首先,讲一下数据库国产化的大背景。
一、数据库国产化的背景
国家战略方面的,随着外部形势的日益复杂,核心技术急需实现自主可控、安全可靠、高效开放;另一个要求是业务方面的,当业务高速发展后各种问题会接踵而至,单机数据库达到瓶颈,业务拆分、垂直拆分、水平拆分等,都需要花费大量的研发时间。
二、主流的数据库架构
首先和大家分享一下目前主流的数据库架构。目前业内主流的数据库架构大体分为三类:Shared-Everything、Shared-Nothing,Shared-Storage。

-
Shared-Everything
这一种架构可能大家都比较熟悉,是很经典的一个架构,主机上的所有进程共享CPU、内存、IO,任意一个硬件达到了瓶颈,也就意味着数据库达到了瓶颈。
-
Shared-Nothing
这里可以再细分出两个架构,一种是基于 Proxy 的架构,这个架构由传统的单机数据库演变而来,当我们单机数据库达到瓶颈以后,我们再往上加一层 Proxy,通过 Proxy 把我们的数据打散到不同的节点上,以此来解决数据扩展性问题;另一种 Shared-Nothing 架构,是目前在国内比较火的像 TiDB、OB 这样的数据库。
-
Shared-Storage
这种架构在业内比较有名的是的 Aurora,还有目前在国内也比较火的阿里的 PolarDB。
首先,先详细介绍一下 Shared-Everything 架构。这个架构可能大家都比较熟悉,它是一种传统的单机数据库架构,当我们的数据库达到瓶颈以后,我们通常会采用各种各样的方式把我们的数据打散到各个 set 里面去,以此来解决数据库当地容量上限的问题。
有很多公司会通过这种方式来实现,把应用层、接入层、网关层都根据同样的分片逻辑,把数据整合到一个 set 里面,从而实现数据在 set 里面的闭环。通过这样的一套架构能做非常多有意思的事情。比如一些全链路在线的压测,因为数据已经在一个 set 里面不闭环了,如果我在一个测试 set 里面做数据压测,它不会污染到线上真实的数据,还可以做一些向线上的灰度引流、灰度发版等。
Shared-Storage 架构中,目前在国外做得特别好的是 AWS 的Aurora,在国内做得比较好的是阿里的 PolarDB。因为它对数据库研发投入非常高,同时需要依托底层一个非常强大的底座,所以一开始这些数据库推出来之后,像 Aurora 至今都是只支持在云上部署。
Shared-Nothing 架构,大家已经比较熟悉了,我们传统的数据库达到瓶颈演进后,单机解决不了性能、容量问题,于是就加一层Proxy,在 Proxy 上做各种各样的路由,这样的架构慢慢地演进到现在。国内有非常多基于这样的架构去演化出来的数据库,目前移动用的比较多的数据库都是类似的架构。
