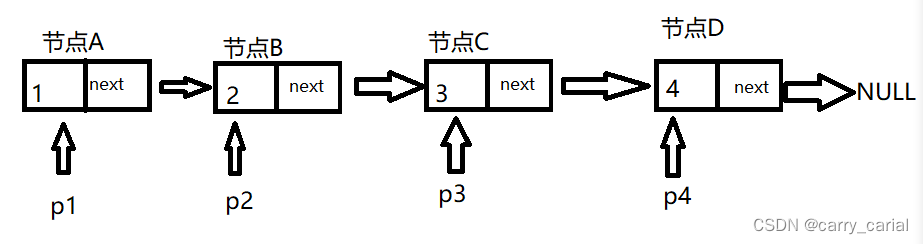 就如同锁链一样链接起来
就如同锁链一样链接起来
两个节点之间的空间都没有任何联系
比如 节点A 和节点 B的空间 本来没有任何联系
但是两者通过 next 的指针
从节点 A 能够访问到节点 B ,然后能够一直向下访问知道 空指针
但是实际上
那个箭头是不存在的,是用来理解用的
实际存在的只有地址,访问过程中调用的也是指针(地址)
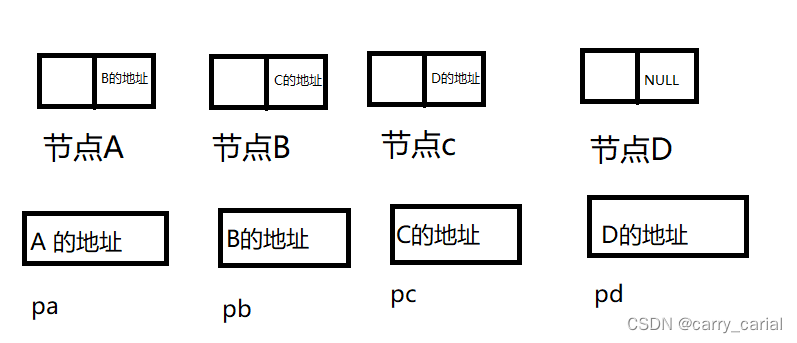
从图片的分析来看
一个节点要被分成两半
一般用来储存数据,一般用来储存下一个节点的地址
所以我们程序上的指针的定义可以这样写
typedef int Datatype;
typedef struct SingleList
{
Datatype Data;
struct SingleList* next;
}SLTNode;
但是下面定义是不对的
typedef int Datatype;
typedef struct SLTNode
{
Datatype data;
SLTNode* next;
}SLTNode;
因为在内容上 next 的定义在 SLTNode 的 typedef 重命名前,语法错误
链表的特性
链表有什么独特的地方?
所谓独特,必须有所对比,这里取顺序表进行对比
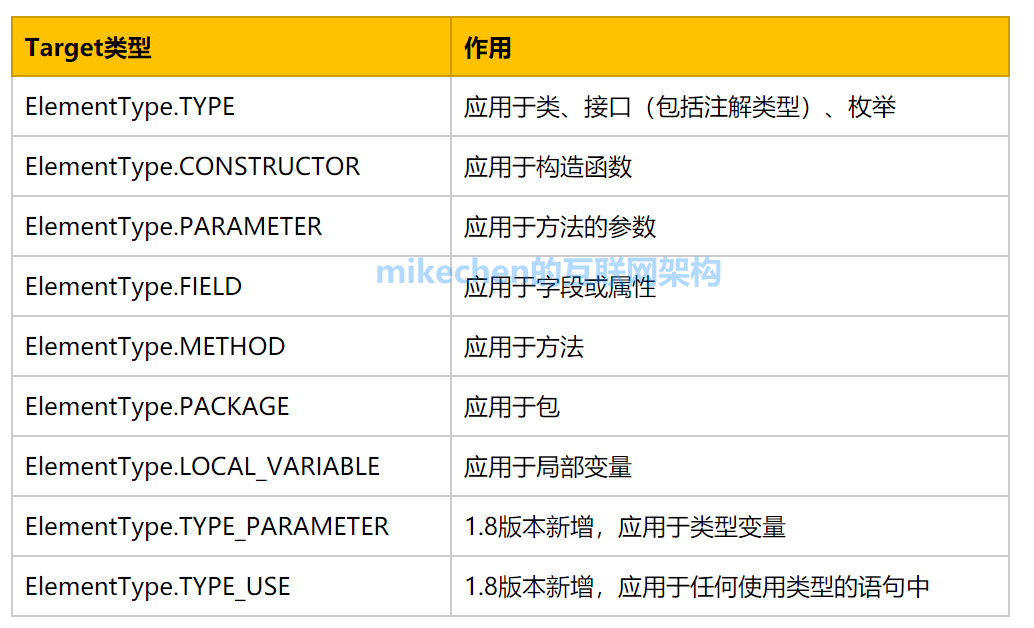
| 不同点 | 链表 | 顺序表 |
|---|---|---|
| 存储空间 | 物理上空间连续 | 逻辑连续,物理上不一定连续 |
| 随机访问 | 可以使用下标直接访问 | 必须遍历找到对应地址 |
| 任意位置插入(重要) | 需要搬移数据 | 只需要修改指向 |
| 容量 | 容量不足的时候需要扩容 | 不需要扩容 |
| 使用场景 | 元素频繁访问 | 任意位置的插入和删除 |
所以链表的优点
- 插入删除很高效
- 寻找元素速度慢
- 空间利用率高,不需要扩容
链表的功能(最重要)
我们如何利用链表存储数据和调用数据?
