构建带口音的语音合成系统可以增加语音合成的多样性和趣味性。然而不是每个人都能说多种口音。为了实现口音与说话人音色的自由组合,借助迁移学习技术,为没有口音数据的说话人构建口音合成系统,是实现“口音任意说”的有效途径。但是以往大多数口音迁移技术需要一个高质量的口音语音合成数据集才能实现将口音迁移到一个没有口音的说话人上,因此实现口音迁移的数据门槛较高。
近期,由西工大音频语音与语言处理研究组(ASLP@NPU)和腾讯 IEG 合作的论文“ AccentSpeech: Learning Accent from Crowd-sourced Data for Target Speaker TTS with Accents”被语音旗舰会议 ISCSLP 2022 接收。该论文利用低质量的众包口音数据集KeSpeech [1] ,将低质数据中的各种普通话地方口音迁移到标准普通话口音的目标说话人DB1 [2] 上,实现保留DB1音色带有各种口音的语音合成系统。

论文题目:AccentSpeech: Learning Accent from Crowd-sourced Data for Target Speaker TTS with Accents
作者列表:张雍茂,王智超,杨培基,孙闳绅,王智圣,谢磊
论文原文:https://arxiv.org/abs/2210.17305

图1 发表论文截图
1. 背景动机
语音中包含了丰富的信息,口音(Accent)是其中的重要组成部分,反映了说话人的地域等属性。实验室之前的相关工作实现了输入任意说话人语音转换到目标说话人音色带各种口音的语音[3]
一个理想的文语转换(TTS)系统应该可以合成目标说话人音色的多种口音。为了构建口音迁移系统实现“口音任意说”的语音合成系统,通常需要高质量的棚录口音数据集,但是这样的高质量口音数据集的构建不仅需要完备的录音条件,还需要每种口音的专业录音人员,成本较高。相比高质量的带口音的语音合成数据集,低质量的众包口音数据相对容易获取。例如,KeSpeech数据集 [1]就包括了来自中国30多个城市两千多个说话人贡献的超过1500小时的口音语音数据。然而在使用这些低质数据构建口音迁移系统时会遇到两个困难:
-
音质问题。众包数据通常在常规环境录制,录音来自各种不同设备(诸如各种型号手机),存在明显背景噪声和混响,录音信道和前处理算法也会对音质造成损伤。
-
韵律问题。众包口音发音人根据跟定文本进行朗读,发音韵律较差,不可避免有不正常停顿、一字一顿等现象。
为了克服上述两个问题,我们通过采用噪声鲁棒的ASR系统提取的瓶颈特征(Bottleneck feature)来缓解音质问题带来的影响,并采用平行数据扩充的方式来避免建模众包数据发音人的发音韵律。
2. AccentSpeech方案
针对低质数据存在的两个问题,本文的解决方法如下。
-
针对众包数据音质带来的问题,我们采用噪声鲁棒的ASR系统 [4] 提取的瓶颈特征 (BN) 作为中间表征来缓解噪声和混响带来的影响。由于噪声鲁棒的端到端ASR系统提取的BN特征具有一定的噪声和混响鲁棒性,所以从低质口音数据中提取的瓶颈特征能够消除这些干扰影响,只包含了语言和与发音相关的信息,低质数据中的噪声和混响对模型的影响较小。
-
针对众包发音人的发音韵律较差的问题,我们引入了一个三段式TTS框架。首先使用目标说话人的高质量数据训练Text-to-BN (T2BN) 和 BN-to-Mel (BN2Mel) 模块,并在两个模块中间加入一个使用众包口音数据训练的BN-to-BN (BN2BN) 模块来进行口音迁移任务。我们通过数据扩充的方式生成了非口音的BN和带有口音的BN的平行数据来训练BN2BN模块。最终通过三段式框架实现了合成目标说话人带口音的语音。因为合成语音的韵律是从目标说话人的高质量数据中学习的,所以最终语音的发音韵律稳定。
AccentSpeech系统的整体模型结构如图3所示,声学模型部分由T2BN、BN2BN、BN2Mel三部分串联得到。T2BN采用FastSpeech [5] 模型结构,BN2BN采用卷积加FFT Block的结构,BN2Mel采用自回归的结构。

