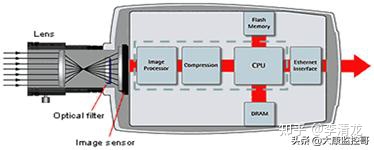
鹏程·盘古模型基于 1.1 TB 高质量中文训练数据,采用全场景人工智能计算框架 MindSpore 自动并行技术实现了五维并行训练策略,从而可将训练任务高效扩展到 4 096 个处理器上。
对比实验表明,在少样本或零样本情况下,鹏程·盘古模型在多个中文自然语言理解或生成任务上都具有较优的性能。
模型架构

目标
假设一 个序列 X = {x1,x2,...,xN}由 N 个 Token 组成,目标如下
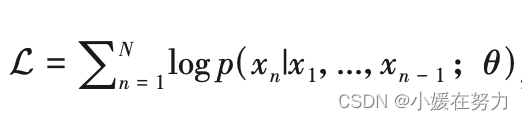
p(xn|x1,...,xn - 1 ; θ) 是指,在知道前 n - 1 个 Token xn-1的情况下,观察到第 n 个 Token xn 的概率;θ 表示模型参数
Transformer 层


Query 层

语料数据生成
最终语料如下

语料库数据处理:

数据处理
1. 原始数据清洗
- 去除中文字符低于 60% 或者字符数小于 150 的数据 (仅有网页名称的数据也会被去除);
- 去除特殊字符,并去除在一个网页中重复出现的 段落;
- 通过广告关键词去除包含大量广告的网页数据;
- 将所有繁体中文转换为简体中文;
- 识别并去除网页导航页。
2. 文本过滤
- 去除包含 3 个以上敏感词的网页数据:通过关键词过滤。构建了一个包含 724 个敏感词的词库,并通过敏感词库去除包含 3 个以上敏感词的网页数据
-
去除垃圾广告和垃圾邮件:基于模型的过滤。通过人工标注数据训练一个 FastText 文本分类模型。负样本为从 Common Crawl 数据中人工挑选的 1 万条垃圾文本数据,正样本为从高质量中文语料数据中抽样得到的数据。基于 FastText 的文本分类模型对语料进行垃圾过滤处理
-
低质量文本过滤:借鉴 GPT-3 的数据处理策略,训练了一个数据质量评分模型。该模型可去除得分较低的文本
3. 文本去重
-
MinHashLSH
- 自己设计的
4. 数据质量评估
-
人工评估数据原则主要从句子通顺性、文本低质量内容占比 (如广告短语、重复短句、敏感词 等) 两个维度进行评估。
-
模型 在高质量数据集中的困惑度 (PPL) 指标来评估数据质量。PPL 越小,数据集清洗和过滤所采用 的清洗规则和过滤模型就越好。
训练数据段落长短与模型生成效果有关。当训练样本平均长度较短时,模型倾向于生成更短的句子,从而有利于模型处理下游任务中需要生成短句的任务;反之,当训练样本平均长度较长时,模型会倾向于生成更长的句子。
训练-并行策略
五维并行和拓扑感知调度