链表本身就是一个数据结构,就需要定义定义一个数据结构,并且实例化
数据结构用来存放取出数据,访问数据
最终要销毁数据结构
所以有如下要求
定义和初始化
第一个问题,链表是由什么组成的?
是由 内容为存储的数据 和 指向下一个节点的 节点组成
第1. 1 的问题是 节点的类型 如何定义?
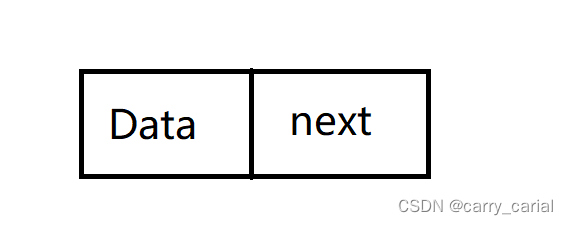
用程序的话说就是:
typedef int STDatatype;
struct ListNode
{
STDatatype data;
struct ListNode* next;
};
typedef struct ListNode SLTNode;
但是只有一个节点的结构是不足的
就像只知道有 int 这个类型但是没有数据一样,光有空壳但是没有血肉
如何在 Node 里面填充血肉?
第1.2 个问题:如何创建节点
主要步骤是:
- 开辟一个节点空间
- 在节点空间中存放数据
对于程序来说就是:
SLTNode* BuyNewNode(Datatype x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if(newnode == NULL)
{
perror("malloc failed");
exit(-1);//故障退出
}
newnode->next = NULL;
newnode->data = x;
return newnode;
}
第1.3 个问题: 如何初始化一个链表
我们使用单链表的时候,只要拿到链表的头就能够操作了
所以因为头的特殊性,我们单独定义一个名字
typedef SLTNode SLTHead;
随后进行链表的创建
步骤
- 循环创建节点
- 将节点链接起来
细节
- 当创建第一个节点时,头结点改变指向第一个节点,之后的节点头结点位置不再改变
//创建 n 个节点
SLTHead* BuildList(int n )
{
SLTHead* phead = NULL;
SLTNode* pcur = phead;
