到目前为止,我们还没有花太多的精力来研究将HTML转换为PDF时使用的字体。我们知道Helvetica是iText在没有指定字体时使用的默认字体(第2章),我们知道如果需要嵌入字体,pdfHTML会附带一些内置字体(第4章),但我们还没有得到支持哪些字体的清晰概述。
在阅读本章之前,您需要了解两件事:
- “iText core”库支持Type1字体(
.AAFM/.PFB)、旧的TrueType字体(.TTF)、具有Type1轮廓的OpenType字体(.otf)、具有TrueType轮廓的OpenType字体(.TTF)和TrueType集合(.ttc),以及Web开放字体格式(.woff)。 - pdfHTML插件使用
DefaultFontProvider,默认情况下,它只支持14种标准Type 1字体和内置于pdfHTML中的12种字体。您可以配置字体提供程序以支持更多字体。
在本章中,我们将查看一些使用pdfHTML中提供的默认字体的示例,并将解锁对核心库支持的所有其他类型字体的访问。
1. 标准Type 1字体
ISO 32000(第1部分和第2部分)第9.6.2.2节列出了标准Type 1类字体(也称为14种标准字体)。
Section 9.6.2.2: Standard Type 1 Fonts (Standard 14 Fonts)
14种Type 1字体(称为14种标准字体)的PostScript名称如下:Times Roman、Helvetica、Courier、Symbol、Times Bold、Helvedica Bold、Courier Bold、ZapfDingbats、Times Italic、Helvetina Oblique、Courier Oblique,Times BoldItalic、Hervetica BoldOblique和Courier BoldObrique。
这些字体或其字体度量(font metrics)和合适的替代字体应可供大家使用。
在创建PDF文档时不必嵌入这些字体,因为每个PDF查看器都知道如何呈现这十四种字体。iText附带了与这些标准14字体对应的14个Adobe Font Metrics(AFM)文件,这意味着始终支持这些字体。但是,由于相应的打印机字体二进制文件(Printer Font Binaries,PFB)是专有的,iText永远不会嵌入这些字体。
fonts_standardtype1.html文件列出了14种字体:4种Helvetica字体、4种Times字体、4种Courier字体、Symbol和ZapfDingbats字体。从图6.1中可以看出,浏览器正确渲染了Helvetica、Times和Courier。

Symbol和ZapfDingbats是具有自定义编码的字体。他们不能很好地在HTML中展示。在常见问题解答FAQ中,我们将发现还有其他字体更适合符号,例如Symbol和ZapfDingbats中提供的字体。目前,我们z只能展示Symbol字体的数字(0123456789)和ZapfDingbats字体的不间断空格字符( )。
下面代码中,我们使用在之前篇章中简单的createPdf()/CreatePdf():
public void createPdf(String src, String dest) throws IOException {
HtmlConverter.convertToPdf(new File(src), new File(dest));
}
当我们查看图6.2所示的文档属性中的字体选项卡时,我们看到PDF文档中使用了所有14种字体。

这些字体都没有嵌入,因为iText只提供字体度量,而不提供字体二进制文件。字体由本地计算机上可用的字体替换。在这种情况下,Courier被CourierStd取代,Helvetica被ArialMT取代,Times Roman被TimesNewRomanPSMT取代。
不同操作系统上的不同PDF查看器可能会使用其他字体作为“Actual Fon”。例如,当您想要创建PDF/A文档时,这可能会有问题。为了解决这个问题,pdfHTML插件附带了12种免费字体。
2. iText附带的字体
pdfHTML插件支持三种字体家族的字体嵌入:san、serif和monospaced家族。对于每个font-family,有四种字体可用:常规字体、粗体字体、斜体(或倾斜)字体和粗体斜体(或粗体倾斜)字体。
在fonts_shipped.html文件中,我们使用font-family:FreeSans、font-family:FreeSerif和font-family:Free Mono。我们也可以使用font-family:sans、font-family:serif和font-family:mono;这将导致同样的结果。我们使用字体weight:bold和字体style:italic的不同组合,以便显示每个font-family的四种字体。
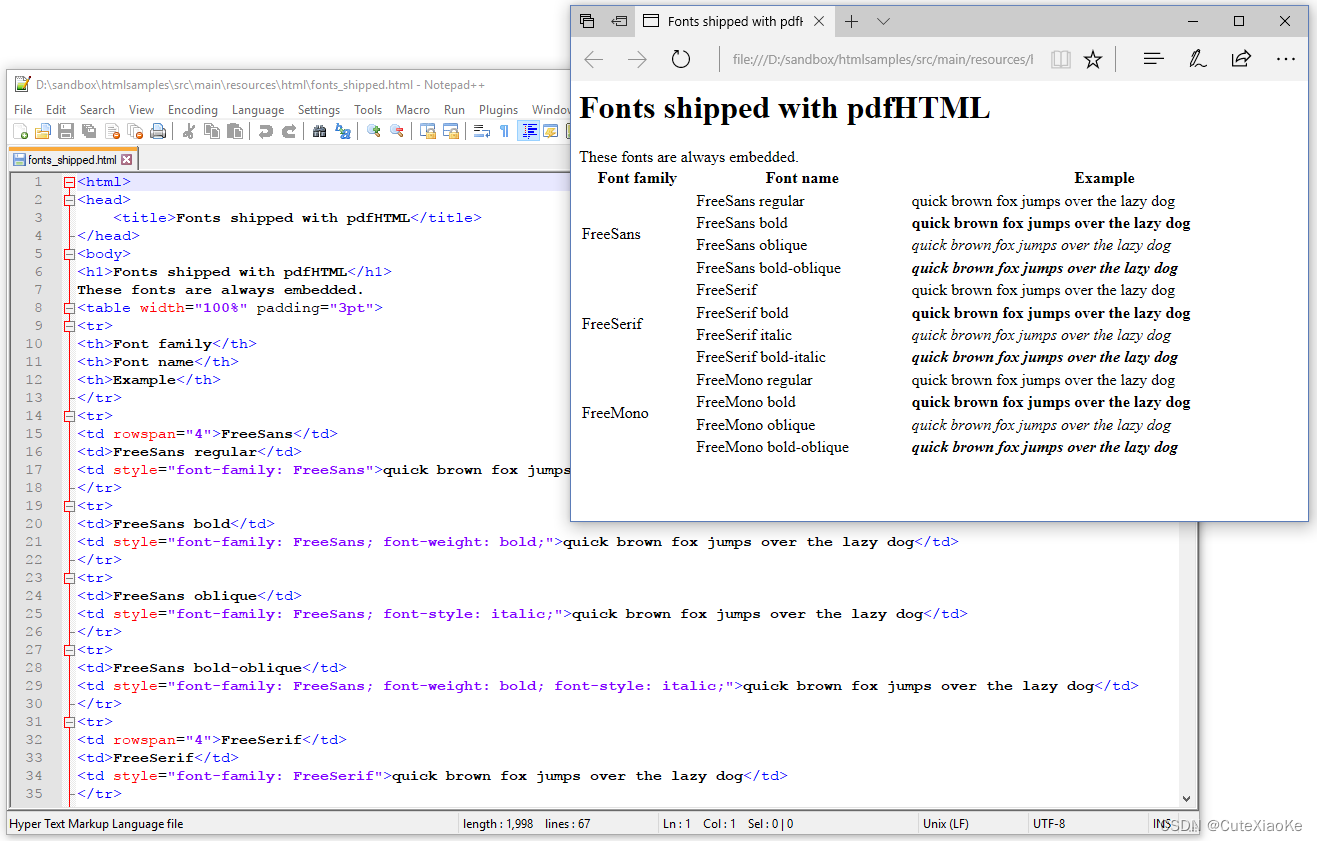
用来呈现这个HTML页面的浏览器不知道在哪里可以找到sans和monospaced字体;如上图图6.3。
这很遗憾,但创建的相应PDF看起来不错。

查看图6.4中文档属性的字体面板,我们发现十二种字体中的每一种都有一个子集被嵌入,而Helvetica和HelveticaBold则完全没有嵌入。
如果不更改字体提供程序,这26种字体(其中只有24种在HTML上下文中真正有用)是默认情况下支持的唯一字体。
这是非常有限的,所以让我们来看看如何添加对更多字体的支持。例如:如果我们能够访问我们正在使用的操作系统提供的所有系统字体,这不是很好吗?