这套架构主要可以分成三类组件:
GTM 组件负责全局的协调,主要用来取协调分布式事务的管理,包括全局 ID 的生成活跃,GTE ID 的快照等等。
Proxy/计算节点。一开始 Proxy 这一层可能只是简单做数据的路由,但是后面随着整个数据库架构的演进,Proxy 这一层也承担起一定的计算能力,包括分布式事务的优化、计算的下推,还有一些 SQL 解析等。
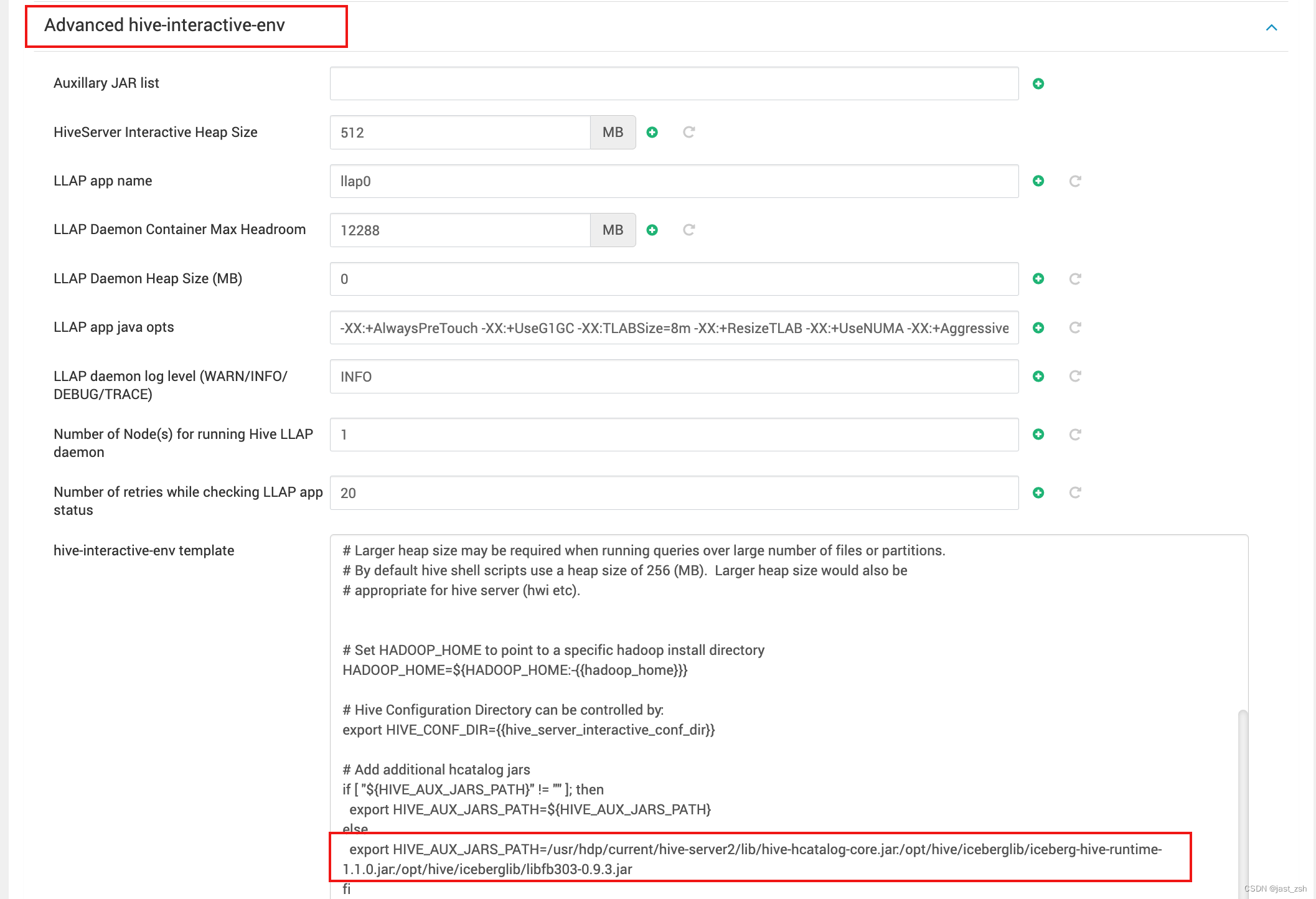
底层的存储节点,大多数目前都是基于开源的数据库去做二次开发,目前比较常见的就是 MySQL 和 PostgreSQL。它的架构的好处就是比较成熟稳定。但是它的坏处就是整个改造的过程非常痛苦,因为我们在整个改造的过程中,第一步需要去选取分片键,然后根据我们的分片键把数据打散到不同的节点上去,这一步就足以让业务抓狂。
Shared-Nothing 的另外一种架构是刚刚提到的OB、TiDB。这里以TiDB为例, TiDB是基于谷歌的论文去开发的一套分布式数据库。这个数据库它分成三层,调度层PD,计算节点TiDB,然后是底层的存储节点TiKV。
但是TiDB它在使用的过程中不需要显式地去指定分片键,它数据的分片拆分都是与依托于底下的数据库自动去完成的,所以采用这样的架构的话,改造成本可能会相对于低一些。
小结,以上提到的四种数据库架构,可以看到它们在扩展性层面,除了第一种没办法做到动态横向扩容,后面的三种其实只要改造完了,基本上都能做到数据层的横向扩容。
在一致性方面,第一种和最后一种基本上都是依托于半同步去保证各个节点之间的一致性。中间这两类数据库一般都是用了分布式一致性协议,目前用的比较多的是 Paxio协议,还有的 Raft 协议。
下面,跟大家分享我们在数据库国产化挑战与探索上的一些实践经验。
三、数据库国产化挑战与探索
业务逻辑和数据层的深度绑定是我们整个数据库改造过程中最头疼的一个点,于是出现了各种各样的数据库迁移方案,总结下来无非是以下七步:选型、测试、同步、改造、灰度、上线、保障。

首先是选型阶段,我们关注更多的是稳定性、效率、成本以及生态。选型阶段是一个很重要的阶段,因为如果选型选得好,可以极大地降低我们在后面数据库国产化改造的过程中的成本。但是很多时候我们在做数据库改造的过程中,选型阶段除了考虑技术的因素外,还有很多非技术的因素需要去考虑,所以最后我们只能在有限的范围内选出最优解。不能指望在选型阶段就把整个数据库国产化改造中的所有问题都一并解决掉。
