为什么学?因为它查询速度很快,而且是非关系型数据库 (NoSql)
一些增删改查已经配置好了,无需重复敲码
ElasticSearch 更新快,本篇文章将主要介绍一些常用方法。
对于 spirngboot 整合 Es 的文章很少,有些已经过时【更新太快了】
依赖:Maven
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>配置类:EsConfig
@Configuration
public class EsConfig {
// 创建低级客户端
public RestClient restClient() {
return RestClient.builder(
// 创建一个客户端 地址本机 9200 端口
new HttpHost("localhost",9200)
).build();
}
// 使用Jackson映射器创建传输层
public ElasticsearchTransport elasticsearchTransport() {
return new RestClientTransport(
// 将客户端放在这里
restClient(),
// json 解析器 【spring boot提供】
new JacksonJsonpMapper());
}
// 创建API客户端
@Bean
public ElasticsearchClient elasticsearchClient() {
return new ElasticsearchClient(elasticsearchTransport());
}
}水果信息
@Document(indexName = "fruit")
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Fruit implements Serializable {
private Long id;
@Field(type = FieldType.Text)
private String name;
@Field(type = FieldType.Keyword)
private String category;
@Field(type = FieldType.Double)
private Double price;
@Field(index = false, type = FieldType.Keyword)
private String images;
private String body;
}操作数据库:继承类
// 继承 Ela... 可以简单实现增删改查
// 存储位置: Elasticsearch 安装目录下有个data 文件夹
// 集群操作: 可以多复制几个 ES 服务器【集群名字不能相同,端口不能相同】
@Repository
public interface FruitRepository extends ElasticsearchRepository<Fruit,Long>{
Fruit findById(long id);
Fruit findByName(String name);
// 通过分类查询所有水果
// category 水果分类
List<Fruit> findAllByCategory(String category);
}配置已完成!
1. 增删改查
调用 save 方法,该方法已经在 CrudRepository 实现
long id = System.currentTimeMillis();
Fruit fruit = new Fruit(id,"红蛇果","苹果",7.29,"https://s1.ax1x.com/2023/02/13/pSIqh2q.png","蛇果");
fruitMapper.save(fruit);
System.out.println(fruit.getId());
控制器 Controller 里面如何添加?fruitServices 写在 service 层,这个 Controller 层只做请求和响应,具体业务逻辑与上面添加代码一样(即 save 方法)。
@PostMapping("/add")
public ResponseBody<String> addFruit(Fruit fruit) {
// 调用 service 层方法
HttpStatus status = fruitService.save(fruit);
// 针对操作成功与否,返回不同的响应
if (status == HttpStatus.OK) {
// 操作成功
return ResponseBody.success();
}
return ResponseBody.failure(status);
}普通的增删改查,其实与数据库操作并无区别【步骤都差不多】
- 创建一个接口类 【继承 ElasticsearchRepository】 (MySql 可能会用到 @Mapper 注解或者映射文件,这里采取 Mybatis 来管理 MySql)
- 可以直接写 Controller 层【如果可以,也可以写在 Service 层】
- 运行、浏览器请求接口【完毕!】
2. 搜索?——用 ES 方式查询数据库
对于实际例子,我们可以看这篇2019年的文章【SpringBoot 整合 ElasticSearch】
