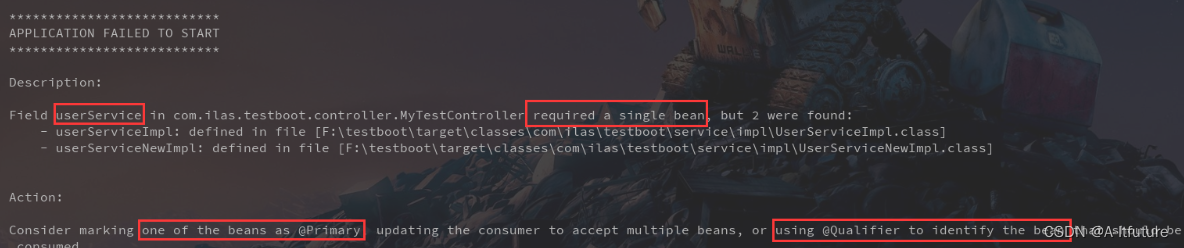
针对提供下游数据报表展示的场景,一般需要走预计算的流程将结果持久化下来,对数据就绪和计算耗时的敏感度都较高,而且查询逻辑相对复杂,Trino/Impala 集群规模相对较小,执行容易失败,导致稳定性欠佳。这个场景下我们使用了集群部署规模最大的 Spark 引擎来处理,在不引入新的资源成本的情况下,做到了离线计算资源的复用。
数据就绪方面,通过 Arctic 表水位感知方案,可以做到较低的分钟级就绪延迟。
计算方面,Arctic 对 Spark Connector 提供了一些读取优化,用户可以通过配置 Arctic 表的 read.split.planning-parallelism 和 read.split.planning-parallelism-factor 这两个参数值,来调整 Arctic Combine Task 的数量,进而控制计算任务的并发度。由于 Spark 离线计算的资源相对灵活和充足,我们可以通过上述调整并发度的方式来保证在 2~3 分钟内完成业务的计算需求。

(3)Hive + Spark 满足传统离线数仓生产链路的调度
Arctic 支持将 Hive 表作为 Basestore,Full Optimize 时会将文件写入到 Hive 数据目录下,以达到更新 Hive 原生读取内容的目的,通过存储架构上的流批一体来降低成本。因此传统的离线数仓生产链路,可以直接使用对应的 Hive 表来作为离线数仓链路的一部分,时效性上相较于 Arctic 表虽缺少了 MOR,但通过 Hive 表水位感知方案,可以做到业务能接受的就绪延迟,从而满足传统离线数仓生产链路的调度。

3 项目影响力与产出价值
3.1 项目影响力
通过 Arctic + X 方案在传媒的探索和落地,为传媒准实时计算场景提供了一个新的解决思路。该思路不但减轻了全链路 Flink 实时计算方案所带来的实时资源压力和开发运维负担,而且还能较好地复用现有的 HDFS 和 Spark 等存储计算资源,做到了降本增效。
此外 Arctic 在音乐、有道等多个 BU 也有落地,比如在音乐公技,用于 ES 冷数据的存储,降低了用户 ES 的存储成本;而有道精品课研发团队也在积极探索和使用 Arctic 作为其部分业务场景下的解决方案。
目前 Arctic 已经在 github 上开源,受到了开源社区与外部用户的持续关注,在 Arctic 的建设与发展中,也收到了不少外部用户提交的高质量 PR 。
3.2 项目产出价值
通过上述方案我们将 push ETL 明细数据通过 Flink 实时入湖到 Arctic,然后在调度平台上配置分钟级的调度任务,按照不同交叉维度进行计算后将累计型指标后写入关系数据库,最后通过有数直连进行数据展示,做到了业务方要求的分钟级时效数据产出。改造后的方案,同原来的全链路 Flink 实时计算方案相比:
(1)充分复用离线空闲算力,降低了实时计算资源开支
方案利用了空闲状态下的离线计算资源,且基本不会带来新的资源开支。离线计算业务场景注定了资源使用的高峰在凌晨,而新闻 push 推送及热点新闻产生的场景大多为非凌晨时段,在满足准实时计算时效的前提下,通过复用提升了离线计算集群的综合利用率。另外,该方案能帮我们释放大约 2.4T 左右的实时计算内存资源。
(2)降低任务维护成本,提升任务稳定性
Arctic + Spark 水位感知触发调度的方案可减少 17+ 实时任务的维护成本,减少了 Flink 实时计算任务大状态所带来的稳定性问题。通过 Spark 离线调度任务可充分利用离线资源池调整计算并行度,有效提升了应对突发热点新闻流量洪峰时的健壮性。
(3)提升数据异常时的修复能力,降低数据修复时间开支
通过流批一体的 Arctic 数据湖存储架构,当数据出现异常需要修正时,可灵活地对异常数据进行修复,降低修正成本;而如果通过实时计算链路回溯数据或通过额外的离线流程来修正,则需要重新进行状态累计或复杂的 ETL 流程。



![[附源码]java毕业设计8号体育用品销售及转卖系统](https://img-blog.csdnimg.cn/608c90f6573a434faed416e9108f1ddc.png)