一,刷题目情况,已经完成了8道题目,对于其中一些题目做一下题解。

这个题目的意思是找到的两个位置l和r,为了做到这个数组的l到r的子数组经过排序后,会变成输入的另外一个数组,这个题目的思路就是首先找到在两个数组中 第一个不相同的元素和最后一个不相同的元素。然后把这个子数组进行排序,排序完后,向两边扩展如果扩展后还是符合升序,就添加不然就终止。
代码如下
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 判断位置 i 是否在排序后的子数组内
bool inRange(int i, int l, int r) {
return l <= i && i <= r;
}
// 查找可行的 l 值
int findL(const vector<int>& a, const vector<int>& ap, int start, int end) {
int l = start;
for (int i = start; i <= end; i++) {
if (ap[i] < a[i]) {
l = start;
break;
}
}
return l;
}
// 查找可行的 r 值
int findR(const vector<int>& a, const vector<int>& ap, int start, int end) {
int r = end;
for (int i = end; i >= start; i--) {
if (ap[i] < a[i]) {
r = end;
break;
}
}
return r;
}
int main() {
int t;
cin >> t;
while (t--) {
int n;
cin >> n;
vector<int> a(n);
vector<int> ap(n);
// 读取原始数组 a 和排序后的数组 ap
for (int i = 0; i < n; i++) {
cin >> a[i];
}
for (int i = 0; i < n; i++) {
cin >> ap[i];
}
// 找到第一个不同的元素
int start = -1;
for (int i = 0; i < n; i++) {
if (a[i] != ap[i]) {
start = i;
for(int j=i;j>=0;j--){
if(a[j]>a[start]||ap[j]>ap[start]){
break;
}
start =j;
}
break;
}
}
// 找到最后一个不同的元素
int end = -1;
for (int i = n-1; i >= 0; i--) {
if (a[i] != ap[i]) {
end = i;
for(int j=i;j<n;j++){
if(a[j]<a[end]||ap[j]<ap[end]){
break;
}
end =j;
}
break;
}
}
// 如果整个数组都相同,则输出 1 和 n-1
if (start == -1 && end == -1) {
cout << "1 " << n-1 << endl;
} else {
// 找到 l 和 r 的值
int l = findL(a, ap, start, end);
int r = findR(a, ap, start, end);
// 输出 l 和 r 的值
cout << l+1 << " " << r+1 << endl;
}
}
return 0;
}


这个题目的题意是把 每一组数据不断的只与后面做减法,求出绝对值,如果直接使用代码模拟这个过程的话时间复杂度就比较高会有超时的问题,所以思路是对于每一列进行一个排序,然后每一次都是后面减前面的数字,这样就不用考虑绝对值,所以对于每一列的数据来说,他会参与的计算计算在与他前面的数据计算时为正数,与后面的数据计算时为负数,这样使用(j-(n-1-j))*a[i][j]这个方程就可以得到在这一列数据中所有a[i][j]参与的值。每一次进行相加就可以得到结果
代码如下
#include <bits/stdc++.h>
using namespace std;
int n,m;
int main()
{
long long n,m;
long long t=1;
cin>>t;
while(t--)
{
cin >>n>>m ;
vector<vector<int>> a(m,vector<int>(n));
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
cin >> a[j][i];
}
}
long long ans =0;
for(int i=0;i<m;i++){
sort(a[i].begin(),a[i].end());
}
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
ans+=(j-(n-1-j))*a[i][j];
}
}
cout<<ans<<endl;
}
return 0;
}然后就是关于读书的情况,我是看了redis设计与实现两本书和tcp/ip协议socket编程这两本书。
关于redis:
看了客户端和服务器的相关底层实现
客户端
对于redis来说客户端分为伪客户端和客户端两种。
伪客户端是用来载入AOF文件和lua脚本的,普通客户端是连接的服务器进行数据库使用的。
所以伪客户端不需要套接字连接。
服务器clients链表连接起多个客户端状态,新添加的客户端会被放在链表的末尾。
服务器有一个输入缓冲区记录客户端发送的命令请求,这个缓冲区的大小不会超过1G.
