一、向量检索介绍
1.1 多模态信息的典型特点-非结构化
信息可以被划分为两大类:当信息能够用数据或统一的结构加以表示,称之为结构化数据;当信息无法用数字或统一的结构表示,称之为非结构化数据。非结构数据与结构化数据相比较而言,更难让计算机理解。
以搜索为例:需要将非结构化数据→转为结构化→再完成搜索;

1.2 向量检索的定义与应用
1.2.1 什么是向量检索?
将物理世界产生的非结构化数据,转化为结构化的多维向量,用这些向量标识实体和实体间的关系。
再计算向量之间距离,通常情况下,距离越近、相似度越高,召回相似度最高的TOP结果,完成检索。
向量检索其实离我们很近:以图搜图、同款比价、个性化搜索、语义理解……
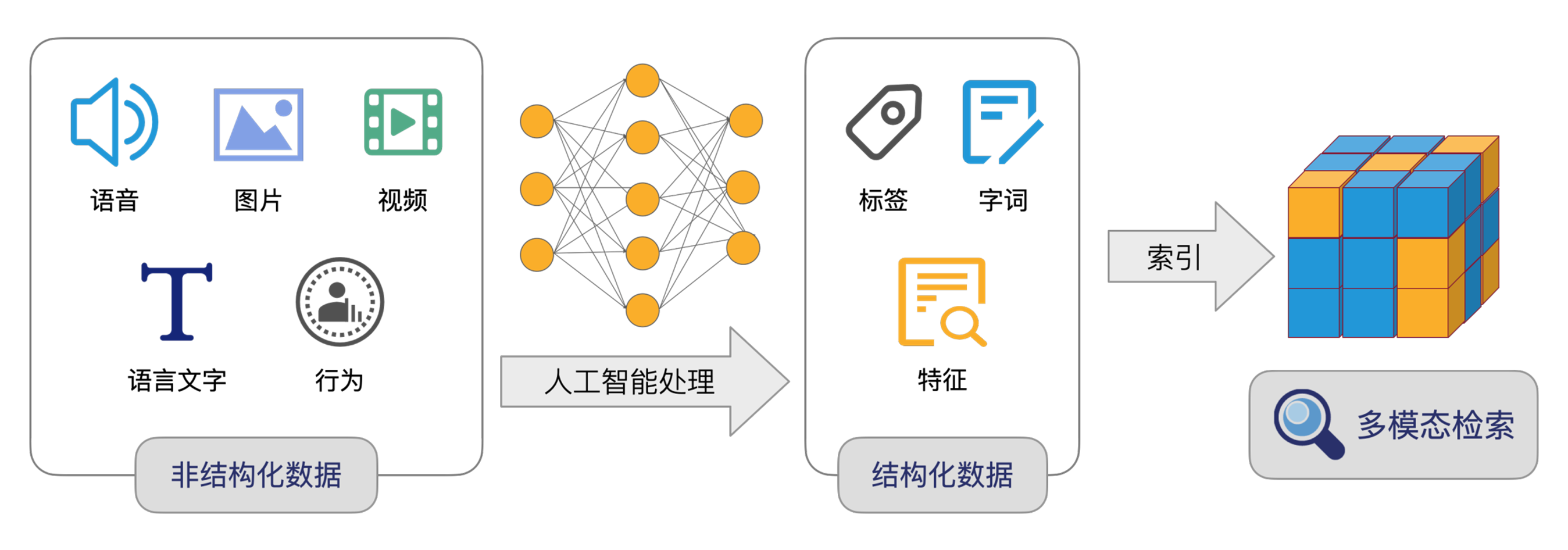
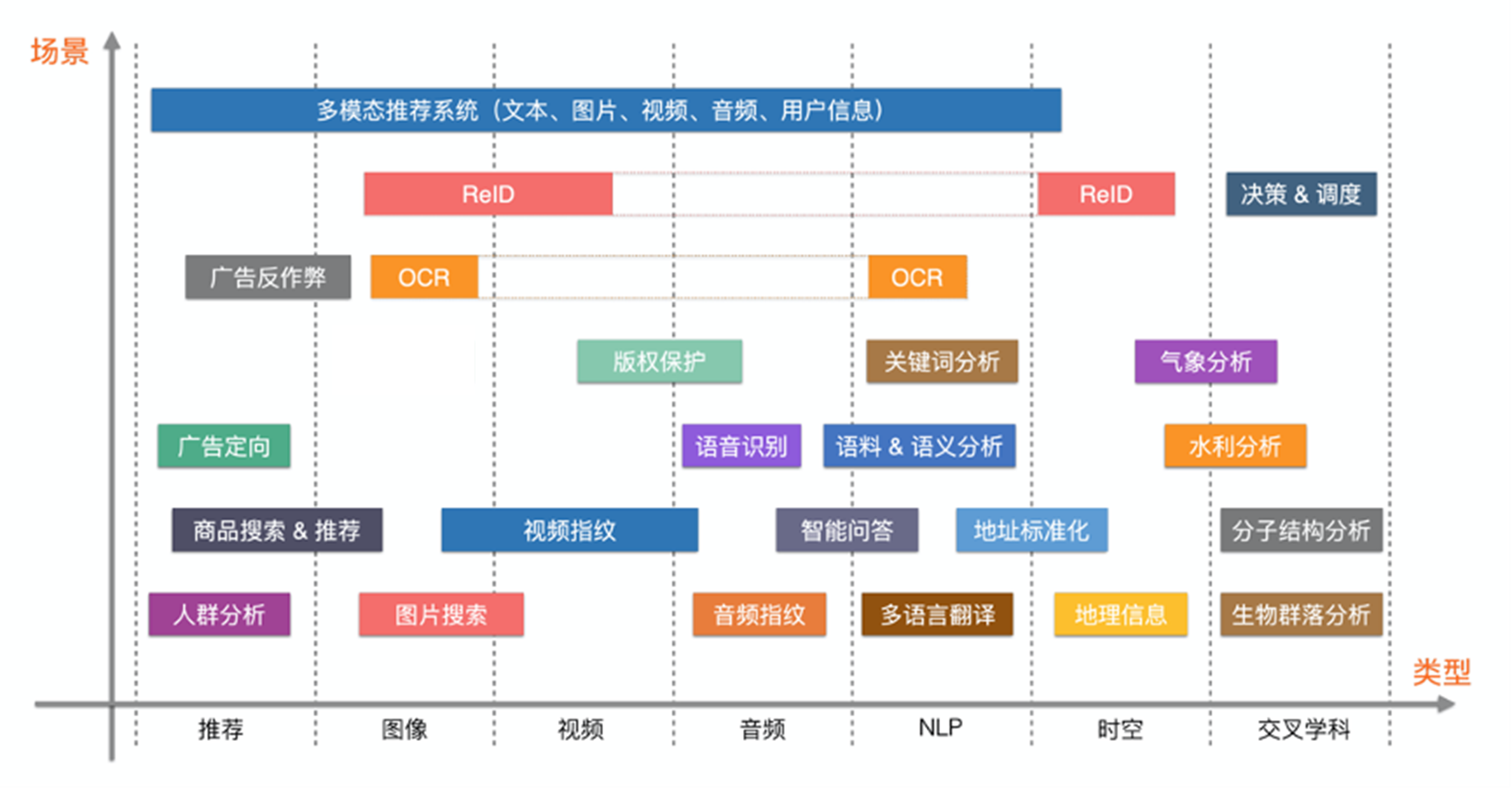
1.2.2 向量检索典型应用场景
- 图像/视频/语音 多模态检索
图搜购物、同款比价,拍照搜题、图片识别等;
- NLP 文本检索
标准地址库检索、企业机构名称检索、通过补充向量语义召回,提升搜索效果;
