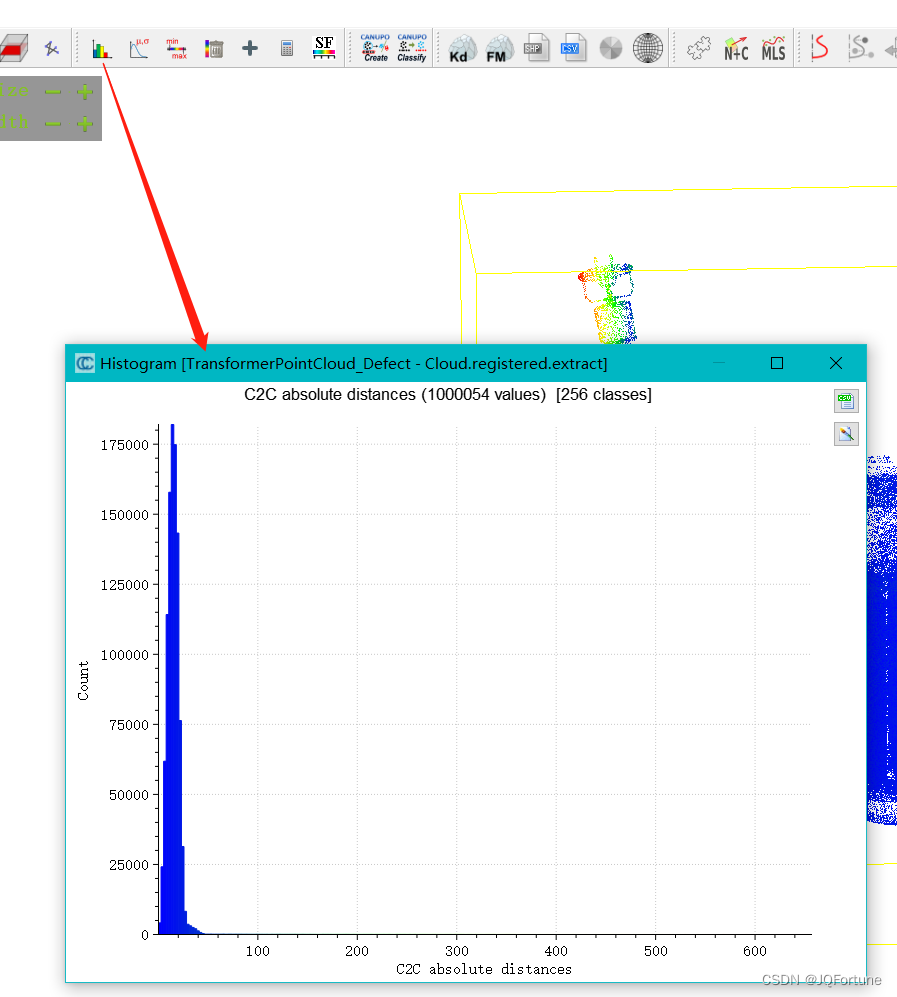
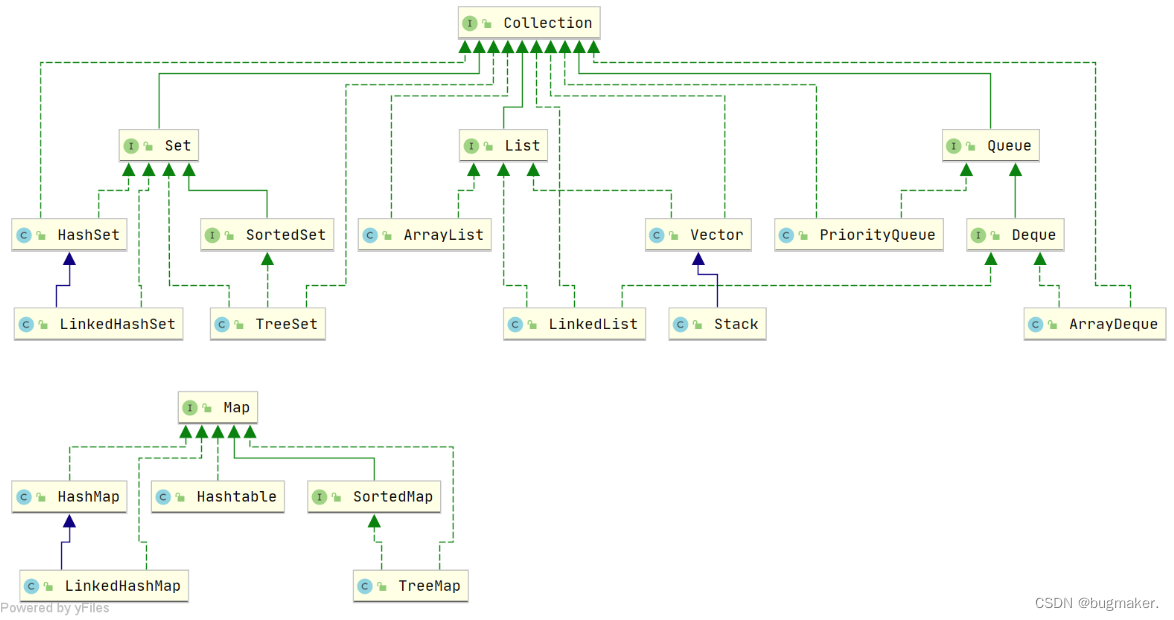
Java 集合概览Java 集合, 也叫作容器,主要是由两大接口派生而来:一个是 Collection接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于Collection 接口,下面又有三个主要的子接口:List、Set 和 Queue。Java 集合框架如下图所示:
说说 List, Set, Queue, Map 四者的区别?
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。Set(注重独一无二的性质): 存储的元素是无序的、不可重复的。Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),“x” 代表 key,“y” 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
先来看一下 Collection 接口下面的集合。# ListArrayList: Object[] 数组Vector:Object[] 数组LinkedList: 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)# SetHashSet(无序,唯一): 基于 HashMap 实现的,底层采用 HashMap 来保存元素LinkedHashSet: LinkedHashSet 是 HashSet 的子类,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的 LinkedHashMap 其内部是基于 HashMap 实现一样,不过还是有一点点区别的TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)# QueuePriorityQueue: Object[] 数组来实现二叉堆ArrayQueue: Object[] 数组 + 双指针再来看看 Map 接口下面的集合。# MapHashMap: JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间LinkedHashMap: LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:《LinkedHashMap 源码详细分析(JDK1.8)》open in new windowHashtable: 数组+链表组成的,数组是 Hashtable 的主体,链表则是主要为了解决哈希冲突而存在的TreeMap: 红黑树(自平衡的排序二叉树)
list
ArrayList 和 Vector 的区别?
ArrayList 是 List 的主要实现类,底层使用 Object[]存储,适用于频繁的查找工作,线程不安全 ;Vector 是 List 的古老实现类,底层使用Object[] 存储,线程安全的。
ArrayList 与 LinkedList 区别?