3. 系统字体
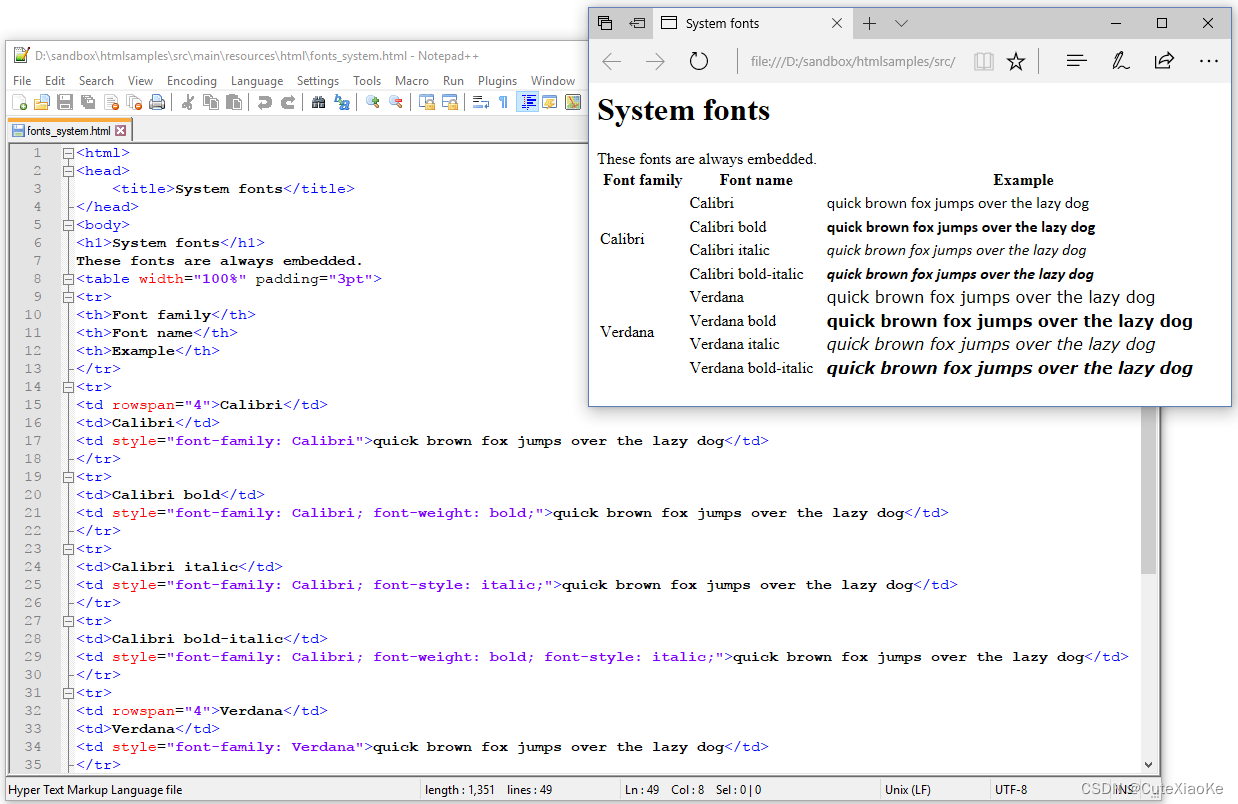
在fonts_system.html文件,我们引入了诸如Calibri和Verdana等字体系列。在Windows计算机上编写本教程,浏览器可以正确呈现不同的Calibri和Verdana字体(参见图6.5),因为C:\Windows\fonts目录中提供了相应的字体程序。
默认情况下,pdfHTML使用如下创建的DefaultFontProvider实例:
FontProvider provider = new DefaultFontProvider();
此构造函数调用另一个以三个布尔值作为参数的构造函数。上述行相当于:
FontProvider provider = new DefaultFontProvider(true, true, false);
该构造函数的每个布尔值都会导致注册特定类型的字体:
registerStandardPdfFonts–将注册十四种标准Type 1字体,registerShippedFreeFonts–将注册十二种iText自带的字体,registerSystemFonts–将注册系统字体。
registerStandardPdfFonts和registerShippedFreeFonts的默认值为true,因为这些字体几乎不需要任何资源。
registerSystemFonts的默认值为false,因为当您将此值设置为true时,iText将搜索操作系统上包含系统字体的目录。这有一些缺点:
- 加载和选择字体可能耗时,并且
- 如果我们注册完整的目录,我们无法控制字体的添加顺序,
- 如果你偶然碰到了带有嵌入限制的字体,那你就倒霉了。
但现在我们不必担心,我们还是更改字体提供程序以支持系统字体。下面示例中将所有布尔值设置为true,然后看看会发生什么。
public void createPdf(String src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setFontProvider(new DefaultFontProvider(true, true, true));
HtmlConverter.convertToPdf(new File(src), new File(dest), properties);
}
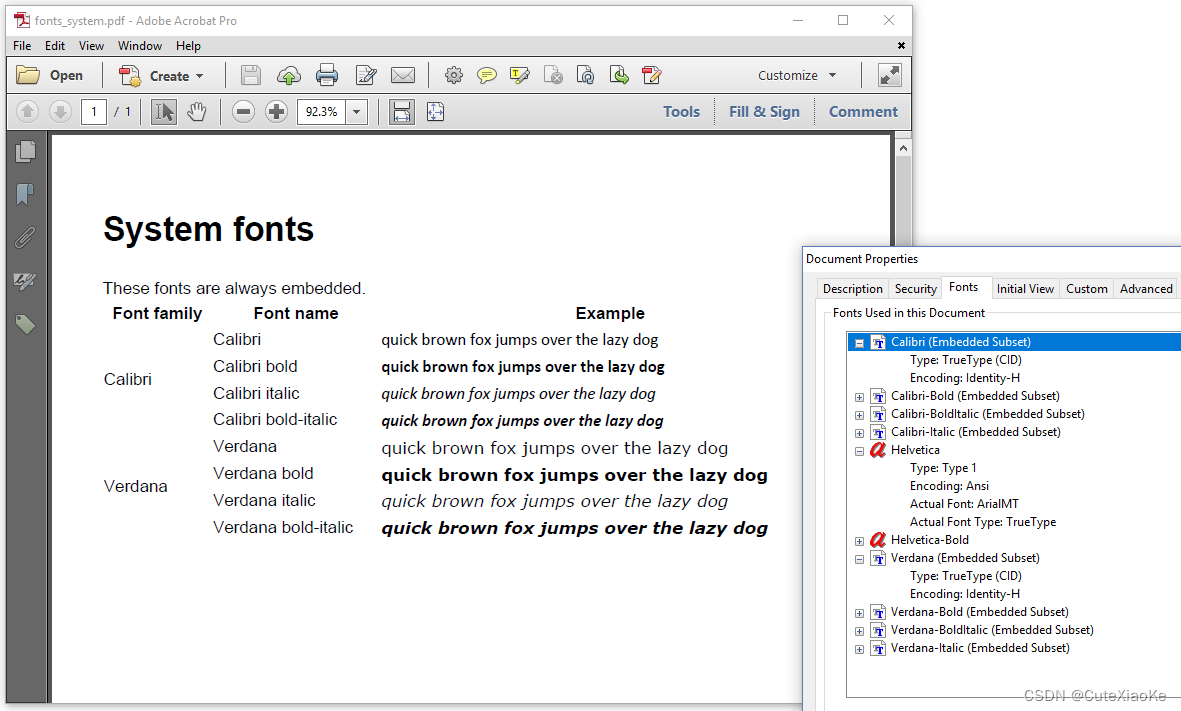
现在我们已经更改了ConverterProperties,我们几乎可以使用C:\Windows\Fonts中的任何字体。其中包括Calibri和Verdana系列的字体。这些字体的子集现在嵌入到PDF中,如图6.6所示。
如果您正在另一个操作系统上工作,例如Linux,没有C:\Windows\Fonts目录,但这不是问题。
iText尝试使用环境变量获取字体目录,并在此基础上搜索以下目录:
/usr/share/X11/fonts,/usr/X/lib/X11/fonts,/usr/openwin/lib/X11/fonts,/usr/share/fonts,/usr/X11R6/lib/X11/fonts,/Library/Fonts,以及/System/Library/Fonts。
小心使用此系统字体功能。通常,让pdfHTML访问所有系统字体不是最好的选择。让我们看看一些替代方案。