客户端有固定大小的缓冲区和可变大小缓冲区两个缓冲区可以用,固定大小为16kb,可变大小缓冲区不能超过服务器的硬性限制。
输出缓冲区大小超过服务器硬性限制,该客户端会立即关闭,如果客户端在一定时间内一直超过服务器设置的软性设置,该客户端也会被关闭。
服务器
主要是有关服务器与客户端的交互过程。
一个命令请求从发送到完成主要包括以下步骤:
1)客户端将命令请求发送给服务器;
2)服务器读取命令请求,并分析出命令参数;
3)命令执行器根据参数查找命令的实现函数,然后执行实现函数并得出命令回复;
4)服务器将命令回复返回给客户端。
然后就是关于服务器的维护函数,serverCron,它的默认执行时间是100毫秒一次,主要处理更新服务器状态信息,处理服务器接收的SIGTERM信号,管理客户端资源和数据库状态,检查并执行持久化操作等等。
服务器从启动到能够处理客户端的命令请求需要执行以下步骤:
1)初始化服务器状态;
2)载人服务器配置;
3)初始化服务器数据结构;
4)还原数据库状态;
5)执行事件循环。
还有就是对于tcp/ip协议的了解
首先是tcp,ip协议的基本概念
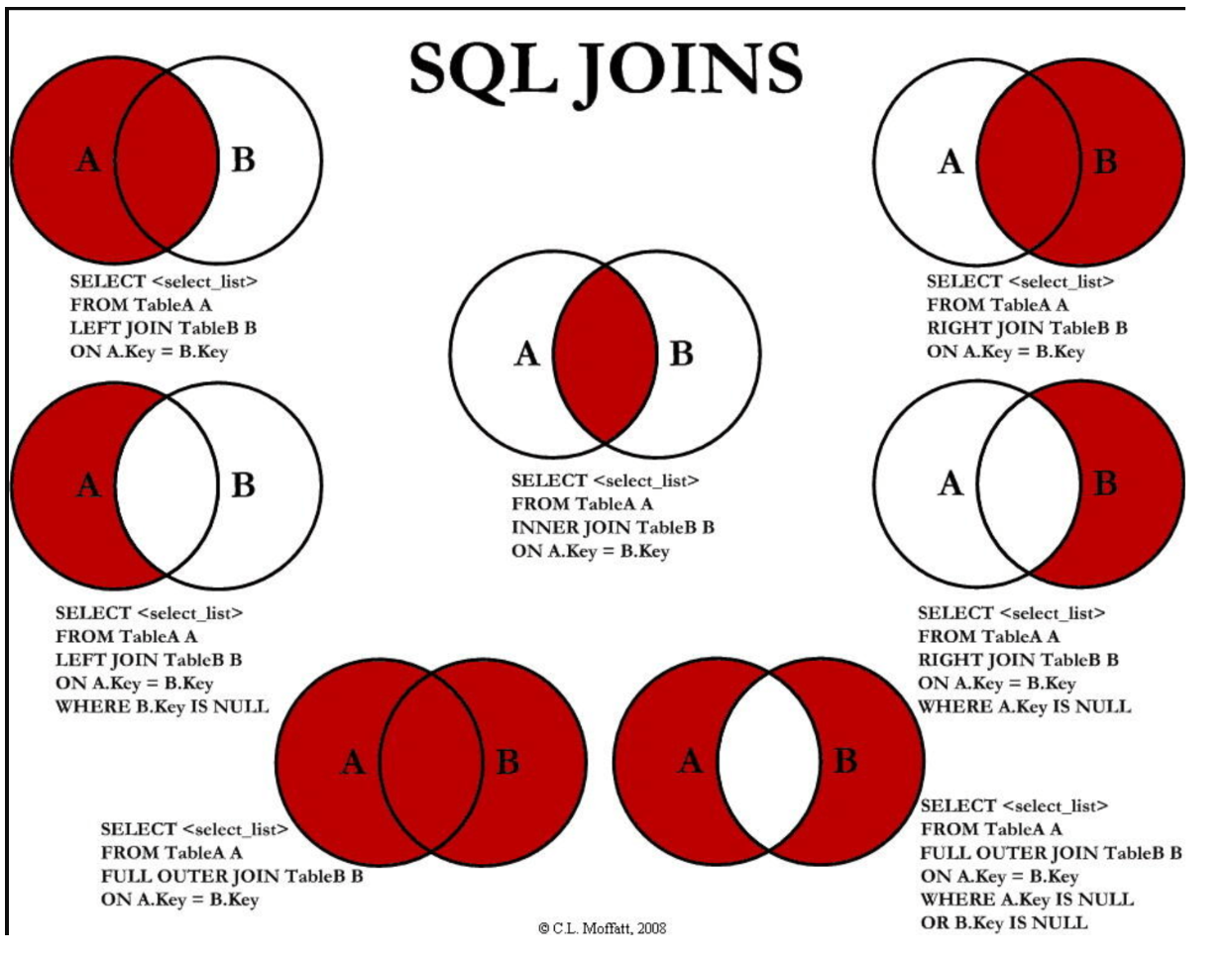
这张图就可以很清楚的看出来了
