目录:Faster R-CNN的几点理解
- 一、Faster R-CNN概述
- 二、R-CNN、Fast R-CNN、Faster R-CNN的对照
- 2.1 R-CNN
- 2.1.1 R-CNN的检测步骤
- 2.1.2 R-CNN的主要缺点
- 2.2 Fast R-CNN
- 2.2.1 Fast R-CNN的检测步骤
- 2.2.2 Fast R-CNN的缺点
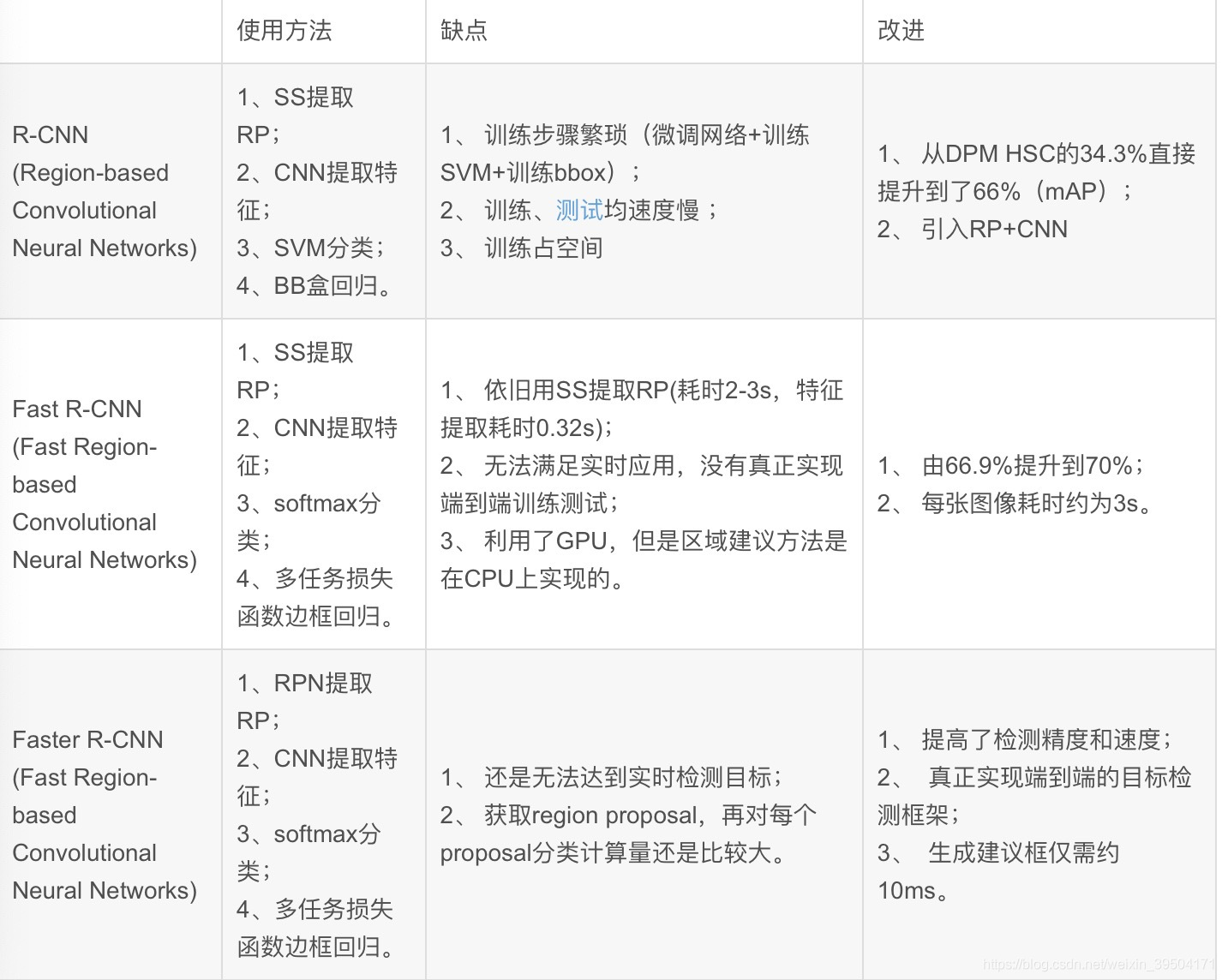
- 2.3 R-CNN、Fast R-CNN、Faster R-CNN的比较
- 三、Faster R-CNN网络结构简介
- 四、Faster R-CNN网络结构详解
- 4.1 特征提取网络
- 4.2 区域建议网络RPN
- 4.2.1 RPN概述
- 4.2.2 RPN实现的具体方法
- 4.2.3 Roi pooling
- 五、Faster R-CNN网络的训练过程
- 5.1 拆分训练
- 5.2 端到端训练
一、Faster R-CNN概述
Faster-RCNN是2015年提出的第一个真正意义上的端到端的深度学习检测算法,其最大的创新之处就在于通过添加RPN网络,基于Anchor机制来生成候选框(代替selective search),最终将特征提取、候选框选取、边框回归和分类都整合到一个网络中,从而有效的提高检测精度和检测效率。
Faster-RCNN的具体的流程就是将输入图像缩放以后进入到卷积层提取特征得到feature map(特征图),然后特征图送入RPN网络生成一系列可能的候选框,接下来将原始的特征图和RPN输出的所有候选框输入到Roi Pooling层,提取收集proposal,并计算出固定大小7×7的proposal feature maps,送入全连接层进行目标分类与坐标回归。
二、R-CNN、Fast R-CNN、Faster R-CNN的对照
2.1 R-CNN
2.1.1 R-CNN的检测步骤
- 输入一张待检测图像;
- 区域推荐(候选区域):常见的方法有selective search和edge
boxes,通过选择性搜索算法对输入图像产生1000~2000个候选边框,但形状和大小是不相同的,这些框之间是可以互相重叠互相包含的;利用图像中的纹理、边缘、颜色等信息,可以保证在选取较少窗口的情况下保持较高的召回率(Recall); - 特征提取:利用卷积神经网络(CNN)对每一个候选边框提取深层特征;
- 分类:利用线性支持向量机(SVM)对卷积神经网络提取的深层特征进行分类;
- 去除重叠:将非极大值抑制方法应用于重叠的候选边框,挑选出支持向量机得分较高的边框(bounding box)。
2.1.2 R-CNN的主要缺点
- 重复计算:计算了候选框之间的重叠部分;(在Fast R-CNN中改良;)
- 性能瓶颈:所有的候选框会被放缩到固定的尺寸,这将导致图像的畸变,使得模型的性能很难有进一步的提升;(在Fast R-CNN中通过RoI
