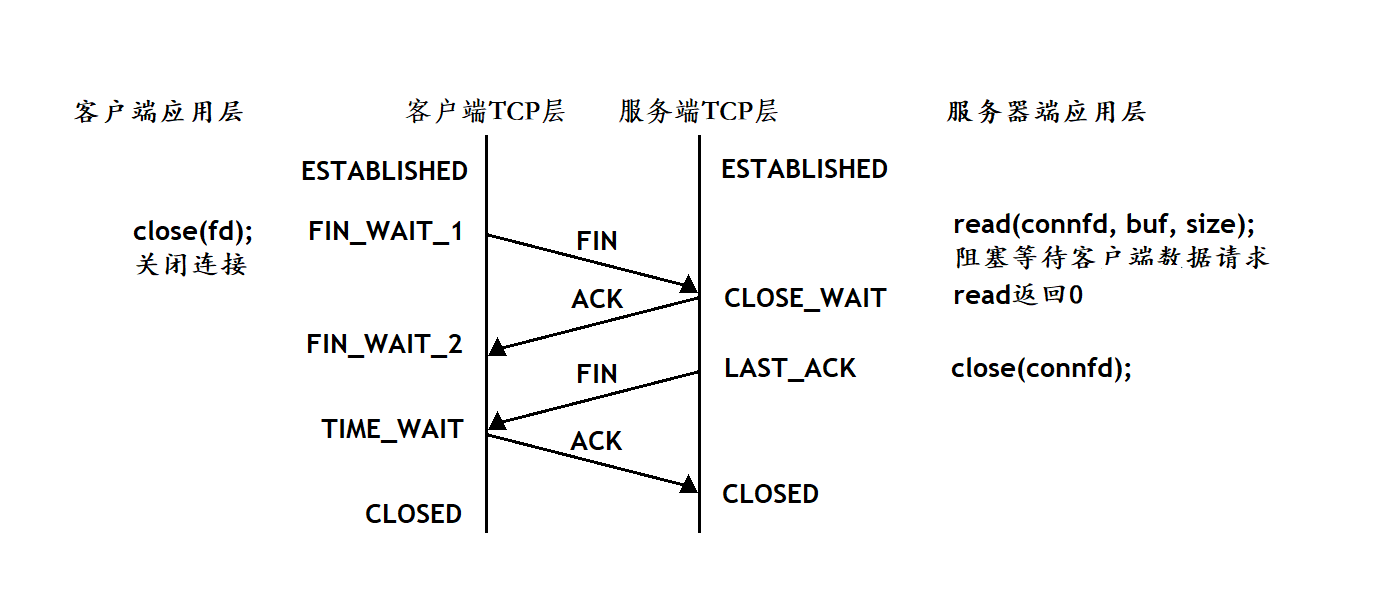
目录
- 3.1 改变色彩空间
- 目标
- 改变色彩空间
- 对象跟踪
- 如何找到HSV值来追踪?
- 练习
- 3.2 图像的几何变换
- 目标
- 变换
- 缩放
- 平移
- 旋转
- 仿射变换
- 透视变换
- 其他资源
- 3.3 图像阈值处理
- 目标
- 简单的阈值处理
- 自适应阈值处理
- Otsu的二值化
- Otsu的二值化是如何工作的?
