简介
主页:https://ethanweber.me/nerfbusters/
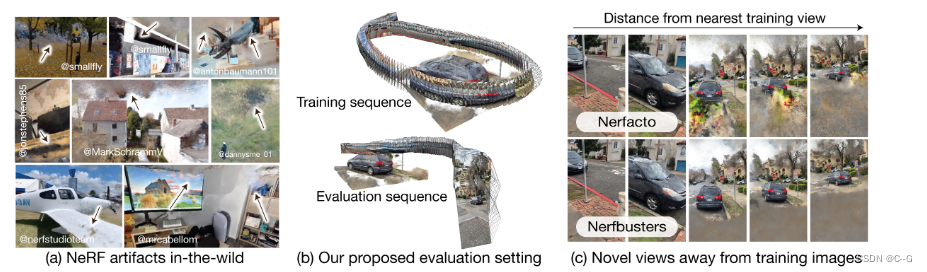
在远离训练视图的新视图上渲染nerf可能会导致伪影,例如浮动或糟糕的几何形状。这些工件在野外捕获(a)中很普遍,但在NeRF基准测试中很少看到,因为评估视图通常从与训练视图相同的相机路径中选择。现有的评估方案通常不能捕捉到这些效果,因为它们通常只在训练捕获的每8帧评估图像质量
现有的手工制作的正则化器并不能去除漂浮物,也不能改善场景的几何形状
提出了一个新的野外捕获数据集和一个更现实的评估过程(b),其中每个场景通过两条路径捕获:一条用于训练,一条用于评估。

提出了Nerfbusters,这是一种基于3D扩散的方法,该方法利用局部3D先验和一种新的基于密度的分数蒸馏采样损失来阻止NeRF优化过程中的伪影,可以改善场景几何形状并减少漂浮物©,在这个更现实的评估设置中显着改进了现有的正则器
论文从SDS优化程序中获得灵感,但使其以无条件的方式直接在3D密度值上监督NeRF密度,作为基础模型,在从ShapeNet对象中提取的局部3D立方体上训练一个3D扩散模型。
局部立方体内的几何(表面)分布明显比2D自然图像或全局3D对象简单,减少了对条件反射和高引导权重的需求
评估对象

- 录制视频来捕捉场景(训练分割)
- 从一组不同的视点录制第二个视频(评估分割)
- 从两个视频中提取图像并计算所有图像的相机姿势
- 在两个分割的组合上训练一个“伪地面真相”模型,并为评估视点保存深度、法线和可见性地图
- 在训练分割上优化NeRF,并从评估分割中评估新的视点(使用捕获的图像和伪地面真值图)。
Masking valid regions
使用可见性掩膜只评估评估图像中在训练视图中共同观察到的区域
定义为(1)没有被任何训练视图看到的区域,或者(2)被预测太远(即预测深度>距离阈值)的区域。阈值设置为训练和评估分割中任意两个相机原点之间最大距离的两倍。在Nerfstudio代码库中,这对应于2的值,因为相机姿势被缩放以适应具有边界(-1,-1,-1)和(1,1,1)的框
Coverage
评估视点中所有像素中评估像素的百分比(即被可见性和深度掩盖后),这是深度补全中通常报告的一个度量
实现流程
- 训练一个扩散模型来学习三维表面斑块的分布。该模型在合成数据上进行训练,无条件地生成局部三维立方体
- 将该局部先验应用于真实3D场景的NeRF重建。通过在训练过程中查询场景中局部3D补丁的密度,并使用一种新的密度分数蒸馏分数(DSDS)损失来正则化采样密度来实现这一点,改进了监督信号稀疏区域的重建,并消除了浮动信号
Nerfbusters扩散模型

