前言
前面讲了 Underfit , Overfit ,这里重点讲解一下如何检测
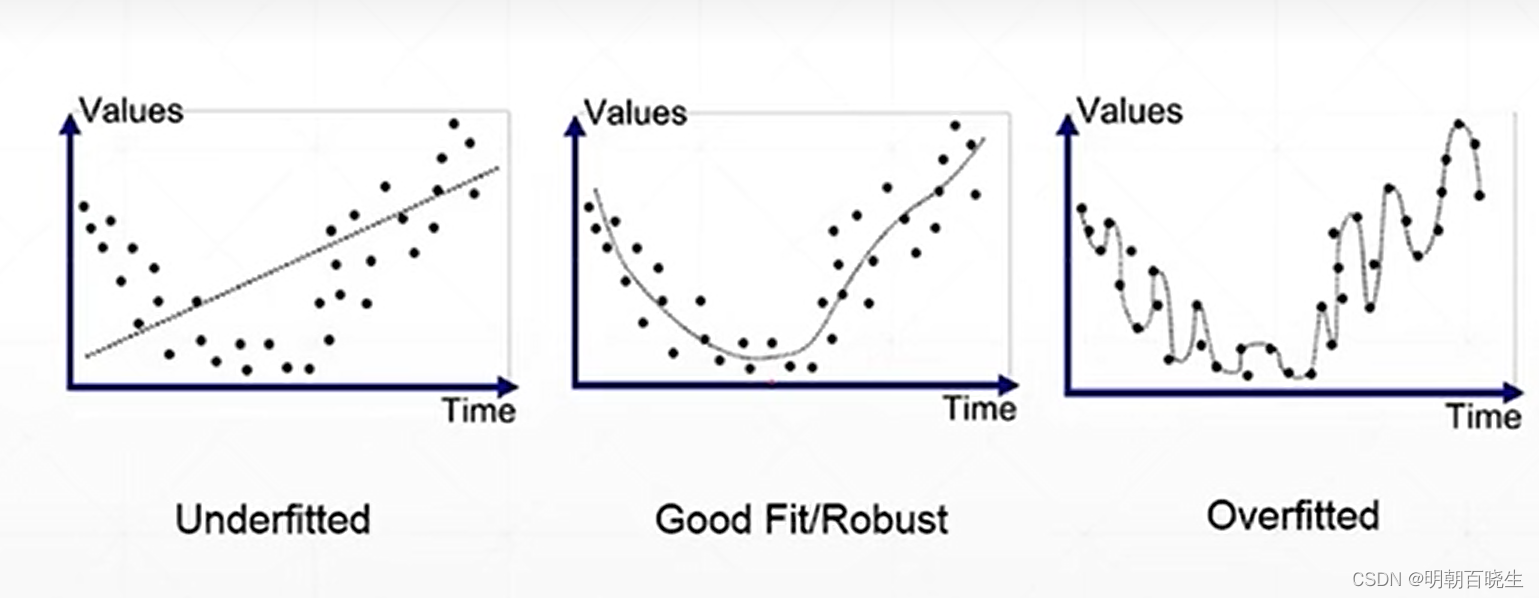
一 数据集划分
训练的时候,我们一般把数据集分成 训练集 和 验证集

每训练一轮或者几轮.validation 一次,看一下当前 验证集上的loss&acc 是否
提升.如果已经是最佳值,则提前结束训练,防止过拟合.