- 搜索推荐广告
相似推荐、个性化搜索等;
- 向量检索几乎能够应用到AI领域的所有场景。
同时检索的结果也可以作为后续算法的输入进行更多业务相关的计算,实现复杂的业务场景。
二、企业自建向量检索的痛点
- 性能差:返回结果耗时太长、结果返回率低 —— 搜索等待久,甚至超时崩溃,体验差
- 成本高:索引占用过多内存,成本高,价格贵 —— 业务投入成本高,性价比低
- 效果差:缺少向量搭建经验,精度和参数调不好 —— 搜索效果差
- 海量数据支持差:业务快速增长,数据量飞涨,自建方案无法有效进行海量数据的索引构建和处理 —— 构建慢、更新慢、拓展性差
三、OpenSearch向量检索版-端到端图像搜索解决方案
3.1 端到端图像搜索方案介绍
就算企业没有向量数据、仅有图片原始数据,也能通过OpenSearch向量检索版端到端图像搜索方案,快速搭建图像搜索服务。用户可以直接导入图片源数据,在OpenSearch内部便捷完成图片向量化、向量搜索等步骤,实现以图搜图、以文搜图等多种图像检索能力。
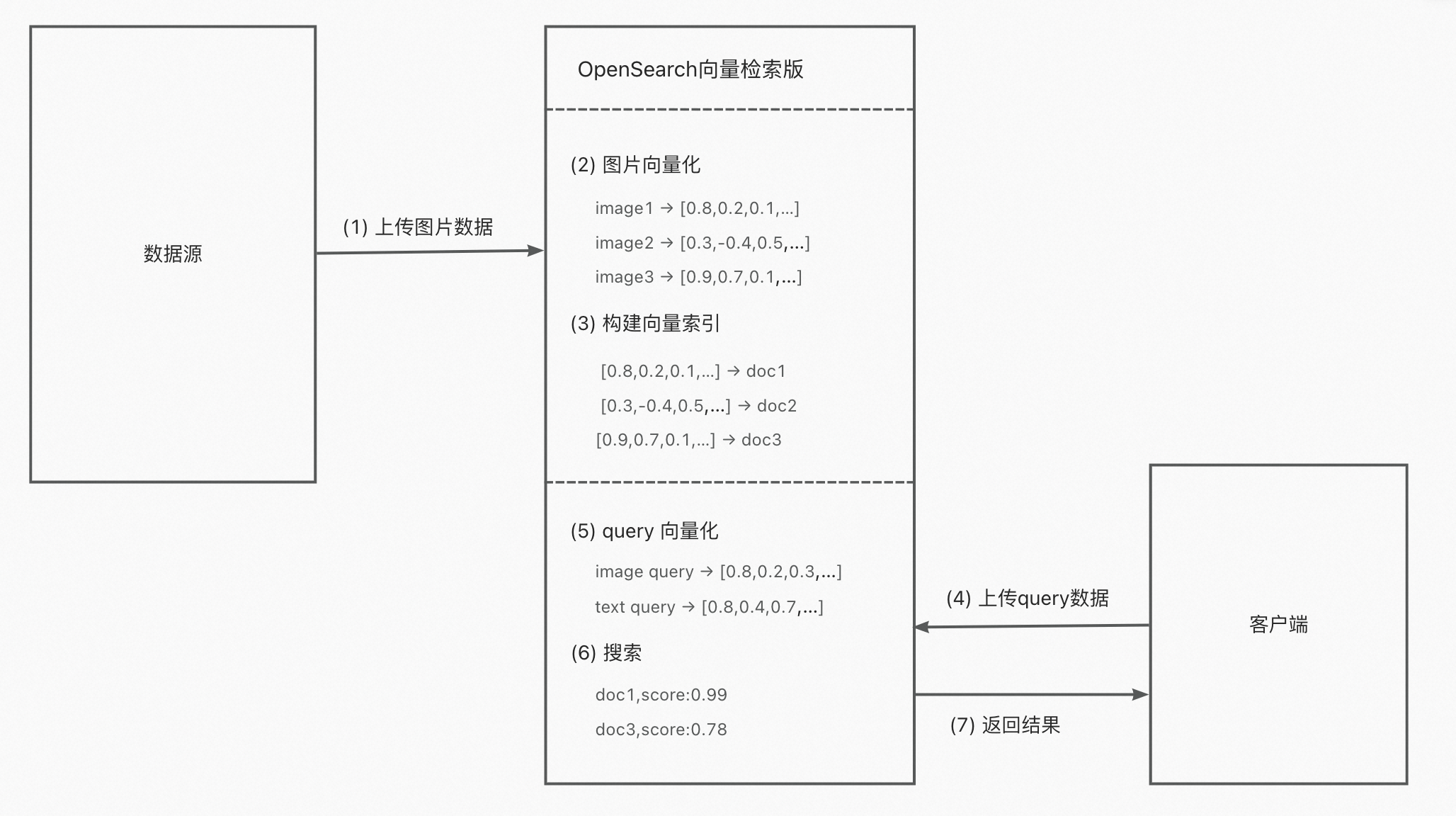