for(int i = 0;i<n;i++)
{
SLTNode* newnode = BuyNewNode(i);
if(phead == NULL)
{
phead = newnode;
pcur = phead;
}
else
{
pcur->next = newnode;
pcur = newnode;
}
}
return phead;
}
我们创建链表的工作就完成了,我们可以调用一下
void Test0()
{
//创建一个有10个节点的链表,保留他的头节点
SLTHead* pList = BuildList(10);
}
头插头删
链表有两端,头为一端,尾为一端
头尾的图
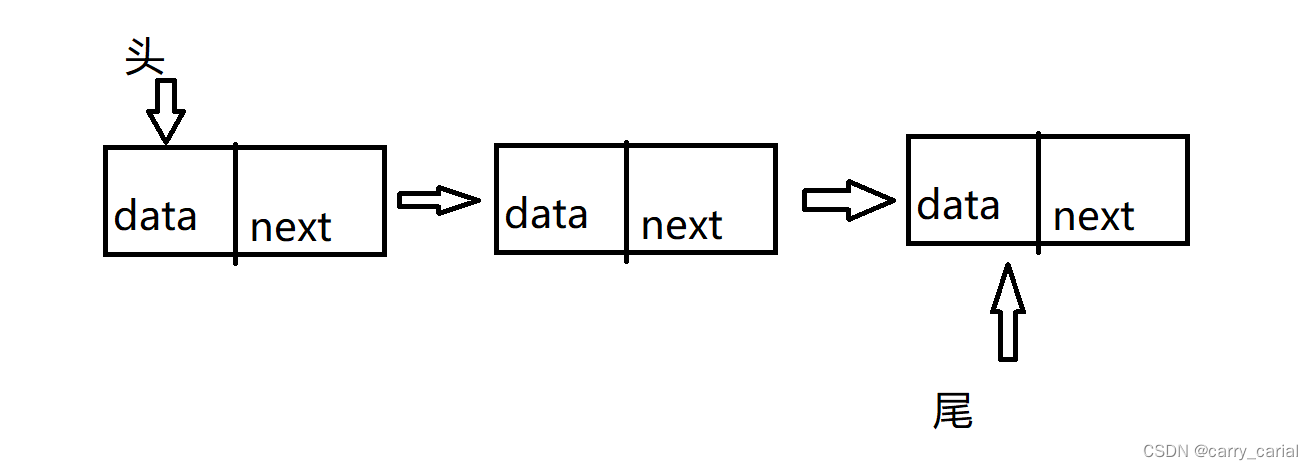
要实现头部的插入删除,我们要解决以下问题
第1.1个小方面,头插
第1.1.1个问题
头插的过程是什么样的?
步骤
- 生成一个新节点newnode
- 这个新节点链接到原来的链表
- 链表头向前移动

程序
第一种程序
void SLTPushFront(SLTHead* phead,Datatype x)
{
SLTNode* newhead = BuyNewNode(x);
newnode->next = phead;
phead = newnode;
}
这个程序是错误的,哪里错了呢?
(这个图片需要放大一点看)
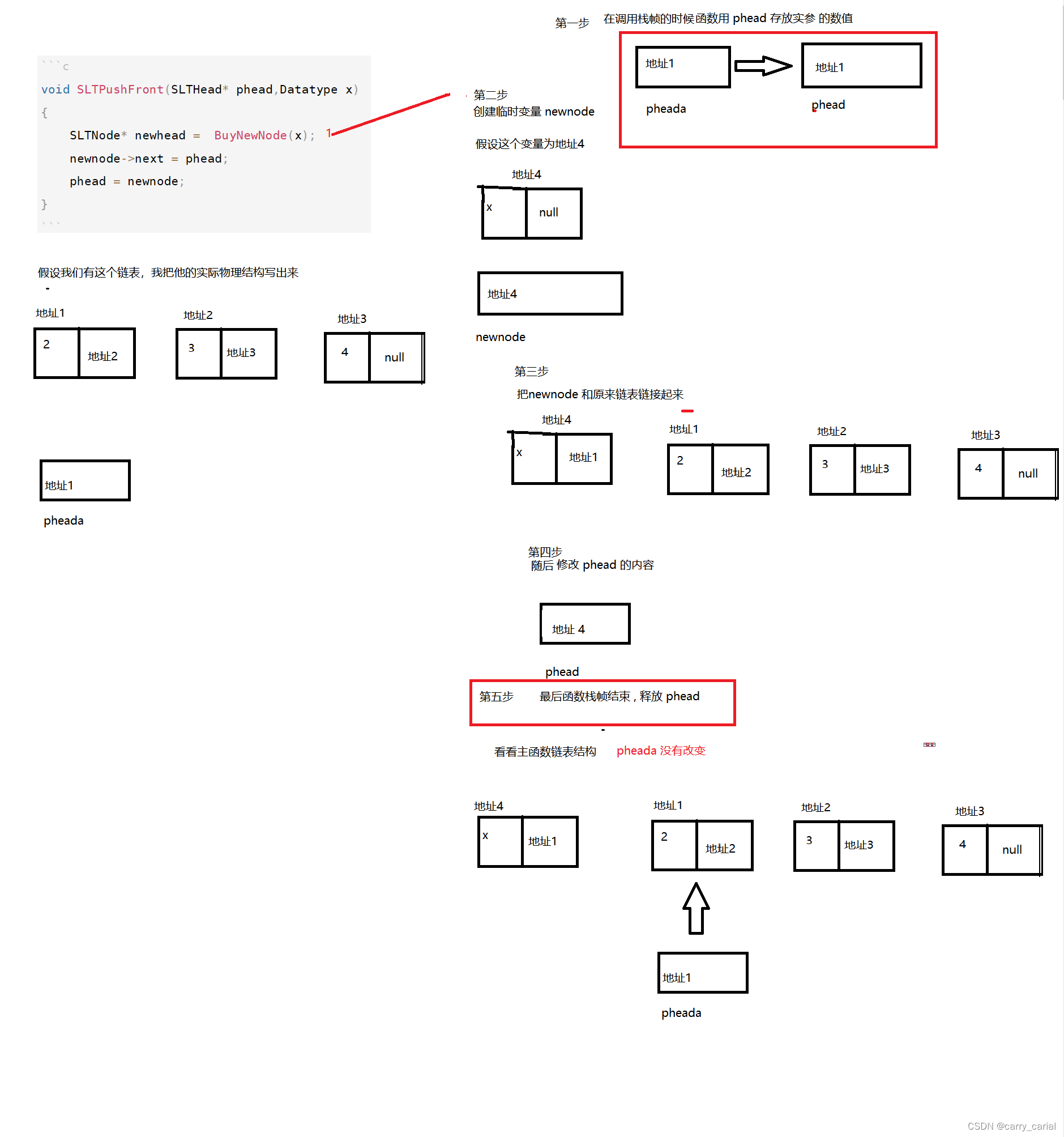
调用函数,创建栈帧的时候
开辟空间把实参的值传给形参
最终函数调用完成后会释放栈帧,销毁变量
如果要改变主函数的类型,就需要传递对应的类型的指针
因为我们要改变的是 头节点的地址,就必须要传形参为指针的地址
正确的程序:
void SLTPushFront(SLTHead** pphead,Datatype x)
{
assert(pphead);
SLTNode* newnode = BuyNewNode(x);
//没有必要对 pcur 判空
SLTNode* pcur = *pphead;