图3 AccentSpeech模型结构
如图4所示,模型的训练流程分为三步:
-
使用目标说话人高质量数据训练T2BN、BN2Mel和Vocoder三个模型;
-
使用文本前端和强制对齐工具得到众包口音数据的音素和时长信息,在此基础上使用第一步训练的T2BN模型构造非口音BN和带口音BN的平行数据;
-
使用第2步得到的平行数据训练BN2BN口音转换模型。
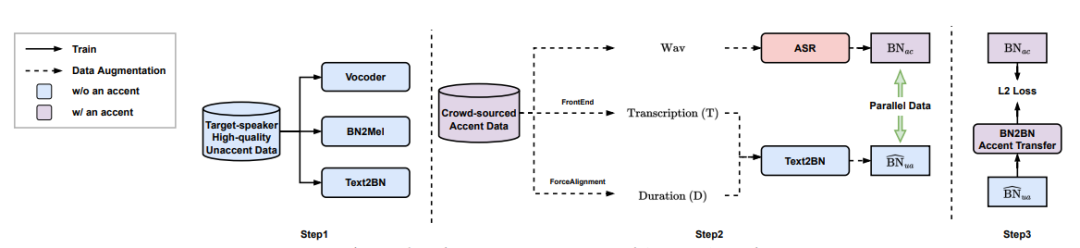
图4 AccentSpeech训练流程
3. 实验验证
我们在中文口音迁移任务上进行实验验证。实验使用两个开源数据进行验证,众包口音数据为KeSpeech [1],目标说话人数据为DB1。我们选用KeSpeech数据中的四川、西安、郑州三个城市的口音数据进行实验,三个城市的口音数据分别有30566、32323、21901句。目标说话人DB1的高质量普通话数据有10000句。
我们在此数据集上对比了Accent-FastSpeech、Accent-Hieratron和AccentSpeech三个系统的口音迁移效果。Accent-FastSpeech采用FastSpeech的结构并接受AccentID和SpkID来实现对口音和说话人的控制。Accent-Hieratron采用Hieratron的模型结构,包括Text2Bottleneck和Bottleneck2Mel两部分,分别负责建模口音与音色,在合成时通过口音与音色的组合来实现口音迁移。对比结果如图5所示,Accent-FastSpeech训练不收敛,Accent-Hieratron同样使用了端到端ASR系统提取的BN特征,所以音质与AccentSpeech相近,但Accent-Hieratron的发音自然度较差,这是由于众包数据是由普通人在日常状态下朗读录制的,Accent-Hieratron学到了其中的发音韵律。而AccentSpeech的韵律则更加稳定,因为BN2BN模型只会学到众包数据中的口音,而韵律来自专业目标发音人。

图5 偏好测试结果
我们还对音色相似度和音素时长进行分析,计算口音迁移之后的音频与目标说话人的音色相似度和时长MAE如表1所示。我们发现AccentSpeech和Accent-Hieratron的音色相似度相当,进行口音迁移之后相比迁移之前的音色相似度略有下降。AccentSpeech预测的时长更接近目标说话人的真实时长。
表1 客观指标

对预测的时长进行可视化如图6所示,可以看出Accent-Hieratron因为学到了众包数据中的发音韵律,导致预测的时长偏离目标说话人的真实时长较大,听感不自然。