Pooling改良;) - 步骤繁琐,训练过程分为多阶段;(在Fast R-CNN中通过Softmax替代SVM进行分类改良;)
- 训练占用内存大,目标检测速度慢。
2.2 Fast R-CNN
2.2.1 Fast R-CNN的检测步骤
- 输入一张待检测图像;
- 提取候选区域:利用Selective Search算法在输入图像中提取出候选区域,并把这些候选区域按照空间位置关系映射到最后的卷积特征层;
- 区域归一化:对于卷积特征层上的每个候选区域进行RoI Pooling操作,得到固定维度的特征;
- 分类与回归:将提取到的特征输入全连接层,然后用Softmax进行分类,对候选区域的位置进行回归。
2.2.2 Fast R-CNN的缺点
- 仍然未能实现端到端(end-to-end)的目标检测,比如候选区域的获得不能同步进行;(在Faster
R-CNN中通过RPN替代SS算法进行改良;) - 速度上还有提升空间。
2.3 R-CNN、Fast R-CNN、Faster R-CNN的比较
三、Faster R-CNN网络结构简介
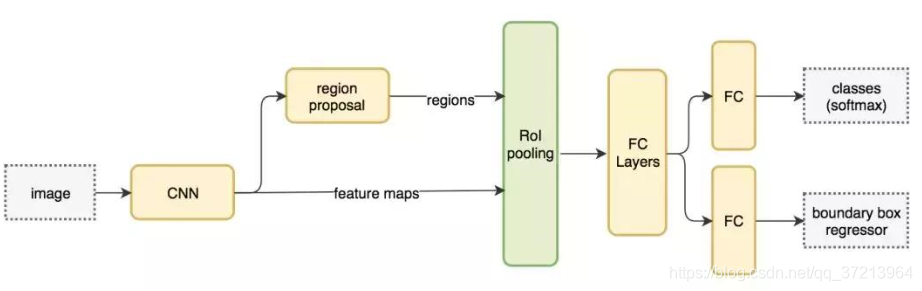
Faster R-CNN的结构可分为四个部分:
- 特征提取网络CNN;
- 区域建议网络RPN
- Roi Pooling:这一步主要是将ROI映射到特征图上,然后进行分块,再对每个块做maxpooling,主要作用是将不同大小的ROI统一成固定长度的输出
- 分类和回归
四、Faster R-CNN网络结构详解
4.1 特征提取网络
这部分和普通的CNN网络中特征提取结构相同,可使用VGG、ResNet、Inception等各种常见的结构(只使用全连接层之前的部分)对输入图片提取特征,最后输出feature map。
4.2 区域建议网络RPN
4.2.1 RPN概述
无论是SSP net 还是 Fast R-CNN网络结构,区域候选环节都采用了Selective search算法,以现在的眼光去比喻类似于造好了一辆汽车(CNN)但是在用马(selective search)拉着跑,因为selective search的计算太慢了,想让物体检测达到实时,就得改造候选框提取的方法。
Faster CNN要做的改进就是统一区域候选提取、分类和边界框回归,实现检测算法的End-to-End。RPN在Faster RCNN这个结构中专门用来提取候选框,相比于Selective Search算法RPN耗时少,并且便于结合到Fast RCNN中成为一个整体。
RPN的引入真正意义上把物体检测整个流程融入到一个神经网络中, Faster RCNN = RPN + Fast RCNN 。
4.2.2 RPN实现的具体方法
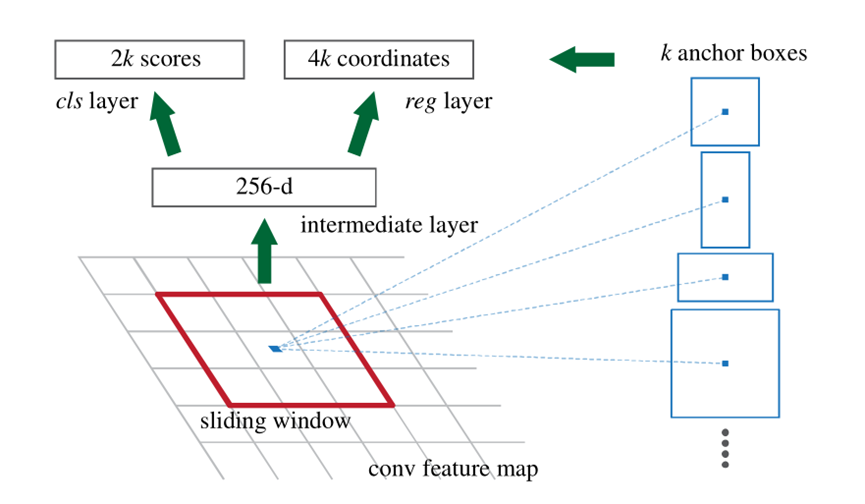
