来源:投稿 作者:王老师
编辑:学姐
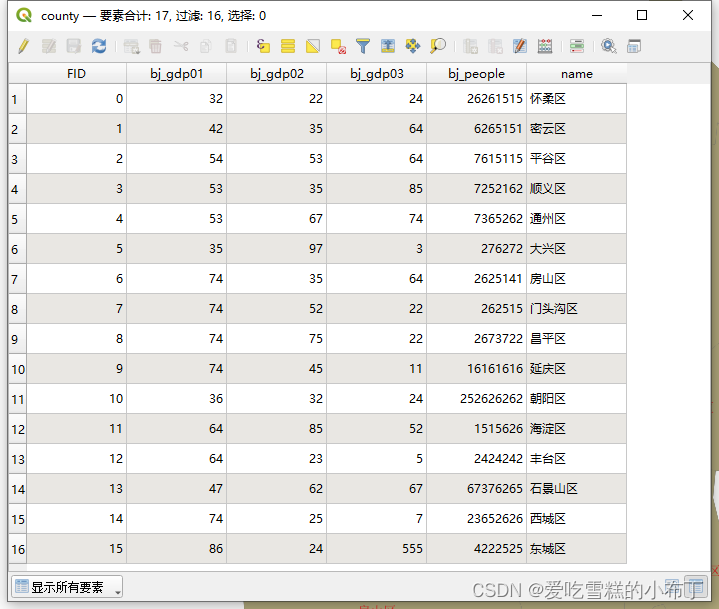
论文1

论文标题:
Boosting Video Object Segmentation via Space-time Correspondence Learning
论文链接: https://arxiv.org/pdf/2304.06211v1.pdf
代码链接:暂未开源
作者单位:上海交通大学 & 浙江大学
发表于CVPR2023
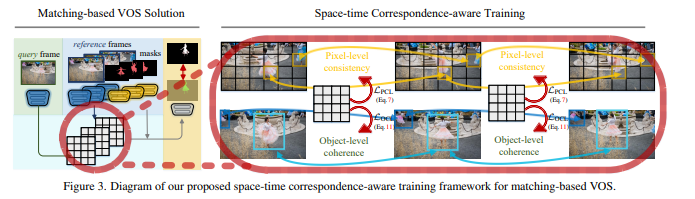
当前领先的视频对象分割(video object segmentation,VOS)解决方案通常遵循基于匹配的机制:对于每个查询帧,根据其与先前处理的帧和第一个注释帧的对应关系来推断分割掩码。他们只是简单地利用来自地面实况掩码的监督信号来学习掩码预测,而不对时空对应匹配构成任何约束,然而,时空对应匹配是这种机制的基本组成部分。为了缓解这一关键但通常被忽视的问题,我们设计了一个感知对应关系的训练框架,该框架通过明确鼓励网络学习过程中的鲁棒对应关系匹配来促进基于匹配的VOS解决方案。通过在像素和对象级别上全面探索视频中的内在连贯性,我们的算法通过无标签的对比对应学习加强了掩码分割的标准、完全监督的训练。在训练过程中既不需要额外的注释成本,也不需要在部署过程中造成速度延迟,也不引起架构修改的情况下,我们的算法在四个广泛使用的基准测试上提供了坚实的性能提升,即DAVIS2016和2017,以及YouTube-VOS2018和2019,在著名的基于匹配的VOS解决方案之上。
论文2

论文标题: Two-shot Video Object Segmentation
论文链接: https://arxiv.org/abs/2303.12078
代码链接:https://github.com/yk-pku/Two-shot-Video-Object-Segmentation
作者单位:北京大学 & 微软亚洲研究院
发表于CVPR2023
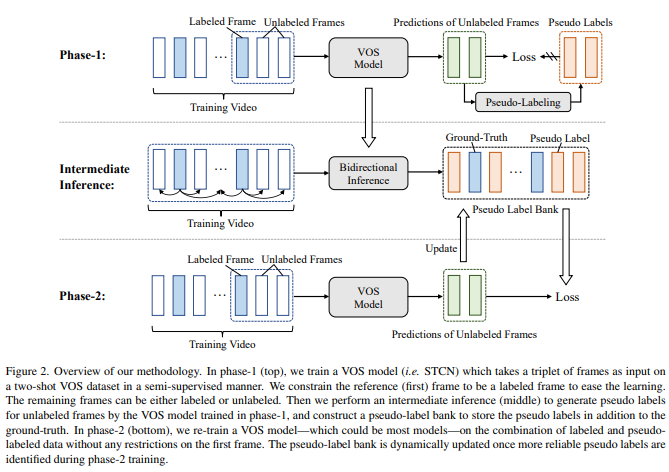
先前关于视频对象分割(video object segmentation VOS)的工作是在密集注释的视频上进行训练的。然而,获取像素级别的注释是昂贵且耗时的。在这项工作中,我们证明了在稀疏注释的视频上训练令人满意的VOS模型的可行性——我们只需要每个训练视频两个标记的帧,同时保持性能。我们将这种新的训练范式称为两镜头视频对象分割,简称两镜头VOS。其基本思想是在训练期间为未标记的帧生成伪标签,并在标记和伪标记数据的组合上优化模型。我们的方法非常简单,可以应用于大多数现有框架。我们首先以半监督的方式在稀疏注释的视频上预训练VOS模型,第一帧总是标记的。然后,我们采用预训练的VOS模型为所有未标记的帧生成伪标签,然后将其存储在伪标签库中。最后,我们在标记和伪标记数据上重新训练了VOS模型,对第一帧没有任何限制。我们首次提出了一种在两次VOS数据集上训练VOS模型的通用方法。通过使用YouTube VOS和DAVIS基准的7.3%和2.9%的标记数据,我们的方法与在完全标记集上训练的方法相比,获得了可比的结果。
论文3

论文标题: Under Video Object Segmentation Section
论文链接: https://arxiv.org/abs/2303.07815
代码链接:暂未开源
作者单位:英国三星研究院
发表于CVPR2023
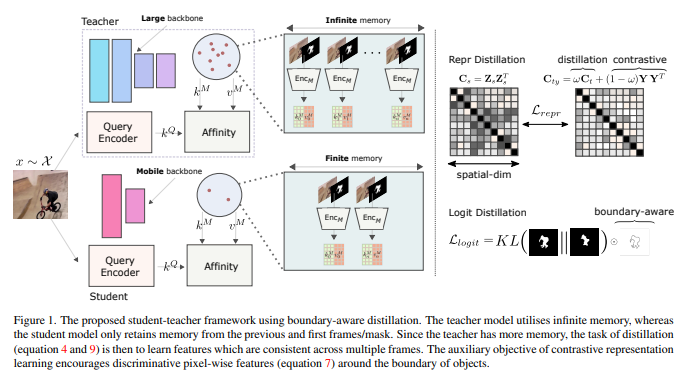
本文解决了在资源受限的设备(如手机)上进行半监督视频对象分割的问题。我们将这个问题公式化为一个蒸馏任务,从而证明具有有限内存的小型时空存储网络可以实现与现有技术相竞争的结果,但计算成本很低(在三星Galaxy S22上每帧32毫秒)。具体来说,我们提供了一个理论基础框架,将知识提取与监督对比表示学习相结合。这些模型能够共同受益于像素对比学习和来自预训练教师的提炼。我们通过在标准DAVIS和YouTube基准上实现具有竞争力的J&F以达到最先进水平来验证这一损失,尽管运行速度更快,且参数更少。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“CVPR”获取CV方向顶会必读论文
码字不易,欢迎大家点赞评论收藏!