4. web开放字体格式(Web Open Font Format fonts)
Web开放字体格式是一种用于网页的字体格式。WOFF字体本质上是具有压缩和附加元数据的OpenType或TrueType字体。
在fonts_woff.html文件,您可以看到我们如何定义SourceSerifPro字体系列的六种字体。
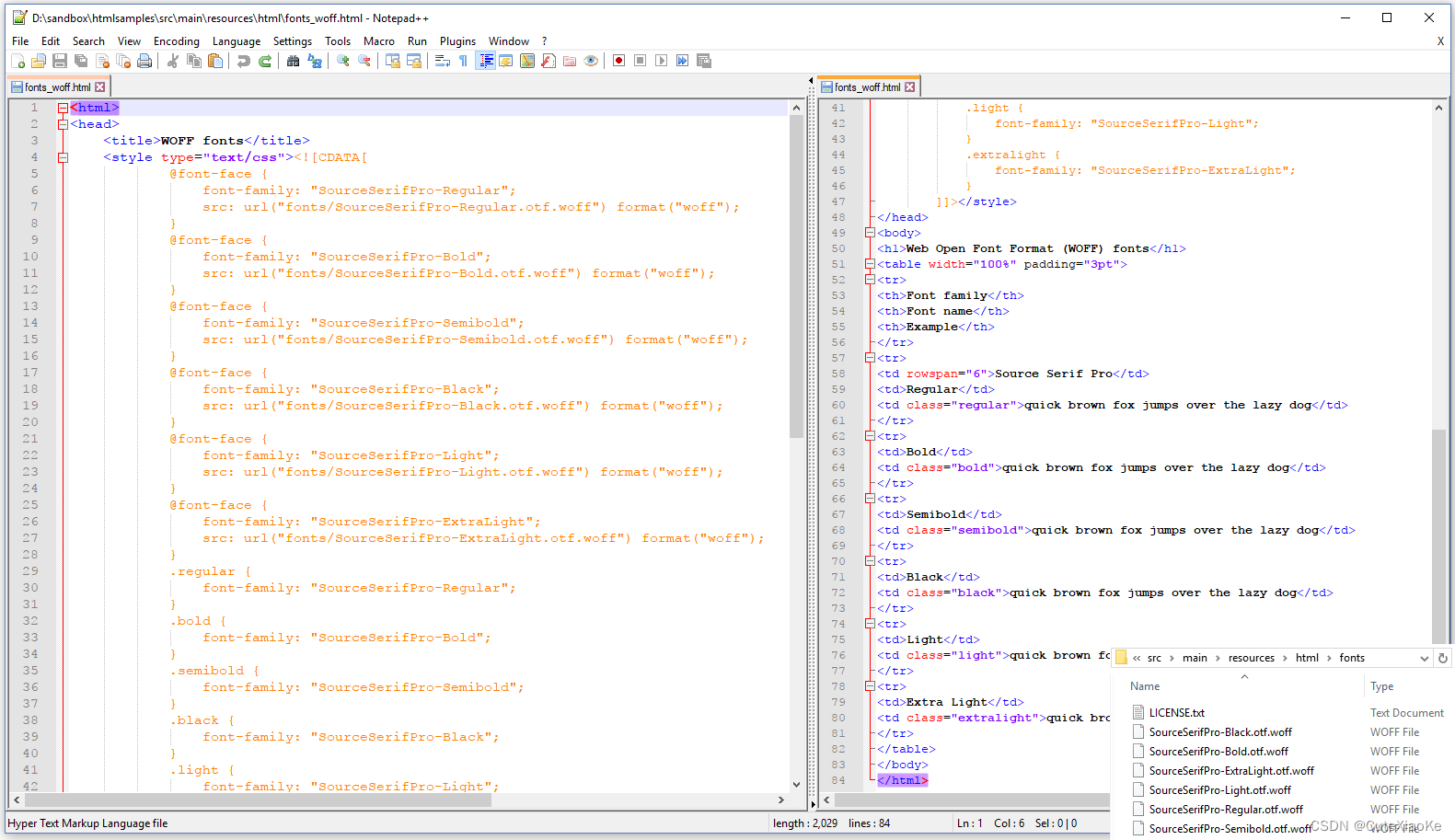
首先,我们定义@font-face,例如:
@font-face {
font-family: "SourceSerifPro-Regular";
src: url("fonts/SourceSerifPro-Regular.otf.woff") format("woff");
}
然后定义一个类选择器中使用字体,例如:
.regular {
font-family: "SourceSerifPro-Regular";
}
最终,我们在HTML中使用类选择器:
<td class="regular">quick brown fox jumps over the lazy dog</td>
这个例子我们不会改变ConverterProperties:
public void createPdf(String src, String dest) throws IOException {
HtmlConverter.convertToPdf(new File(src), new File(dest));
}
pdfHTML插件将自动下载WOFF字体(如图6.7右下角所示),并将这些字体的子集嵌入PDF中,如图6.8所示。
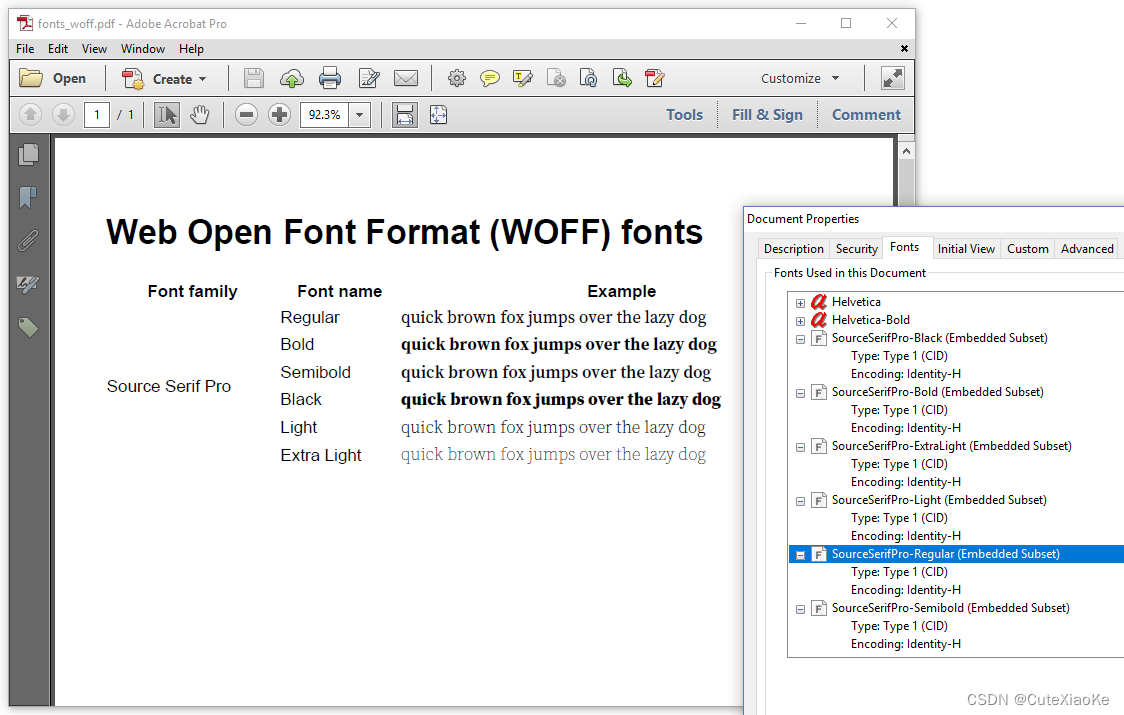
如果您想将在互联网上网页转换为PDF,则特别欢迎对WOFF字体的支持,但请考虑到使用此方法时,HTML到PDF的转换过程可能会缓慢。字体是通过网络下载的,这通常会降低速度。
最快的选项是将所选字体添加到字体提供程序。
5. 添加所选字体到字体提供程序
在fonts_extra.html中,我们将语句"quick brown fox jumps over the lazy dog"写了3次:
- 一次为字体家族Cardo的常规字体,
- 一次为字体家族Cardo的加粗字体,但如果在任何情况下都找不到Cardo粗体,则将使用Times字体,
- 一次为字体家族Cardo的倾斜字体,但如果在任何情况下都找不到Cardo斜体,则将使用Times字体。
如图6.9所示:

在代码里面我调整了字体提供程序:
public static final String FONT = "src/main/resources/fonts/cardo/Cardo-Regular.ttf";
public void createPdf(String src, String font, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
FontProvider fontProvider = new DefaultFontProvider();
FontProgram fontProgram = FontProgramFactory.createFont(FONT);
fontProvider.addFont(fontProgram);
properties.setFontProvider(fontProvider);