RPN网络是一个全卷积网络,它的核心思想就是使用”滑动窗口+anchor机制”来生成候选框。具体方法是在前面卷积层卷积得到的4060的特征图上,利用滑动窗口的方式,也就是3×3的卷积核在每个滑动窗口中心点构造9个不同长宽比不同尺度的候选框(4060*9≈2万个),并将其以16的映射比例映射到rescale图像中框出来,舍弃超出边界的预proposal,再根据每个区域的softmax score进行从大到小排序,提取前2000个预proposal,对这个2000个进行非极大值抑制,最后将得到的再次进行排序,输出300个proposal给Faster RCNN进行预测,此时Faster RCNN的预测类别不包括背景,因为RPN输出默认为前景。
RPN是一个卷积层(256维)+ relu激活函数 + 左右两个层的(clc layer 和 reg layer)的小网络。RPN在feature map上用3×3的滑动窗口进行卷积,卷积步长stride=1,填充padding=2得到可以被9个anchor区域共享的256d特征。生成anchor区域具体操作是在对特征图卷积的同时,以每个卷积核的中心点为anchors的中心,为每个特征点生成长宽比为[1:1,1:2,2:1]的共9个矩形,输入RPN分类器RPN回归器。如下图所示:
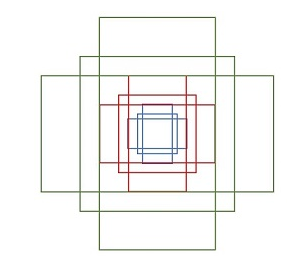
也就是只要一次前向操作就同时预测k个区域的前景、背景概率(1个区域2个scores,所以得到2k个scores)以及bounding box(1个区域4个coordinates,所以是4k个coordinates),最终每一个bbox都有一个6维的向量,前2维用来判断该框内是否有物体,后面4个维度用来判断该bbox里物体的坐标。另外,在训练RPN筛选候选框时,设定跟任意ground truth(GT) IOU的阈值为0.7,大于0.7的anchor标记为前景(正标签),小于0.3的标定为背景(负样本),然后在分类层,损失函数用softmax loss,RPN只对有标签的区域计算loss,非正非负的区域不算损失,对训练没有作用。
而且,在训练的过程中,FasterRCNN采用交替训练的方式,用初始化的权值训练RPN,再用RPN提取的候选区域训练卷积网络,更新权值。
4.2.3 Roi pooling
Roi Pooling在介绍Fast R-CNN的博客中做过比较具体的介绍,它在此处的具体作用主要有两个:
- 从feature maps中“抠出”proposals(大小、位置由RPN生成)区域
- 对大小不一致的输入(这里是卷积层特征图)执行最大池化,并生成固定大小的小功能映射