Nerfbusters扩散模型的训练数据。给定一个网格,提取按网格大小1 - 10%缩放的局部立方体。以
3
2
3
32^3
323 的分辨率对这些立方体进行体素化,并通过随机旋转和随机膨胀来增强它们。Shapenet的合成场景提供了多种多样的局部立方体,包括平面、圆形和精细结构。
将局部3D先验表示为去噪扩散概率模型(DDPM),该模型迭代地对占用 x 的32 × 32 × 32立方体进行去噪
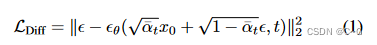
其中
t
∼
μ
(
0
,
1000
)
,
ϵ
∼
N
(
0
,
I
)
t \sim \mu(0,1000),\epsilon \sim N(0,I)
t∼μ(0,1000),ϵ∼N(0,I)
使用了一个小的7.2M参数的3D U-Net,从ShapeNet场景中提取的合成三维立方体上训练模型
为了收集用于训练的三维立方体,选择一个随机的ShapeNet网格,并沿着物体表面提取N个局部立方体有界的补丁,立方体大小在物体边界体积的1-10%之间变化。以 3 2 3 32^3 323 的分辨率对这些局部样本进行体素化。然后用随机数量的旋转和膨胀来增加立方体。
该数据处理管道快速,并在训练期间在线执行,以增加3D立方体的多样性。用膨胀调整表面的厚度(而不是将内部像素标记为已占用)对于非水密网格来说更快,定义更好
新的正则化策略
(1)从NeRF的非空部分采样占用立方体的机制;
(2)一种新的密度分数蒸馏采样(DSDS)损失,鼓励采样占用符合扩散模型的学习几何先验
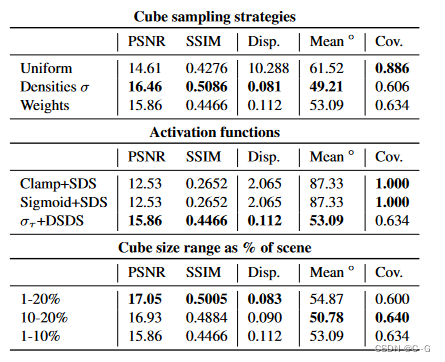
采样策略
为了实现更有效的采样,存储了一个低分辨率的累积权重或密度网格,它可以用来告知对场景中不同位置进行采样的概率。该网格在NeRF训练过程中与指数移动平均(EMA)衰减联合更新,这样在训练的后期阶段不会重复采样删除浮动的区域。在使用累积权值和密度之间的选择有相关的权衡:使用累积权值产生的立方体主要是在经常看到的表面上采样,而使用密度则可以对遮挡区域进行采样。在实践中使用密度网格,限制为[0,1],以避免少数密度支配采样概率。这种重要性采样方法几乎没有额外的成本,因为存储密度或权重沿着已经用于体渲染的光线,并使用一个小的 2 0 3 20^3 203 网格。这个网格通知了3D立方体中心的选择,大小是在场景的1-10%的范围内随机选择的,体素分辨率为 3 2 3 32^3 323。
DSDS损失
实验表明,NeRF的密度在 [ 0 , ∞ ] [0,\infty] [0,∞],以0.01为分界线,小于该值为空白区域,在[0.01,2000]为占用区域。论文采用密度分数蒸馏采样(DSDS)损失来处理密度之间的域间隙。
给定NeRF立方体密度 σ \sigma σ,将密度离散为二元占用: x t = 1 x_t = 1 xt=1 如果 σ > τ σ > τ σ>τ else −1对于扩散时间步 t,其中 τ 是一个超参数,决定在什么密度下将体素视为空的或已占据的。Nerfbusters扩散模型预测去噪后的立方体 x 0 x_0 x0。时间步长 t 是一个超参数,它决定了扩散模型应该去除多少噪声,并且可以解释为学习率。这里选择了一个小的 t ∈ [ 10 , 50 ] t \in [10,50] t∈[10,50]。
得到去噪后的立方体
x
0
x_0
x0 ,惩罚扩散模型预测为空的NeRF密度,或增加扩散模型预测为被占据的密度
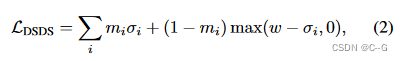
m
=
1
{
x
0
<
0
}
m = 1 \{x_0<0\}
m=1{x0<0}是基于去噪预测的掩码。
在扩散模型预测空白的地方惩罚密度,在模型预测占用的地方增加密度
W是一个超参数,它决定了在已占用空间中增加多少密度
max算子确保如果被占用的体素的密度已经超过 w,则不会产生损失
与SDS类似,DSDS损失通过单个前向传递提取扩散先验,而不通过扩散模型进行反向传播
与SDS不同,DSDS损失在将原始采样占有率提供给扩散模型之前,不会向其添加噪声
虽然可能会觉得占用网格采样削弱优化过程中不完全匹配的分布噪声数据集用于训练,不过发现去噪过程产生合理的样本都是在清洁表面的管汇和类似的输入数据集的内容
DSDS对于任何预测为空或已占用的密度都具有梯度
可见性损失函数