HtmlConverter.convertToPdf(new File(src), new File(dest), properties);
}
我们将执行以下步骤:
- 我们创建一个
DefaultFontProvider实例。 - 通过传递指向字体程序Cardo-Regular.ttf路径给
FontProgramFactory来创建一个FontProgram。 - 添加这个字体程序到字体提供程序,并且把这个字体提供程序设置成一个转换属性。
通过这种方式,我们将一种选定的字体添加到字体提供程序中。因此,我们定义了常规字体的语句“quick brown fox jumps over the lazy dog”将使用Carbo-Regular字体呈现。由于我们没有提供Carbo系列的任何粗体或斜体字体,因此其他两行使用Type 1型字体Roman-Bold和Roman-Italic。
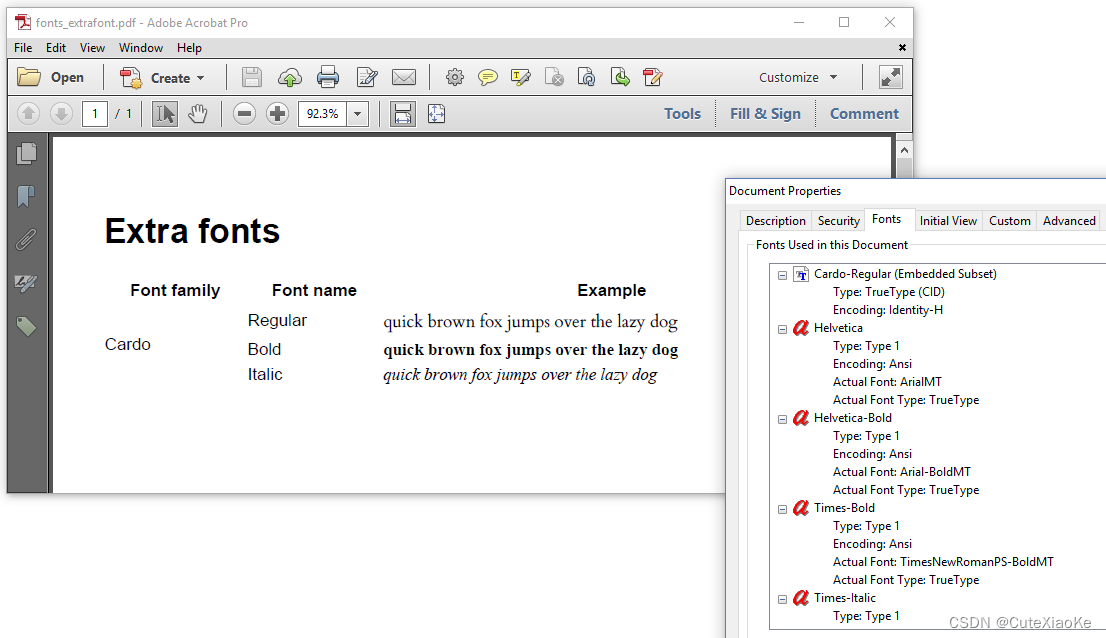
让我们修复它,下面的例子中,我们不使用addFont()/AddFont()方法一次添加一个字体。相反,我们使用addDirectory()/AddDirectory()方法一次性添加三种Carbo字体:
public static final String FONTS = "src/main/resources/fonts/cardo/";
public void createPdf(String src, String fonts, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
FontProvider fontProvider = new DefaultFontProvider();
fontProvider.addDirectory(FONTS);
properties.setFontProvider(fontProvider);
HtmlConverter.convertToPdf(new File(src), new File(dest), properties);
}
Cardo目录下面同时包含了字体家族Cardo的粗体和斜体,iText不再依赖于Times字体系列。如图6.11。
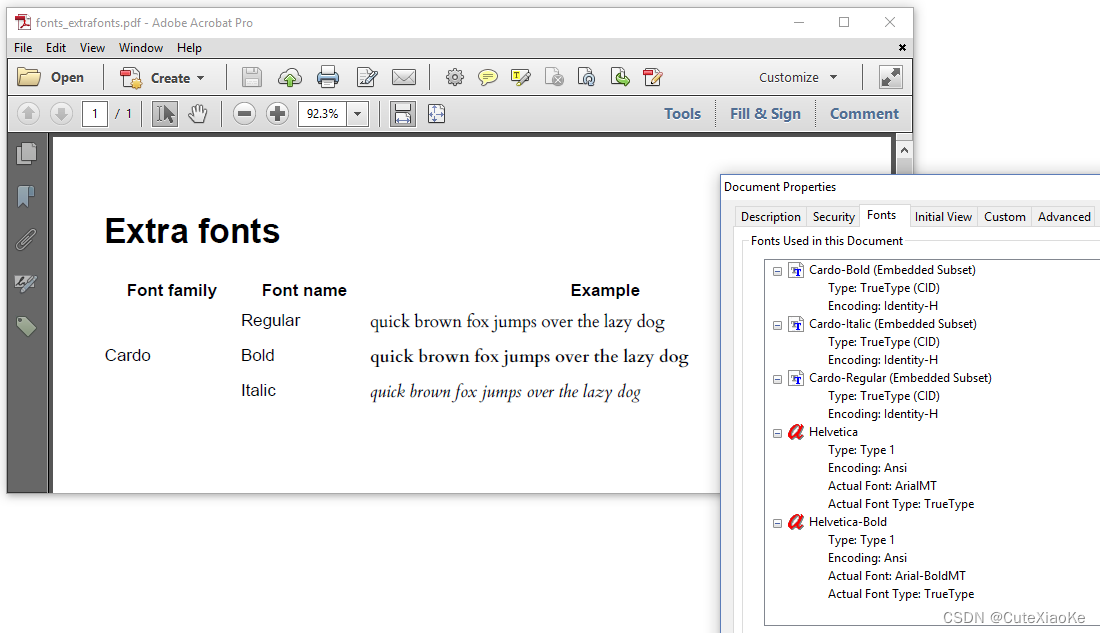
添加包含大量字体的目录时要小心。字体添加到字体提供程序的顺序很重要、
6. 选择正确的字体顺序
当我们谈到使用系统字体时,我们提到,如果我们注册了完整的目录,就无法控制字体的添加顺序。我们将使用简单的hello.htmk文件了解为什么这是一个缺点。见图6.12。
我们将使用相同的createPdf()/CreatePdf()方法将这个简单的HTML文件转换为PDF两次,但我们将创建一个DefaultFontProvider实例,该实例不注册任何标准Type 1字体,不注册任何内置字体,也不注册任何系统字体。这将排除使用Helvetica、FreeSans或任何其他字体作为默认字体。
我们将添加一组字体,这些字体的路径存储在名为fonts的String数组中;pdfHTML必须使用其中一种字体作为默认字体。代码如下:
public void createPdf(String src, String[] fonts, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
