多目标跟踪算法:DeepSort
https://arxiv.org/pdf/1703.07402.pdf
https://github.com/ZQPei/deep_sort_pytorch
DeepSORT(Deep Learning-based SORT)是一种基于深度学习的多目标跟踪算法,用于在视频序列中跟踪多个目标并进行身份识别。它是SORT(Simple Online and Realtime Tracking)算法的扩展,可以处理遮挡、运动模糊和光照变化等复杂情况,因此在视频监控、交通管理和人员追踪等领域得到广泛应用。
DeepSORT基于卷积神经网络(CNN)和循环神经网络(RNN)等深度学习模型,可以从目标检测框中提取出目标的特征表示,并通过匈牙利算法和卡尔曼滤波等多种跟踪技术,对多个目标进行跟踪和身份识别。具体来说,DeepSORT包括以下几个步骤:
-
目标检测:使用目标检测算法(如YOLO、Faster R-CNN等)从视频帧中检测出所有目标,并生成对应的边界框。
-
目标特征提取:使用CNN等深度学习模型从每个目标的边界框中提取出特征向量,并将其输入到RNN中进行序列建模。
-
目标匹配:使用匈牙利算法计算两帧之间的目标匹配关系,并根据目标特征向量的相似度和卡尔曼滤波预测结果来确定匹配结果。
-
身份管理:为每个跟踪目标分配一个唯一的ID,并在跟踪过程中将其与先前的跟踪结果进行比较,以确保ID的唯一性和一致性。
DeepSORT通过融合深度学习和传统跟踪技术,可以实现高效、准确和稳定的多目标跟踪和身份识别,因此在实际应用中具有广泛的应用前景。
多目标追踪的主要步骤
- 获取原始视频帧;
- 利用目标检测器对视频帧中的目标进行检测;
- 将检测到的目标的框中的特征提取出来,该特征包括表观特征(方便特征对比避免ID switch)和运动特征(运动特征方便卡尔曼滤波对其进行预测);
- 计算前后两帧目标之前的匹配程度(利用匈牙利算法和级联匹配),为每个追踪到的目标分配ID。
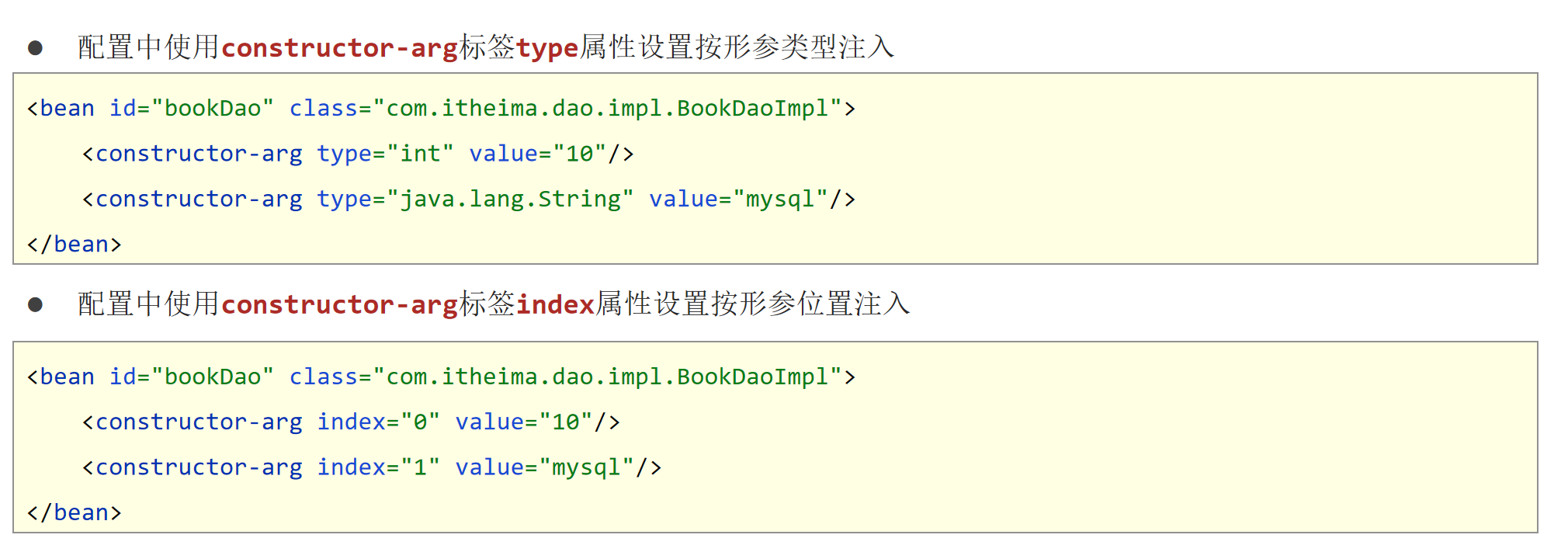
Sort 算法原理
- 卡尔曼滤波算法
该算法的主要作用就是当前的一系列运动变量去预测下一时刻的运动变量,但是第一次的检测结果用来初始化卡尔曼滤波的运动变量。
- 匈牙利算法
简单来讲就是解决分配问题,就是把一群检测框和卡尔曼预测的框做分配,让卡尔曼预测的框找到和自己最匹配的检测框,达到追踪的效果。
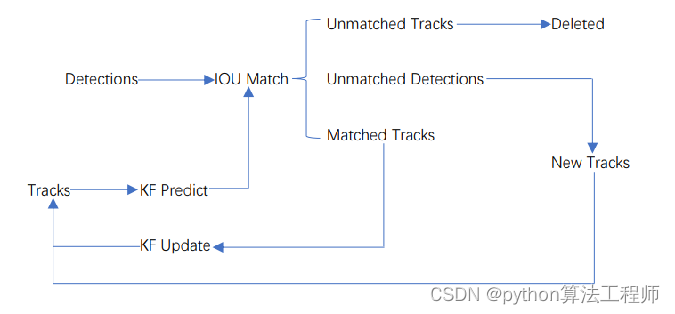
Detections是目标检测框
Tracks是轨迹信息(外观特征和运动信息)
什么是重识别(ReID)?
