版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录

目录
- scala的 泛型
- 给方法定义泛型
- 给类定义泛型
- 泛型的上下界
- 泛型中 非变 协变 和 逆变
- scala中actor相关内容
- actor基本介绍
- actor的入门案例
- 基于actor模拟消息发送和接收
- 基于actor实现自定义消息传递
- wordCount整体实现操作
- akka
- akka的基本介绍
- 基于akka实现进程之间的通信
- 基于akka实现一个spark内部通信案例
- 通信的流程
- 准备工作
- 代码操作
- spark-master
- spark-slave
scala的 泛型
给方法定义泛型
格式:
def 方法名[泛型名称](..) = {
//...
}
示例
示例说明
用一个方法来获取任意类型数组的中间的元素
- 不考虑泛型直接实现(基于Array[Int]实现)
- 加入泛型支持
package com.lee
// 不使用泛型来实现的操作: 整体的操作比较繁琐的
object Demo01 {
/*
用一个方法来获取任意类型数组的中间的元素
- 不考虑泛型直接实现(基于Array[Int]实现)
- 加入泛型支持
*/
def getMiddleData(array:Array[Int]) = {
array((array.length-1) /2)
}
def getMiddleData(array:Array[String]) = {
array((array.length-1) /2)
}
def getMiddleData(array:Array[Double]) = {
array((array.length-1) /2)
}
def main(args: Array[String]): Unit = {
val value1 = getMiddleData(Array(1,2,3,4,5))
val value2 = getMiddleData(Array("A","B","C","D","E"))
val value3 = getMiddleData(Array(1.2,2.2,3.2,5.2,6.2))
println(value1)
}
}
实现泛型来实现
package com.lee
// 不使用泛型来实现的操作: 整体的操作比较繁琐的
object Demo02 {
/*
用一个方法来获取任意类型数组的中间的元素
- 不考虑泛型直接实现(基于Array[Int]实现)
- 加入泛型支持
*/
def getMiddleData[T](array:Array[T]) = {
array((array.length-1) /2)
}
def main(args: Array[String]): Unit = {
val value1 = getMiddleData(Array(1,2,3,4,5))
val value2 = getMiddleData(Array("A","B","C","D","E"))
val value3 = getMiddleData(Array(1.2,2.2,3.2,5.2,6.2))
println(value1)
}
}
给类定义泛型
语法结构:
class 类[T](val 变量名: T)
示例
示例说明
- 实现一个Pair泛型类
- Pair类包含两个字段,而且两个字段的类型不固定
- 创建不同类型泛型类对象,并打印
package com.lee
object Demo03 {
/*
- 实现一个Pair泛型类
- Pair类包含两个字段,而且两个字段的类型不固定
- 创建不同类型泛型类对象,并打印
*/
class Pair[T] {
var array:Array[T] = _
var list1:List[T] = _
def eat[T](value:T) = {
value match {
case _ : Int => println("这是一个Int类型数据")
case _ : String => println("这是一个String类型数据")
case _ =>println("不知道什么类型")
}
}
}
def main(args: Array[String]): Unit = {
val pair = new Pair[String]()
pair.array = Array("张三","李四")
pair.eat(10)
}
}
说明:
在对类定义泛型后, 泛型仅对成员变量是生效的, 而方法是可以单独在重新定义的
泛型的上下界
- 上界
使用<: 类型名表示给类型添加一个上界,表示泛型参数必须是该类型的子类或者本身
[T <: 类型]
上界设置操作
package com.lee
import com.lee.Person
// 演示 泛型的上界
object Demo04 {
trait Person
class Stu extends Person
