前言
再次声明:
并不是所有场景都需要(或者适合)用rust来写的,绝大部分操作数据库的功能和计算,用SQL就已经足够了!
本系列中,所有的案例,仅用于说明pgrx的能力,而并非是说这样做比用SQL更合适。反之:对于操作数据库本身的部分,大部分能用SQL来实现的东西,都比做一个扩展开发要更加合适。
——如果哪位大神写Rust走火入魔,说啥数据库功能都要用Rust来扩展实现的,不报我的名字,你们打成半死就行,报我的名字,请打成八成死。

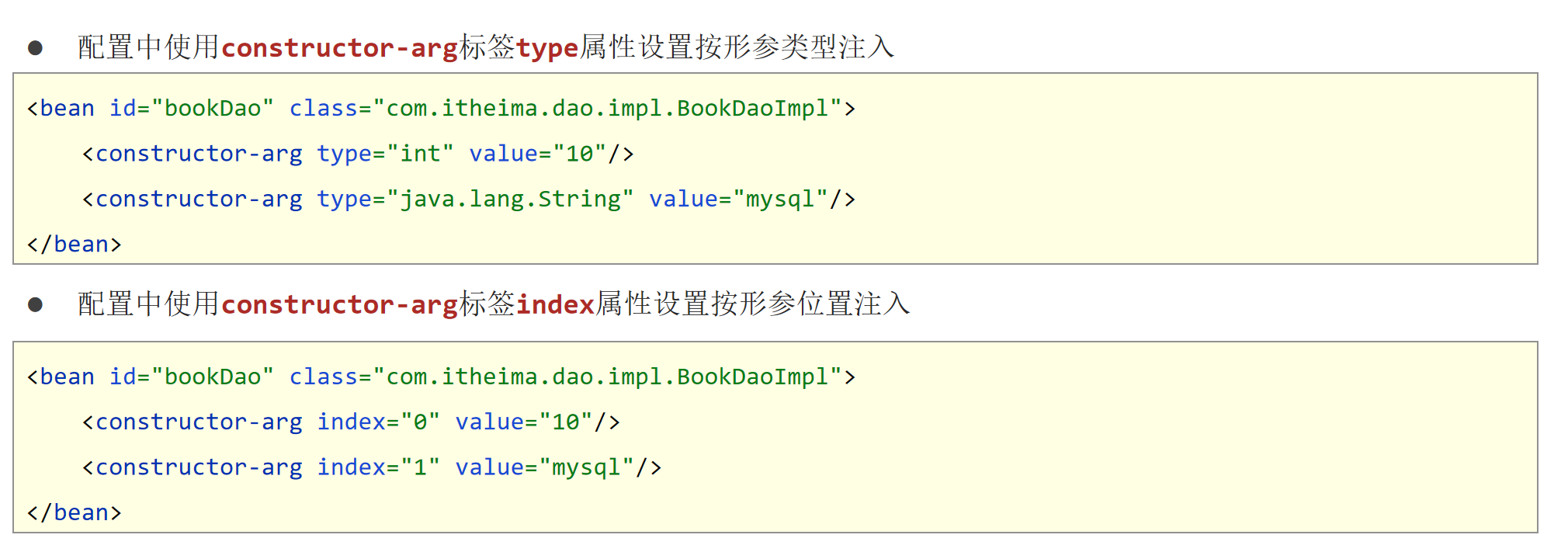
单值输入与输出函数
这里的单值,是针对序列这种多值类型而言的。
SQL做为第四代语言,与第三代语言最大的区别,就是尽量舍弃了所谓的计算机思维,即for和if。
例如我们在高级语言里面对一批数据要进行查询或者筛选,必须是按照计算机的思维方式来进行:
例如老板说,我们准备找出大于35岁的同学,以向社会进行输送,那么程序员要实现这个想法,就得这样思考和实现问题: 对整个数据集进行一个个的迭代,然后一个个的比较,如果满足条件,就进行社会输出……
for row in dataset:
if row['age'] > 35:
row["结果"] = "输送社会"
else:
row["结果"] = "在用几年"但是SQL里面,要实现这个功能,则不会有for和if这类语句:
select * from dataset where age > 35有正如高级语言要执行,先要被编译器编译成汇编,然后再编译成机器语言再进行执行意义,SQL要执行,实际上也要别数据库引擎编译成汇编指令和机器语言,那么依然可以是可以解读为for和if的。
例如,我们写了这样一个数据库扩展:
#[pg_extern]
fn age_add(age:i32) -> i32 {
age +1
}
来看看效果,非常直观:
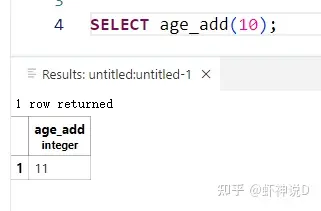
那么在实际使用中,比如要作用于数据库表格上的话,是什么样子呢?
先有这样一张表:

如果我们把自定义的函数作用在这张表上的时候,就是这样的:
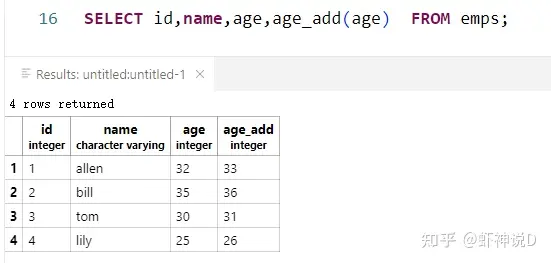
可以看见,相当于对于表emps进行逐行的迭代计算,然后得到了结果。
当然,这种功能肯定没必要用扩展这种牛刀杀鸡的做法,直接用SQL就可以了:
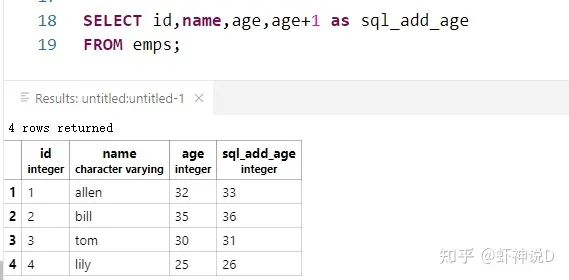
下面我们来做一个稍微复杂点的场景:
有如下这样一张表:

这是一个员工信息表有五个字段,分别id,名称、加入公司的时间、生日和工资,一共是20万条记录:我用Python的faker库生成的,当然没来得及去关注入职时间和生日之间的相关关系,里面肯定有没满18岁就参加工作的问题……就不要在意这些细节了。

