关系抽取从流程上,可以分为流水线式抽取(Pipline)和联合抽取(Joint Extraction)两种,流水线式抽取就是把关系抽取的任务分为两个步骤:首先做实体识别,再抽取出两个实体的关系;而联合抽取的方式就是一步到位,同时做好了实体和关系的抽取。流水线式抽取会导致误差在各流程中传递和累加,而联合抽取的方式则实现难度更大。
关系抽取从实现的算法来看,主要分为四种:
1、手写规则(Hand-Written Patterns);
2、监督学习算法(Supervised Machine Learning);
3、半监督学习算法(Semi-Supervised Learning,比如Bootstrapping和Distant Supervision);
4、无监督算法。
1. 手写规则模板的方法
1、例子:
有种关系叫做上下位关系,比如hyponym(France; European countries)。从下面两个句子中都可以抽取出这种关系:
European countries, especially France, England, and Spain...
European countries, such as France, England, and Spain...
两个实体之间的especially和such as可以看做这种关系的特征。观察更多表达这种关系的句子,我们就可以构造如下的规则模板,来抽取构成上下位关系的实体,从而发现新的三元组。

2、优点和缺点:
优点是抽取的三元组查准率(Precision)高,尤其适合做特定领域的关系抽取;缺点是查全率(Recall)很低,也就是说查得准,但是查不全,而且针对每一种关系都需要手写大量的规则,比较惨。
2. 监督学习的方法
监督学习的方法也就是给训练语料中的实体和关系打上标签,构造训练集和测试集,再用传统机器学习的算法(LR,SVM和随机森林等)或神经网络训练分类器。
1、机器学习和深度学习方法
对于传统的机器学习方法,最重要的步骤是构造特征。可以使用的特征有:
(1)词特征:实体1与实体2之间的词、前后的词,词向量可以用Bag-of-Words结合Bigrams等。
(2)实体标签特征:实体的标签。
(3)依存句法特征:分析句子的依存句法结构,构造特征。这个不懂怎么弄。

