目录
一、索引
1.1 索引的概念
1.2 索引的运用
1.2.1 索引的创建
1.2.2 查看表的索引
1.2.3 创建索引
1.2.4 删除索引
1.2.5 总结
二、索引底层的数据结构
B+ 树的特点
一、索引
1.1 索引的概念
当我们是使用查询语句对表中的数据进行条件查询的时候,MySql 服务器会对该表中的数据进行条件遍历,即每一条记录都会判断,时间复杂度是 O(N)。
当我们涉及到多表联合查询时,多表数据就会形成一个笛卡尔积——数据库中的数据都是以二维表的形式存放的,记录就是表格的行,字段就是其中的每个列, 笛卡尔积就是把多个表中的所有数据进行(全部预设的组合),举个例子:
学生表 stu:
 成绩表:grade
成绩表:grade
 我们对这两张表进行联合查询。
我们对这两张表进行联合查询。
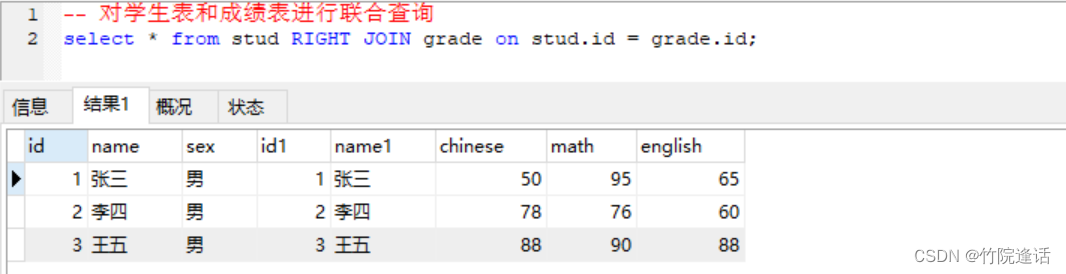 这里博主展示了全部字段,所以两个表中的数据有所重复,这里使用 Right Join 进行右连接,on 后面是连接匹配的条件,right join 以左表(学生表)为主,在右表(成绩表)中根据匹配条件查找,例如:成绩表中的 id 字段需要和学生表中的 id 字段有所匹配,左表中有符合条件的数据就返回数据与右表进行组合。
这里博主展示了全部字段,所以两个表中的数据有所重复,这里使用 Right Join 进行右连接,on 后面是连接匹配的条件,right join 以左表(学生表)为主,在右表(成绩表)中根据匹配条件查找,例如:成绩表中的 id 字段需要和学生表中的 id 字段有所匹配,左表中有符合条件的数据就返回数据与右表进行组合。
这是建立在我们设置了连接条件的基础上,如果我们没有设置条件,两张表就会生成笛卡尔积。
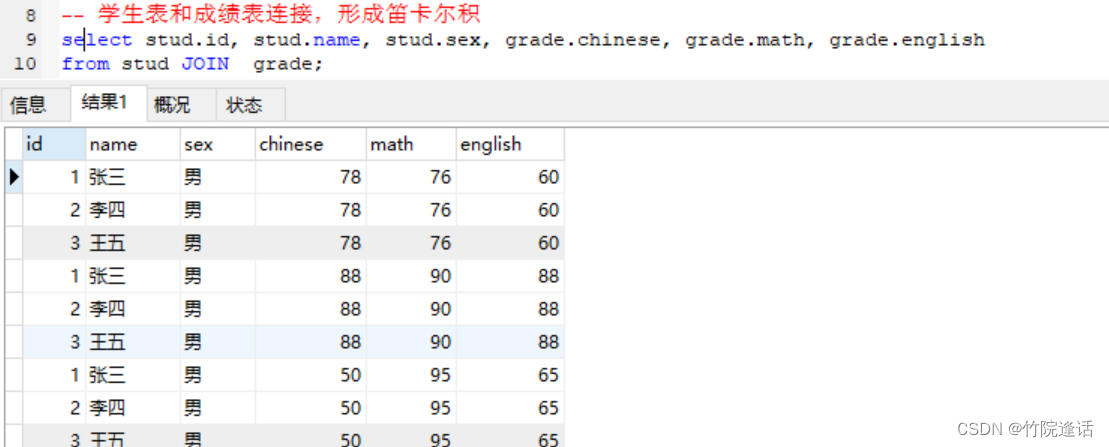 由上图可见,笛卡尔积就是将两张表的数据进行无规则的排列组合,即使数据是错误的,也会排列出来,当我们设置了条件进行条件查询,就会在笛卡尔积中遍历寻找符合条件的数据,形成一张新的数据集合返回客户端,展示给用户,笛卡尔积有多少行记录,取决于,多表中有多少条记录,即: stud 表中记录数 和 grade 表中记录数的乘积,这两张表才只插入了3行记录,笛卡尔积就有9 行, 如果两表中各有 100条记录, 笛卡尔积就有 100 * 100 (10000)行记录,在这种情况下,遍历查询的效率就非常低了。
由上图可见,笛卡尔积就是将两张表的数据进行无规则的排列组合,即使数据是错误的,也会排列出来,当我们设置了条件进行条件查询,就会在笛卡尔积中遍历寻找符合条件的数据,形成一张新的数据集合返回客户端,展示给用户,笛卡尔积有多少行记录,取决于,多表中有多少条记录,即: stud 表中记录数 和 grade 表中记录数的乘积,这两张表才只插入了3行记录,笛卡尔积就有9 行, 如果两表中各有 100条记录, 笛卡尔积就有 100 * 100 (10000)行记录,在这种情况下,遍历查询的效率就非常低了。
创建索引的目的就是为了能够快速的定位、检索数据,索引我们可以先理解为是根据字段创建的指向对应记录的指针。
 如果搜索条件的列上已经创建了索引,MySQL服务器无需扫描任何记录即可迅速得到目标记录所在的位置。
如果搜索条件的列上已经创建了索引,MySQL服务器无需扫描任何记录即可迅速得到目标记录所在的位置。
1.2 索引的运用
索引的创建使用需要考虑一些情况:
索引一般创建于数据量特别大的情况下
索引可以针对一列或者是多列创建,创建于需要经常对这些列进行条件查询的字段,例如 :学号 id
创建索引会占用额外的存储空间,服务器需要组织管理索引