重识别(ReID)是一种计算机视觉任务,旨在识别不同位置、时间或摄像机中的同一对象。它通常应用于视频监控、人员管理和公共安全等领域。
在ReID中,模型需要从给定的图像或视频序列中提取出人物的特征向量,并将其与一个已知的人物数据库进行匹配,以确定该人物在数据库中的身份。与传统的人脸识别不同,ReID需要处理全身图像,因此需要考虑姿态、服装、光照等因素。
ReID通常包括以下几个步骤:
-
特征提取:使用深度学习模型(如ResNet、DenseNet等)从图像中提取出人物的特征向量。
-
特征匹配:使用一些度量方法(如欧氏距离、余弦相似度等)计算两个特征向量之间的相似度,并将其与一个已知的数据库进行比较。
-
单目标跟踪(可选):使用目标跟踪算法(如卡尔曼滤波、匈牙利算法等)跟踪单个目标,并在多个摄像机之间进行跨摄像机重识别。
-
多目标跟踪(可选):将单目标跟踪扩展到多个目标,以处理多人情况。
近年来,随着深度学习的发展,ReID已经取得了显著的进展,并在许多实际应用中得到了广泛应用。
上一帧
 当前帧
当前帧

什么是身份变换(IDswitch)?
在目标追踪中引入身份变换(IDswitch)是一种常见的技术,它可以实现目标的身份变换,从而应对目标在追踪过程中的遮挡、离开视野等问题。身份变换可以用于多种目标追踪场景,例如视频监控、智能交通和机器人导航等领域。
身份变换的实现通常包括以下几个步骤:
-
目标检测:使用目标检测算法(如YOLO、Faster R-CNN等)从视频帧中检测出目标,并生成对应的边界框。
-
目标跟踪:使用目标跟踪算法(如KCF、MOSSE等)追踪目标,并根据目标位置和运动状态等信息对目标进行预测。
-
身份变换:根据目标特征表示(如人脸特征、颜色特征等),将目标的身份进行变换。这通常需要使用图像合成技术(如身份变换、图像融合等)将目标的特征表示与目标图像进行融合,从而实现身份变换的效果。
-
身份管理:为每个目标分配一个唯一的ID,并在跟踪过程中将其与先前的跟踪结果进行比较,以确保ID的唯一性和一致性。
需要注意的是,身份变换技术可能存在一些误差和局限性,例如人脸姿态变化、光照变化和遮挡等问题。因此,在实际应用中,需要结合具体的场景和需求,选择合适的身份变换技术,并对算法进行严格的评估和验证。
id=001


id=001

如何进行多目标跟踪
- 如何对多目标进行跟踪
常见的跟踪策略就是track + detection
Track + Detection是一种常见的目标跟踪方法,它结合了目标检测和目标跟踪两种技术,可以在视频序列中实现高效、准确和稳定的目标追踪。
Track + Detection的基本思路是,首先使用目标检测算法(如YOLO、Faster R-CNN等)从每个视频帧中检测出所有目标,并为每个目标生成一个唯一的ID。然后,使用目标跟踪算法(如KCF、MOSSE等)对每个目标进行跟踪,并根据目标位置和运动状态等信息对目标进行预测。在下一帧视频中,重新使用目标检测算法检测目标,并利用匈牙利算法等技术将当前帧的目标与上一帧的目标进行匹配,从而实现目标跟踪的连续性和稳定性。
Track + Detection方法的优点在于,它可以利用目标检测算法的强大能力,检测出所有的目标,并为它们分配唯一的ID,从而避免了目标ID混淆的问题。同时,它结合了目标跟踪算法的优势,可以在目标运动状态不变或者轻微变化的情况下,实现高效、准确和连续的目标跟踪。
然而,Track + Detection方法也存在一些局限性,例如对于目标运动剧烈或者发生遮挡等情况,可能会导致目标跟踪失败。此外,由于目标检测算法和目标跟踪算法的计算复杂度较高,需要较高的计算资源和算法优化,才能在实时应用中实现高效的目标跟踪效果。
- 为什么选择与detection进行结合?
是因为目标检测算法大多是基于多目标的
选择与目标检测(detection)进行结合的原因有以下几点:
-
处理复杂场景:目标检测算法可以在复杂场景中检测出所有目标,包括遮挡、变形、光照变化等情况,从而可以更全面地捕捉目标信息。
-
解决ID混淆问题:在多目标跟踪过程中,可能会存在同一时刻出现多个目标的情况,使用目标检测算法可以为每个目标分配一个唯一的ID,避免ID混淆问题。
-
连续性和鲁棒性:目标检测算法可以为目标跟踪算法提供连续性和鲁棒性,即使目标跟踪算法在某些帧中跟踪失败,也可以通过重新检测目标来恢复跟踪。
-
实时性:目标检测算法可以在较短的时间内检测出目标,并提供目标位置和大小等信息,从而可以在实时应用中实现高效的目标跟踪。
综上所述,与目标检测进行结合可以提高多目标跟踪的准确性、鲁棒性和实时性,从而在各种实际场景中得到广泛应用,例如视频监控、智能交通、机器人导航等领域。
- 那么问题又来了,为什么不可以直接用detection进行多目标跟踪?