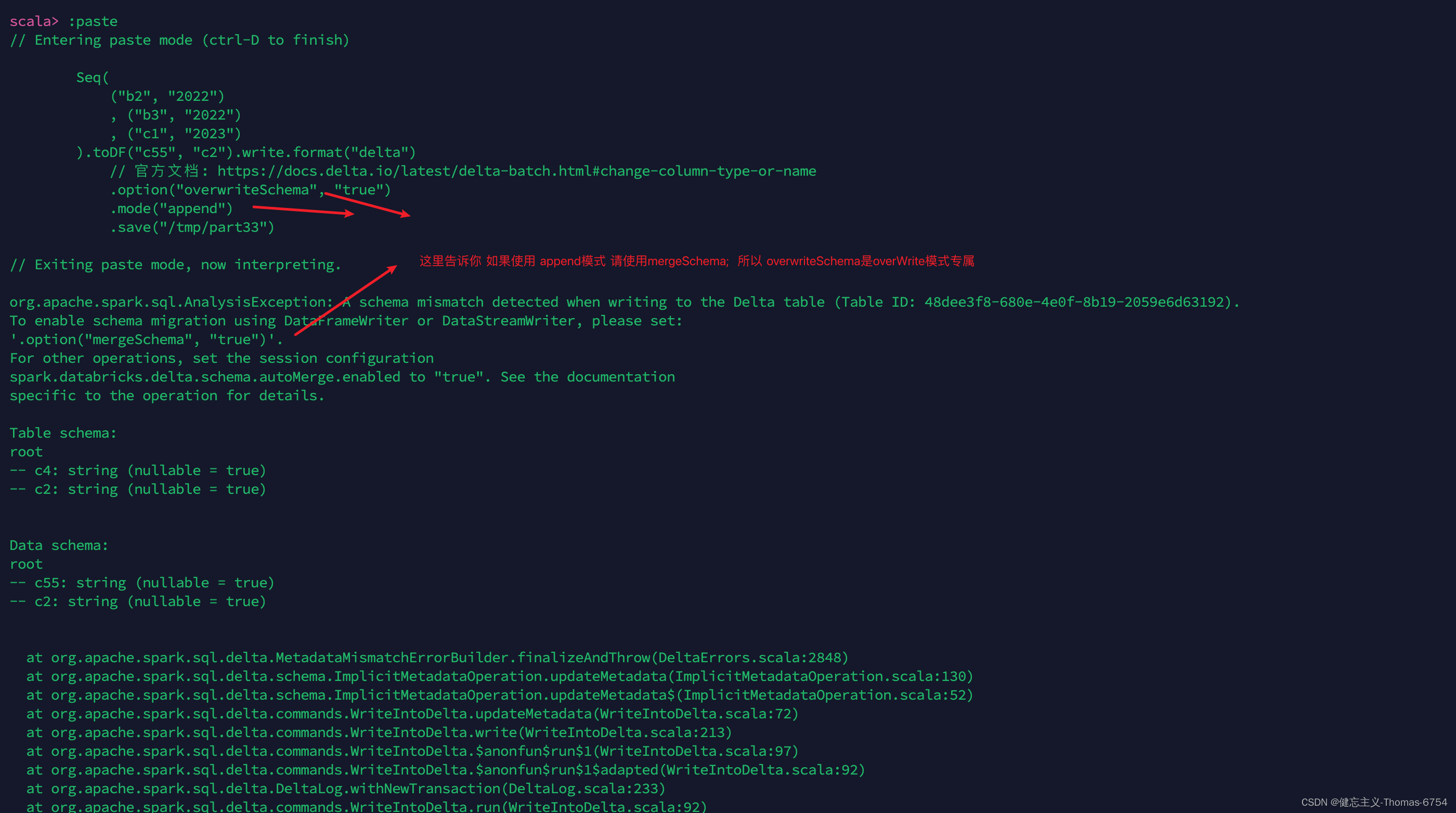
如下图,Testing Error 先降低,如果一致训练下去,就会出现过拟合。
TrainError 降低,但是Test Error 变高

实际做产品或者项目的时候,会把数据集分成三部分
Train Set |Val Set|Test Set

二 数据集划分
2.1 train Data 划分
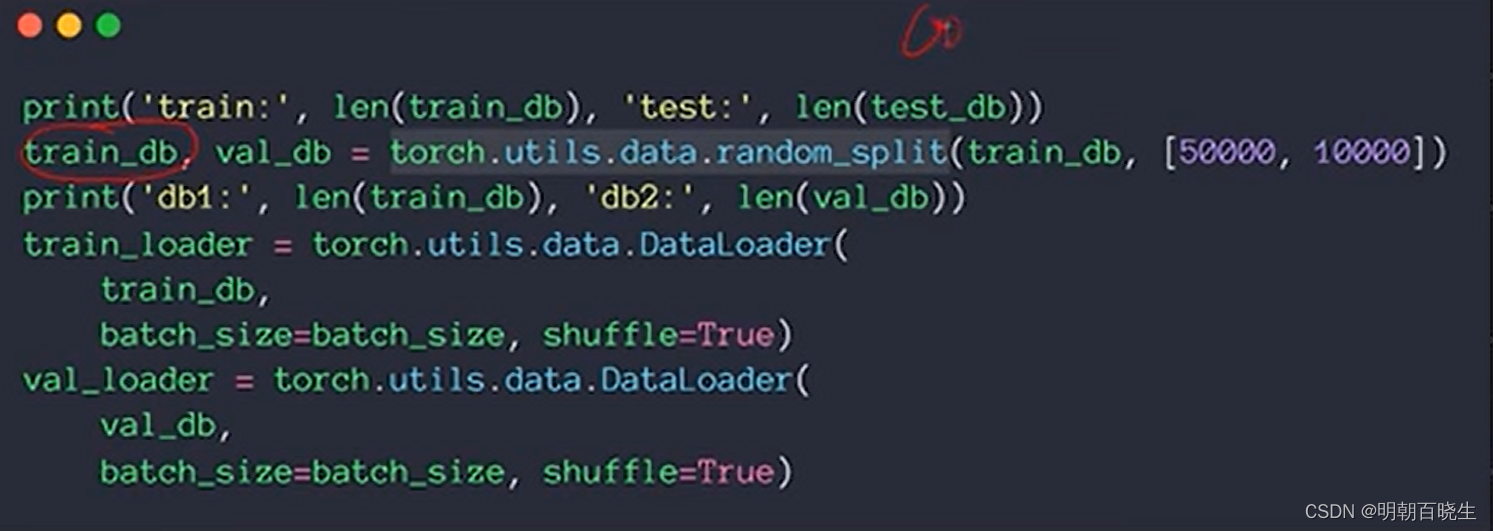
这里使用
torch.utils.data.random_split
描述
随机将一个数据集分割成给定长度的不重叠的新数据集。可选择固定生成器以获得可复现的结果(效果同设置随机种子)
参数