紧接着是测试阶段,我们拿到一块数据库之后,可能会做各种各样的测试,比如基础功能测试、可用性测试、可维护性测试,还有一些基础的性能测试等。但是哪怕我们做了这样的测试以后,也不能保证这套数据库可以满足业务的需求,更多的是我们在做完这样的一些测试之后,淘汰一些不满足我们需求的一些数据库。如果我们想筛选出哪些数据库能基本符合我们的要求,可能还要结合一些线上的流量录制以及流量回放的一些东西。
数据同步这里可以稍微展开讲一下,这一块主要是分为全量数据同步和增量数据同步,我强烈建议大家在做这种大数据量的迁移时候,不要上来就去研究全备要用物理备份还是逻辑备份,哪个工具强,哪个工具差。第一步更多的是需要去分析一下自己的业务,分析自己的库表、业务逻辑是怎样的、数据到底是怎么分布的,哪些是历史数据、热数据、冷数据,哪些数据是可以现在立马要迁移的、哪些数据是可以放到放到后面慢慢迁的……在做完这样的数据分析之后,再来做全量和增量的数据迁移,往往可以做到事半功倍。

在增量同步这一块,我们内部也开发了类似的一个增量数据的同步工具。它是去监听了数据库变化的日志,然后把这些变化通过通过中间件的方式写到像 Kafka 这样的消息中间件,然后有需求的业务再去定从我们的中间件里面去订阅。
通过这样的一个工具能做非常多有意思的事情。像我们刚刚提到的数据迁移,那么可以通过这些工具的来做异构数据的同步,还可以做一些像数据库当缓存之间的同步,或者是说 OLTP 向 OlAP之间的同步等等。通过这个工具能解决非常多的业务的痛点。
业务改造这一块也是非常痛苦的一个点。我们改造的关键点主要分两块,一块是应用,应用这一块更多的是关注一些驱动程序、语法兼容、数据对象等等、API、 SQL 等等的一些东西。数据库这一层更多的是关注一些像数据分片、冷热分离、轻重隔离、SQL优化、读写分离等等这一些的东西。
这个适配改造我们目前改造的积累下来的需要关注的点,已经到大几十项了,所以这里我也没有详细地列出来,只是稍微地把它汇总了一下。我刚刚在前面几页提到的就是数据库国产化改造中最大的一个痛点就是业务逻辑和数据库的深度耦合,把这个问题给解决掉。所以我们在改造的过程中逐步地把那个 DB 给弱化成一个简单的存储,然后明确应用和数据之间的一个边界,然后再去做各种各样的适配改造。
通过这一系列操作把数据库国产化的这件事情,也作为我们整一个架构的梳理和优化。切换方案这里可以稍微简单地提一下。我们的切换方案主要有两种,目前这两种方案都有在用:第一种是基于数据层的中间件的方案,这种方案相对而言会比较简单一些,另一种方案是基于应用的双写方案,这种方案可能相对比较复杂,但是这种稳定性和安全性要求会对稳定性和要求的保障会更好一些。