虽然目标检测算法可以检测出所有目标并提供目标位置信息,但是直接使用目标检测算法进行多目标跟踪仍然存在一些问题:
1. 目标ID混淆:在多目标跟踪过程中,可能会存在同一时刻出现多个目标的情况,如果直接使用目标检测算法进行跟踪,可能会导致目标ID混淆的问题。
2. 连续性和鲁棒性:目标检测算法通常只能在每个视频帧中检测出目标,无法跟踪目标的运动状态和轨迹,从而无法保证多目标跟踪的连续性和鲁棒性。
3. 计算复杂度:在多目标跟踪场景中,目标数量可能较多,直接使用目标检测算法进行跟踪会导致计算复杂度较高,无法实现实时性。
因此,为了解决这些问题,需要使用目标跟踪算法对目标进行跟踪,并结合目标检测算法进行多目标跟踪。通过结合两种算法的优势,可以提高多目标跟踪的准确性、鲁棒性和实时性,从而在各种实际场景中得到广泛应用。
(1)因为检测算法有时会出现漏检的情况;
(2)在跟踪算法中一旦跟踪丢了目标就很难再继续跟踪下去了;
(3)如果遇到漏检的情况,将失去身份ID。
对于跟踪,算法并不知道自己跟踪的目标内容是什么,它只负责跟踪,具体是什么并不需要知道,那么就会出现重识别(ReID)的问题。
DeepSort 算法原理
DeepSORT是一种基于深度学习的多目标跟踪算法,它是SORT(Simple Online and Realtime Tracking)算法的改进版,利用深度学习网络提取目标特征,结合卡尔曼滤波进行多目标跟踪。
DeepSORT的核心思想是将目标跟踪问题分解为目标检测和目标跟踪两个子问题。具体来说,DeepSORT首先使用目标检测算法(如YOLO、Faster R-CNN等)从视频帧中检测出所有目标,并为每个目标生成一个唯一的ID。然后,利用深度学习网络(如ResNet、DenseNet等)提取目标的特征向量,并计算当前目标与历史目标的相似度,从而将目标ID分配给最相似的历史目标。
为了解决目标跟踪中的运动模糊和遮挡问题,DeepSORT采用了卡尔曼滤波来预测目标运动状态,并对目标轨迹进行平滑处理。具体来说,DeepSORT利用卡尔曼滤波对目标位置和速度进行估计,并根据历史数据和当前观测值来更新目标状态。此外,DeepSORT还使用匈牙利算法来匹配当前帧的目标和上一帧的目标,从而实现目标跟踪的连续性和稳定性。
总之,DeepSORT算法的主要原理是结合深度学习特征提取和卡尔曼滤波预测,实现了高效、准确和稳定的多目标跟踪。它在各种实际场景中都有广泛的应用,例如视频监控、智能交通、机器人导航等领域。
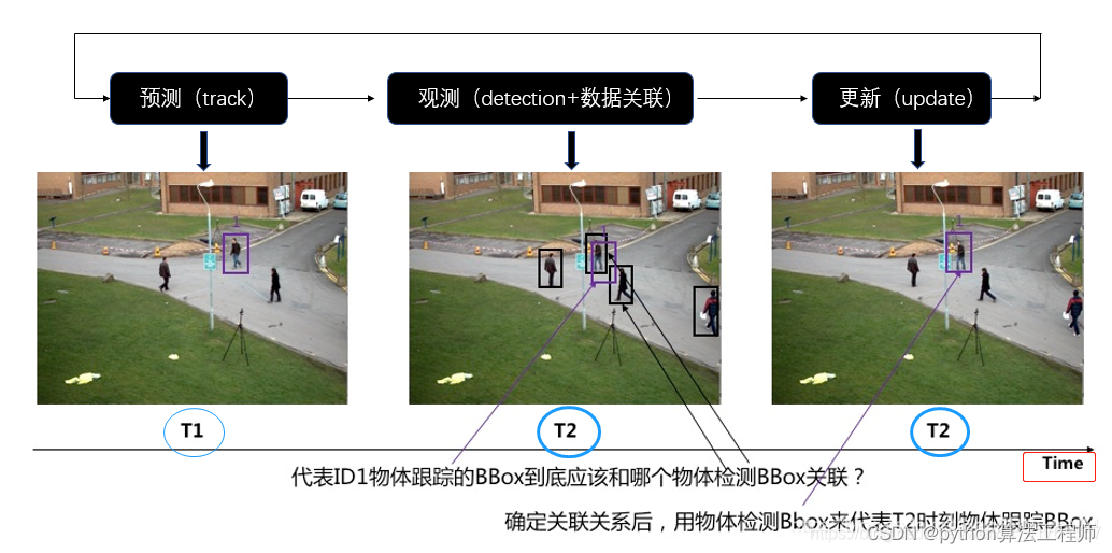 SORT算法
SORT算法
对身份变换的问题,仅仅采取框和框之间距离的匹配方式,没有考虑框内的内容,所以容易发生身份变换;
SORT算法只适用于遮挡情况少的、运动比较稳定的对象。
DeepSort的核心流程:
预测(track)——>观测(detection + 数据关联)——>更新
(1)预测:预测下一帧的目标的bbox,即后文中的tracks;
(2)观测:对当前帧进行目标检测,仅仅检测出目标并不能与上一帧的目标对应起来,所以还要进行数据关联;
(3)更新:预测bbox和检测bbox都会有误差,所以进行更新,更新后的跟踪结果通常比单纯预测或者单纯检测的误差小很多。
DeepSort流程图
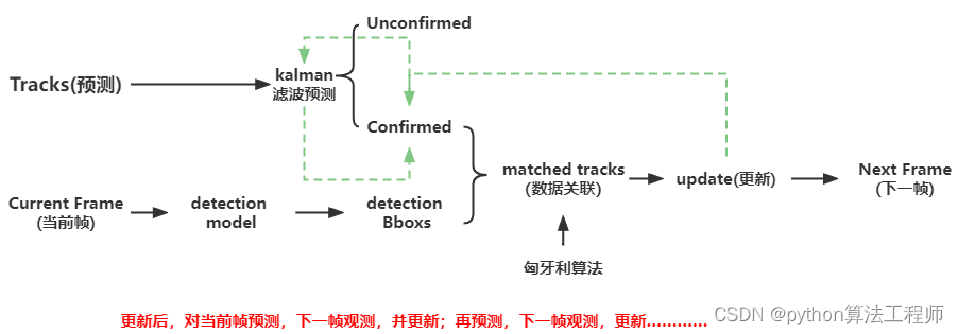 Tracks都会设置confirmed/unconfirmed,对于新建立的tracks,尚未确定是否就是真切存在的,万一是检测错的杂七杂八呢,所以将其设置为unconfirmed,并对其进行三次考察,如果是实际目标修改为confirmed,再进行 预测-观测-更新。
Tracks都会设置confirmed/unconfirmed,对于新建立的tracks,尚未确定是否就是真切存在的,万一是检测错的杂七杂八呢,所以将其设置为unconfirmed,并对其进行三次考察,如果是实际目标修改为confirmed,再进行 预测-观测-更新。
实际情况:
1、Tracks中的track匹配不到detection box;
2、detection box匹配不到 track;
如何解决?
