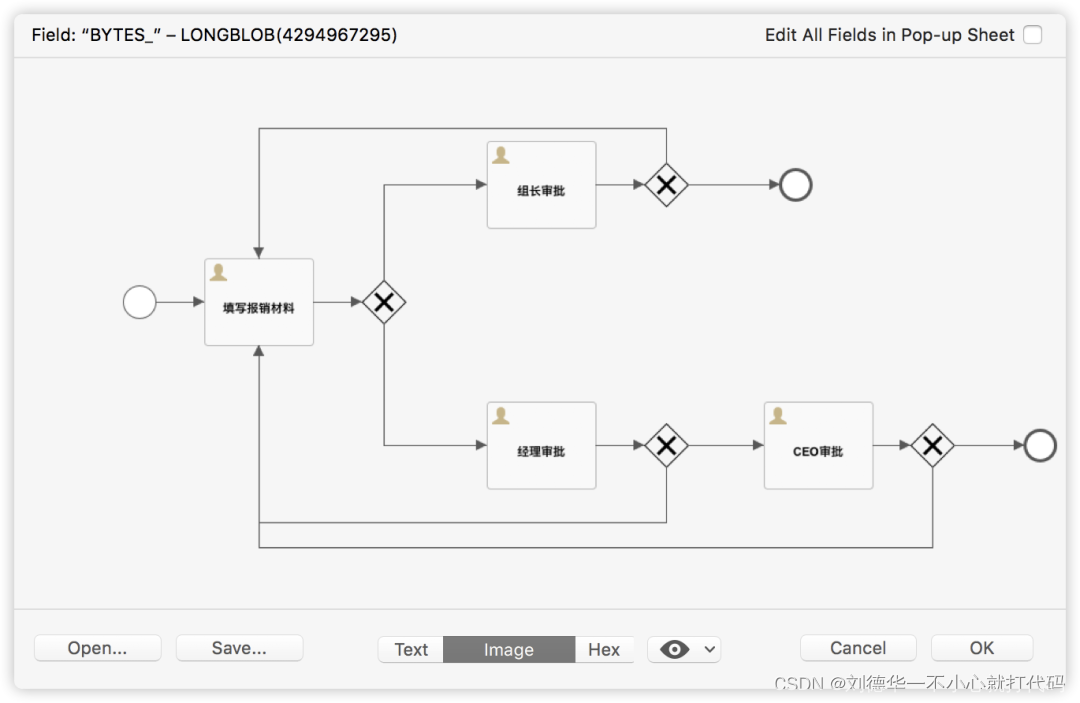
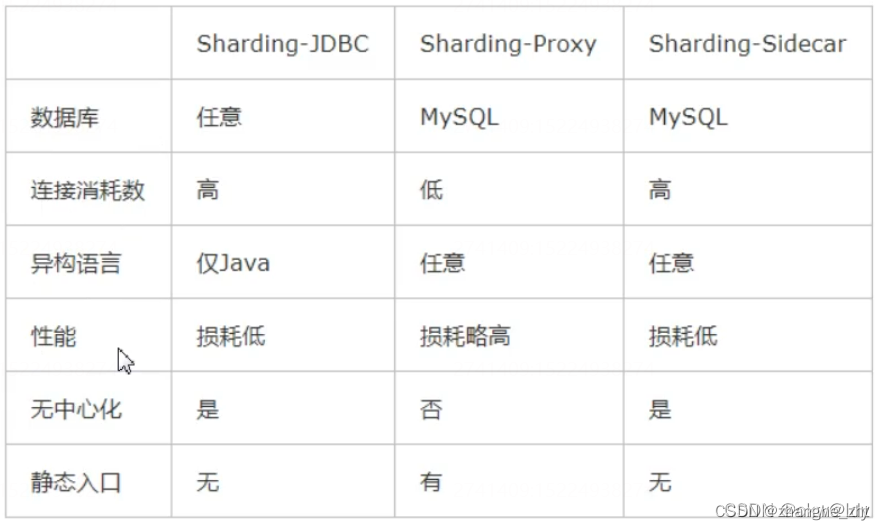
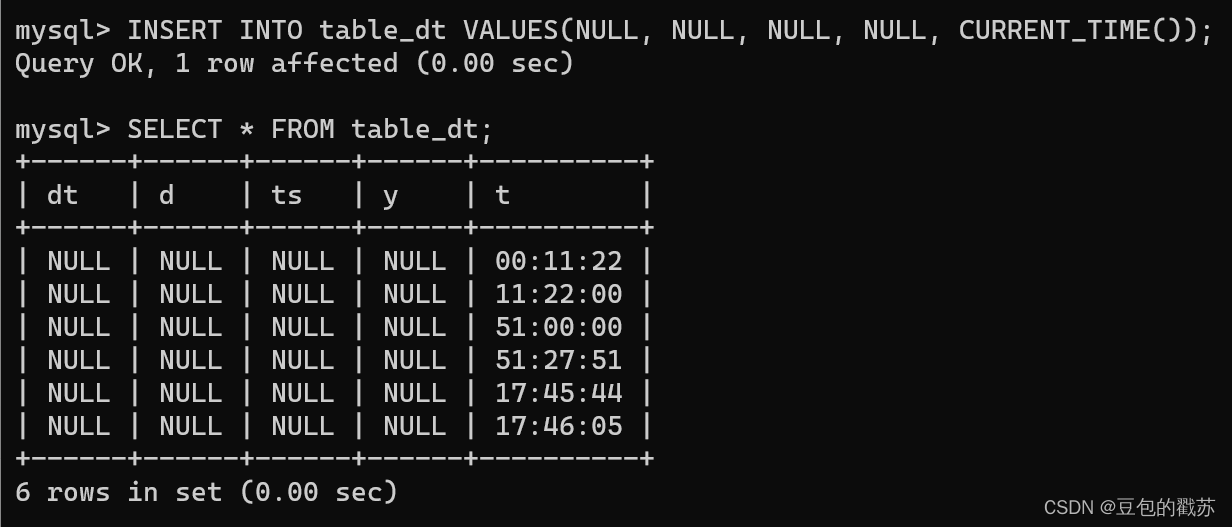
YOLOv1代码复现2:数据加载器构建
前言
在经历了Faster-RCNN代码解读的摧残后,下决心要搞点简单的,于是便有了本系列的博客。如果你苦于没有博客详细告诉你如何自己去实现YOLOv1,那么可以看看本系列的博客,也许可以帮助你。
另外,当完成所有代码后,会将代码放在GitHub上。
目标
最主要的目标肯定是能够跑通整个代码,并且我希望可以详细的告诉大家如何参考博客自己去实现,因此,文章也会记录我自己遇到的错误和调试过程。
本系列计划完成的内容与已完成的内容:
本系列计划六篇,如下:
- 第一篇:辅助功能实现
- 第二篇:数据加载器构建(文本)
- 第三篇:网络框架构建(等待完成)
- 第四篇:损失函数构建(等待完成)
- 第五篇:预测函数构建(等待完成)
- 第六篇:总结(等待完成)
目录:
文章目录
- YOLOv1代码复现2:数据加载器构建
- 1. 要实现的功能:
- 2. 导入所需的库:
- 3. My_Dataset类构建:
- 3.1 类框架构建:
- 3.2 \_\_init\_\_方法:
- 3.3 parse_xml方法:
- 3.4 parse_xml_to_dict方法:
- 3.5 read_json方法:
- 3.6 \_\_len\_\_方法:
- 3.7 \_\_getitem\_\_方法:
- 3.8 encode方法:
- 3.9 纠错:
- 4. 调试代码:
- 5. 完整代码:
- 6. 总结:
1. 要实现的功能:
对于数据加载器,和我们平时实现的不同,它要求将图像的标签输出为7*7*30的格式,这样才可以与模型的预测输出相匹配。
另外,上一篇的辅助文件,还要求输出一个变量,其带有box坐标、类别和概率信息。
ps:完整代码在文末。
2. 导入所需的库:
这里先把可能用到的库导入:
import torch
import cv2
import os
import json
import numpy as np
from PIL import Image
from lxml import etree
from torch.utils.data import Dataset
from torchvision import transforms
3. My_Dataset类构建:
3.1 类框架构建:
我们知道Dataset类至少需要实现三个方法,即__init__\__len__\__getitem__:
class My_Dataset(Dataset):
def __init__(self):
pass
def __len__(self):
pass
def __getitem__(self, idx):
pass
3.2 __init__方法:
参数:
传入的参数有:
| 参数 | 意义 |
|---|---|
| root_file | 传入数据集的路径 比如:…\data\VOC2012 |
| transform | 需要进行的图像预处理操作,默认为空 |
| txt_name | 用于控制加载训练集还是测试集,默认为train.txt |
| images_size | 缩放后图像的大小,默认为448*448 |
其中,需要对最后一个参数说明,论文原文要求输入图像大小为448*448。
实现
由于传入的路径参数为..\data\VOC2012,因此需要拼接出我们需要的几个路径,如下图:

可以使用os.path.join方法实现:
# 拼接出需要的路径
self.img_root = os.path.join(root_file, "JPEGImages")
self.annotations_root = os.path.join(root_file, "Annotations")
# 读取ImageSets/Main/下的train.txt or test.txt
self.txt_path = os.path.join(root_file, "ImageSets", "Main", txt_name)
另外,train.txt中的值都是文件名,没有后缀,因此需要和.xml后缀拼接在一起,形成真正的文件名:
# 将文件名(2007_000027)和后缀(.xml)拼接在一起,这样才是真实的文件
with open(self.txt_path) as f:
xml_list = [os.path.join(self.annotations_root, line.strip() + ".xml")
for line in f.readlines() if len(line.strip()) > 0]
接着,我们需要去读取每个xml文件里的内容,我们定义parse_xml方法去解读它:
# 解读xml文件
self.parse_xml(xml_list)
同样的,需要读取pascal_voc_classes.json文件,同样定义read_json方法去解读它:
# 读取json文件
self.read_json()
最后,就是初始化变量值即可:
# 定义预处理方法
self.transform = transform
# 定义图像大小
self.image_size = images_size
3.3 parse_xml方法:
参数:
只有一个参数,即xml_list,里面的值都是每个xml文件对应的路径值。
实现:
定义一个类变量,用于存储后面所有的值:
self.xml_list = []
接着,遍历xml_list里面的每一个路径值:
- 首先,以文件的形式打开它,并直接读取所有内容,此时返回的值为字符串
- 接着,用导入的
xml库,构建xml对象 - 然后,再定义一个方法,去获取
xml对象里面节点的内容,并以字典形式返回 - 最后,把字典的值添加入
self.xml_path
# 解析xml文件,返回列表值
for xml_path in xml_list:
with open(xml_path) as f:
xml_str = f.read()
# 构建xml对象
xml = etree.fromstring(xml_str)
# 获取节点的内容,并转为字典值
data = self.parse_xml_to_dict(xml)["annotation"] # 获取annotation节点下的所有内容
# 添加
self.xml_list.append(data)
3.4 parse_xml_to_dict方法:
参数:
传入的参数只有一个,即xml对象。
实现:
我们知道,xml对象里面的值肯定是由标签、标签对应的值构成,而标签与标签之间可以嵌套的,如下:
<a>
hello
<b>hi</b>
</a>
因此,想要获取所有的值,只有一个方法:递归。定下这个思路就好实现了。
首先,递归的结束条件必须有,即xml对象为空,就可以结束递归了:
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
# xml.tag节点名字
# xml.text里面的值
return {xml.tag: xml.text}
如果没有结束,继续往下走:
- 先定义一个结果字典用于存储值
- 接着,循环遍历
xml对象中的每个节点:- 递归一下(因为这个节点可能有子节点)
- 当递归结束了,说明此时的节点已经被掏空了,也返回了
{xml.tag: xml.text}的值,那么,基于此: - 判断
xml对象的标签是否为object(即是否为图像中的对象,由于图像同一个对象可能不只一个值,因此专门用一个列表来存放值)- 如果不是,可以直接放入结果中;
- 如果是,判断这个对象之前是否出现过,没有则新加一个列表存放值,有则直接添加即可
result = {}
# 对于每个xml中的子节点
for child in xml:
child_result = self.parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
返回值
解析完成后的字典值:
return {xml.tag: result}
3.5 read_json方法:
这个方法简单,就是读取json文件,然后转为字典值即可,只要学习过python基础的都应该可以编写出来,我就不多说了:
def read_json(self):
# 读取类别文件,一共20个类,从1开始是因为0留给背景
json_file = '../data/VOC2012/pascal_voc_classes.json'
with open(json_file, 'r') as f:
self.class_dict = json.load(f)
3.6 __len__方法:
这个方法就是返回加载数据的长度,可以直接用len函数返回即可:
return len(self.xml_list)
3.7 __getitem__方法:
参数:
这个参数是固定的,即idx,是随机索引值。
返回值:
这个方法需要先明确返回的值。这里,我决定返回四个值:
- image:图像对象,原始图像,tensor格式
- img:图像对象,resize为448*448的,并且为cv2的对象格式
- target:用于画图的字典值
- new_target:
7*7*30的返回值
说明:
如果你是按照我的思路,一行一行的敲/读,那么你还不能启用调试功能,此时建议你先把所有代码拷贝过来用,然后可以调试看具体参数值。
在此,再次声明我的文件目录结构:(有些路径参数,需要你自己修改)