人工构造特征非常麻烦,而且某些特征比如依存句法分析,依赖于NLP工具库,比如HanLP,工具带来的误差不可避免会影响特征的准确性。
用端到端的深度学习方法就没这么费劲了。比如使用CNN或BI-LSTM作为句子编码器,把一个句子的词嵌入(Word Embedding)作为输入,用CNN或LSTM做特征的抽取器,最后经过softmax层得到N种关系的概率。这样省略了特征构造这一步,自然不会在特征构造这里引入误差。
2、监督学习的优缺点
监督学习的优点是,如果标注好的训练语料足够大,那么分类器的效果是比较好的,可问题是标注的成本太大了。
3. 半监督学习
鉴于监督学习的成本太大,所以用半监督学习做关系抽取是一个很值得研究的方向。
半监督学习的算法主要有两种:Bootstrapping和Distant Supervision。Bootstrapping不需要标注好实体和关系的句子作为训练集,不用训练分类器;而Distant Supervision可以看做是Bootstrapping和Supervise Learning的结合,需要训练分类器。
3.1 Bootstrapping基于种子的启发式方法
Bootstrapping算法的输入是拥有某种关系的少量实体对,作为种子,输出是更多拥有这种关系的实体对。敲黑板!不是找到更多的关系,而是发现拥有某种关系的更多新实体对。
首先准备一些高质量的实体一关系对作为初始种子(Seed)。如图所示,作者刘慈欣与《三体》这两个实体之间是创作人的关系,可以用<刘慈欣,三体,创作人>三元组来表示,同时需要准备一个大规模语料库提供种子进行模板(pattern)的学习。整个过程会不断重复以下步骤:
- 以初始种子为基础,在大规模语料库中匹配所有相关的句子;
- 对这些句子的上下文进行分析,提取出一些可靠的模板;
- 接着再通过这些模板去匹配语料,发现更多待抽取的实例(新的种子);
- 然后通过新抽取的实例去发掘出更多新的模板。
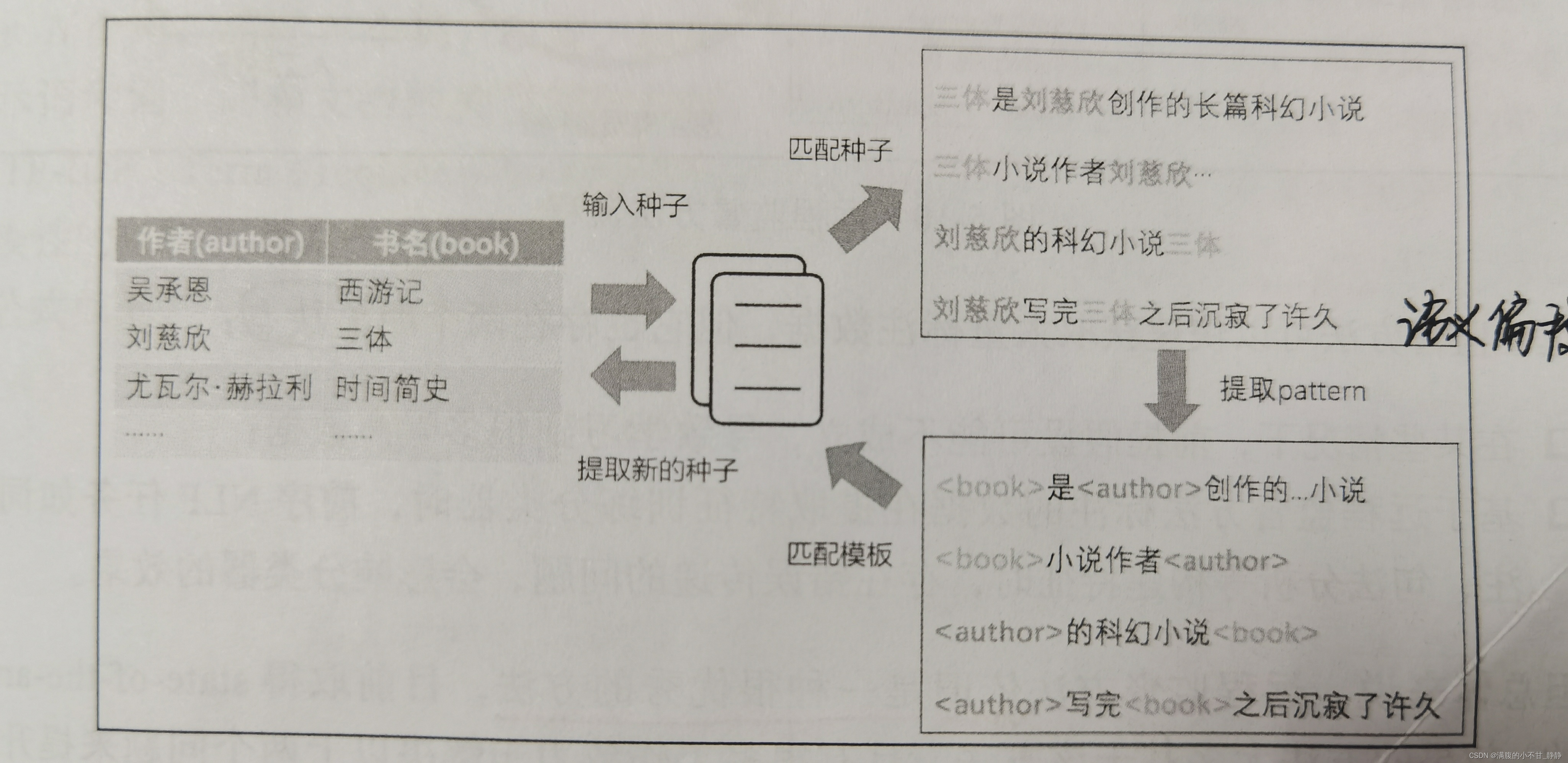
如此不断迭代学习,直到满足预设的收敛条件。通常可以设置不再发现新的实体或者模板作为收敛条件,也可以通过设计评测指标,当新发掘的实例和模板质量低于特定条件时结束迭代。