解决办法:对于匹配不上的tracks和detection再次进行匹配
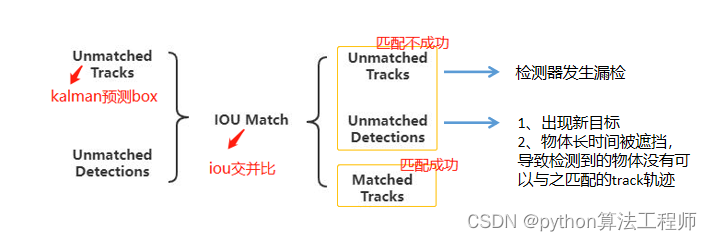 对于再次匹配也匹配不成功怎么办?
对于再次匹配也匹配不成功怎么办?
解决办法:对于再次匹配不上的detections建立一个new tracks
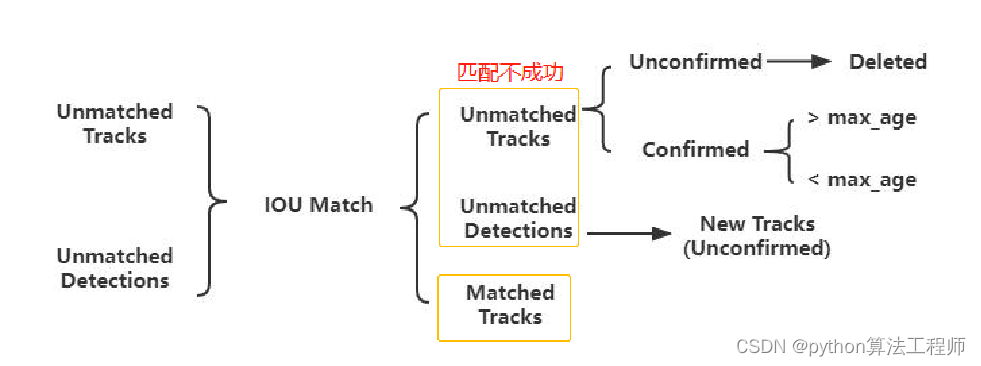 对于再次匹配依然失败的detections,前面讨论过detections匹配失败的原因可能是新出现的目标在之前没有它的轨迹tracks,或者长时遮挡的也没有轨迹tracks,所以对其建立一个new tracks,前面也提到,tracks都会设置confirmed/unconfirmed,对于新建立的tracks,尚未确定是否就是真切存在的,万一是检测错的杂七杂八呢,所以将其设置为unconfirmed,并对其进行三次考察,如果是实际目标修改为confirmed,再进行 预测-观测-更新。
对于再次匹配依然失败的detections,前面讨论过detections匹配失败的原因可能是新出现的目标在之前没有它的轨迹tracks,或者长时遮挡的也没有轨迹tracks,所以对其建立一个new tracks,前面也提到,tracks都会设置confirmed/unconfirmed,对于新建立的tracks,尚未确定是否就是真切存在的,万一是检测错的杂七杂八呢,所以将其设置为unconfirmed,并对其进行三次考察,如果是实际目标修改为confirmed,再进行 预测-观测-更新。
DeepSort 整体流程图
 Deepsort算法在sort算法的基础上增加了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。Tracks分为确认态(confirmed),和不确认态(unconfirmed),新产生的Tracks是不确认态的;不确认态的Tracks必须要和Detections连续匹配一定的次数(默认是3)才可以转化成确认态。确认态的Tracks必须和Detections连续失配一定次数(默认30次),才会被删除。
Deepsort算法在sort算法的基础上增加了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。Tracks分为确认态(confirmed),和不确认态(unconfirmed),新产生的Tracks是不确认态的;不确认态的Tracks必须要和Detections连续匹配一定的次数(默认是3)才可以转化成确认态。确认态的Tracks必须和Detections连续失配一定次数(默认30次),才会被删除。