因此,下面讲解的时候,配图都是调试时的真实值。
实现:
首先,随机获取一个解析后的xml字典对象:
# 随机读取一个xml文件
data_dict = self.xml_list[idx]

那么,可以获取图像的名称,并打开图像:
# 获取xml文件对应的图像路径
img_path = os.path.join(self.img_root, data_dict["filename"])
# 打开图像
image = Image.open(img_path)
然后,初始化变量:
# 初始化一些变量
boxes = [] # 边界框
labels = [] # 标签值
接下来,循环遍历xml字典中object下的对象值:
# 读取xml文件中object节点下的内容
# 因为一张图片可能不知一个对象
for obj in data_dict["object"]:

基于上图,我们可以去获取坐标值和类别值,并添加到对应列表中。不过,不要忘记类别值需要转为数字值:
for obj in data_dict["object"]:
# 获取bbox框的坐标
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
# 添加真实边界框
boxes.append([xmin, ymin, xmax, ymax])
# 添加标签 obj["name"]=person, self.class_dict[obj["name"]] = 15
labels.append(self.class_dict[obj["name"]])

接着,将相关变量转为tensor类型的值,并将这些值传入一个名为target的字典中:
# 将所有的类型转为tensor类型
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
# 图像也转为tensor值
f = transforms.ToTensor()
image = f(image)
# 创建一个字典,保存数据,用于画图
target = {}
target['boxes'] = boxes
target['labels'] = labels
接下来就是要将已经获取的坐标值、类别值、概率值转为7*7*30的形式了。
首先,需要将坐标归一化(相对于图像宽高):
- 先获取图像的宽、高
- 然后用box坐标除以对应的宽高即可
# 归一化处理
# expand_as 是将[w, h, w, h]变为和boxes shape一样的
_,w,h = image.shape
boxes /= torch.Tensor([w, h, w, h]).expand_as(boxes)

接着,将图像缩放到448*448的大小,这里我们先直接缩放以实现代码,后期看情况是否修改为其它的缩放方式:
# 将图像缩放为448*448
img = cv2.resize(image.numpy(), (self.image_size, self.image_size))
看看img的值:

发现有问题,就是resize只是修改了前面两个维度的值,但是image第一个维度是图像的通道数,因此需要修改一下代码:
# 将图像缩放为448*448
# permute方法是按照索引调整image的维度,我们将
image = image.permute(1,2,0)
img = cv2.resize(image.numpy(), (self.image_size, self.image_size))
此时img的值:

接下来,我们定义一个名为encode的方法将值处理为7*7*30的结果:
# 对target中的boxes、labels进行处理,转为7*7*30的值
# 注意此时的boxes是归一化后的值
new_target = self.encode(boxes,labels)
最后,就是定义预处理的方法,并返回值即可:
# 预处理
if self.transform is not None:
for transform in self.transform:
img = transform(img)
return image,img,target,new_target
这里,需要补充一点:此时的预处理方法,不能调用官方实现的预处理方法,因为官方实现的没有同时处理边界框的功能。
所以,这里我暂时先这么写,后期再进行修改。因为,我是边写代码边写博客的,这样才能记录的详细一些。所以有些功能还是需要后期修补,望理解。
3.8 encode方法:
参数:
传入的参数两个:
| 参数 | 意义 |
|---|---|
| boxes | 归一化后的坐标值 |
| labels | 边界框对应的类别值 |
比如,调试时的一个值为:

返回值:
返回一个7*7*30的张量。
实现:
首先,定义两个基本变量,即论文中每张图片划分S*S个网格,和类别个数:
# S*S , class = 20 (VOC)
S_cell = 7
class_num = 20
接着,定义一个缩放因子和一个全为0的7*7*30的变量:
cell_size = 1 / S_cell # 缩放因子
target = torch.zeros((S_cell,S_cell,class_num+10)) # 7*7*30
接下来的任务就是:用我们已有的值,去替换上面定义的7*7*30全为0值的张量。
首先,获取归一化后的框的宽、高和中心坐标:
# 获取宽高和中心坐标
wh = boxes[:, 2:] - boxes[:, :2]
cxcy = (boxes[:, 2:] + boxes[:, :2]) / 2
上面两个式子如何得来的,可以看下图:


然后,开始遍历所有对象:
# 遍历
# cxcy.size()[0] 表示一张图像有多少个对象
# 比如这里只有一个对象,那么i只能取到0
for i in range(cxcy.size()[0]):
这里,首先大家要知道:YOLOv1回归边界框,回归的是什么?见下图:

那么,我们下一步就是基于中心坐标值,去获取此时左上角的坐标:
cxcy_sample = cxcy[i] # 中心坐标 1*1
ij = (cxcy_sample / cell_size).ceil() - 1 # 左上角坐标,就是该网格左上角的坐标 (7*7)为整数

对上面调试的值进行解释说明(见下图):

那么,最后一步,也是最为关键的一步:将已有的值从7*7*30的零张量中替换。
这里替换的思路如下图:

- 由于这里是加载的真实数据集,因此置信度都为1。
- 论文中采取两个坐标框,因此这里也是同样采取两个,所以其实两个框的值都相同
- 20个概率值,只有真实类别为1,其余都为0
有了以上几点的说明,便可以进行操作了:
for i in range(cxcy.size()[0]):
cxcy_sample = cxcy[i] # 中心坐标 1*1
ij = (cxcy_sample / cell_size).ceil() - 1 # 左上角坐标,就是该网格左上角的坐标 (7*7)为整数
# 第一个框的置信度: 4 即30中的位置
target[int(ij[1]), int(ij[0]), 4] = 1
# 第二个框的置信度: 9 即30中的位置
target[int(ij[1]), int(ij[0]), 9] = 1
# 设置类别概率值为1: 加10是前面10个为坐标值,注意我们的类别是从1开始的
# 将真实类别的位置概率值设为1,其余位置默认为0
target[int(ij[1]), int(ij[0]), int(labels[i]) + 9] = 1
# 归一化后的图像的该网格的左上坐标 (1*1)
xy = ij * cell_size
# 计算边界框中心与左上角的偏差(归一化后),然后缩放到原来的
delta_xy = (cxcy_sample - xy) / cell_size # 中心与左上坐标差值 (7*7)
# 坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例
target[int(ij[1]), int(ij[0]), 2:4] = wh[i] # w1,h1
target[int(ij[1]), int(ij[0]), :2] = delta_xy # x1,y1
# 每一个网格有两个边框: 这里只能复制一份
target[int(ij[1]), int(ij[0]), 7:9] = wh[i] # w2,h2
# 由此可得其实返回的中心坐标其实是相对左上角顶点的偏移,因此在进行预测的时候还需要进行解码
target[int(ij[1]), int(ij[0]), 5:7] = delta_xy # [5,7) 表示x2,y2
最后,返回值即可:
return target
3.9 纠错:
我在写完后,进行进一步的调试的时候,发现了一个错误:encode方法中的ij变量有时候会达到7,此时会报索引错误。因为7已经超过了网格的索引。
后来,我发现了错误的原因是归一化处理的时候w,h值反了,如下图:

因此,只需要修改一下顺序即可:
# 归一化处理
_,h,w = image.shape
boxes /= torch.Tensor([w, h, w, h]).expand_as(boxes)
接着,我又发现一个错误,就是显示的图片,没有框,如下图:

然后,我突然想起tensor变量,内存是共享的,即当时我们用一个变量保存了box坐标,但是后面又归一化了,所以就没了,因此需要将变量克隆一份:
# 克隆一份
new_boxes = boxes.clone()
new_labels = labels.clone()
target = {}
target['boxes'] = new_boxes
target['labels'] = new_labels