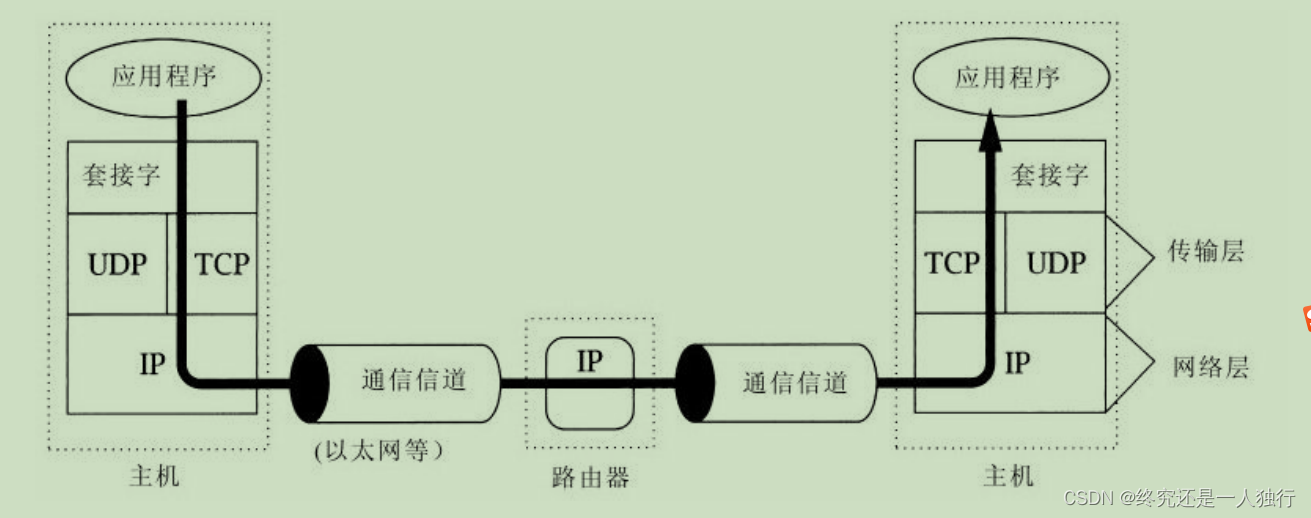
可以看到不管是tcp协议还是UDP协议都是在ip协议的基础上运行的,tcp和UDP协议都是为了区分不同同一主机的不同应用程序,ip协议是用来连接两个主机的。
tcp和UDP的区别在于,
TCP协议提供了一个可信赖的字节流(reliable byte-stream)信道。TCP协议是一种面向连接(connection-oriented)的协议:在使用它进行通信之前,两个应用程序之间首先要建立一个TCP连接,这涉及相互通信的两台电脑的TCP部件间完成的握手消息(handshake message)的交换。这是保证tcp不会产生报文丢失、重复及其他错误的原因。
但是UDP协议就不一样,它只是扩展了ip协议的功能,完成在应用程序工作而不是在主机间工作。
这种区别可以由电话和邮箱形象的表示出来。
tcp相当于两个人在打电话有信息通道,双方都清楚对方现在的情况,而UDP就是派送邮件,邮件什么时候送到你手上,邮件是不是已经损坏了,我们都不清楚。




![C++入门基础知识[博客园长期更新......]](https://img-blog.csdnimg.cn/img_convert/8c0abe7909d6dbf89a64da484f27a450.png)