聊聊StarRocks向量化执行引擎-过滤操作
StarRocks是开源的新一代极速MPP数据库,采用全面向量化技术,充分利用CPU单核资源,将单核执行性能做到极致。本文,我们聊聊过滤操作是如何利用SIMD指令进行向量化操作。
过滤操作的SIMD向量化函数是filter_range,我们以binary类型的列为例:
BinaryColumnBase<T>::filter_range
执行过程如下图所示:
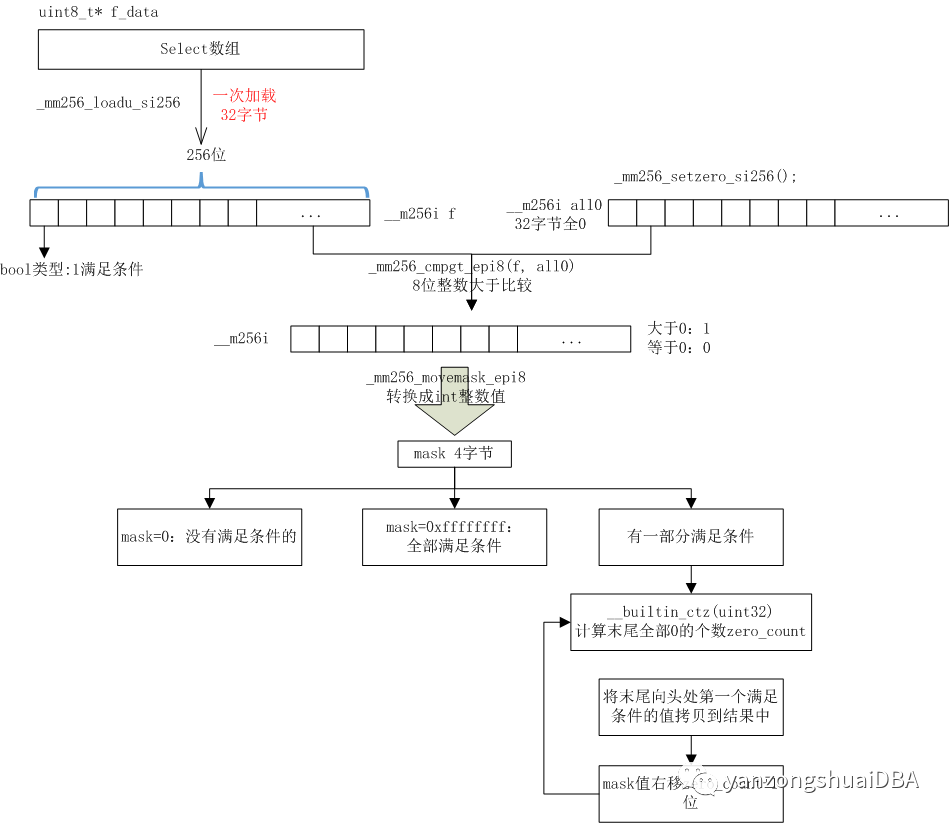
1、通过1个字节uint8_t类型的f_data数组来表示是否满足过滤条件,1表示满足条件,0表示不满足
2、AVX2指令集环境下:通过_mm256_loadu_si256封装的指令函数加载256位长度值到寄存器,也就是32字节值f
3、_mm256_setzero_si256生成256位的0值all0
4、_mm256_cmpgt_epi8函数将f和all0每个字节进行并行比较,也就是32个字节并行比较,f中字节>all0中字节值时,对应结果位为1,否则为0
5、将第4步的值通过_mm256_movemask_epi8转换成int整数mask。比如10001111111111111,转换后为36863,其中f_data[0]为1,f_data[1]为0...
6、mask等于0,表示没有一个满足条件。
7、mask等于0xffffffff,表示全部满足条件,需要将32个数据全部拷贝到结果集中
8、mask等于其他值时,表示有一部分值满足条件。这个时候需要特殊处理:
1)通过__builtin_ctz(mask)计算mask中0的个数zero_count。比如:
11100000:有5个0
2)mask右移6位,即11,值3。其实就是跳过不满足的行
3)_offsets[i]数组表示第i个值的偏移。
size = _offsets[start_offset + i + 1] - _offsets[start_offset + i]即为第一个满足条件值的偏移,即第6位对应的值。
4)将满足条件的值拷贝到结果集
memmove(data + _offsets[result_offset], data + _offsets[start_offset + i], size)5)返回1)步继续计算。
注:当过滤数组的值比较稀疏时,比如“00010001...”能够大量减少比较,但是如果过滤数组的值紧密时,性能就不太高效了。
9、当然,比较数组不一定正好是256位的倍数,所以需要处理尾数据。对于尾数据,就不能利用SIMD指令了,需要走遍历过滤数组的分支,来一个一个的进行判断了:
for (auto i = start_offset; i < to; ++i) {
if (filter[i]) {//一个一个的进行判断
DCHECK_GE(_offsets[i + 1], _offsets[i]);
T size = _offsets[i + 1] - _offsets[i];
// copy data
memmove(data + _offsets[result_offset], data + _offsets[i], size);
// set offsets
_offsets[result_offset + 1] = _offsets[result_offset] + size;
result_offset++;
}
}