4. 调试代码:
这里,就不赘述了,就是用上一篇的绘图函数的功能,进行调试的,只是注意目录结构即可:
# 调试用的代码
from matplotlib import pyplot as plt
import torchvision.transforms as ts
import random
from utils.draw_box import draw_objs
# 读取类别json文件
category_index = {}
try:
json_file = open('../data/VOC2012/pascal_voc_classes.json', 'r')
class_dict = json.load(json_file)
category_index = {str(v): str(k) for k, v in class_dict.items()}
except Exception as e:
print(e)
exit(-1)
# 加载
train_data_set = My_Dataset('../data/VOC2012')
for index in random.sample(range(0, len(train_data_set)), k=5):
image,img, target,_ = train_data_set[index]
# 因为修改了通道顺序,这里该回去
image = image.permute(2,0,1)
# 需要将tensor图像对象转为PIL对象
f = transforms.ToPILImage()
image = f(image)
plot_img = draw_objs(image,
target["boxes"].numpy(),
target["labels"].numpy(),
np.ones(target["labels"].shape[0]),
category_index=category_index,
box_thresh=0.5,
line_thickness=3,
font='arial.ttf',
font_size=20)
plt.imshow(plot_img)
plt.show()
5. 完整代码:
# author: baiCai
# 制作自己的数据加载器
import torch
import cv2
import os
import json
import numpy as np
from PIL import Image
from lxml import etree
from torch.utils.data import Dataset
from torchvision import transforms
class My_Dataset(Dataset):
def __init__(self,root_file,transform=None,txt_name='train.txt',images_size=448):
'''
:param root_file: 传入数据集的路径,比如 .\data\VOC2012
:param transform: 需要进行的图像预处理操作,默认为空
'''
# 拼接出需要的路径
self.img_root = os.path.join(root_file, "JPEGImages")
self.annotations_root = os.path.join(root_file, "Annotations")
# 读取ImageSets/Main/下的train.txt or test.txt
self.txt_path = os.path.join(root_file, "ImageSets", "Main", txt_name)
# 将文件名(2007_000027)和后缀(.xml)拼接在一起,这样才是真实的文件
with open(self.txt_path) as f:
xml_list = [os.path.join(self.annotations_root, line.strip() + ".xml")
for line in f.readlines() if len(line.strip()) > 0]
# 解读xml文件
self.parse_xml(xml_list)
# 读取json文件
self.read_json()
# 定义预处理方法
self.transform = transform
# 定义图像大小
self.image_size = images_size
def __len__(self):
return len(self.xml_list)
def __getitem__(self, idx):
# 随机读取一个xml文件
data_dict = self.xml_list[idx]
# 获取xml文件对应的图像路径
img_path = os.path.join(self.img_root, data_dict["filename"])
# 打开图像
image = Image.open(img_path)
# 初始化一些变量
boxes = [] # 边界框
labels = [] # 标签值
# 读取xml文件中object节点下的内容
# 因为一张图片可能不知一个对象
for obj in data_dict["object"]:
# 获取bbox框的坐标
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
# 添加真实边界框
boxes.append([xmin, ymin, xmax, ymax])
# 添加标签 obj["name"]=person, self.class_dict[obj["name"]] = 15
labels.append(self.class_dict[obj["name"]])
# 将所有的类型转为tensor类型
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
# 图像也转为tensor值
f = transforms.ToTensor()
image = f(image)
# 创建一个字典,保存数据,用于画图
# 克隆一份
new_boxes = boxes.clone()
new_labels = labels.clone()
target = {}
target['boxes'] = new_boxes
target['labels'] = new_labels
# 归一化处理
# expand_as 是将[w, h, w, h]变为和boxes shape一样的
_,h,w = image.shape
boxes /= torch.Tensor([w, h, w, h]).expand_as(boxes)
# 将图像缩放为448*448
image = image.permute(1, 2, 0)
img = cv2.resize(image.numpy(), (self.image_size, self.image_size))