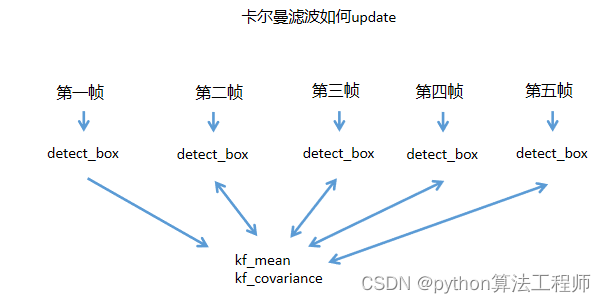
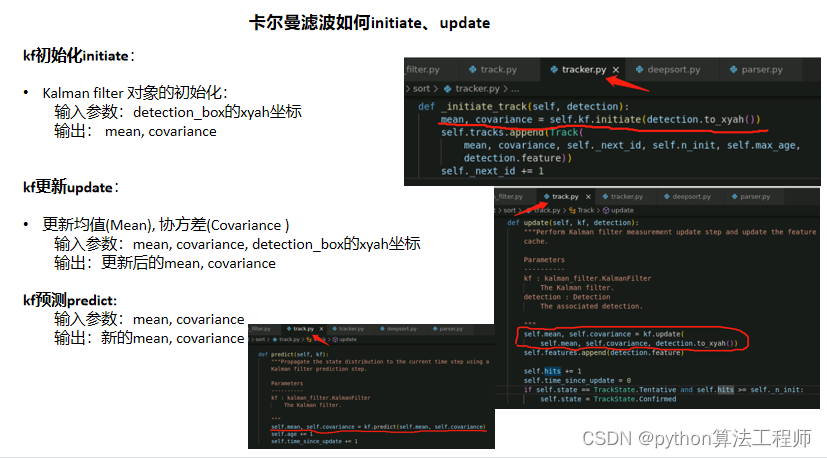
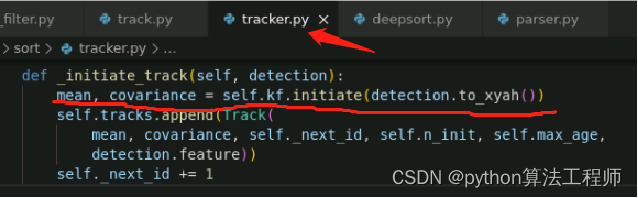
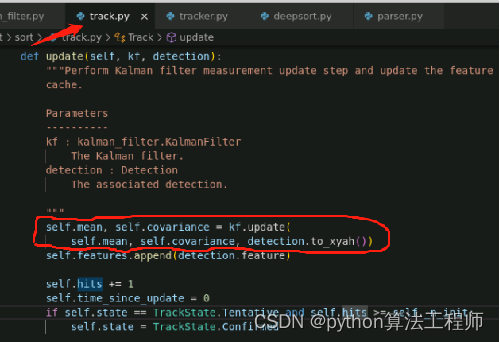
卡尔曼滤波参数
均值mean (8维)
作用:使用8个参数来描述bbox的运动状态 (x, y, a, h, vx, vy, va, vh)
x,y分别代表bbox的中心点坐标,a为bbox的宽高比,h为bbox的高度,以及它们在图像坐标中的速度
先验条件:物体运动遵循恒定速度模型。
初始化时,vx, vy, va, vh值为0。
协方差covariance(8*8矩阵)
作用:衡量两个变量的总体误差,来度量各个维度偏离其均值的程度。
协方差越大,表明预测的结果与真实值有较大的偏差,即估计值的可信度较低。




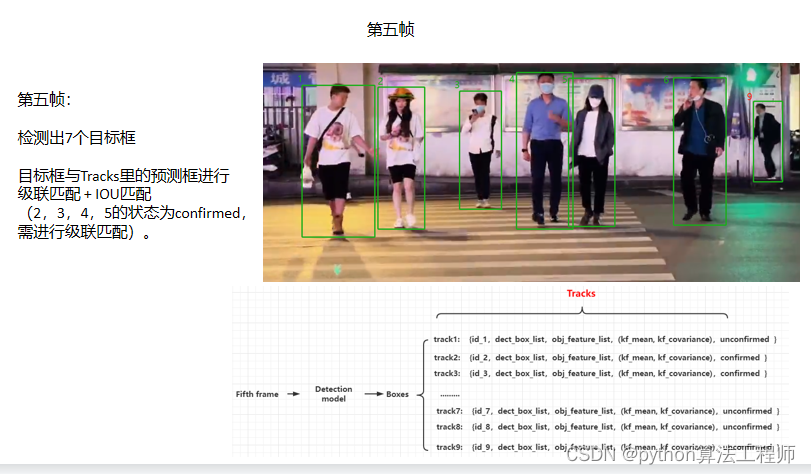
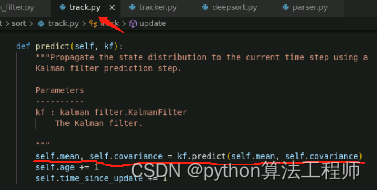
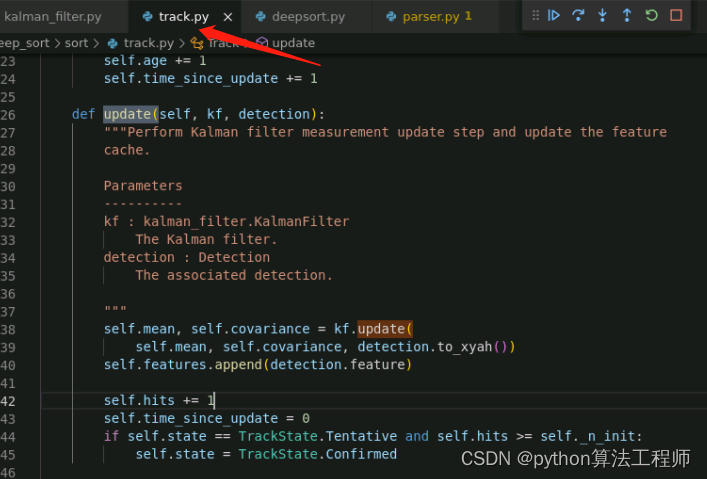
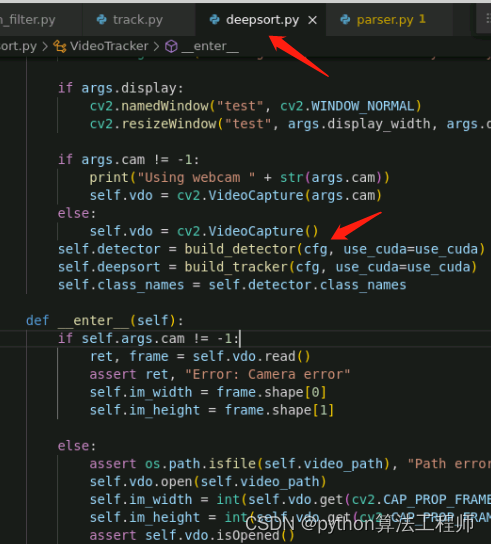
DeepSort 在自动驾驶方面的应用


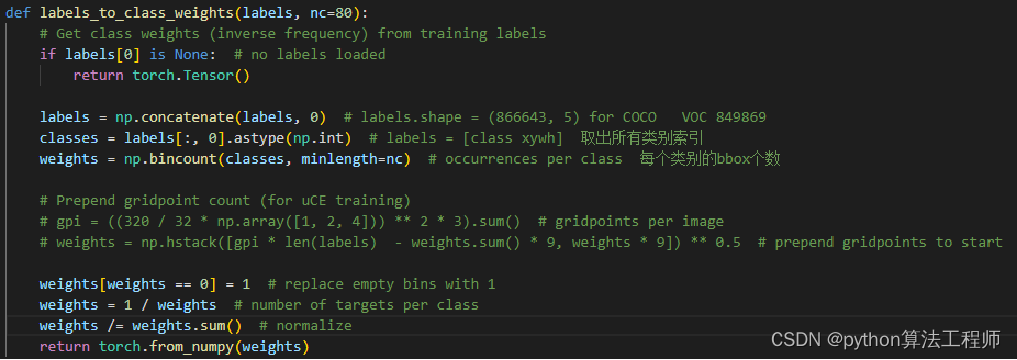
类权重系数和图像权重系数
解决问题:训练样本不均衡
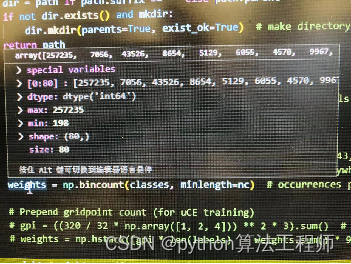
根据样本种类分布,通过不同的图像采样频率的方法来解决样本不均衡的问题。
1、将样本中的ground truth读出来,存为一个列表;
2、统计训练样本列表中不同类别的矩形框个数,然后给每个类别按相应目标框数的倒数赋值,(数目越多的种类权重越小),形成按种类的分布直方图;
3、对于训练数据列表,每个epoch训练按照类别权重筛选出每类的图像作为训练数据,如使用