newnode->next = pcur;
*pphead = newnode;
}
我们可以看到,即使链表本来为 null 我们也可以直接进行头插,不需要特殊处理
第1.2个方面,头删
第1.2.个问题
链表的头删是如何工作的?
步骤
- 找到头节点的下一个节点
- 释放头结点
- 令头结点为下一个节点
图解:

第1.2.2个问题
如果链表被删除到空,该做些什么?
如果是 链表已经为 空,那不能再删除,我们可以使用assert来截断
程序
void SLTPopFront(SLTHead** pphead)
{
assert(pphead);
assert(*pphead);
SLTNode* pcur = *pphead;
SLTNode* plast = pcur;
pcur = pcur->next;
free(plast);
*pphead = pcur;
}
难点:
对头指针的改变需要传递指针的地址
细节说明
assert的使用
为什么使用assert ?
因为,在assert报错的时候,程序会定位到报错的位置
在调试的时候出乎意料地节省很多很多时间
(真地非常好用)
尾插尾删
第1.1 个问题,尾插的步骤是什么样子的?
- 找到尾
- 向尾部插入数据
图解:

第1.2 个问题,尾插的难点是什么?
1 如果链表本身没有元素
如果没有元素,就需要改变主函数中的头结点指针,因为要改变头结点指针,所以要传指针的地址
2 找到尾巴的过程
依次遍历,直到 next 为空
程序:
void SLTPushBack(SLTHead** pphead,Datatype x)
{
assert(pphead);
SLTNode* pcur = *pphead;
SLTNode* newnode = BuyNewNode(x);
if(pcur == NULL)
{
*pphead = newnode;
return;
}
while(pcur->next)
{
pcur = pcur->next;
}
pcur->next = newnode;
}
第2.1 个问题,尾删的步骤是什么样子的?