局部3D扩散模型改进了场景几何并去除了漂浮物,但它需要适当的启动密度,因为它在局部运行,因此需要上下文信息来接地其去噪步骤
提出了一个简单的损失,惩罚多个训练视图未看到的3D位置的密度
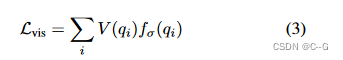
f
σ
(
q
i
)
f_\sigma(q_i)
fσ(qi)为NeRF在3D点
q
i
q_i
qi的密度,
V
(
q
i
)
=
1
{
∑
j
=
1
v
i
j
<
1
}
V(q_i) = 1 \{\sum_{j=1} v_{ij}<1\}
V(qi)=1{∑j=1vij<1} 表示该位置在任何训练视图中都不可见。用视锥检查来近似第 j 个训练视图中第 i 个3D位置的可见性
v
i
j
v_{ij}
vij∈{0,1}
通过在训练图像周围定义一个紧密的球体来实现这一点,并渲染从球体表面的随机位置发射的批量光线,通过场景中心,直到远处
使用建议采样器来对表面周围的样本进行重要采样,因此损失在快速剔除可见区域外高密度的任何浮动伪影方面是有效的
实验
为了评估目的,关闭姿态估计,然后训练Nerfacto进行30K次迭代,这需要半小时
使用不同的正则化器方法对这个检查点进行微调,将提出的方法与vanilla Nerfacto、Nerfacto与提出的可见性损失、Nerfacto与可见性损失和3D稀疏性损失、3D TV正则化和2D TV(如RegNeRF)进行了比较
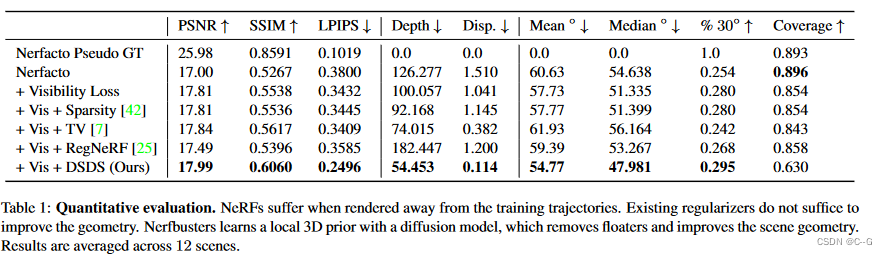
使用了Nerfacto默认开启的失真损失,所有方法在前1K次微调迭代内都是有效的(在NVIDIA RTX A5000上用于Nerfbusters约4分钟),但训练了5K次迭代
对于3D基线,每次迭代采样
403
2
3
40 32^3
40323个立方体,对于2D基线RegNeRF,渲染
3
2
2
32^2
322 个补丁。通常的NeRF重建损失也应用在微调期间,每批4096条射线

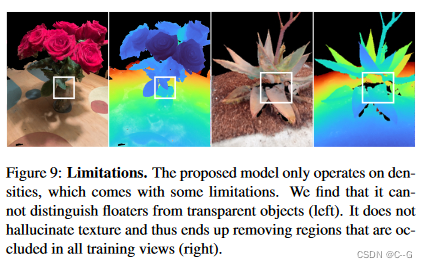
limitations
提出的模型只适用于密度,这有一些局限性。它不能区分漂浮物和透明物体(左)。它不会产生幻觉纹理,因此最终会移除所有训练视图中被遮挡的区域(右)。
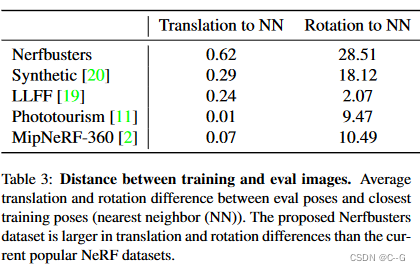
future work
Transparent objects
nerf能够通过为透明对象分配低密度来表示透明对象。这些透明密度的行为类似于漂浮物,它需要语义信息来区分两者。由于局部扩散先验没有语义信息,它删除了透明物体
Hallucinating texture
由于方法对密度进行操作,因此该方法可以清除几何形状,但不能编辑纹理。这意味着可以移除含有漂浮物的区域或填充孔洞,但不能给这些区域上色。