CSDN个人主页:清风莫追
欢迎关注本专栏:《一起撸个DL框架》
文章目录
- 2 节点与计算图的搭建 🍒
- 2.1 简介
- 2.2 设计节点类
- 2.3 节点类的具体实现
- 2.4 搭建计算图进行计算
- 2.5 小结
- 2.6 题外话——节点存储的值
2 节点与计算图的搭建 🍒
2.1 简介
这一节将动手搭建一个简单的“计算图”,并在其上进行计算。
计算图这个术语大家可能感到陌生,它是图论中“图”的一种,由节点和有向边组成,用来表示数据的流动。计算时则根据变量节点的输入得到输出。
2.2 设计节点类
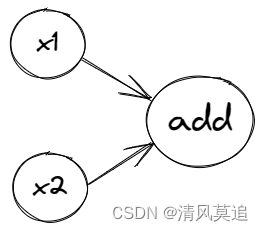
我们将定义一个抽象的节点类。计算图中有两种节点,一种是“变量节点”,是计算图接受外部输入的地方,如上图中x1、x2节点;另一种是“计算节点”,从父节点获取输入,并进行某种运算后得到本节点的值,运算过程与具体的节点有关,如上图中add结点。所有的节点都将从抽象的节点类中派生得到。
(你当然也可以独立地实现每个节点类。但在抽象的节点类实现各种节点共有的性质,比如每个节点都会有自身的值、会有父节点,这样可以减少一些冗余的代码。)
我们将抽象的节点类命名为Node,那么Node类中应该有哪些成员呢?在搭建计算图时,需要将新建立的节点与之前的节点进行连接,因此可以有一个__init__()方法;变量节点需要接受外部输入,可以有个set_value()方法;计算节点需要知道自身具体的计算过程,可以有个compute()方法。那么,Node类的大致结构如下:
(这里为了简化设计,我们假定计算图中的每个节点都至多拥有两个父节点。即使是3个数相加,也可以拆解成两次2个数相加的运算。)
class Node:
def __init__(self, parent1=None, parent2=None) -> None:
pass
def set_value(self, value):
pass
def compute(self):
pass
接着,我们就可以通过继承Node类,实现各种具体的节点。比如“变量节点类(Varrible)”和“加法节点类(Add)”。其中变量节点什么也不用做,只需要原样继承Node类就好了。那么我可以直接将Node类作为变量节点吗?当然可以!这里主打的就是一个整整齐齐(继承关系更加统一和清晰)。同时,变量节点没有父节点,而是从外部接受输入,因此父节点直接初始化为None就好。
加法节点还需要具体实现计算本节点值的compute()方法。
class Varrible(Node):
def __init__(self) -> None:
super().__init__()
class Add(Node):
def __init__(self, parent1=None, parent2=None) -> None:
super().__init__(parent1, parent2)
def compute(self):
pass
2.3 节点类的具体实现
实现代码如下:
(在Node类中定义
copute()有什么意义呢,在具体的计算节点类中再定义不就可以了吗?没错,但这里我们的目的主要是作为一个提醒:在计算节点中不用忘记了实现具体的计算方法,同时保证统一的方法名,不要在加法节点中是compute,在以后的乘法节点中又变成了calculate)
class Node:
def __init__(self, parent1=None, parent2=None) -> None:
self.parent1 = parent1
self.parent2 = parent2
self.value = None
def set_value(self, value):
self.value = value
def compute(self):
'''本节点值的计算逻辑。是抽象方法,需在具体的节点类中重写'''
pass
class Varrible(Node):
def __init__(self) -> None:
super().__init__()
class Add(Node):
def __init__(self, parent1=None, parent2=None) -> None:
super().__init__(parent1, parent2)
def compute(self):
self.value = self.parent1.value + self.parent2.value
2.4 搭建计算图进行计算
完成节点类的定义之后,利用计算图进行计算的过程大致是个三步走的过程:
- 1 搭建计算图。节点本身是孤立的,将节点连接起来才是具有逻辑结构的计算图。
- 2 输入。
- 3 计算结果节点的值。
if __name__ == '__main__':
# 搭建计算图
x1 = Varrible()
x2 = Varrible()
add = Add(x1, x2) # 结果节点
# 输入
x1.set_value(int(input('请输入x1:')))
x2.set_value(int(input('请输入x2:')))
# 进行前向计算
add.compute() # 计算add节点的值并保存在该节点的value属性中
print(add.value)
运行结果:
请输入x1:3
请输入x2:4
7
2.5 小结
本节以一个不到40行代码的简单例子,向搭建介绍了计算图的搭建与运算的大致过程,实现了将两个变量x1、x2作为输入,计算它们的和add的功能。
有同学可能就疑惑了,40行的简单例子?那它和我这四行代码有什么区别吗?嗯,从实现的功能上来看,几乎可以说是没有区别。不过,这是为了给后面的内容做铺垫的啦!我们想要实现一个简单的框架,图的结构可以比较灵活的进行调整,而一个函数def add(x1, x2)直接就写定了。
def add(x1, x2):
return x1 + x2
y = add(int(input('请输入x1:')), int(input('请输入x2:')))
print(y)
本节实现的计算图只有三个节点,后面我们将继续对代码进行扩展,以支撑更加复杂的计算图的实现,一步步前进,最终尝试用我们的框架去实现一些简单的深度学习任务。
2.6 题外话——节点存储的值
我们与实际深度学习框架相比,虽然都是基于计算图的思想,但基本的实现上却有所区别。因为多个节点的运算在实现上,可以通过矩阵乘法来打包进行,效率更高,代码编写也更简单,但也更加抽象和难以理解。
“小批量梯度下降法”(MBGD)是一个基本的神经网络优化算法,每次用一小批样本来更新网络的参数,而不是一个样本(SGD),也不是所有样本(BGD)。框架通常还将“批机制”集成到了计算图中,可以在计算图的一次运算中批量处理多个样本,于是计算图需要再加一个维度。而对于三维的图像输入数据(高,宽,通道数),图的节点中存储的将是四维的张量。
注:有时我们谈到SGD,其实指的是MBGD。
我主要参考的书籍是张觉非和陈震的《用Python实现深度学习框架》,书中实现的MatrixSlow框架为了概念的清晰,将批机制放在了计算图之外,以将它与计算图在原理上区分开。在MatixSlow的实现中,每个节点存储的值都是二维矩阵。
然而目前我们的实现中,每个节点存储的都是单个数值,也就是“标量”。这将导致更糟糕的计算效率,但好处是可以屏蔽之后反向传播时的矩阵乘法运算的求导问题。我感觉这样在概念上对深度学习框架的理解可能会更简单一些。
上一篇:【一起撸个DL框架】1 绪论