五维并行和拓扑感知调度
- (a) 数据并行,它在设备之间划分训练的批次大小,并在执行迭代优化命令之前与来自不同设备的梯度信息保持同步。
- (b) 算子级并行,它对每个算子所涉及的张量进行切分,通过对参数和显存进行切片来减少显存消耗,同时通过通信优化来使连续算子之间的分布式张量状态保持一致。
- (c) 流水并行,它将总的模型层划分为不同阶段,然后将不同阶段的模型层放置到不同的设备上。每台设备只拥有模型层次的一部分,可大大节省显存占用,并使通信只发生在不同状态的边界上。
- (d) 优化器并行,其作用是减少由数据并行所导致的优化器内存冗余和计算消耗。
- (e) 重计算前向运算结果可以释放部分中间结果,以减少整个训练阶段显存消耗。
- 需要指出的是,每个维度的并行都要通过计算(或通信)开销来换取显存(或吞吐量)收益。因此,为了获得最大的端到端吞吐量,我们需要在多维度并行之间 找到一个最佳组合平衡点。而设备集群中的异构带宽使这变得更具挑战性。
混合并行训练 – 没看懂
图中仅展示2层:
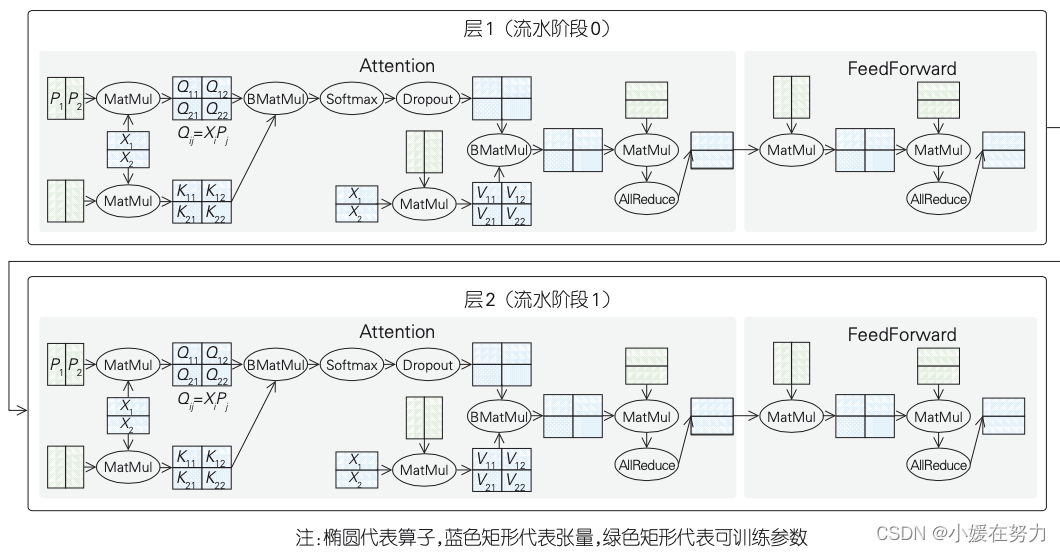
- 首先,将模型总层次(64层)划分成16个状态,每个状态包含 4 层。每一层会为每个算子切分所需要的参数和张量。具体来说,Query(Q)、Key(K) 和 Value(V)算子相关的参数被切分为 8 片。将这 3 个算子的输入张量划分为 16 个切片,并以此确定优化器并行的维度。该层中其他算子的并行策略也以同样的方式进行配置。每层算子都首先被切分,然后再执行下发命令。这有效降低了额外的计算开销。在本方案中,总共使用了 2048 个来自鹏城云脑 II 的 Ascend 910 AI 处理器。
鹏程·盘古 200B 模型具体的混合并行策略为 :数据并行 8 路、算子级并行 8 路、流水并行 16 路,在数据并行的同时叠加优化器并行。
模型会将通信量大的并行方式 (算子级并行)放置在服务器内部的多卡之间,将通信量较小的并行方式 (流水并行) 放置在同一机架内的服务器之间,将部分数据并行 (叠加优化器并行) 放置在不同机架之间。因此,通信可以与计算同时进行,对带宽要求较低。
评测
生成类任务的评测:类似于 GPT-3,小样本学习采用上下文学习的方式,即把 K 个提示相互拼接。其中,前 K−1 个提示均包含答案,最后一个提示的答案则通过模型预测来获得。
分类任务的评测:主要采用基于 PPL(模型 在高质量数据集中的困惑度) 的评测方法,针对每组 <段落,标签> 数据对,根据预设计模板自动生成输入,由模板生成的序列被输入到模型中,同时模型计算出相应的 PPL 值,该段落的预测结果为具有最小 PPL 值的标签。与生成类任务评测类似,分类任务也采用上下文学习策略来完成小样本学习任务。