创建索引的列必须能够进行比较,幸运的是 Mysql 提供的数据结构都能够比较。
1.2.1 索引的创建
当我们对数据表的字段创建主键约束 (PRIMARY KEY),唯一约束 (UNIQUE), 外键约束(FOREIGN)的时候,会自动的为这些字段创建索引, 这些字段也是常常被我们用来作为查询条件。
以下是在创建 (create)数据表时建立约束,当数据表创建完毕后,可以使用 ALTER 语句修改(不建议使用 ALTER 语句)。
对字段建立主键约束:
【字段名】 数据类型 primary key
对字段建立外键约束:
foreign key 【字段名】references 【主表】(主键字段或者唯一字段)
对字段建立唯一约束:
【字段名】 数据类型 unique
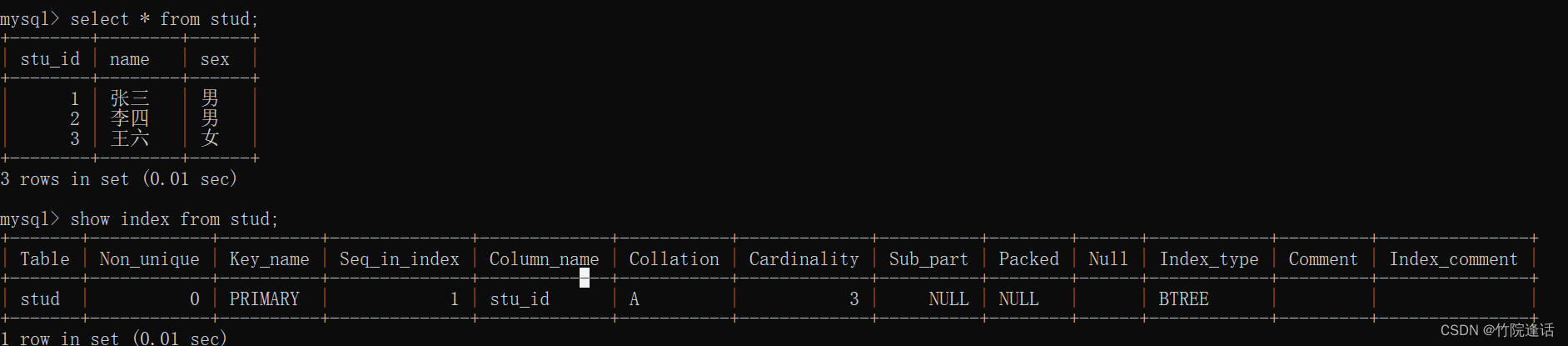
1.2.2 查看表的索引
show index from 【表名】
 1.2.3 创建索引
1.2.3 创建索引
针对并非 主键、外键、唯一约束的字段,创建索引
create index 索引名 on 【表名】(字段名)
举个例子: 为学生表的 sex 字段设置 引索
mysql> select * from stud;
+--------+--------+------+
| stu_id | name | sex |
+--------+--------+------+
| 1 | 张三 | 男 |
| 2 | 李四 | 男 |
| 3 | 王六 | 女 |
+--------+--------+------+
3 rows in set (0.00 sec)
mysql> create index gender on stud(sex);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from stud;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| stud | 0 | PRIMARY | 1 | stu_id | A | 3 | NULL | NULL | | BTREE | | |
| stud | 1 | gender | 1 | sex | A | 2 | NULL | NULL | YES | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
以上是建立在数据表已经创建好的情况下,在创建数据表的时候可以直接为字段创建约束。
创建一个学生表 stu2 ,有 id ,name, sex 字段,并为 id 字段创建 索引。
mysql> create table if not exists ();
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '()' at line 1
mysql> create table if not exists stud2 (
-> id int,
-> name varchar(20),
-> sex varchar(3),
-> index(id) );
Query OK, 0 rows affected (0.02 sec)
mysql> show index from stud2;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| stud2 | 1 | id | 1 | id | A | 0 | NULL | NULL | YES | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
1.2.4 删除索引