(1)便捷、高性价比的端到端体验
- 向量化和索引构建
-
- 客户将图片源数据上传到OpenSearch向量检索版,向量检索版使用内置算法,能够将千亿级别的图片数据进行向量化、存储、并形成向量索引。
- 针对字段、索引进行压缩,尽可能减少内存占用,帮助客户降低成本。
- 搜索
-
- 客户将要搜索的图片,上传给OpenSearch向量检索版,由它对该图片进行向量化
- 将向量化后的图片与此向量索引进行比对查询,获取相似度最高的结果,并返回给客户
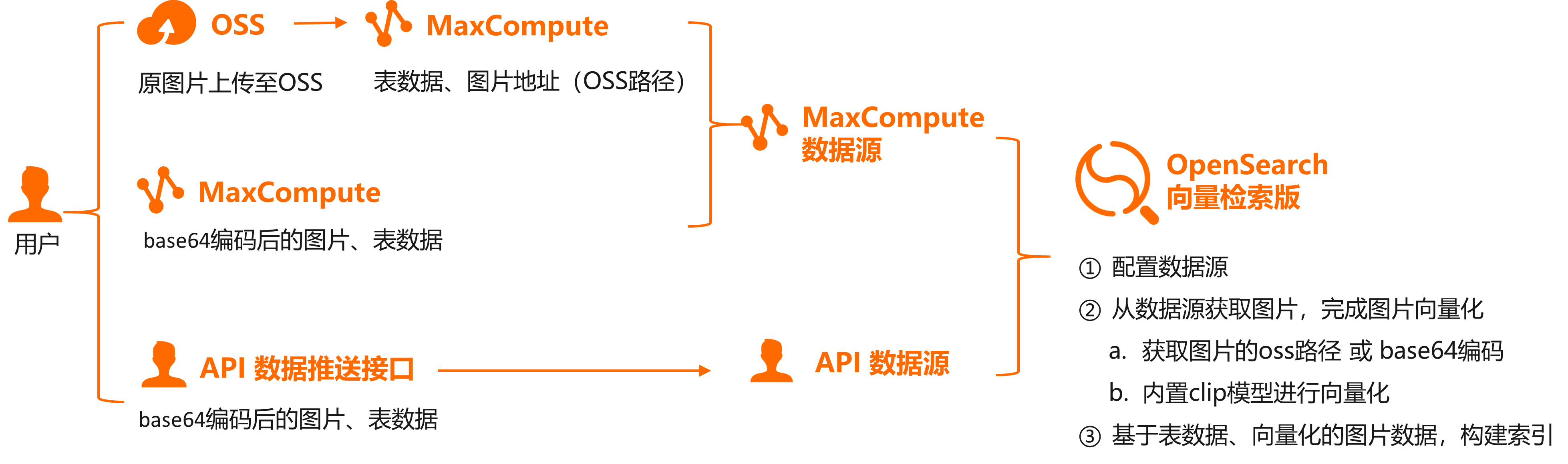
(2)可选三种方式上传图片原始数据,进行向量化处理
- OSS+MaxCompute+OpenSearch向量检索版:用户先将图片上传至OSS中,在MaxCompute中存储业务表数据以及每条数据对应的图片地址(OSS里的路径,比如/image/1.jpg)
- MaxCompute+OpenSearch向量检索版:用户将图片通过base64编码后的图片及其表数据存储在MaxCompute中