random.choice(population, weights=None, *, cum_weights=None, k=1)更改训练图像索引,可达到样本均衡的效果。
类别权重
当训练图像的所有类个数不相同时,我们可以更改类权重, 即而达到更改图像权重的目的;然后根据图像权重新采集数据,这在图像类别不均衡的数据下尤其重要。
训练自己的数据集时,各类别的标签数量难免存在不平衡的问题,在训练过程中为了就减小类别不平衡问题的影响,就引入了类别权重和图像权重的设置。

图像权重
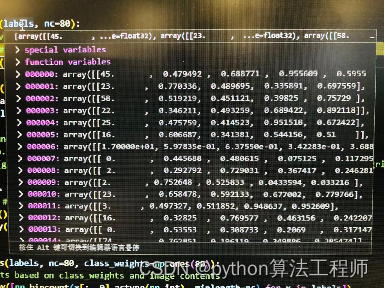
若类别权重已经更改了,每张图像包含了多个类,因此对应图像的权重也会随之而变. 默认的图像权重都为1。
计算每个图像所有类权重之和,即为图像权重;
若图像权重越大,那么该图像被采样的概率也越大;反之,则越小。


1、统计每张图中标签的数量,并且把统计结果转换为ndarray格式
2、每张图片对图中的每个标签的权重求和即为图片的权重
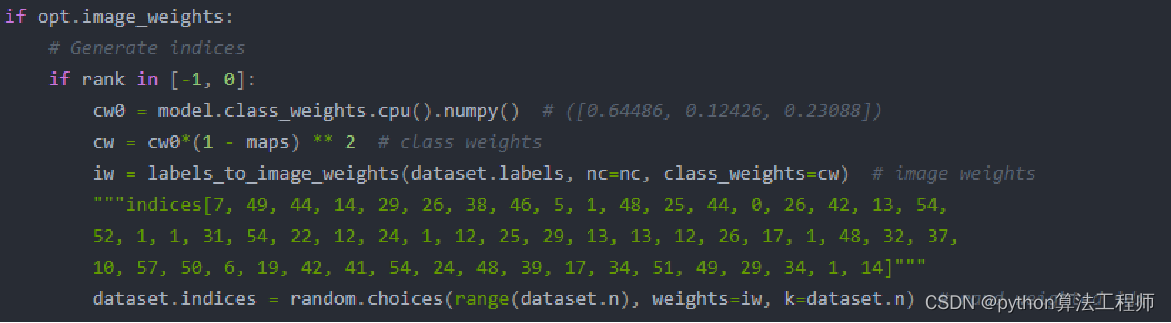 利用random.choices根据图像的权重选取图片,每次选取和训练集相同的图片数。
利用random.choices根据图像的权重选取图片,每次选取和训练集相同的图片数。
也就意味着训练集中的图片权重大的有的可能会被选取多次,权重小的可能一次都不会被选中用于训练。
多目标跟踪 ByteTrack
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
https://arxiv.org/pdf/2110.06864.pdf
https://github.com/ifzhang/ByteTrack
ByteTrack、DeepSort、Sort的区别
ByteTrack
1、卡尔曼滤波
2、IOU匹配(包含匈牙利算法)
DeepSort
1、有目标特征feature
2、有卡尔曼滤波、级联匹配、IOU匹配(包含匈牙利算法)
Sort
1、卡尔曼滤波、IOU匹配(包含匈牙利算法)
问题引入:
1、由于现实场景的复杂性,检测器无法得到完美的检测结果。
2、大部分的目标检测场景,会选择一个阈值(一般设置的检测置信度阈值为0.5左右),只保留高于这个阈值的检测结果, 然后和现有的跟踪轨迹进行关联匹配,低于这个阈值的检测结果直接丢弃。
3、低分检测框往往预示着物体的存在(例如遮挡严重的物体),简单地把这些物体丢弃会给跟踪带来不可逆转的错误,包括大量的漏检和轨迹中断,降低整体跟踪性能。