FontProvider fontProvider = new DefaultFontProvider(false, false, false);
for (String font : fonts) {
FontProgram fontProgram = FontProgramFactory.createFont(font);
fontProvider.addFont(fontProgram);
}
properties.setFontProvider(fontProvider);
HtmlConverter.convertToPdf(new File(src), new File(dest), properties);
}
我们将在两个例子C06E07_ExtraFontsOrder1.java和C06E08_ExtraFontsOrder2.java中使用相同的字体: NotoSans-Regular.ttf 和Cardo-Regular.ttf,但是两个例子生产的PDF会不一样。
第一个例子C06E07_ExtraFontsOrder1.java中,创建的顺序为:
public static final String[] FONTS = {
"src/main/resources/fonts/noto/NotoSans-Regular.ttf",
"src/main/resources/fonts/cardo/Cardo-Regular.ttf"
};
Noto字体是数组中的第一个元素,它包含将HTML文件呈现为PDF所需的所有字形,因此不需要Cardo字体。见图6.13:
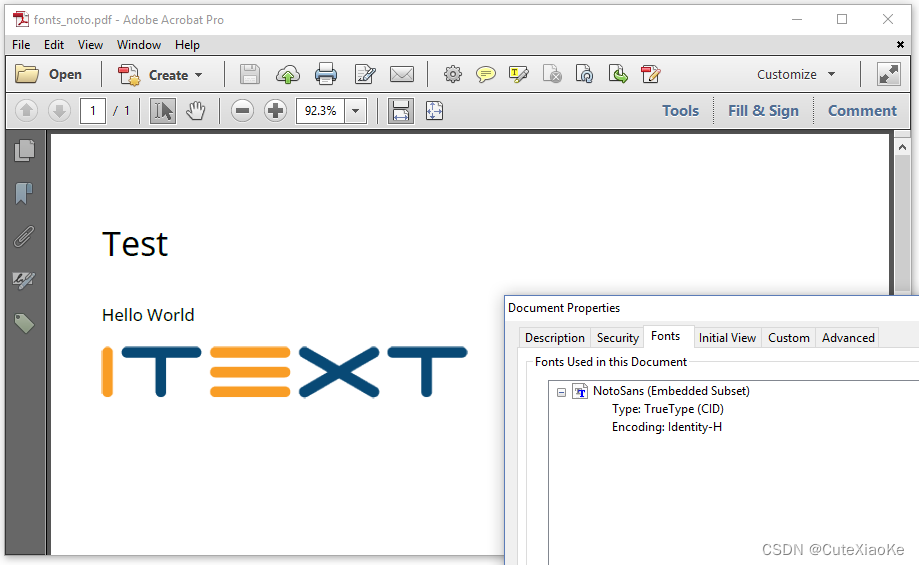
第二个例子C06E08_ExtraFontsOrder2.java中,我们把顺序颠倒:
public static final String[] FONTS = {
"src/main/resources/fonts/noto/Cardo-Regular.ttf",
"src/main/resources/fonts/cardo/NotoSans-Regular.ttf"
};
现在Carbo字体是数组中的第一个元素,它还包含将HTML文件呈现为PDF所需的所有字形,因此不需要Noto字体。见图6.14:
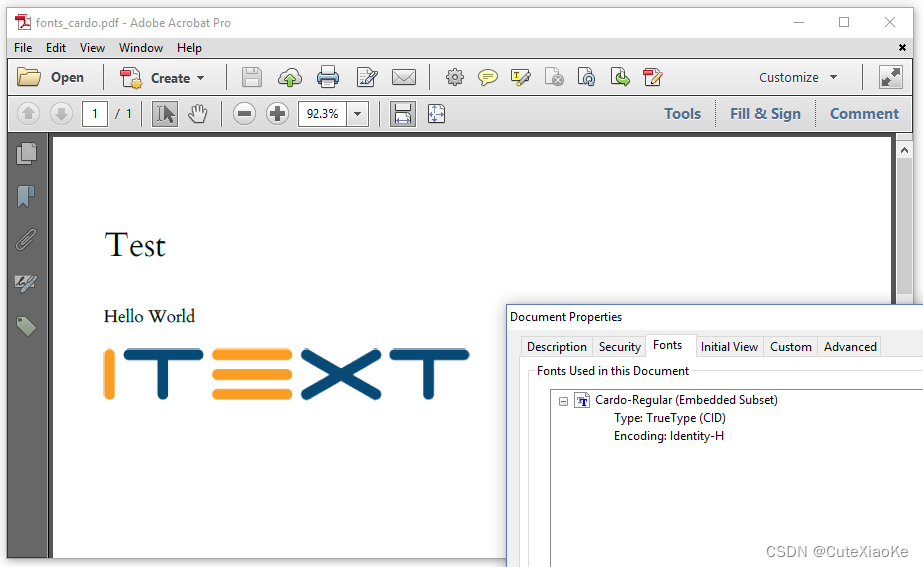
这两个例子解释了pdfHTML内部工作的一个重要方面。当pdfHTML需要将字符呈现为字形时,它将首先在HTML中搜索字体名称,并询问字体提供商是否有该名称可用的字体。如果找不到字体,或者没有提供字体名称,则pdfHTML将按照注册的顺序对注册到字体提供商的不同字体进行循环。一旦pdfHTML找到可以将字符呈现为字形的字体,它将使用该字体。
当注册一个完整的目录时,例如通过包含所有系统字体,您无法控制不同字体程序添加到字体提供程序的顺序。这使得很难预测pdfHTML将使用哪种字体。如果您编写的应用程序可以迁移到不同的系统,这尤其有问题。不同的系统可能有不同的系统字体,这可能会导致PDF文档看起来完全不同,因为使用了不同的字体。字体目录中包含嵌入限制的字体也存在风险。当pdfHTML遇到这样的字体时,将引发异常。