- 其他资源
- 练习
翻译及二次校对:cvtutorials.com
编辑者:廿瓶鲸(和鲸社区Siby团队成员)
3.1 改变色彩空间
目标
- 在本教程中,你将学习如何将图像从一个色彩空间转换为另一个色彩空间,如BGR ↔ 灰色,BGR ↔ HSV,等等。
- 此外,我们将创建一个应用程序,提取视频中的彩色物体。
- 你将学习以下函数:cv.cvtColor(),cv.inRange(),等等。
改变色彩空间
在OpenCV中,有超过150种色彩空间转换方法。但我们只研究两种最广泛使用的方法:BGR ↔ Gray和BGR ↔ HSV。
对于颜色转换,我们使用函数cv.cvtColor(input_image, flag),其中flag决定了转换的类型。
对于BGR → GRAY的转换,我们使用标志cv.COLOR_BGR2GRAY。类似地,对于BGR→HSV的转换,我们使用标志cv.COLOR_BGR2HSV。要获得其他标志,只需在你的Python终端运行以下命令。
>>> import cv2 as cv
>>> flags = [i for i in dir(cv) if i.startswith('COLOR_')]
>>> print(flags )
备注:对于HSV,色调范围是[0,179],饱和度范围是[0,255],值范围是[0,255]。不同的软件使用不同的范围。因此,如果你将OpenCV的值与它们进行比较,你需要将这些范围归一化。
对象跟踪
现在我们知道了如何将BGR图像转换为HSV,我们可以用它来提取一个彩色物体。在HSV中,要比在BGR色彩空间中更容易表示一种颜色。在我们的应用中,我们将尝试提取一个蓝色的物体。因此,方法是这样的:
1.取出视频的每一帧
2.从BGR色彩空间转换为HSV色彩空间
3.对HSV图像中的蓝色范围进行阈值处理
4.现在单独提取蓝色物体,我们可以在该图像上做任何我们想做的事情
下面是代码,其中有详细的注释:
import cv2 as cv
import numpy as np
cap = cv.VideoCapture(0)
while(1):
# Take each frame
_, frame = cap.read()
# Convert BGR to HSV
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
# define range of blue color in HSV
lower_blue = np.array([110,50,50])
… break
cv.destroyAllWindows()
下面的图片显示了对蓝色物体的追踪:

注意事项:图像中存在一些噪音。我们将在后面的章节中看到如何消除它。这是物体追踪中最简单的方法。一旦你学会了轮廓线的功能,你就可以做很多事情,比如找到物体的中心点,用它来追踪物体,只需在相机前移动手就可以画图,以及其他有趣的事情。
如何找到HSV值来追踪?
这是在stackoverflow.com上发现的一个常见的问题。它非常简单,你可以使用同一个函数,cv.cvtColor()。你不需要传递图像,而只需要传递你想要的BGR值。例如,要找到绿色的HSV值,在Python终端尝试以下命令。
>>> green = np.uint8([[[0,255,0 ]]])
>>> hsv_green = cv.cvtColor(green,cv.COLOR_BGR2HSV)
>>> print( hsv_green )
[[[ 60 255 255]]]
现在你把[H-10,100,100]和[H+10,255,255]分别作为下限和上限。除了这种方法,你可以使用任何图像编辑工具,如GIMP或任何在线转换器来找到这些值,但不要忘记调整HSV范围。
练习
- 尝试找到一种方法来提取一个以上的彩色物体,例如,同时提取红色、蓝色和绿色物体。
3.2 图像的几何变换
目标
- 学习对图像应用不同的几何变换,如平移、旋转、仿射变换等。
- 你将看到这些函数:cv.getPerspectiveTransform
变换
OpenCV提供了两个变换函数,cv.warpAffine和cv.warpPerspective,用它们可以进行各种变换。cv.warpAffine需要一个2x3变换矩阵,而cv.warpPerspective需要一个3x3变换矩阵作为输入。