该方法构建成本低,适合进行大规模的数据构建,并且可能发现新的隐含关系。然而它对初始种子的质量要求高,总体准确率较低,在不断迭代过程中可能会发生语义偏移的、情况,例如图中第四个句子虽然同时包含<刘慈欣>和<三体>实体,但是二者之间并非<创作人>的关系,需要做较多的条件约束来控制提取出的数据的质量。
例子2:“创始人”是一种关系,如果我们已经有了一个小型知识图谱,里面有3个表达这种关系的实体对:(严定贵,你我贷),(马云,阿里巴巴),(雷军,小米)。
- 第一步:在一个大型的语料集中去找包含某一实体对(3个中的任意1个)的句子,全部挑出来。比如:严定贵于2011年创立了你我贷;严定贵是你我贷的创始人;在严定贵董事长的带领下,嘉银金科赴美上市成功。
- 第二步:归纳实体对的前后或中间的词语,构造特征模板。比如:A 创立了 B;A 是 B 的创始人;A 的带领下,B。
- 第三步:用特征模板去语料集中寻找更多的实体对,然后给所有找到的实体对打分排序,高于阈值的实体对就加入到知识图谱中,扩展现有的实体对。
- 第四步:回到第一步,进行迭代,得到更多模板,发现更多拥有该关系的实体对。

细心的小伙伴会发现,不是所有包含“严定贵”和“你我贷”的句子都表达了“创始人”这种关系啊,比如:“在严定贵董事长的带领下,嘉银金科赴美上市成功”——这句话就不是表达“创始人”这个关系的。某个实体对之间可能有很多种关系,哪能一口咬定就是知识图谱中已有的这种关系呢?这不是会得到错误的模板,然后在不断的迭代中放大错误吗?
没错,这个问题叫做语义漂移(Semantic Draft),一般有两种解决办法:
- 一是人工校验,在每一轮迭代中观察挑出来的句子,把不包含这种关系的句子剔除掉。
- 二是Bootstrapping算法本身有给新发现的模板和实体对打分,然后设定阈值,筛选出高质量的模板和实体对。具体的公式可以看《Speech and Language Processing》(第3版)第17章。
2、Bootstrapping的优缺点
Bootstrapping的缺点一是上面提到的语义漂移问题,二是查准率会不断降低而且查全率太低,因为这是一种迭代算法,每次迭代准确率都不可避免会降低,80%---->60%---->40%---->20%...。所以最后发现的新实体对,还需要人工校验。
3.2 远程监督
远程监督本质上是一种自动标注样本的方法,但是它的假设太强了,会导致错误标注样本的问题。