现在我们要计算一下年终奖金的系数,规则如下:
基数为2,也就是两个月工资,如果在公司超过10年,每年加1.5个点,如果不满10年,则每年1个点,不满一年的按基准算,最后用系数乘以工资,得到最后的奖金。
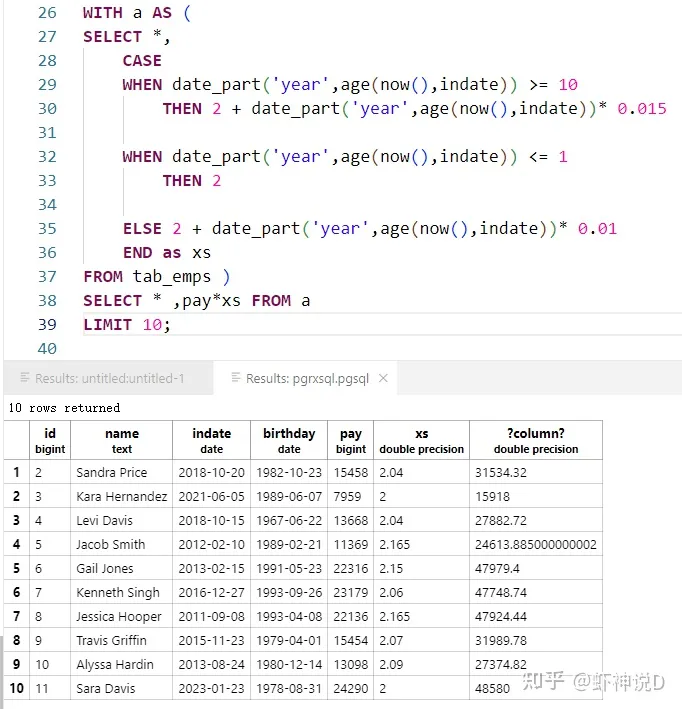
这个场景在业务编码里面经常见到,虽然很简单,但是包含了多条件判断、时间计算和数学计算等多种计算模型,当然……用SQL本身就很容实现,如下所示:
WITH a AS (
SELECT *,
CASE
WHEN date_part('year',age(now(),indate)) >= 10
THEN 2 + date_part('year',age(now(),indate))* 0.015
WHEN date_part('year',age(now(),indate)) <= 1
THEN 2
ELSE 2 + date_part('year',age(now(),indate))* 0.01
END as xs
FROM tab_emps )
SELECT * ,pay*xs FROM a
LIMIT 10; 结果如下:
那么我们在扩展函数里面写怎么做呢? (再次强调,仅为说明能力,绝对不是建议大家这种功能小功能也动用扩展函数来牛刀杀鸡)
代码如下:
#[pg_extern]
fn cal_bonus(indate:pgrx::Date,pay:i64) -> f32{
let now: DateTime<Local> = Local::now();
let now_epoch = now.timestamp()/60/60/24;
let x = (now_epoch as i32 - indate.to_unix_epoch_days()) / 365 ;
let mut xs:f32=0.0;
if x >=10{
xs = 2.0 + x as f32 * 0.015;
}
else if x <=1 {
xs = 2.0;
}
else{
xs = 2.0 + x as f32 * 0.01;
}
xs * pay as f32
}
结果如下:
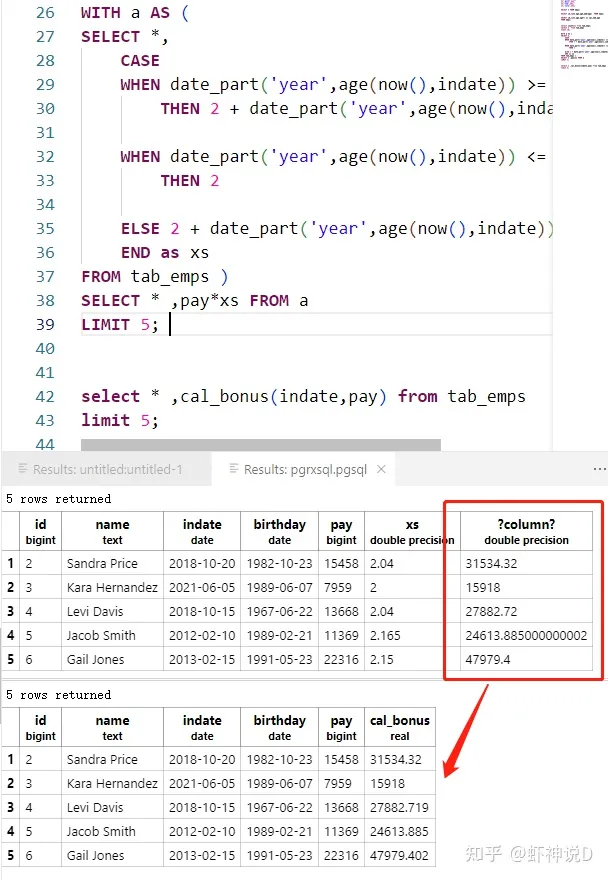
可以看见二者的结果是完全一样的。
性能对比
我们来具体对比一下,使用SQL原生方式和与扩展函数两种方式,在PG上面的执行效率,我们采用EXPLAIN ANALYZE的方式来测试效率:
- 对于加1方法的测试:
为了复用建立出来的20万条记录的表格,所以我们需要修改一下方法: 把输入参数从i32改成i64——rust是一种强类型的语言,所以数据库中的integer和bigint是无法通用。
当然,我们也可以用泛型来做,不过既然本教程针对的是初学者,这里我就不用了,以免增加学习负担。
#[pg_extern] fn age_add(age:i64) -> i64 { age +1 }
结果如下:
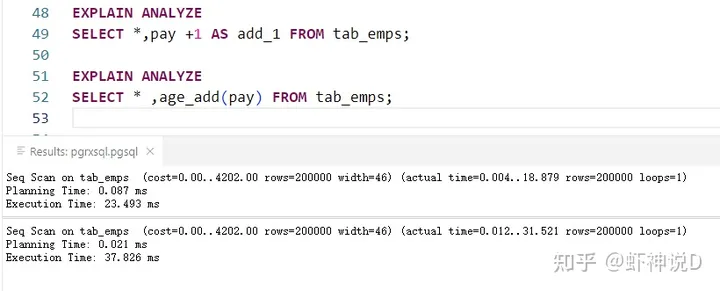
我们发现,对于20万条数据,用SQL执行加1操作,仅用了23ms,而采用扩展函数,则需要用37ms。
接下去,我们分别测试更新和插入,用两种方法,生成一张新的表格,然后在做一次更新,分别来看看性能:
CREATE AS SELECT的性能:


依然是原生SQL性能更好
然后看看UPDATE的性能:
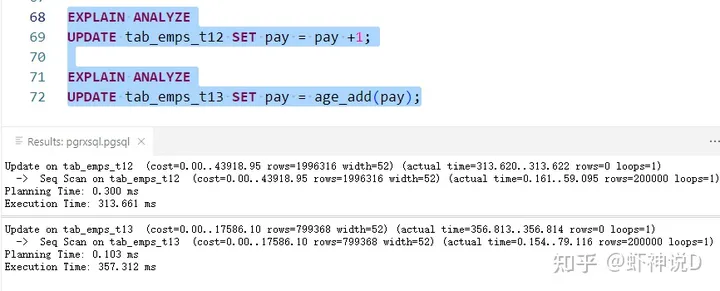
三个测试的结果如下:

然后我们再来测试一下稍微复杂点的系数与奖金计算:
查询

创建:

更新 (原生SQL的子查询模式更新,实在太慢了,20万条没有执行成功,所以我把数量缩减到了1000条,也有可能是我SQL语句没写对……因为以前没有搞过子查询模式的更新这种东西,如果哪位大神写过,可以联系我……)


而让我感到震惊的是,使用扩展函数编写的更新,对于20万条数据,整体执行的时间如下:

对比如下:
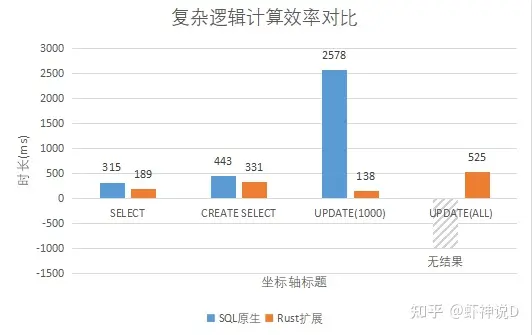
结论
- 简单计算和查询,SQL语言比扩展模式性能更好。
- 复杂计算和查询,随着数据量的变大,Rust扩展模式越发显示出优势,可能是因为在SQL里面也需要调用底层语言编写的函数,而导致转换间的性能损失吧。
- 如果有复杂计算且更新的需求,扩展函数的性能比原生SQL要好太多太多……可能并非是性能,而是运行机制的问题,此结论因为虾神SQL能力不行,所以不可靠。
- 不管是原生SQL模式还是扩展函数模式,一定都比DBC(Database Connectivity)模式要强很多很多……
待续未完。