是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;底层数据结构: ArrayList 底层使用的是 Object 数组;LinkedList 底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)插入和删除是否受元素位置的影响:ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。LinkedList 采用链表存储,所以,如果是在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst() 、 removeLast()),时间复杂度为 O(1),如果是要在指定位置 i 插入和删除元素的话(add(int index, E element),remove(Object o)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入。是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList(实现了RandomAccess接口) 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。内存空间占用: ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。我们在项目中一般是不会使用到 LinkedList 的,需要用到 LinkedList 的场景几乎都可以使用 ArrayList 来代替,并且,性能通常会更好!就连 LinkedList 的作者约书亚 · 布洛克(Josh Bloch)自己都说从来不会使用 LinkedList 。
set
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同HashSet、LinkedHashSet 和 TreeSet 都是 Set 接口的实现类,都能保证元素唯一,并且都不是线程安全的。HashSet、LinkedHashSet 和 TreeSet 的主要区别在于底层数据结构不同。HashSet 的底层数据结构是哈希表(基于 HashMap 实现)。LinkedHashSet 的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet 底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。底层数据结构不同又导致这三者的应用场景不同。HashSet 用于不需要保证元素插入和取出顺序的场景,LinkedHashSet 用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet 用于支持对元素自定义排序规则的场景。
Queue
Queue 是单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 先进先出(FIFO) 规则。Queue 扩展了 Collection 的接口,根据 因为容量问题而导致操作失败后处理方式的不同 可以分为两类方法: 一种在操作失败后会抛出异常,另一种则会返回特殊值。
Deque 是双端队列,在队列的两端均可以插入或删除元素。