对于查询来说,相比于普通增删改查,多了一个 @Query 注解,对于老版本的一些方法已经废弃了,如 NativeSearchQueryBuilder 已被弃用
@Query 注解?elasticsearch 常见几种查询方式
- 精准查询 term【完全匹配,不分词】
- 单值查询
- 多值查询
- 匹配查询 match 【分词,类似模糊匹配】
- match
- match_all
- multi_match
- match_phrase 【分词,保留全部搜索词项,位置相同】
- bool 查询【类似于 mysql where语句】
- must 【and 匹配】
- must_not 【不算贡献分】
- should 【or 匹配】
- filter 【过滤,不算贡献分】
- filter 查询 【缓存,常和range范围搭配使用】
- gt 大于
- lt 小于
- gte 大于等于
- lte 小于等于
当没有采用 @Query 时,默认精准查询
如查询 http://localhost:8123/fruit/红富士苹果
List<Fruit> findAllByName(String name);
如果在接口方法上加上 @Query,同样查询红富士苹果
▶ 调用接口与上面类似,只是作为区分,方法名以 Match 结尾【可自定义方法名】
🐱🚀 同样如果不用重新创建一个方法,直接在接口方法添加 @Query 就行
@Query("{\"match\":{\"name\":\"?0\"}}")
List<Fruit> findAllByNameMatch(String name);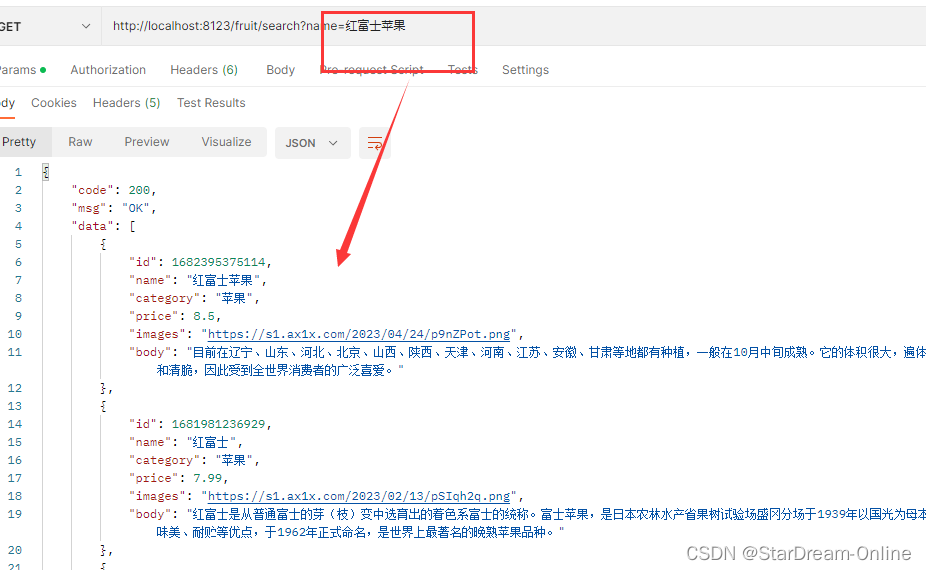
😊总结:自定义查询的方式有2种
- 自定义1个接口,并对其进行实现 【官方基本够使用,因此很少自己创建】
- 使用 @Query 来修饰接口方法 【个人感觉用的较多】
3. 爬虫?这只是方便获取大量网上信息
@Autowired
private BlobRepository blobRepository;
@Test
public void testE1() throws InterruptedException {
for (int i = 0;i < 31;i++) {
String content = "";
// 创建httpclient实例
try(CloseableHttpClient httpclient = HttpClients.createDefault()) {
// 创建http get实例
HttpGet httpget = new HttpGet("https://www.quge9.cc/book/666/" + i + ".html");
// 执行get请求
CloseableHttpResponse response = httpclient.execute(httpget);
// 返回实体
HttpEntity entity = response.getEntity();
// 转码: UTF-8
content = EntityUtils.toString(entity, "utf-8");
// 关闭流和释放系统资源
response.close();
} catch (IOException e) {
e.printStackTrace();
}
// 解析网页
Document document = Jsoup.parse(content);
// 选出文章段落
Elements articleP = document.selectXpath("//*[@id=\"chaptercontent\"]");
// 处理文章段落,将每一段拆开,添加上<p></p>
String[] text = articleP.text().split(" ");
List<String> pList = new ArrayList<>(Arrays.asList(text));
StringBuilder resultP = new StringBuilder();
for (String p : pList) {
// 过滤掉无关信息
if (!p.contains("请收藏本站") && !p.contains("点此报错")) {
p = p.replaceAll((char)12288 + "","");
p = "<p>" + p + "</p>";
resultP.append(p);
}
}
// 解析标题
Elements articleT = document.select("#read > div.book.reader > div.content > h1");
// 获取结果,保存数据库
Blob blob = new Blob(System.currentTimeMillis(),articleT.text(),"史上最强练气期",new Date(),resultP.toString());
blobRepository.save(blob);
System.out.println("正在爬取第" + i + "章内容...,每隔3秒爬取下一章内容!");
Thread.sleep(3*1000);
}
}






![[C++初阶]栈和队列_优先级队列的模拟实现 deque类 的理解](https://img-blog.csdnimg.cn/e11affaba9a6468da59f9cd57c621309.png)