内存
- 平时我们在电脑上听歌,聊天,或者启动某个程序,那么这个启动过程,其实就是把程序从硬盘读入到内存中去。就像安卓手机,内存不够了很卡,杀掉几个软件,内存就升上来了。但也不是所有的程序都会一次性的读入内存,为了节省内存空间和提高效率,程序是可用分段或者分页的加载,比如一个2k内存的机器读一个2m的文件。
什么是内存呢
我们知道,CPU计算很快,但是磁盘的IO实在是太慢了。解决CPU和磁盘之间速度的鸿沟,我们引入了内存。其实在CPU内部还有一部分缓存。我们先来看一下计算机的存储设备有哪些。
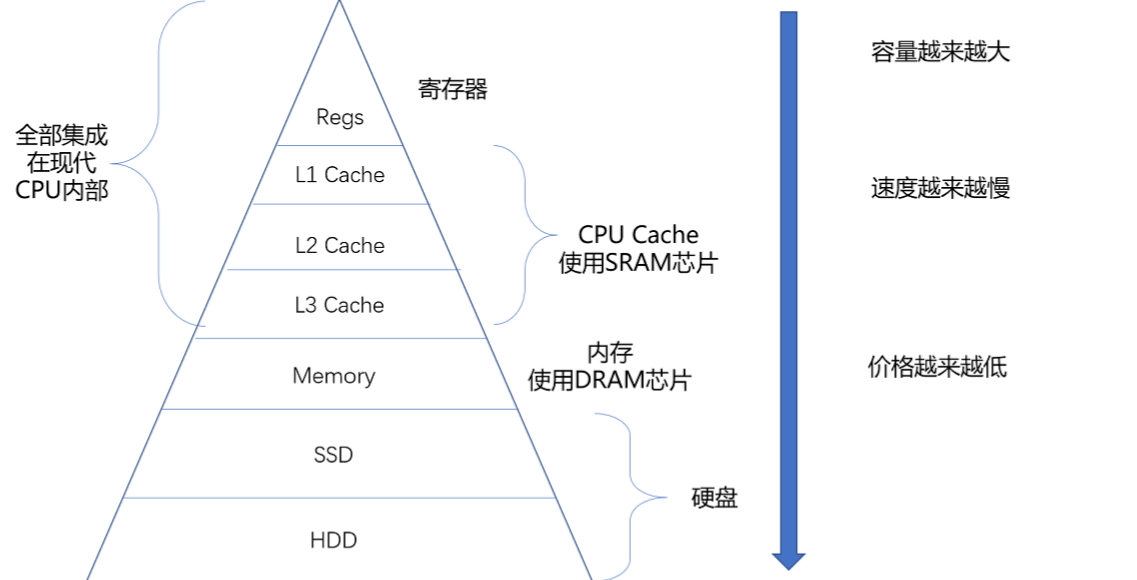
我们再量化一下这些存储设备的速度,大概是这样
- CPU : 每个指令大概需要 0.38ns,以此作为对比的基本单位 1s
- 一级缓存:读取时间大约为 0.5ns,对比 CPU 的时间大约是 1.3s
- CPU 分支预测错误: 耗时为 5ns,对比 CPU 的时间大约是 13s
- 二级缓存:读取时间大约为 7ns,对比 CPU 的时间大约是 18.2s(与一级缓存相差了一个数量级)
- 锁:互斥锁的加锁和解锁大约需要 25ns,对比 CPU 的时间大约是 65s(一分钟)。所以说,在并发编程中,锁是一个很耗时的操作
- 内存:每次内存寻址需要 100ns,对比 CPU 的时间大约是 260s(四分钟,又提升了一个数量级)。CPU 和内存之间的瓶颈被称为冯诺依曼瓶颈
- 一次 CPU 上下文切换:大约耗时为 1500ns,对比 CPU 的时间大约是 65 分钟(一个小时)。在上下文切换的时间内,CPU 没有做任何有用的计算,只是切换了两个不同进程的寄存器和内存状态。
- 在 1Gbps 的网络上传输 2k 的数据需要 20us,对比 CPU 的时间大约是 14.4 个小时(理论值,实际中可能更久),可以看到网络上非常少的数据传输对于 CPU 来说已经很漫长了
- SSD 随机读取耗时为 150us,对比 CPU 的时间为 4.5 天。SSD 的速度已经比机械硬盘快很多了,但对于 CPU 来说速度就想乌龟一样。所以应该少写 I/O 设备读取的代码,把常用的数据放到内存中作为缓存。
- 从内存中读取1MB 的连续数据,耗时大约是 250us,对比 CPU 的时间是 7.5 天
- 同一个数据中心网络上跑一个来回需要 0.5ms,对比 CPU 的时间大约是 15 天(半个月)。
- 从 SSD 读取 1MB 的顺序数据,大约学院 1ms,对比 CPU 的时间大约是一个月
- 磁盘寻址时间是 10ms,对比 CPU 的时间是 10 个月
- 从磁盘读取 1MB 的连续数据需要 20ms,对比 CPU 的时间是 20 个月。所以说IO 设备是计算机系统的瓶颈
- 从世界上不同城市的网络上走一个来回,平均需要 150ms,对比 CPU 的时间是 12.5 年。所以程序和架构都会尽量避免不同城市或者是跨国家的网络访问
- 虚拟机重启一次需要 4s 的时间,对比 CPU 的时间是三百多年,