步骤
1 找到尾
2 然后把尾巴删除
第2.2个问题,尾删的难点是什么?
1 上一个节点如果的 next 如果置为空,就无法找到下一个节点,找到下一个节点就无法回溯到上一个节点,所以需要保存上一个节点的位置,所以需要 plast
图解

2 同时,如果原来链表是空,就不能再进行删除
3 如果只有一个元素,头结点就需要置空
程序
void SLTPopBack(SLTHead** pphead)
{
assert(pphead);
assert(*pphead);
SLTNode* pcur = *pphead;
SLTNode* plast = *pphead;
while(pcur->next != NULL)
{
pcur = pcur->next;
plast = pcur;
}
//判断是否只剩下一个节点
if(pcur == plast)
{
free(pcur);
*pphead = NULL;
}
else
{
free(pcur);
plast->next = NULL;
}
}
寻找链表元素与打印链表
第1.1个问题寻找链表元素需要做什么?
需要遍历,然后匹配,返回对应的位置;遍历过程参考尾插的过程
程序:
SLTNode* SLTSearch(SLTHead* phead,Datatype x)
{
SLTNode* pcur = phead;
while(pcur != NULL)
{
if(pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
第2.1个问题,打印的步骤是什么?
还是遍历,然后一个个打印出来
void SLTPrint(SLTHead* phead)
{
SLTNode* pcur = phead;
while(pcur != NULL)
{
printf("%d->",pcur->data);
pcur = pcur->next;
}
printf("NULL");
}
第2.2 个问题
传参为何不用传 SLTNode** ?
因为
在Print中我们只是范围对应的结构体,使用结构体的地址就可以(只是没必要用指针的地址,但是是可以用的)
在Search中我们也没有对结构体的地址进行修改,只是得到对应地址的值,因此也只需要传结构体的地址
在 某位置后插入删除
第1.1个问题
为什么要先说在 pos(位置的代称) 后插入呢?
单链表的特性就是,可以通过上一个节点的 next 寻找到下一个节点,只要我们知道上一个节点的地址,就很容易能够找到下一个节点
第1.2个问题
如何找到上一个节点的位置?
记得在上一个小节,我们写了一个SLTSearch
我们可以通过这个函数找到有对应数据的节点
第1.3 个问题
步骤是什么
- 找到储存对应数据的节点的地址
- 生成新的节点
- 将节点链接到原来的链表
图例解释

第1.4个问题
链接的顺序是什么?
从图上可以看出,是 newnode 先链接到后面,然后再修改上一个节点的指向
因为是单链表,如果先将 pos -> next 指向newnode
pos 原来的后段就丢失了,导致出错
第1.5个问题
如果没有找到对应的节点怎么办?
因为定义中 Search 若没有找到对应的节点,由于这里是在某位置后插入,所以找不到就无法再插入了,就退出了
void SLTInseartBack(SLTNode* pos,SLTDatatype x)
{
if(pos == NULL)
{
return ;
}
SLTNode* newnode = BuyNewNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
//这里是调用
void Test1()
{
PList* phead;//假设这是一个已知链表的头结点的地址
SLTNode* pos = SLTSearch(phead,x);
SLTInseartBack(pos,x);
}
这里相似的,就会有在某个位置后删除
步骤是:
- 找到某个位置
- 找到pos ->next->next
- 将pos->next 删除
图解

第2.1 个问题,如果没找到或者pos 没有元素呢?
在这两种情况下都不能删除
对应程序
void SLTDelBack(SLTNode* pos)
{
if(pos == NULL || pos->next == NULL )
{
return ;
}
SLTNode* pfree = pos->next;
pos->next = pos->next->next;
free(pfree);
}
在某位置的插入删除
难点: 链表指针无法访问到前一个元素
首先第1.1个问题
我们想用这个函数做什么?
我们可以通过 Search 找到对应的 pos
我们想直接在 pos 的位置上插入或者删除元素,这是我们的目的
第1.2 个问题
这个函数实现的难点是什么?
因为是单链表,不能找到pos 前一个位置,所以需要遍历找到前一个位置
具体步骤
- 利用 search 找到 pos
- 利用遍历找到pos 前一个元素的位置
- 在前一个位置的后面插入删除
图例解析

第1.3个问题
如果pos 是空是什么情况?