字体有一个重要的方面,到目前为止我们没有花任何精力去关注。当我们使用字体时,我们将HTML文件中的字符映射到PDF文档中的字形。a字符可以映射到字母a的不同可视化,例如’a’、‘a’或’a’,甚至’α’或“@”或任何其他字形,具体取决于所使用的编码。
有关字体和编码的更多信息,请参阅iText7高级教程之构建基础块——1.引入字体。
7. 选择合适的编码
使用标准Type 1字体时,iText使用Helvetica、Times和Courier字体系列的Winansi编码。Symbol和ZapfDingbats字体有自己的自定义编码。
在Winansi编码的情况下,iText创建一个简单的字体(simple font)。简单字体最多可将256个字符映射到256个字形,这意味着每个字符只能包含一个字节。如果您希望在一种字体中支持256个以上的字符,则需要使用复合字体。例如:如果使用Identity-H编码,则字符将存储为Unicode字符。
使用Unicode,或者至少提供到Unicode的映射(toUnicode mapping),被认为是PDF中的最佳实践。这是PDF/A level U的要求,也是可读性方面的要求,因为Unicode映射允许检索文件中引用的每个字符的语义属性。
pdfHTML插件将尽可能使用Unicode。这解释了为什么许多示例在屏幕截图中显示Identity-H编码,但使用标准Type 1字体的情况除外。标准Type 1字体不支持Unicode,因此改用Winansi。
如果您不同意iText选择的默认编码,可以定义自己的编码。例如,请见下面代码示例中,我们使用Carbo-Regular,就像我们在上一个示例中所做的那样,但是我们没有让iText选择编码,而是明确告诉iText使用Winansi:
public static final String FONT = "src/main/resources/fonts/cardo/Cardo-Regular.ttf";
public void createPdf(String src, String font, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
FontProvider fontProvider = new DefaultFontProvider(false, false, false);
FontProgram fontProgram = FontProgramFactory.createFont(FONT);
fontProvider.addFont(fontProgram, "Winansi");
properties.setFontProvider(fontProvider);
HtmlConverter.convertToPdf(new File(src), new File(dest), properties);
}
当我们将图6.15中文档属性的字体面板与图6.14中的字体面板进行比较时,我们现在看到的编码是“Ansi”而不是“Identity-H”。

这种从复合字体到简单字体的变化也会影响文件大小。
- 使用(Win)Ansi编码,每个字符存储为单个字节;
- 使用Identity-H编码,每个字符都存储为两个字节。
图6.16显示了fonts_cardo.pdf文件(Identity-H编码)和fonts_encoding.pdf文件(Ansi编码)的大小差异。

文件大小的差异是有限的,因为包含单字节或双字节字符的内容流都是压缩的。