- 物理服务器重启一次的时间是5min,对比 CPU 的时间是2万5千年
那么为什么我们不能全部用最高速的存储设备呢?因为越靠近 CPU 速度越快,容量越小,价格越贵。哈哈。
另外每一种存储器设备只和它相邻的存储设备打交道。比如,CPU Cache 是从内存里加载而来的,或者需要写回内存,并不会直接写回数据到硬盘,也不会直接从硬盘加载数据到 CPU Cache 中,而是先加载到内存,再从内存加载到 Cache 中。
- 在linux下,我们可以通过以下命令查看高速缓存的大小
# cat /sys/devices/system/cpu/cpu0/cache/index0/size
32K
# cat /sys/devices/system/cpu/cpu0/cache/index1/size
32K
# cat /sys/devices/system/cpu/cpu0/cache/index2/size
4096K
内存逃逸
- go程序中的数据和变量都会被分配到程序所在拥有的内存中。而内存中有两个重要的区域,就是栈区(Stack)和堆区(Heap)。
栈
栈区的内存一般由编译器自动进行分配和释放,其中存储着函数的入参以及局部变量,这些参数会随着函数的创建而 创建,函数的返回而消亡,一般不会在程序中长期存在,这种线性的内存分配策略有着极高地效率,但是工程师也往 往不能控制栈内存的分配,这部分工作基本都是由编译器自动完成的。
堆
一般来讲堆是人为手动进行管理,手动申请、分配、释放。一般硬件内存有多大堆内存就有多大。适合不可预知大小的内存分配,分配速度较慢,而且会形成内存碎片。C++ 等编程语言会由工程师主动申请和释放内存,Go 以及 Java 等编程语言 会由工程师和编译器共同管理,堆中的对象由内存分配器分配并由垃圾收集器回收。
什么是内存逃逸
当编译器无法保证一个变量的生命周期只在函数内部时,它就会认为这个变量逃逸了,需要在堆上分配内存。这样可以保证变量在函数返回后仍然有效,不会被栈回收。简单来说,局部变量通过堆分配和回收,就叫内存逃逸。在程序中,每个函数块都会有自己的内存区域用来存自己的局部变量(内存占用少)、返回地址、返回值之类的数据,这一块内存区域有特定的结构和寻址方式,寻址起来十分迅速,开销很少。这一块内存地址称为栈。栈是线程级别的,大小在创建的时候已经确定,当变量太大的时候,会"逃逸"到堆上,这种现象称为内存逃逸。
内存逃逸的影响
通过前面讲解的堆栈,我们知道堆分配昂贵,栈分配廉价,在go中所有内存优先栈分配。而堆是一块没有特定结构,也没有固定大小的内存区域,可以根据需要进行调整。全局变量,内存占用较大的局部变量,函数调用结束后不能立刻回收的局部变量都会存在堆里面。变量在堆上的分配和回收都比在栈上开销大的多。对于 go 这种带 GC 的语言来说,会增加 gc 压力,同时也容易造成内存碎片。
go中内存逃逸的现象举例
- 局部变量x在函数结束后还被其他地方调用
func Foo()func(){
x:=5
return func(){