drop index 【索引名】 on 【表名】
删除刚刚 为 stud 学生表 sex 字段创建的名为 gender 的索引
mysql> drop index gender on stud;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from stud;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| stud | 0 | PRIMARY | 1 | stu_id | A | 3 | NULL | NULL | | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
1.2.5 总结
我们创建索引有4种方式:
- 为表中的某些字段设置 主键,外键,唯一约束
- 使用 create index 索引名 on 【表名】(字段名) 语句
- 可以在创建数据表的时候 使用index(字段)创建索引
- 可以使用 ALTER 语句创建索引,也可以给字段添加主键,外键等。
ALTER TABLE table_name ADD INDEX index_name (column_list);
注意:我们创建索引的时候,或者是主键,尽量提前设计好表的结构,在创建表的时候就把这些约束啥的弄好,或者是在表刚刚创建完毕,还没有插入数据的时候 使用 ALTER 语句对表的结构进行修改,不建议在有很多数据的时候给字段添加索引,因为当数据量过多的时候创建索引对空间和时间开销很大,比如说几百万数据建立索引,系统需要分配大量的资源来存储和管理索引,就会引起数据库的卡顿或者是崩溃。
创建索引的目的就是为了加快MySql 服务端对数据检索的效率,当然这是建立在条件查询的基础之上,主要就是对我们经常作为查询条件的字段创建索引是比较好的选择,索引虽好,需要我们能够把握好他的使用场景,从某种意义上来说创建索引的开销也是很大的。
二、索引底层的数据结构
管理索引底层的数据结构是 B+ 树,说起 B+树,不知道有没有朋友了解过 二叉搜索树呢, B + 树是 B树的基础上做的优化改进, 可以理解为他们是 N 叉搜索树,
B+ 树的特点
key 值——创建索引得字段值
- 一个节点可以存储 N个 key值, N 个key 值划分出 N 个区间 (一个key 值划分一个区间)
- 每个节点中key 的值(父),会作为子节点的最大值出现在子节点中
- B + 树的叶子节点依次链接,类似于一个链表的结构
- 因为每个key 值都会划分出 N 个区间,每个key 值都会以最大值的形式在子节点中出现,所以
B+ 树的叶子节点就包含了所有的 key 值,我们也只需要在叶子节点中存储数据表中每一行的数据。
 为什么会使用B+ 树作为索引的底层结构呢
为什么会使用B+ 树作为索引的底层结构呢
B+ 树的实质是 N叉搜索树,相对于二叉搜索树来说,一个节点可以保存更多的 Key ,树的高度会相对来说低,所以查询的效率更高,这就意味着降低了对硬盘的访问次数,MySql 本身就是依托于硬盘存储,数据总归是会被读取到内存中处理的。
B+ 树的叶子节点相互构成链表,适合进行范围查询,找到了指定的 Key 值,Key 值得前后就是范围,顺着指针遍历。
B+ 树叶子节点存储了每一条记录,非叶子节点只需要存储 key 值(创建索引得字段值),所以非叶子节点所占得存储空间比较少,也可以降低硬盘访问数据量。
月亮很亮,亮也没用,没用也亮。








![[江西专升本/信息技术]计算机网络基础](https://img-blog.csdnimg.cn/cd2297dde4804931b2d54cd7d243cefe.png)