如果文件大小有问题,可以考虑使用Winansi编码而不是Identity-H,但要注意这是有代价的。如果希望您你文件符合当前和未来的长期保存或可读性标准,最好创建文件大小稍大但使用Unicode的文件。
如果要创建包含不同语言内容的文档,也可以使用Unicode。
8. 国际化
fonts_i18n.html文件包含一个表,第一列是电影的英文标题,第二列是同一部电影的不同语言的标题。

我们使用UTF-8编码存储了此文件,并且在HTML标头中明确指出,此HTML文件中的所有字符都应视为UTF-8字符:
<meta charset="UTF-8">
如果省略这一行,则会出现一个典型的编码问题,如图6.18所示。
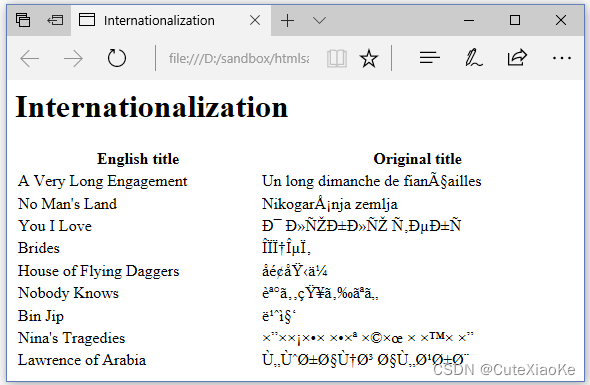
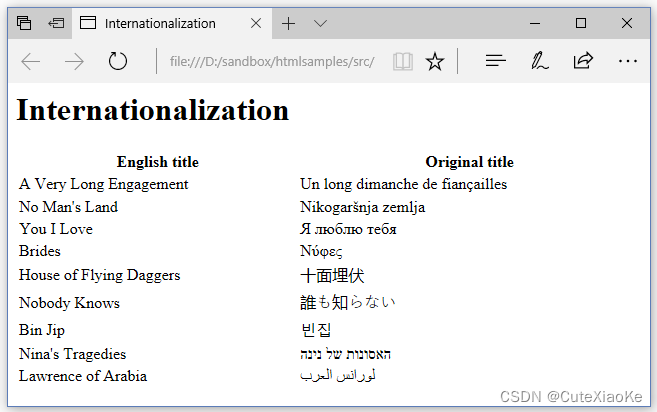
这绝对不是我们想要的。如果你像读取普通ASCII文件一样读取UTF-8文件,您可以在iText中获得类似的胡言乱语。如果使用正确的编码,您将看到如图6.19所示的页面。
首先我们看看错误的代码示例,我简单的createPdf()/CreatePdf()方法是不够的。
public void createPdf(String src, String dest) throws IOException {
HtmlConverter.convertToPdf(new File(src), new File(dest));
}
在这个错误案例中主要有2大类陷阱,我们通过图6.20和图6.21展示这些问题。
当我们查看图6.20中的希伯来语(Hebrew )和阿拉伯语(Arabic)文本时,我们看到字符被呈现为字形,但它们的呈现顺序错误。希伯来语和阿拉伯语是从右到左书写的,需要额外的处理来检测和应用正确的书写系统。
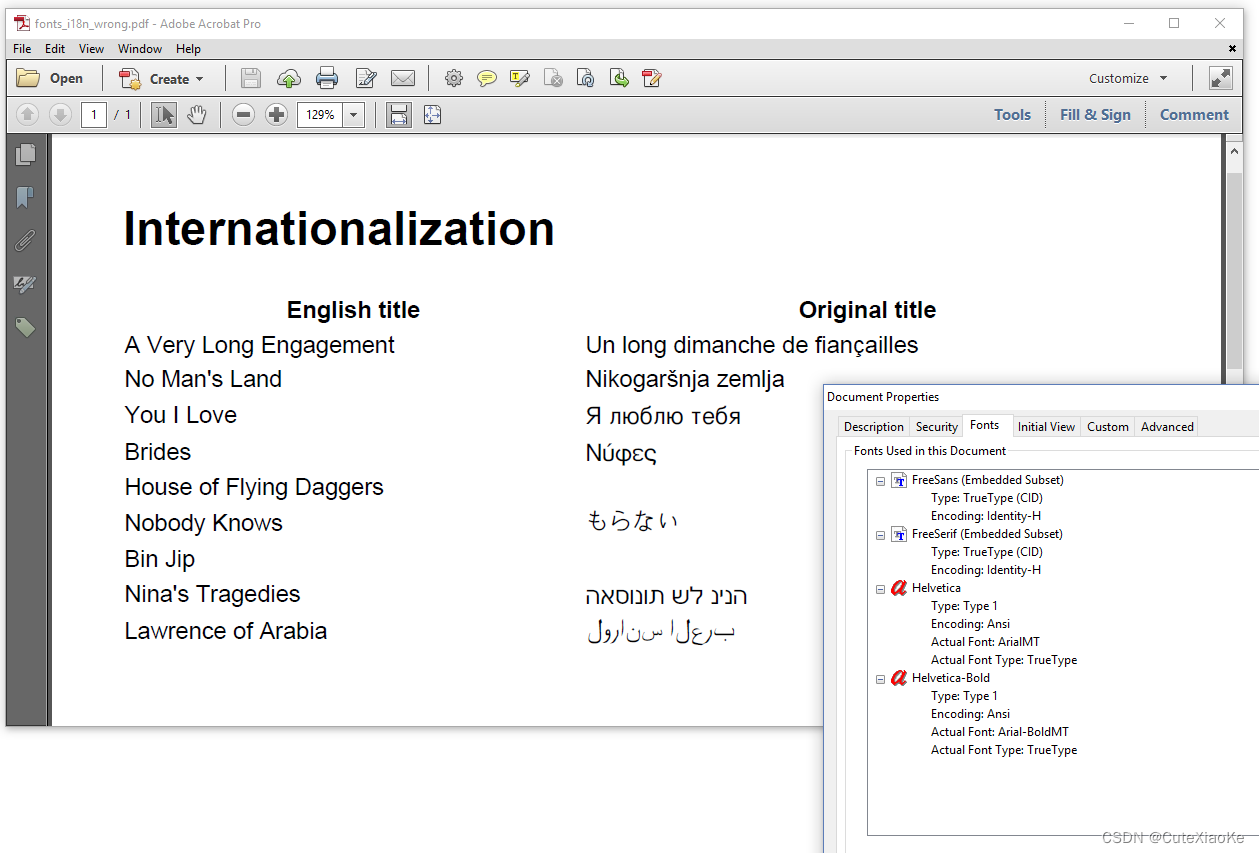
在“特殊”的书写系统中添加内容需要更多的CPU,出于性能的原因,iText默认情况下不使用该CPU。如果要转换希伯来语、阿拉伯语或印度语(印地语、卡纳达语、泰米尔语、泰卢固语…)内容,则需要在CLASSPATH中明确包含pdfCalligraph插件。这将激活特殊的排版功能。
一旦安装了pdfCalligraph,希伯来文文本看起来已经更好了,但结果仍然存在一些严重问题,如图6.21所示。
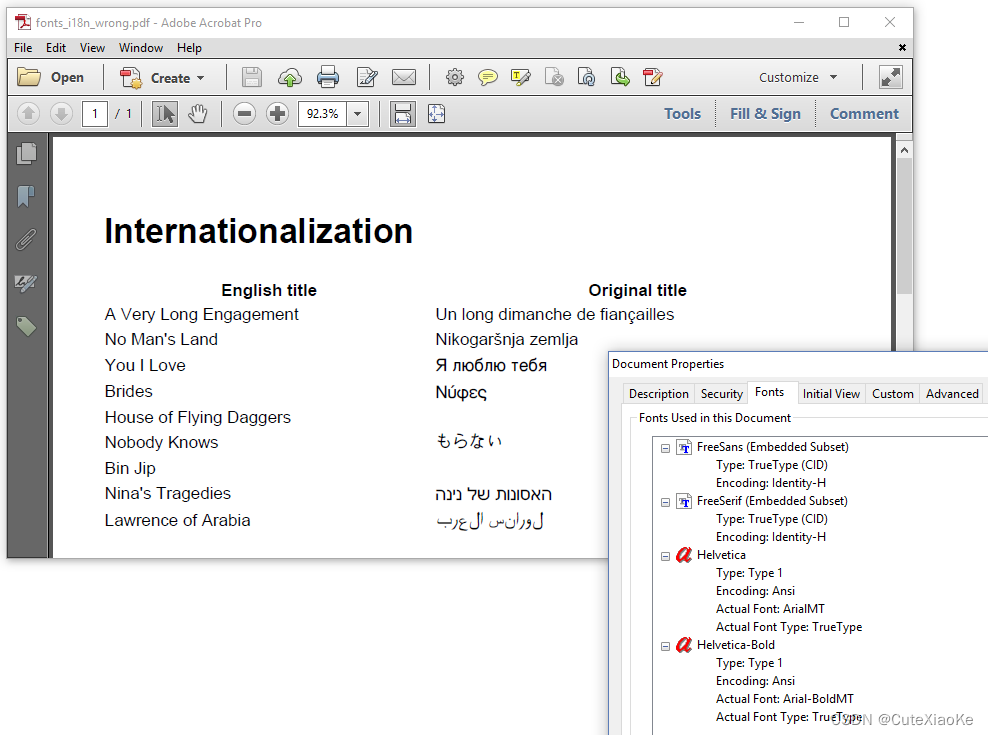
中文和韩语标题仍然缺失,日语标题中的几个字符也是如此。阿拉伯字符在那里,现在它们的顺序是正确的,但它们都是错误的,因为没有做连字。当您使用pdfCalligraph时,可以开箱即用地支持连字,但此插件使用存储在字体内部的信息来创建连字。不幸的是,内置字体不支持阿拉伯文连字。
我们可以通过引入支持中文(如NotoSansCJKsc-Regular)、日语(如NotoSansCJKjp-Regular),韩语(如NotoSansCJKkr-Regular)、希伯来语(如NotoSansHebrew-Regular)和阿拉伯语(如NotoNaskhArabic-Regular)的字体来解决所有这些问题。你可以在包含Noto Sans常规字体的目录中找到所有这些字体。
实现的代码如下:
public static final String[] FONTS = {