x+=1
}
}
func main(){
foo:=Foo()
foo()
}
我们使用go build -gcflags '-m -l' main.go 来查看内存逃逸的情况,
- -m 会打印出逃逸分析的优化策略,实际上最多总共可以用 4 个 -m,但是信息量较大,一般用 1 个就可以了
- -l 会禁用函数内联,在这里禁用掉 inline 能更好的观察逃逸情况,减少干扰。
或者通过反编译命令go tool compile -S main.go 更底层,更硬核,更准确的方式来判断一个对象是否逃逸
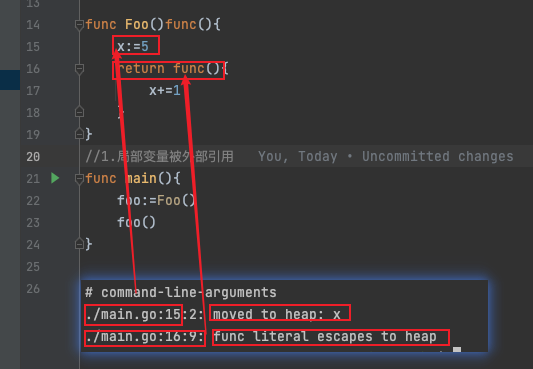
其中move to heap 是在代码生成阶段发生的,它是编译器根据逃逸分析的结果,为变量生成在堆上分配内存的代码。escapes to heap 是在逃逸分析阶段发生的,它是编译器判断一个变量是否需要在堆上分配内存的过程。
- 像下面这种指针类型的值,都会被存储到堆上面,因为是指针类型,编译器不知道在函数运行结束后,外部还是否会用到它,所以不能对它进行回收,它就会认为这个变量逃逸了,就会在堆上分配内存。这样可以保证变量在函数返回后仍然有效,不会被栈回收。
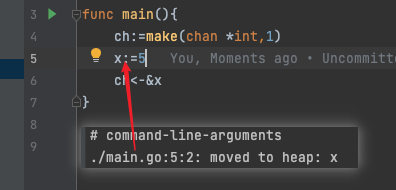
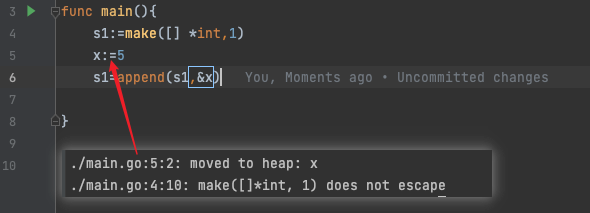
同理,下面这种也是内存逃逸,因为切片s1指向的是底层数组,没有发生逃逸,切片里面元素x发生了逃逸
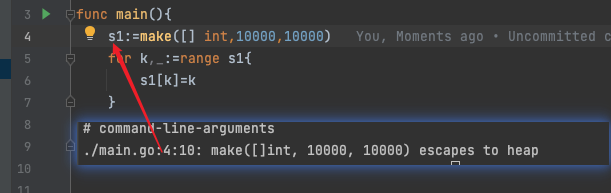
- 还有一种情况,就是数据量太大,栈放不下了。也会发生逃逸,比如下面这个切片,大小是10000 * 8 = 80000字节 = 80KB,而切片的预估容量是64k,所以发生内存逃逸。当然,在32位操作系统中,超过32k就会发生内存逃逸。
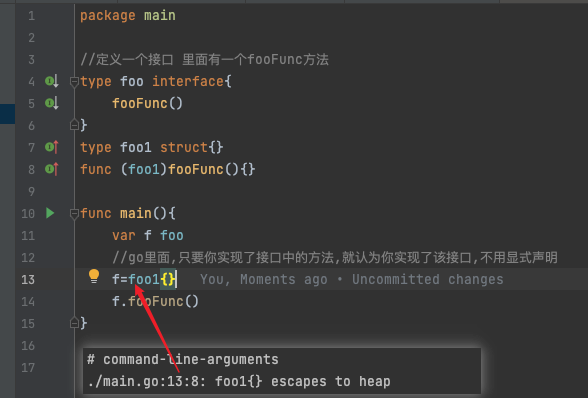
- 还有像 interface 类型上调用方法,接口在编译的时候不知道foofunc怎么实现的。只有运行的时候才知道,所以interface变量使用堆分配。
如何避免内存逃逸
- 尽量减少外部指针引用,必要的时候可以使用值传递;
- 对于自己定义的数据大小,有一个基本的预判,尽量不要出现栈空间溢出的情况;
- Golang中的接口类型的方法调用是动态调度,如果对于性能要求比较高且访问频次比较高的函数调用,应该尽量避免使用接口类型;
- 尽量不要写闭包函数,可读性差且发生逃逸。
总结
- 逃逸分析在编译阶段确定哪些变量可以分配在栈中,哪些变量分配在堆上
- 逃逸分析减轻了GC压力,提高程序的运行速度
- 栈上内存使用完毕不需要GC处理,堆上内存使用完毕会交给GC处理
- 函数传参时对于需要修改原对象值,或占用内存比较大的结构体,选择传指针。对于只读的占用内存较小的结构体,直接传值能够获得更好的性能
- 根据代码具体分析,尽量减少逃逸代码,减轻GC压力,提高性能