如果 pos 是空,那么就意味着是链表的尾部,这就说明是尾插和尾删
第1.4个问题
如果一开始就没有元素呢?
一开始没有元素就需要改变头结点指针的参数
所以传参需要传头结点指针的地址
相当于空链表的尾插
第1.5个问题
如果 pos指向的是第一个元素呢?
我们需要从让新元素排到第一个
这个时候情况就变成了头插
所以对应的程序是
void SLTInsert(SLTNode** pphead,SLTNode* pos,Datatype x)
{
assert(pphead);
SLTNode* pcur = *pphead;
if(pcur == NULL || pos == NULL)
{
SLTPushBack(pphead,x);
return ;
}
if (pcur == pos)
{
SLTPushFront(pphead,x);
return;
}
SLTNode* newnode = BuyNewNode(x);
SLTNode* newnode = BuyNewNode(x);
SLTNode* pnext = pcur->next;
while(pnext != pos)
{
pcur = pnext;
pnext = pnext->next;
}
newnode->next = pnext;
pcur->next = newnode;
}
相对应的也有对应位置的删除
什么步骤呢?
- 找到对应的位置
- 利用遍历找到pos 上一个节点
- 删除pos的元素
问题2.1
尾删是不是一种特殊情况呢?
这个时候尾删, pos 就必须指向一个确定的位置,和普通情况一样,因此不用特殊处理
即使是只剩下一个节点,也可以当做头删来处理
图例解析

void SLTErase(SLTNode** pphead,SLTNode* pos)
{
assert(pphead);
SLTNode* pcur = *pphead;
if(pos == NULL)
{
return ;
}
if(pos == pcur)
{
SLTPopFront(pphead);
return;
}
SLTNode* pre = pcur;
while(pcur != pos)
{
pre = pcur;
pcur = pcur->next;
}
pre->next = pcur->next;
free(pcur);
}
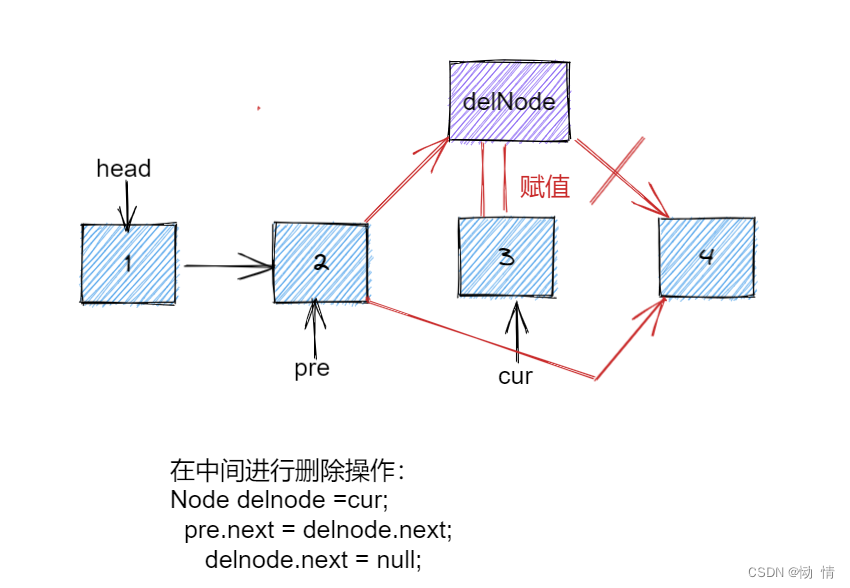
注意:
有一个值得注意的地方
就是 每次 pos 在 位置删除后,这个pos 就不能用了,要在函数外置为 NULL
销毁链表
销毁链表的步骤是?
遍历然后一个个销毁
但是每次要把将要销毁的元素的后一个元素保存起来
图例解析

程序实现
void SLTDestroy(SLTNode* pphead)
{
assert(pphead);
SLTNode* pcur = *pphead;
SLTNode* pre = *pphead;
while(pcur != NULL)
{
pre = pcur;
pcur = pcur->next;
free(pre);
}
*pphead = NULL;
}
希望大家看完,能够有所收获
如果有错误,请指出我一定虚心改正
动动小手点赞
鼓励我输出更加优质的内容