缩放
缩放就是调整图像的大小。OpenCV有一个函数cv.resize()用于这个目的。图像的大小可以手动指定,或者你可以指定缩放系数。使用不同的插值方法。最好的插值方法是用于缩小的cv.INTER_AREA和用于缩放的cv.INTER_CUBIC(慢速)和cv.INTER_LINEAR。默认情况下,插值方法cv.INTER_LINEAR被用于所有调整图像大小。你可以用以下任何一种方法来调整一个输入图像的大小。
import numpy as np
import cv2 as cv
img = cv.imread('messi5.jpg')
res = cv.resize(img,None,fx=2, fy=2, interpolation = cv.INTER_CUBIC)
#OR
height, width = img.shape[:2]
res = cv.resize(img,(2*width, 2*height), interpolation = cv.INTER_CUBIC)
平移
平移是物体位置的移动。如果你知道沿着(x,y)方向的移动,移动的量用(
t
x
t_x
tx,
t
y
t_y
ty)表示,你可以创建变换矩阵M如下:
M
=
[
1
0
t
x
0
1
t
y
]
M = \begin{bmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \end{bmatrix}
M=[1001txty]
你可以把它变成一个np.float32类型的Numpy数组,然后把它传给cv.warpAffine()函数。请看下面的例子,位移为(100,50)。
import numpy as np
import cv2 as cv
img = cv.imread('messi5.jpg',0)
rows,cols = img.shape
M = np.float32([[1,0,100],[0,1,50]])
dst = cv.warpAffine(img,M,(cols,rows))
cv.imshow('img',dst)
cv.waitKey(0)
cv.destroyAllWindows()
警告:cv.warpAffine()函数的第三个参数是输出图像的大小,它应该是(宽度,高度)的形式。记住宽度=列数,高度=行数。
请看下面的结果。

旋转
图像旋转一个角度θ是通过以下形式的变换矩阵实现的
M
=
[
c
o
s
θ
−
s
i
n
θ
s
i
n
θ
c
o
s
θ
]
M = \begin{bmatrix} cos\theta & -sin\theta \\ sin\theta & cos\theta \end{bmatrix}
M=[cosθsinθ−sinθcosθ]
但是OpenCV提供了可调节旋转中心的缩放旋转,因此你可以在你喜欢的任何位置进行旋转。修改后的变换矩阵是这样的
[
α
β
(
1
−
α
)
⋅
c
e
n
t
e
r
.
x
−
β
⋅
c
e
n
t
e
r
.
y
−
β
α
β
⋅
c
e
n
t
e
r
.
x
+
(
1
−
α
)
⋅
c
e
n
t
e
r
.
y
]
\begin{bmatrix} \alpha & \beta & (1- \alpha ) \cdot center.x - \beta \cdot center.y \\ - \beta & \alpha & \beta \cdot center.x + (1- \alpha ) \cdot center.y \end{bmatrix}
[α−ββα(1−α)⋅center.x−β⋅center.yβ⋅center.x+(1−α)⋅center.y]
这里,
α
=
s
c
a
l
e
⋅
cos
θ
,
β
=
s
c
a
l
e
⋅
sin
θ
\begin{array}{l} \alpha = scale \cdot \cos \theta , \\ \beta = scale \cdot \sin \theta \end{array}
α=scale⋅cosθ,β=scale⋅sinθ
为了找到这个变换矩阵,OpenCV提供了一个函数,cv.getRotationMatrix2D。请看下面的例子,它将图像相对于中心旋转了90度而没有任何缩放。
img = cv.imread('messi5.jpg',0)