# 对target中的boxes、labels进行处理,转为7*7*30的值
new_target = self.encode(boxes,labels)
# 预处理
if self.transform is not None:
for transform in self.transform:
img = transform(img)
return image,img,target,new_target
def encode(self,boxes,labels):
# S*S , class = 20 (VOC)
S_cell = 7
class_num = 20
cell_size = 1 / S_cell # 缩放因子
target = torch.zeros((S_cell,S_cell,class_num+10)) # 7*7*30
# 获取宽高和中心坐标
wh = boxes[:, 2:] - boxes[:, :2]
cxcy = (boxes[:, 2:] + boxes[:, :2]) / 2
# 遍历
# cxcy.size()[0] 表示一张图像有多少个对象
for i in range(cxcy.size()[0]):
cxcy_sample = cxcy[i] # 中心坐标 1*1
ij = (cxcy_sample / cell_size).ceil() - 1 # 左上角坐标,就是该网格左上角的坐标 (7*7)为整数
# 第一个框的置信度: 4 即30中的位置
target[int(ij[1]), int(ij[0]), 4] = 1
# 第二个框的置信度: 9 即30中的位置
target[int(ij[1]), int(ij[0]), 9] = 1
# 设置类别概率值为1: 加10是前面10个为坐标值,注意我们的类别是从1开始的
# 将真实类别的位置概率值设为1,其余位置默认为0
target[int(ij[1]), int(ij[0]), int(labels[i]) + 9] = 1
# 归一化后的图像的该网格的左上坐标 (1*1)
xy = ij * cell_size
# 计算边界框中心与左上角的偏差
delta_xy = (cxcy_sample - xy) / cell_size # 中心与左上坐标差值 (7*7)
# 坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例
target[int(ij[1]), int(ij[0]), 2:4] = wh[i] # w1,h1
target[int(ij[1]), int(ij[0]), :2] = delta_xy # x1,y1
# 每一个网格有两个边框: 这里只能复制一份
target[int(ij[1]), int(ij[0]), 7:9] = wh[i] # w2,h2
# 由此可得其实返回的中心坐标其实是相对左上角顶点的偏移,因此在进行预测的时候还需要进行解码
target[int(ij[1]), int(ij[0]), 5:7] = delta_xy # [5,7) 表示x2,y2
return target
def parse_xml(self,xml_list):
self.xml_list = []
# 解析xml文件,返回列表值
for xml_path in xml_list:
with open(xml_path) as f:
xml_str = f.read()
# 构建xml对象
xml = etree.fromstring(xml_str)
# 获取节点的内容,并转为字典值
data = self.parse_xml_to_dict(xml)["annotation"] # 获取annotation节点下的所有内容
# 添加
self.xml_list.append(data)
def parse_xml_to_dict(self, xml):
# 将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dict
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
# xml.tag节点名字
# xml.text里面的值
return {xml.tag: xml.text}
result = {}
# 对于每个xml中的子节点
for child in xml:
child_result = self.parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
def read_json(self):
# 读取类别文件,一共20个类,从1开始是因为0留给背景
json_file = '../data/VOC2012/pascal_voc_classes.json'
with open(json_file, 'r') as f:
self.class_dict = json.load(f)
# 调试用的代码
from matplotlib import pyplot as plt
import torchvision.transforms as ts
import random
from utils.draw_box import draw_objs
# 读取类别json文件
category_index = {}
try:
json_file = open('../data/VOC2012/pascal_voc_classes.json', 'r')
class_dict = json.load(json_file)
category_index = {str(v): str(k) for k, v in class_dict.items()}
except Exception as e:
print(e)
exit(-1)
# 加载
train_data_set = My_Dataset('../data/VOC2012')
for index in random.sample(range(0, len(train_data_set)), k=5):
image,img, target,_ = train_data_set[index]
# 因为修改了通道顺序,这里该回去
image = image.permute(2,0,1)
# 需要将tensor图像对象转为PIL对象
f = transforms.ToPILImage()
image = f(image)
plot_img = draw_objs(image,
target["boxes"].numpy(),
target["labels"].numpy(),
np.ones(target["labels"].shape[0]),
category_index=category_index,
box_thresh=0.5,
line_thickness=3,
font='arial.ttf',
font_size=20)
plt.imshow(plot_img)
plt.show()
6. 总结:
这里我们实现了数据加载器,后面就简单了,只需要实现CNN架构、损失函数和最后的预测函数即可。