dataset(Dataset) – 要划分的数据集。lengths(sequence) – 要划分的长度。generator(Generator) – 用于随机排列的生成器
对70K的train Data, 50K用于训练,10k 用于validation.10k固定用于test.

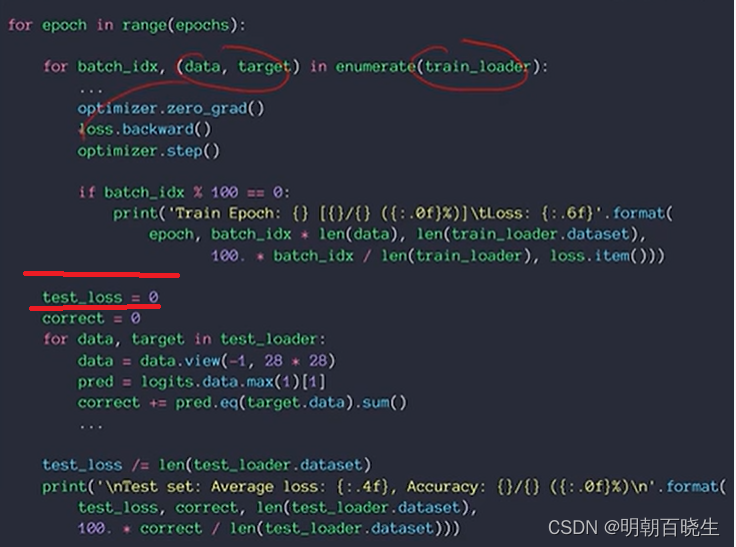
训练的时候,一种方法是训练到最大次数,每一epoch 记录下当前的参数
,当训练结束完,找到validation 上 acc&loss 精度最高的那个点的参数,
然后使用test Data, 测试一下对应的Acc&loss
参考:
课时56 交叉验证-1_哔哩哔哩_bilibili