"src/main/resources/fonts/noto/NotoSans-Regular.ttf",
"src/main/resources/fonts/noto/NotoSans-Bold.ttf",
"src/main/resources/fonts/noto/NotoSansCJKsc-Regular.otf",
"src/main/resources/fonts/noto/NotoSansCJKjp-Regular.otf",
"src/main/resources/fonts/noto/NotoSansCJKkr-Regular.otf",
"src/main/resources/fonts/noto/NotoNaskhArabic-Regular.ttf",
"src/main/resources/fonts/noto/NotoSansHebrew-Regular.ttf"
};
public void createPdf(String src, String[] fonts, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
FontProvider fontProvider = new DefaultFontProvider(false, false, false);
for (String font : FONTS) {
FontProgram fontProgram = FontProgramFactory.createFont(font);
fontProvider.addFont(fontProgram);
}
properties.setFontProvider(fontProvider);
HtmlConverter.convertToPdf(new File(src), new File(dest), properties);
}
现在,我们可以比较图6.22中使用pdfCalligraph创建的PDF的屏幕截图和图6.19中在浏览器中呈现的HTML页面。

注意,我们明确排除了标准Type 1字体、内置字体和系统字体。我们完全优先考虑了Noto字体(google开源项目字体)。当然,我们没有使用与浏览器使用的字体完全相同的字体,但至少所有的字符都在那里,并且连字正确。如果我们想要更好的匹配,我们需要搜索浏览器使用的字体,并将相应字体程序的路径添加到字体提供程序。
实际上,官方提供的源码里面没有引入pdfCalligraph插件,因为这个插件是闭源的,书写顺序一致是从左到右,如果你对书写顺序感兴趣的话,你可以参阅 第7章-如何将包含阿拉伯语/希伯来语字符的HTML转换为PDF? 的内容
9. 总结
在本章中,我们尝试了不同类型的字体。我们已经了解到,默认情况下只支持有限的字体集,而且我们可以添加对几乎任何我们喜欢的字体的支持,前提是我们可以访问相应的字体程序。
我们还发现iText支持不同于西方从左到右书写系统的书写系统,并且支持连字(阿拉伯文、印度文……),但前提是我们包含pdfCalligraph插件。
在下一章(也是最后一章)中,我们将讨论一些常见问题。
iText7高级教程之html2pdf教程源码下载










![[网络工程师]-应用层协议-WWW与HTTP](https://img-blog.csdnimg.cn/19fea6d345d64d1cb27c42ae54d4bd03.png)