我先简单介绍一下基于数据层的切换,一开始我们的应用可能都是直接连到我们的 DB,中间有一些 VIP 的东西,我直接给它省略掉。开始我们给它加了一层中间件,从第一步到第二步之间,因为中间件指向的也是我们的这个DB,所以研发可以慢慢地去改。这个改造的过程耗费十天半个月都没有关系,这它对业务是不会有任何的影响的。当我们把所有的流量都切到中间件以后,我们在数据库这一层去抓包,确保我们的那个请求全部都是通过中间件来的。
等到应用全部改造完成了之后,我们把数据全量地同步到新的数据库去,然后可以把我们的读流量放到新数据库上。因为应用已经通过我们的中间件过来的,所以我们在中间件上做读写分离,对到应用来说是完全透明的。
我们把我们的读流量打到我们的新的数据库上来,以此去验证新的数据库是否能够满足业务的要求,当然通过这样的架构其实是没有办法做到写流量的验证的。在切换过程,对业务的影响就只是那么零点几秒的闪断,替换完之后我们再把数据往回同步,如果真的出现了问题,我们还有一个退路可以往回退。
第二种方案是业务双写的方案,这一个方案可能会相对于上一个方案来说更稳妥,但是也更复杂一些。首先我们准备一套新的数据库,先做全量同步,再做增量同步,保证两边的数据是追平的。然后我们再找一个时间窗口,当然前提是我们就上一步已经执行完了,就是我们应用的适配卡照已经执行完了,然后通过我们的应用去开启我们的双写,然后保证两边的数据都写一致,这个时候我再去把增量同步给停掉,然后底下再开启一个脚本,异步地去对比两边的数据,保证两边的数据是一致的。
对账的过程中如果发现不一致的东西,就打日志出来,然后人工分析,当保证两边是一致以后,就可以开始去分析一下。因为这个时候我们的业务是以老库为主,新库为辅,这个时候新库它是既有读又有写的,我们可以从业务上去观察到新库的各种解指标,包括耗时、错误率等等,如果新库是有问题的,在这个阶段基本上都能发现,而且对业务是毫无影响的。足够稳定之后我们再进行双写扭转,把新库为主,旧库为辅,然后这样再持续稳运行一段时间。当我们发现用新的库足够稳定之后,再把双写给下掉。
做完了上面那一步,就到了上线后的保障阶段。这里主要分两块来做,一块是可观致性,另外一块是可控性、可观测性,保证了我们在出现故障的时候能够快速地发现,快速地定位,可控性保证了我们在出现故障之后可以快速地响应以及快速地恢复。