解决问题:
1、多目标追踪场景中,大部分遮挡物体的检测结果都是低分框;
2、ByteTrack非常简洁的从低分检测框中寻找遮挡的物体,对遮挡非常鲁棒。
BYTE
为了解决丢弃低分检测框的不合理性,我们提出了一种简单、高效、通用的数据关联方法BYTE。
直接地将低分框和高分框放在一起与轨迹关联显然是不可取的,会带来很多的背景(false positive)。BYTE将高分框和低分框分开处理,利用低分检测框和跟踪轨迹之间的相似性,从低分框中挖掘出真正的物体,过滤掉背景
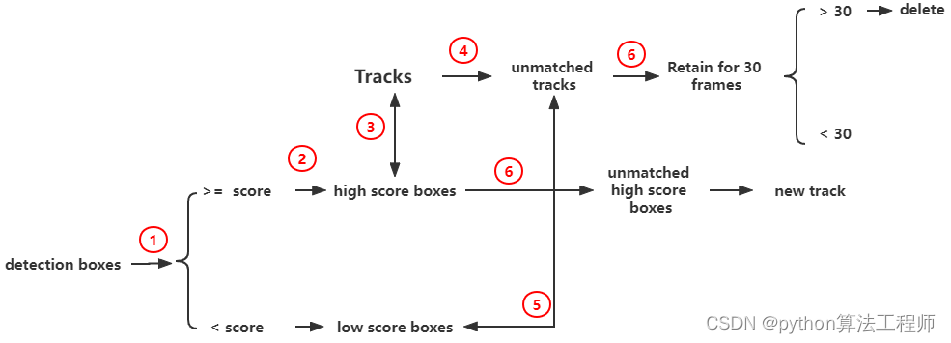
BYTE 步骤
1、Byte中,将检测框按照一定阈值划分为高分框和低分框。
2、对于高分框来说,按照正常的方法与所有跟踪轨迹(Tracks)进行匹配,即使用IOU计算代价矩阵,然后利用匈牙利算法进行分配。
3、对于低分框,将2中未匹配上的轨迹(unmatched tracks)与其进行IOU匹配,然后同样利用匈牙利算法进行分配。
4、对于没有匹配上轨迹的高分框,建立一个新的跟踪轨迹。对于没有匹配检测框的跟踪轨迹,保留30帧,以便于后面再次匹配
作者认为,对于视频或者图片流来说,未匹配上的轨迹,大概率是这帧这个物体被遮挡或者走出画面了导致的。所以作者利用低分框和未匹配上的框进行再匹配,来减缓遮挡导致目标丢失的问题。
 以上图举例的话,这里我们假设把阈值设置为0.3,在第一帧和第二帧中都可以将图片中的三个行人正确识别,但当第三帧中出现了遮挡现象,其中一个行人的置信度则变为0.1,这样这个行人则会在遮挡的情况下,失去了跟踪信息,但对与目标检测来说,他确实被检测出来了,只是置信度较低而已。
以上图举例的话,这里我们假设把阈值设置为0.3,在第一帧和第二帧中都可以将图片中的三个行人正确识别,但当第三帧中出现了遮挡现象,其中一个行人的置信度则变为0.1,这样这个行人则会在遮挡的情况下,失去了跟踪信息,但对与目标检测来说,他确实被检测出来了,只是置信度较低而已。
Byte算法则是用来解决如何充分利用,由于遮挡导致置信度变低的得分框问题。
ByteTrack
目标检测器:YOLOX
在数据关联的过程中,和SORT一样,只使用卡尔曼滤波来预测当前帧的跟踪轨迹在下一帧的位置,预测的框和实际的检测框之间的IoU作为两次匹配时的相似度,通过匈牙利算法完成匹配。
