为了更广泛的医学应用,为催化任何所需的化学反应而重新设计蛋白质是蛋白质工程的重点。因此作者开发了ProteinGAN,这是一种基于自注意力的生成对抗网络,能够学习自然蛋白质序列的多样性,并生成功能性蛋白质序列。
来自:Expanding functional protein sequence spaces using generative adversarial networks
目录
- 背景概述
- 方法
背景概述
蛋白质的3D结构、物理化学性质和分子功能由其氨基酸序列决定。从20种常见的氨基酸中,一个包含100个氨基酸的小尺寸蛋白质可以用 1 0 130 10^{130} 10130种不同的方法制成。在这个巨大的多维空间中,估计只有 1 / 1 0 77 1/10^{77} 1/1077可以折叠成3D结构来执行特定功能。这给旨在筛选具有增强特性的新序列方法带来了很大的负担,因为随机的氨基酸替换都可能会导致蛋白质活性下降。而另一方面,机器学习可以直接从氨基酸序列推断蛋白质特性和功能。能够产生新的功能序列变体的计算方法,并绕过巨大的蛋白质序列空间的实验筛选,对于满足生物医学和生物技术领域对新蛋白质多样性的挑战和需求变得越来越重要。
传统的生物信息学方法,如基于隐马尔可夫模型的方法,以及最近的机器学习方法,已经证明了在天然蛋白质序列中发现结构信息的巨大潜力。然而,蛋白质研究中现有的大多数机器学习模型都是判别性的,也就是说,使用现成的数据对模型进行训练,以预测给定蛋白质序列的特性。相比之下,生成建模方法能够学习底层数据分布并从中生成新样本。因此,从理论上讲,这些方法可以从功能性蛋白质序列空间学习并生成新的蛋白质序列,为发现新的功能性序列提供途径。
因此,作者提出了ProteinGAN(图1a),这是一个生成式对抗网络,能够生成具有天然生化特性的新型功能蛋白质序列。通过学习氨基酸之间复杂的依赖关系,证明了神经网络概括蛋白质序列空间的能力。ProteinGAN通过生成训练数据中不存在的蛋白质结构来生成高度多样化的序列。

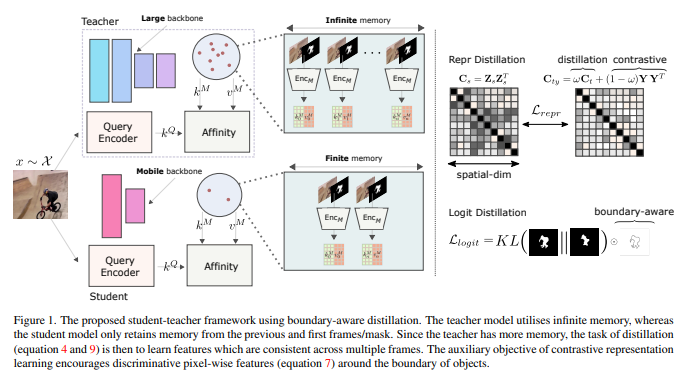
- 图1:ProteinGAN学习天然蛋白质序列之间的内在关系。
- a:ProteinGAN训练。给定一个随机输入向量,Generator网络产生一个蛋白质序列,由Discriminator网络通过将其与自然蛋白质序列进行比较进行评分。生成器试图通过生成最终看起来像真实序列的序列来欺骗判别器(生成器从未看到真正的序列)。
- b:64个生成序列在不同训练迭代下与训练数据最接近的自然序列的序列一致性。
- c:通过插值每个变量维度,潜在空间向量与蛋白质特性相关。
- d:序列多样性可以通过改变潜在向量的方差来控制。x轴表示插值潜向量的标准差,y轴表示在聚类序列相似性阈值内增加70%的序列聚类数量。
- e:ProteinGAN有效捕获天然MDH序列的氨基酸分布。序列变异性表示为多序列比对估计的生成序列和训练序列的香农熵。低香农熵值表示高度保守,而高熵值表明在给定位置上氨基酸多样性高。
方法
GAN架构由两个网络组成:一个判别器和一个生成器。每个网络都使用ResNet块(图2)。鉴别器中的每个块包含三个1D卷积层,滤波器大小为3和ReLU激活。生成器残差块由两个转置卷积层、一个相同滤波器大小为3的卷积层和ReLU激活组成。每个网络都有一个自注意力层。用转置卷积技术进行上采样。为了保证训练的稳定性,在所有层上都实现了归一化。

- 图2:ProteinGAN的框架。
判别器的输入是one-hot编码,词汇表大小为21:20个规范氨基酸和表示序列开头或结尾的空格符号。生成器输入是一个包含128个值的向量:从均值为0,标准差为0.5的随机分布中抽取。