rows,cols = img.shape
# cols-1 and rows-1 are the coordinate limits.
M = cv.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),90,1)
dst = cv.warpAffine(img,M,(cols,rows))
结果如下:

仿射变换
在仿射变换中,原始图像中的所有平行线在输出图像中仍然是平行的。为了找到变换矩阵,我们需要输入图像中的三个点和它们在输出图像中的对应位置。然后cv.getAffineTransform将创建一个2x3的矩阵,并传递给cv.warpAffine。
看看下面的例子,也看看我选择的点(用绿色标记)。
img = cv.imread('drawing.png')
rows,cols,ch = img.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv.getAffineTransform(pts1,pts2)
dst = cv.warpAffine(img,M,(cols,rows))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
结果如下:

透视变换
对于透视变换,你需要一个3x3的变换矩阵。直线在变换后仍会保持直线。要找到这个变换矩阵,你需要输入图像上的4个点和输出图像上的对应点。在这4个点中,有3个不应该是相邻的。然后可以通过函数cv.getPerspectiveTransform找到变换矩阵。然后用这个3x3的变换矩阵应用cv.warpPerspective。
请看下面的代码:
img = cv.imread('sudoku.png')
rows,cols,ch = img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv.getPerspectiveTransform(pts1,pts2)
dst = cv.warpPerspective(img,M,(300,300))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()
结果如下:

其他资源
- “Computer Vision: Algorithms and Applications”, Richard Szeliski
3.3 图像阈值处理
目标
- 在本教程中,你将学习简单的阈值处理、自适应阈值处理和Otsu阈值处理。
- 你将学习函数cv.threshold和cv.adaptiveThreshold。
简单的阈值处理
对于每个像素,应用相同的阈值。如果像素的值小于阈值,它就被设置为0,否则就被设置为一个最大值。函数cv.threshold被用来应用阈值化。第一个参数是源图像,它应该是一个灰度图像。第二个参数是阈值,用于对像素值进行分类。第三个参数是最大值,它被分配给超过阈值的像素值。OpenCV提供了不同类型的阈值处理,由该函数的第四个参数给出。上述的基本阈值处理是通过使用cv.THRESH_BINARY类型完成的。所有简单的阈值处理类型是:
- cv.THRESH_BINARY
- cv.THRESH_BINARY_INV
- cv.THRESH_TRUNC
- cv.THRESH_TOZERO
- cv.THRESH_TOZERO_INV
该方法返回两个输出。第一个是使用的阈值,第二个是阈值化的图像。
这段代码比较了不同的简单阈值处理类型。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('gradient.png',0)
ret,thresh1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
ret,thresh2 = cv.threshold(img,127,255,cv.THRESH_BINARY_INV)
ret,thresh3 = cv.threshold(img,127,255,cv.THRESH_TRUNC)
ret,thresh4 = cv.threshold(img,127,255,cv.THRESH_TOZERO)
ret,thresh5 = cv.threshold(img,127,255,cv.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray',vmin=0,vmax=255)
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
注:为了绘制多个图像,我们使用了plt.subplot()函数。请查阅matplotlib文档以了解更多细节。
该代码产生了这样的结果。

自适应阈值处理
在上一节中,我们使用一个全局值作为阈值。但这可能不是在所有情况下都好,例如,如果一幅图像在不同区域有不同的光照条件。在这种情况下,自适应阈值处理可以提供帮助。在这里,算法根据一个像素周围的小区域来确定该像素的阈值。因此,我们对同一图像的不同区域得到不同的阈值,这对具有不同光照度的图像有更好的效果。
除了上述参数外,cv.adaptiveThreshold方法还需要三个输入参数:
参数adaptiveMethod决定如何计算阈值:
- cv.ADAPTIVE_THRESH_MEAN_C:阈值是邻近区域的平均值减去常数C。
- cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值的高斯加权和减去常数C。
参数blockSize决定了邻域的大小,参数C是一个常数,从邻域像素的平均值或加权和中减去。
下面的代码比较了全局阈值处理和自适应阈值处理对不同照度的图像的影响。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('sudoku.png',0)
img = cv.medianBlur(img,5)
ret,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
th2 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_MEAN_C,\
cv.THRESH_BINARY,11,2)
th3 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,\
cv.THRESH_BINARY,11,2)
titles = ['Original Image', 'Global Thresholding (v = 127)',
'Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img, th1, th2, th3]
for i in range(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
结果如下:

Otsu的二值化
在全局阈值化中,我们使用一个任意选择的值作为阈值。相比之下,Otsu的方法避免了选择一个值,而是自动确定它。
考虑一个只有两个不同图像值的图像(双峰图像),其中直方图只由两个峰值组成。一个好的阈值会在这两个值的中间。同样地,Otsu的方法从图像直方图中确定一个最佳的全局阈值。
为了做到这一点,使用了cv.threshold()函数,其中cv.THRESH_OTSU被作为一个额外的标志传递。阈值可以任意选择。然后,该算法找到最佳的阈值,并作为第一个输出返回。
请看下面的例子。输入的图像是一个有噪声的图像。在第一种情况下,全局阈值为127的阈值被应用。在第二种情况下,直接应用Otsu的阈值处理。在第三种情况下,首先用5x5高斯核过滤图像以去除噪声,然后应用Otsu的阈值。看看噪声过滤是如何改善结果的。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('noisy2.png',0)
# global thresholding
ret1,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
# Otsu's thresholding
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# Otsu's thresholding after Gaussian filtering
blur = cv.GaussianBlur(img,(5,5),0)
… plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)
plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')
plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])
plt.show()
结果如下:

Otsu的二值化是如何工作的?