为什么要pooling成固定长度的输出呢?RPN网络提取出的proposal大小是会变化的,而分类用的全连接层输入必须固定长度,所以需要一个从可变尺寸变换成固定尺寸输入的过程。在较早的R-CNN结构中都通过对proposal进行缩放或剪裁到固定尺寸来实现,缩放和剪裁的副作用就是原始的输入发生变形或信息量丢失,以致分类不准确,而ROI Pooling就完全规避掉了这个问题,proposal能完整的池化成全连接的输入,而且没有变形,长度也固定。
Roi Pooling的具体操作为:
- roi映射,首先将roi映射到特征图的相应位置
- 对映射后的roi分块
- 对每个块进行max pooling操作
- 假设此时的特征图大小为88,roi投影后的对应位置为(0,3)(7,8),需要再将该区域划分 ( 2 × 2 ) (2\times 2) (2×2)sections,注意这里的22是根据要求输出的大小确定的,然后对每个section做Max Pooling操作,这样就得到了固定大小的输出。
五、Faster R-CNN网络的训练过程
Faster R-CNN Faster的训练方法主要分为拆分训练和端到端训练。
5.1 拆分训练
先训练RPN,从所有anchor box中随机挑选256个,保持正样本负样本比例1:1(正样本不够时用负样本补);再从RPN的输出中,降序排列所有anchor box的前景置信度,挑选top-N个候选框叫做proposal, 做分类训练。
整个网络的具体训练过程有四步:
- 使用ImageNet的预训练模型,初始化RPN,单独训练RPN网络
- 使用ImageNet的预训练模型初始化Fast Rcnn,同时将第一步RPN的输出作为Faster R-CNN的输入
- 使用第二步的模型再次训练RPN网络,要求固定住公共网络部分,只更新RPN的参数
- 使用第三步的结果微调Faster R-CNN,同样是固定公共网络不变,只更新检测网络
5.2 端到端训练
- 理论上Faster R-CNN网络可以做端到端的训练,但是由于anchor box提取的候选框中负样本占大多数,有的图中负样本和正样本的比例可以是1000:1,导致直接训练难度很大。真正的端到端的目标检测网络还是有的,例如one-stage中代表的YOLO、SSD算法,速度很快,但是精度差一些。
- Faster R-CNN最核心的工作在于在提取特征的过程中完成候选框提取的操作,大大加快了物体检测的速度。





![[网络工程师]-应用层协议-WWW与HTTP](https://img-blog.csdnimg.cn/19fea6d345d64d1cb27c42ae54d4bd03.png)
![[附源码]SSM计算机毕业设计校园疫情防控管理系统JAVA](https://img-blog.csdnimg.cn/0580695c0edf47d893c8791c8f495f28.png)
![[附源码]计算机毕业设计springboot基于java的社区管理系统](https://img-blog.csdnimg.cn/de9d430bbb8a4393a2a7bede98e5ce86.png)