图6 时长预测可视化
对扩充的数据进行可视化如图7所示,图7(a)为原始众包口音数据中的一条,可以看到音频中存在背景噪声,图7(b)为从图7(a)音频提取BN后还原的音频,可以看出背景噪声消失了,说明提取BN的过程可以有效过滤背景噪声,图7(c)为使用T2BN生成的无口音BN再还原的音频,其与图b对应的BN形成平行数据。
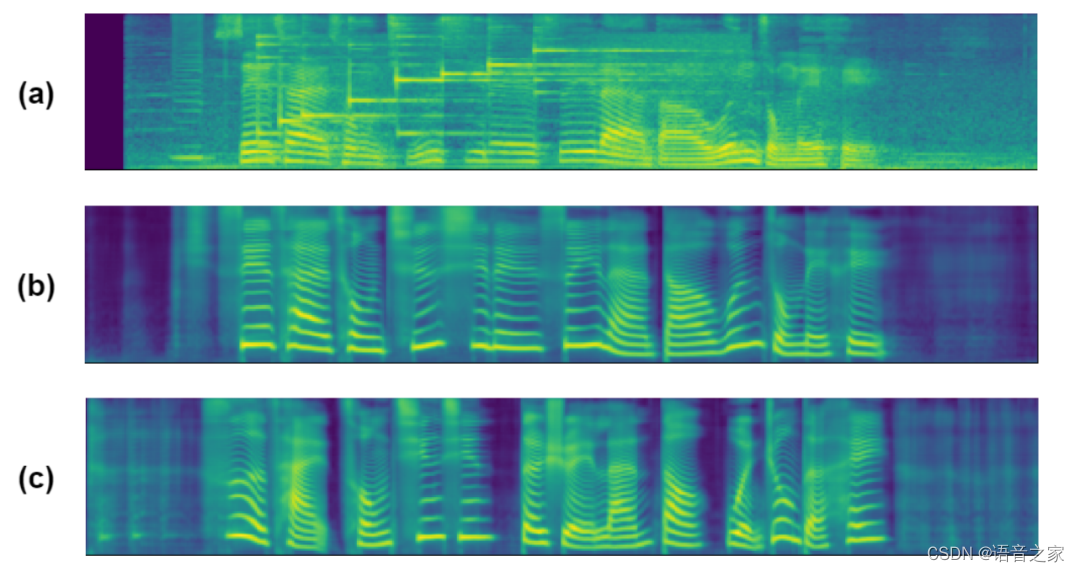
图7 数据扩充可视化
4. 总结
本文提出了利用众包口音数据进行口音迁移的AccentSpeech TTS模型,解决了众包口音数据中存在的低音质和发音韵律差带来的问题,实现了将低质口音数据中的口音迁移到目标说话人同时保留目标说话人音色的语音合成,降低了口音迁移的数据门槛。但合成的整体稳定性有待提高,距离高质量口音数据的迁移效果还有差距。
本文更多样例敬请访问
https://accentspeech.github.io/AccentSpeech/
参考文献
[1] Z. Tang, D. Wang, Y. Xu, J. Sun, X. Lei, S. Zhao, C. Wen, X. Tan, C. Xie, S. Zhou, R. Yan, C. Lv, Y. Han, W. Zou, and X. Li, “Kespeech: An open source speech dataset of mandarin and its eight subdialects”, NeurIPS Datasets and Benchmarks 2021.
[2] https://www.data-baker.com/open source.html.
[3] Z. Wang, W. Ge, X. Wang, S. Yang, W. Gan, H. Chen, H. Li, L. Xie, X. Li, “Accent and Speaker Disentanglement in Many-to-many Voice Conversion”, ISCSLP 2021.
[4] Z. Yao, D. Wu, X. Wang, B. Zhang, F. Yu, C. Yang, Z. Peng, X. Chen, L. Xie, and X. Lei, “Wenet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit”, Interspeech 2021.
[5] Y. Ren, Y. Ruan, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T. Liu, “Fastspeech: Fast, robust and controllable text to speech”, NeurIPS 2019.
![[网络工程师]-应用层协议-WWW与HTTP](https://img-blog.csdnimg.cn/19fea6d345d64d1cb27c42ae54d4bd03.png)
![[附源码]SSM计算机毕业设计校园疫情防控管理系统JAVA](https://img-blog.csdnimg.cn/0580695c0edf47d893c8791c8f495f28.png)
![[附源码]计算机毕业设计springboot基于java的社区管理系统](https://img-blog.csdnimg.cn/de9d430bbb8a4393a2a7bede98e5ce86.png)