- API+OpenSearch向量检索版:用户通过OpenSearch向量检索版给出的数据推送接口,将base64编码后的图片及其表数据推送到OpenSearch向量检索版实例中
(3)内置模型完成图片向量化
- 当前内置达摩院开源clip模型完成图像转向量
- 后续将内置更多可选模型
3.2 技术优势
优势一:高性能保障:自研的超高向量检索引擎
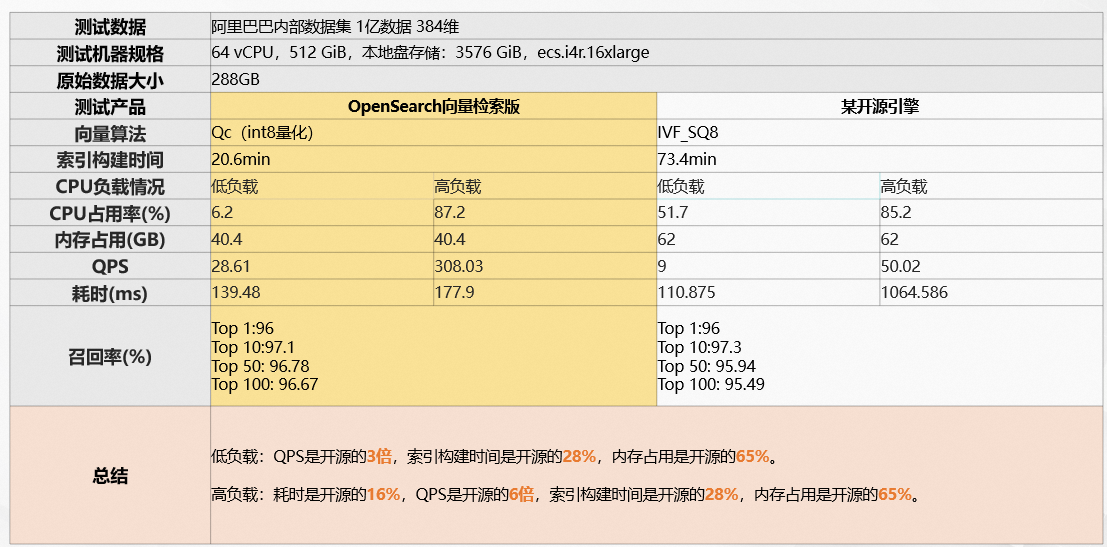
- OpenSearch向量检索版支持千亿数据毫秒级响应,实时数据更新秒级可见
- OpenSearch向量检索版的检索性能优于开源向量搜索引擎数倍,在高QPS场景下召回率明显优于开源向量搜索引擎
OpenSearch向量检索版VS开源引擎性能:中数据场景
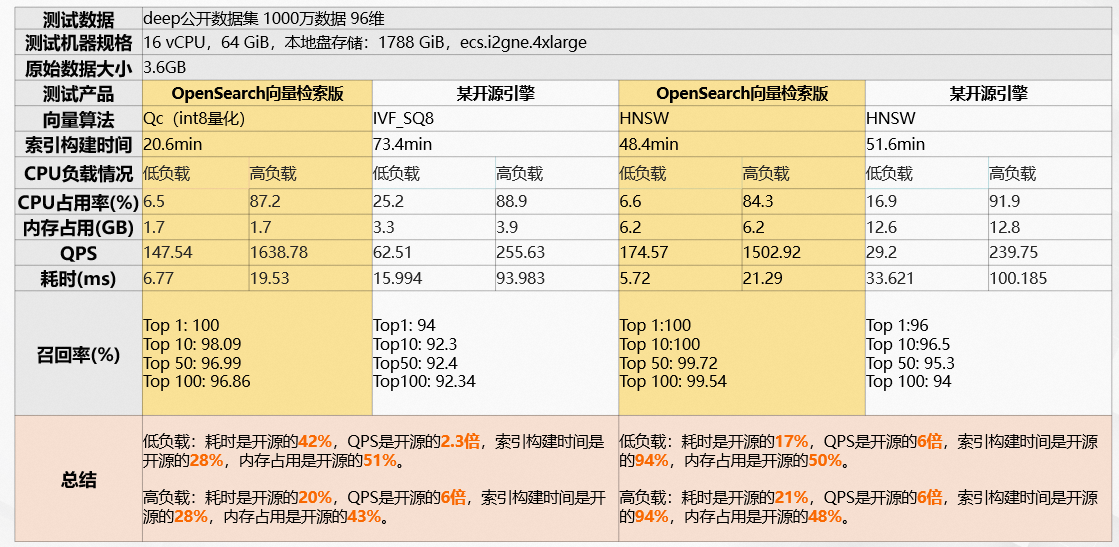
OpenSearch向量检索版VS开源引擎性能:大数据场景
优势二:低成本:采用多种方式优化存储成本、减少资源耗用
数据压缩:可将原始数据转化为float形式存储,并再采用zstd等高效算法进行数据压缩,实现存储成本优化