本节演示了Otsu二值化的Python实现,以显示它是如何实际工作的。如果你不感兴趣,你可以跳过这部分。
由于我们处理的是双模态图像,Otsu的算法试图找到一个阈值(t),使加权的类内方差最小,该阈值由以下公式给出:
σ
w
2
(
t
)
=
q
1
(
t
)
σ
1
2
(
t
)
+
q
2
(
t
)
σ
2
2
(
t
)
\sigma_w^2(t) = q_1(t)\sigma_1^2(t)+q_2(t)\sigma_2^2(t)
σw2(t)=q1(t)σ12(t)+q2(t)σ22(t)
这里,
q
1
(
t
)
=
∑
i
=
1
t
P
(
i
)
&
q
2
(
t
)
=
∑
i
=
t
+
1
I
P
(
i
)
q_1(t) = \sum_{i=1}^{t} P(i) \quad \& \quad q_2(t) = \sum_{i=t+1}^{I} P(i)
q1(t)=i=1∑tP(i)&q2(t)=i=t+1∑IP(i)
μ 1 ( t ) = ∑ i = 1 t i P ( i ) q 1 ( t ) & μ 2 ( t ) = ∑ i = t + 1 I i P ( i ) q 2 ( t ) \mu_1(t) = \sum_{i=1}^{t} \frac{iP(i)}{q_1(t)} \quad \& \quad \mu_2(t) = \sum_{i=t+1}^{I} \frac{iP(i)}{q_2(t)} μ1(t)=i=1∑tq1(t)iP(i)&μ2(t)=i=t+1∑Iq2(t)iP(i)
σ 1 2 ( t ) = ∑ i = 1 t [ i − μ 1 ( t ) ] 2 P ( i ) q 1 ( t ) & σ 2 2 ( t ) = ∑ i = t + 1 I [ i − μ 2 ( t ) ] 2 P ( i ) q 2 ( t ) \sigma_1^2(t) = \sum_{i=1}^{t} [i-\mu_1(t)]^2 \frac{P(i)}{q_1(t)} \quad \& \quad \sigma_2^2(t) = \sum_{i=t+1}^{I} [i-\mu_2(t)]^2 \frac{P(i)}{q_2(t)} σ12(t)=i=1∑t[i−μ1(t)]2q1(t)P(i)&σ22(t)=i=t+1∑I[i−μ2(t)]2q2(t)P(i)
它实际上是找到一个位于两个峰值之间的t值,使两个类的方差最小。它可以在Python中简单地实现,如下:
img = cv.imread('noisy2.png',0)
blur = cv.GaussianBlur(img,(5,5),0)
# find normalized_histogram, and its cumulative distribution function
hist = cv.calcHist([blur],[0],None,[256],[0,256])
hist_norm = hist.ravel()/hist.sum()
Q = hist_norm.cumsum()
bins = np.arange(256)
fn_min = np.inf
thresh = -1
for i in range(1,256):
… if fn < fn_min:
fn_min = fn
thresh = i
# find otsu's threshold value with OpenCV function
ret, otsu = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
print( "{} {}".format(thresh,ret) )
其他资源
- 《数字图像处理》,Rafael C. Gonzalez
练习
- 对Otsu的二进制化有一些优化。你可以搜索并实现它。