ByteTrack只使用运动模型没有使用外观相似度(即不再需要特征提取网络,因为在检测结果足够好的情况下,卡尔曼滤波的预测准确性非常高)。
在ByteTrack中对与目标检测网络的预测置信度阈值设置为了0.001。
好处:
尽可能做到简单高速
目标跟踪扩展
分类任务
我们希望最终训练出的模型,分类正确,同时:
1、把不同类之间分得很开;(拉大类间距离)
2、同类之间靠得比较紧密;(缩小类内距离)
实际情况:
特征距离很近的图像,其实是不同类别;
特征距离很远的图像,其实是同一类别。
Triple loss 三元组损失
Triplet loss 是深度学习的一种损失函数,主要是针对训练样本差异小的问题,比如人脸,细粒度分类等;
常见分类:对大类进行分类
 细粒度分类:对大类再次进行细分
细粒度分类:对大类再次进行细分





Triple loss
Triplet结构:
triplet是指的是三元组:Anchor、Positive、Negative
整个训练过程是:
首先从训练集中随机选一个样本,称为Anchor(记为x_a)。
然后再随机选取一个和Anchor属于同一类的样本,称为Positive (记为x_p)
最后再随机选取一个和Anchor属于不同类的样本,称为Negative (记为x_n)
由此构成一个(Anchor,Positive,Negative)三元组。
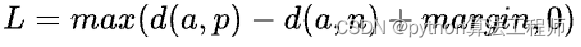 margin是一个大于0的常数
margin是一个大于0的常数
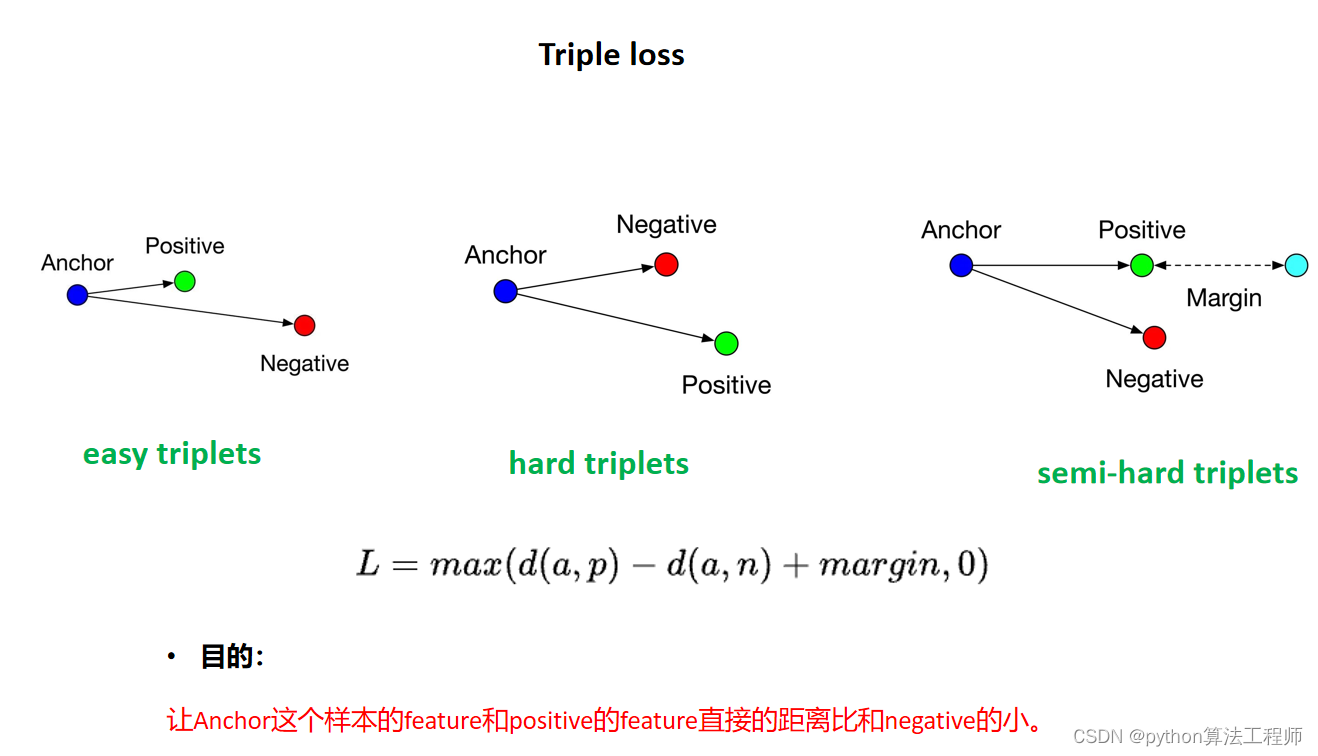


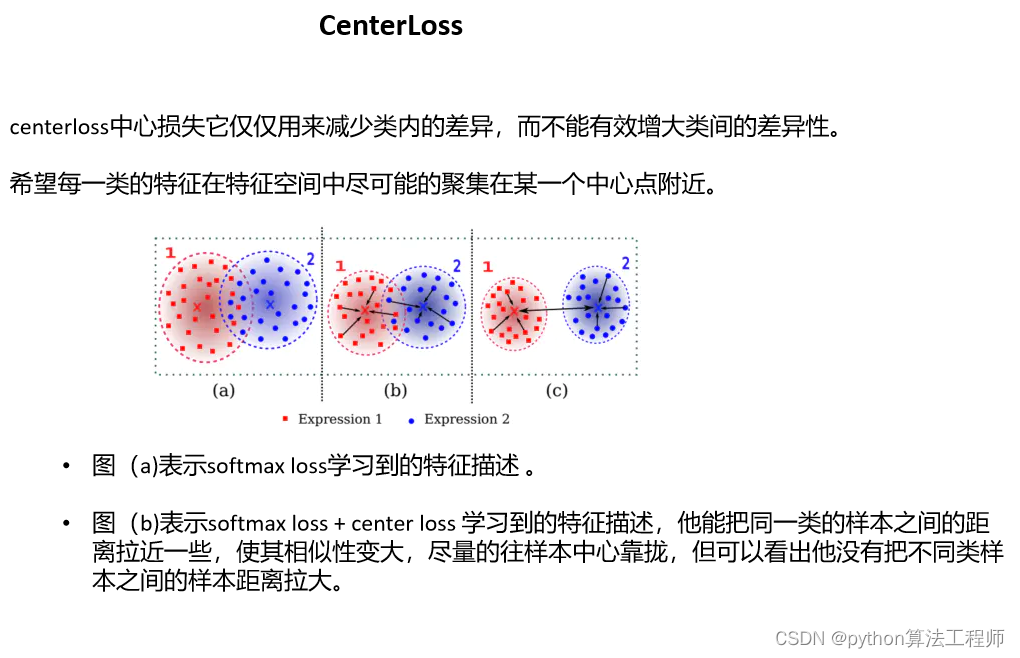 训练时要使用2个Loss函数:Softmax Loss + lamda * Center Loss
训练时要使用2个Loss函数:Softmax Loss + lamda * Center Loss
训练单一类别的数据增广
1、加入非同类的公开数据集
2、随机增广(随机背景crop)

红框: 真实GT框
绿框: 保留的随机背景框
蓝框:舍弃的随机背景框
![[pgrx开发postgresql数据库扩展]4.基本计算函数的编写与性能对比](https://img-blog.csdnimg.cn/img_convert/f73ef4056ed25f9a06b2c6f77a830158.webp?x-oss-process=image/format,png)