可观测性这一块loging、 tracing、metric 这三个大家都经常听到,就不细说了。在我们内部其实也针对刚刚的那几个点做了对应的建设,包括底层资源的监控,业务层的监控、日志采集平台、调用链路分析平台。在可恢复这一块,其实我们通过过往的故障可以发现就是故障的时候,故障恢复的时间大多数并不是花在就是故障的修复的那一刻,时间更多的是花在信息的沟通人员的分工上,就从故障的出现到协调到对应的人,然后再把信对应的信息同步,再到决策要做怎么样的操作。
我们对时间分布做了一整套应急响应体系。我们把故障分为轻微问题、中等问题、还有重大问题,以此打造了一个预案管理平台,平时运维可能更多的只需要在上面建立我们的原子化的一些预案能力。举个例子,SQL 的kill,数据库的主从切换等等这样的一些原子能力。然后我们把这样各种各样的非常成熟的原子能力整合到那个预案平台,然后在预案平台上做各种各样的故障预案的编排,结合AI,在出现故障的时候,自动地去推荐预案再辅以人为的判断。
通过把这样的一些智能化的预案推送到我们的移动端,那么人可能需要做的事情只是在移动端上点一点,那么它就可以自动化地去执行我们的预案。像遇到一些在改造过程中遇到的比较简单的问题,就执行降级操作,降级包括业务降级、请求降级、底层的资源降级,技术层面可能我们还会做一些架构的降级。
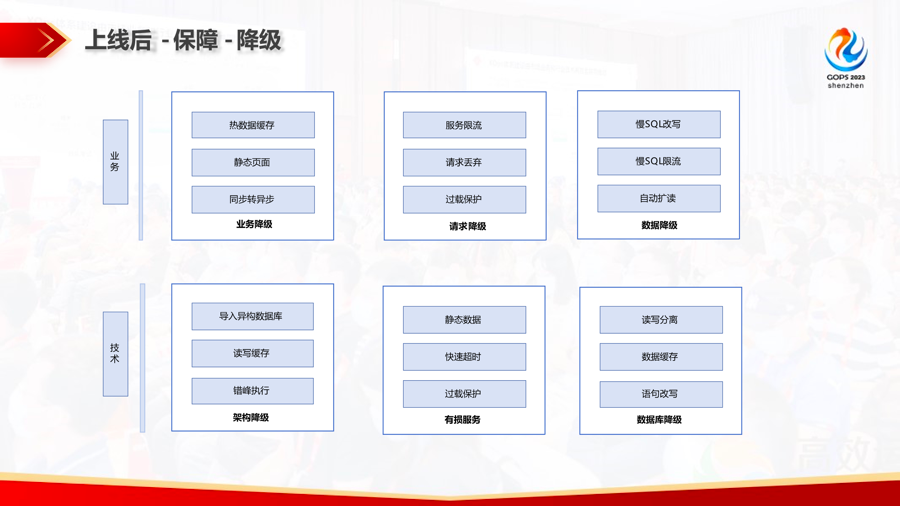
最后我们还有我们的兜底方案,前面提到的切换方案中,不管是我们的双写方案,还是我们基于数据库中间件切换的方案,都能保证我们在秒级内做那个数据库的回退。像双写方案,因为我们把那个双写作为做一个配置项存的一个开关里面,我们做回退只需要修改一下那个数据库切换的一个开关,像中间件的方案,我们只需要切换一下后端的指向。
最后,对我们在数据库国产化改造的经验做个小结。
总结
第一是合适就好。其实大多数时候,集中式的数据库仍然是当前的一个最优解,如果你的数据可能只有几百G,甚至可能就两三个T,那么集中式数据库可能仍是当前最好的选择,因为你不需要去承担数据分片,还有这种各种的各样跨节点同步的耗时这样一系列的问题。
第二是没有银弹,但不要指望用一种数据库去解决所有的问题。过去我们在用 Oracle 的时候,然后 Oracle 承担了太多不应该他承担的东西了。现在我们在做的数据库改造的过程中,慢慢的我们也在解决这样的一个问题,像该扛量的我们用 Redis,像即席查询,那么用 clickhouse 这样的一些数据库去扛,然后做一些大的一些报表分析的这样的一些东西。可能我们会通过我们的同步工具同步到我们的大数据平台,通过大数据平台去做这样的一些分析。
第三是拆掉运维里的墙,打破技术和业务的壁垒。技术只有服务于业务、和业务结合,而运维只有跳出自己的框框,站到全局的视角去看待问题,那么才能真正做到的事半功倍,才能称之为真正的技术运营。