精细索引结构设计:针对不容类型索引,可采用不同优化策略,降低索引大小
非全内存加载:可以使用mmap非lock的形式加载索引,有效降低内存开销
引擎优势:OpenSearch向量检索版引擎本身具备构建索引大小、GPU资源耗用的优势,同等数据条件下,OpenSearch向量检索版内存占用仅为开源向量检索引擎的50%左右。
优势三:具有丰富的向量检索能力
- 支持HNSW、QC、Linear等多种向量检索算法
- 支持标签、文本倒排索引、向量索引的混合检索,提高检索性能与查询精度,下图举例说明按核心词混合检索、类别过滤前后的搜索效果对比:
-

优势四:支持按表达式过滤,具有边检索边过滤能力,能有效降低搜索无结果率,提升搜索效果

优势五:Query中支持设置,相似度阈值、扫描返回的节点数等参数,找到查询耗时与返回结果精度之间的最优解
优势六:大规模数据快速索引构建、支持实时更新、数据水平拓展
- 支持大规模向量快速导入与索引构建,单节点 348维 1亿向量,通过配置优化,可在3.5小时内完成全量构建
- 支持数据动态更新、即增即查、自动索引重建
- 支持数据水平扩展
3.3 产品配置流程
- 第一次开通阿里云账号并登录控制台,您需先创建AK和SK
- 产品支持MaxCompute数据源、API数据源,您需提前准备数据
- 购买OpenSearch向量检索版实例,系统自动部署与购买规格一致的空集群,您需为该集群「配置数据源、配置索引结构、索引重建」,之后才可正常搜索
- 在控制台查询测试页面或通过API/SDK,进行以文搜图效果测试;通过API/SDK进行以图搜图效果测试
- 通过API/SDK调用向量搜索服务
更多使用说明参考: :本文介绍如何通过OpenSearch【向量检索版】帮助企业在没有向量数据的情况下快速搭建图像搜索服务,解决图片向量化、向量搜索等检索难题,实现以图搜图、以文搜图等多种图像检索能力。并通过数据压缩功能,降低存储空间,降低业务成本,为企业提供效果、性能双保障。
3.4 客户案例
某电商客户,通过约15个工作日完成POC接入:
- 完成2亿级别768维向量数据的存储和索引构建,并支持增量更新无需重建索引
- 万级别数据,实现毫秒级检索响应,查询耗时对比自建方案降低50%
- 支持按条件查询、分类筛选、标签过滤的向量检索能力,满足灵活的业务场景需要