远程监督方法最早由Mintz提出,它结合监督学习和基于种子的启发式方法的优点,用于做联系抽取任务。远程监督方法基于一个前提假设:
如果两个实体之间存在某种关系,那么所有同时提到这两个实体的句子都能够描述这种关系。
其核心思想是利用实体在语料中抽取潜在关系,再用关系反向定位抽取实体。首先基于远程监督方法获取大量的标签数据,再用机器学习或深度学习等有监督方法训练分类器,接着对程序自动标注的数据进行划分,将质量较高的自动标注数据加入训练数据,而将质量低的数据丢弃或者交由人工标注审核,整个流程可以参考图。
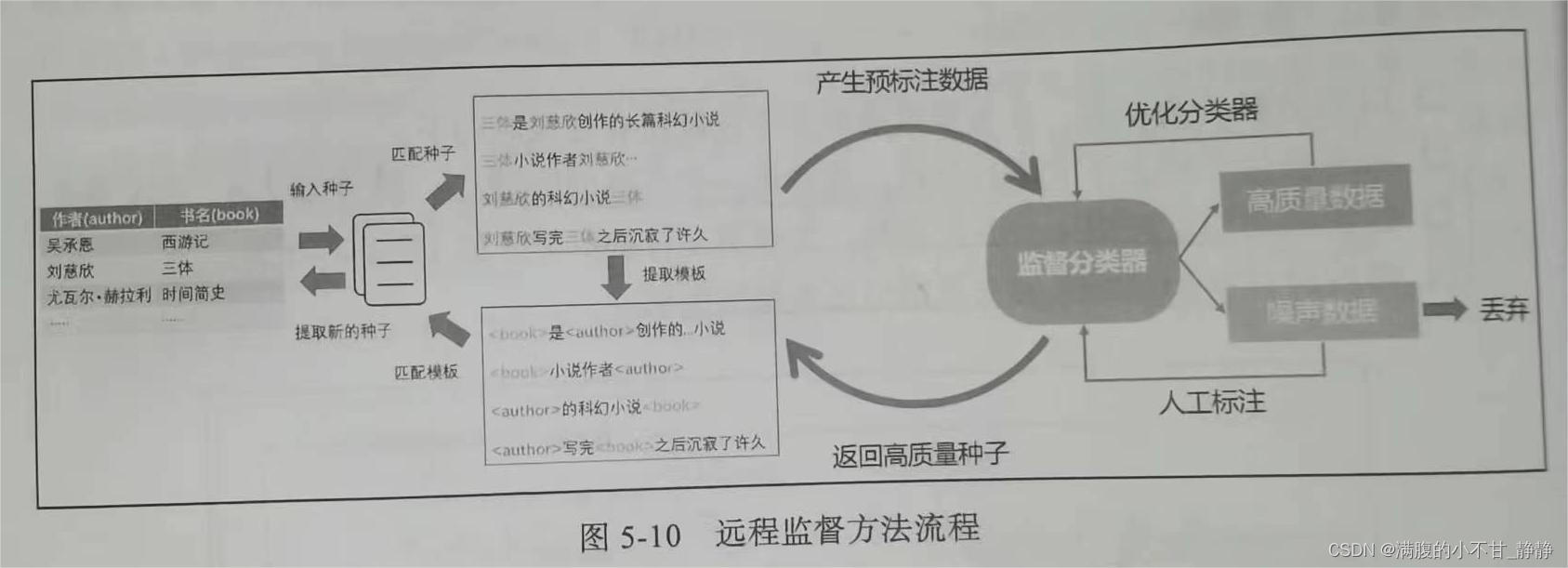
远程监督方法可以快速获取大量标注数据,但它也存在两个明显缺点:
- 在某些情况下,前提假设可能不成立,导致学习到很多噪声数据;
- 基于远程监督方法标注的数据在提取特征训练分类器时,前序NLP任务如词性标注、句法分析等构建特征时,存在错误传递的问题,会影响分类器的效果。这点也是后续研究的一个改进方向,后面的研究人员用神经网络作为特征提取器,代替人工提取的特征,并用词嵌入作为文本特征,如PCNN。
但总体来说,远程监督方法依旧是一种很优秀的方法,目前取得state-of-the-art(最先进的)效果的方法大多基于该方法,且有很多工作致力于解决以上两个问题来提升任务效果,比如Riedel提出了一个加强版的前提假设,即两个实体之间某种关系成立的前提,必须至少有一个包含这两个实体的句子描述了这种关系;再比如在特征构建过程中,也可以摒弃传统pipeline的特征抽取过程,改用CNN网络和Attention机制来抽取特征。
PCNN:亮点在于把多实例学习、卷积神经网络和分段最大池化结合起来,用于缓解句子的错误标注问题和人工设计特征的误差问题,提升关系抽取的效果。
4. 无监督
半监督的办法效果已经勉强,无监督的效果就更差强人意了,这里就不介绍了。









![[网络工程师]-应用层协议-WWW与HTTP](https://img-blog.csdnimg.cn/19fea6d345d64d1cb27c42ae54d4bd03.png)
![[附源码]SSM计算机毕业设计校园疫情防控管理系统JAVA](https://img-blog.csdnimg.cn/0580695c0edf47d893c8791c8f495f28.png)