class Temp[T <: Person] {
var list:List[T] = _
}
def main(args: Array[String]): Unit = {
val temp = new Temp[Stu] // 经过测试, 发现 可以传递 Stu 或者 Person, 说明设置上界为 Person 生效了
}
}
- 下界:
上界是要求必须是某个类的子类,或者必须从某个类继承,而下界是必须是某个类的父类(或本身)
[T >: 类型]
package com.lee
// 演示 泛型的下界
object Demo05 {
trait Person
class Stu extends Person
class zhangsan extends Stu
class Temp[T >: Stu] {
var list:List[T] = _
}
def main(args: Array[String]): Unit = {
val temp = new Temp[Person] // 经过测试, 发现 可以传递 Stu 或者 Person, 说明设置下界为 Stu 生效了 . 只能传递本身和父类
}
}
泛型中 非变 协变 和 逆变
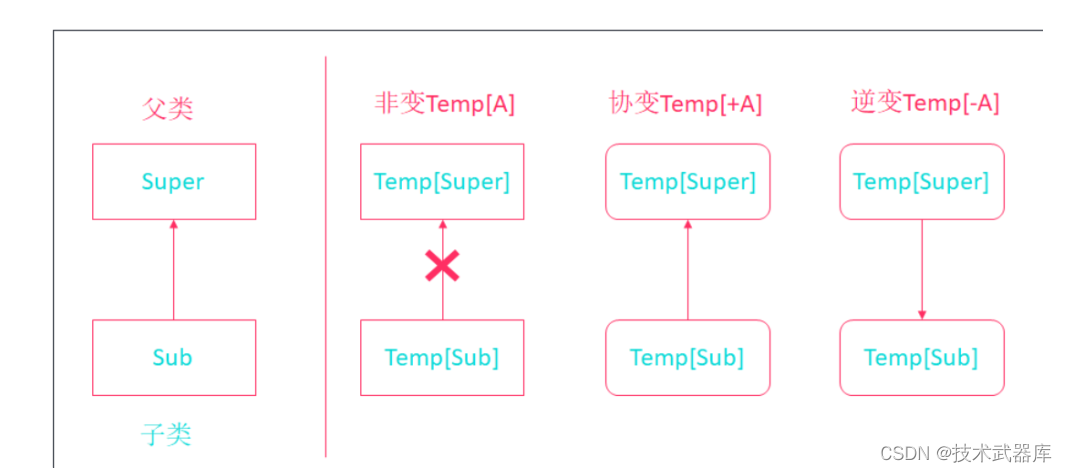
相关操作:
package com.lee
object Demo06 {
class Super
class Sub extends Super
class Temp1[T] // 演示 非变
class Temp2[+T] // 演示 协变 子类转换为父类接收
class Temp3[-T] // 演示 逆变
def main(args: Array[String]): Unit = {
// 演示 非变
val temp1: Temp1[Sub] = new Temp1[Sub]
// val temp:Temp1[Super] = temp1 直接编译报错 无法转换
// 演示协变
val temp2: Temp2[Sub] = new Temp2[Sub]
// val temp:Temp2[Super] = temp2 正常 说明 可以使用父类泛型 接收子类泛型
val temp3: Temp2[Super] = new Temp2[Super]
// val temp:Temp2[Sub] = temp3 编译报错, 不支持 使用子类泛型 接收父类泛型
// 演示逆变
val temp4: Temp3[Super] = new Temp3[Super]
// val temp:Temp3[Sub] = temp4 正常 说明可以使用子类泛型, 接收父类泛型
}
}
scala中actor相关内容
actor基本介绍
scala的actor类似于java中线程(Thread),但是要比java的线程的效率要高的多
在java的线程中, 存在比较大问题, 在操作共享数据的时候, 为了保证线程的安全, 一般都需要进行加锁来处理, 而一旦加锁后, 就会导致只有一个线程可以操作, 其他的线程只能等待, 这样就会导致资源浪费, 同时执行效率也会下降, 同时还有可能出现死锁情况
Actor并发编程模型是一种不共享数据,依赖消息传递的一种并发编程模式,有效避免资源争夺、死锁等情况。
发送消息的方式
| ! | 发送异步消息,没有返回值。 |
|---|---|
| !? | 发送同步消息,等待返回值。 |
| !! | 发送异步消息,返回值是 Future[Any]。 |
注意:
Future 表示一个异步操作的结果状态,可能还没有实际完成的异步任务的结果
Any是所有类的超类,Future[Any]的泛型是异步操作结果的类型。
例如:
要给actor1发送一个异步字符串消息,使用以下代码:
actor1 ! "你好!"
接收消息
Actor中使用receive方法来接收消息,需要给receive方法传入一个偏函数
{
case 变量名1:消息类型1 => 业务处理1,
case 变量名2:消息类型2 => 业务处理2,
...
}
[!NOTE]
receive方法只接收一次消息,接收完后继续执行act方法
actor的入门案例
导入相关的pom依赖
<properties>
<project.build.source.Encoding>UTF-8</project.build.source.Encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<!-- 演示Scala-actor并发编程时需要的依赖,因为过期了在2.12中被移除了,所以引入2.11的-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-actors</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_2.11</artifactId>
<version>2.3.14</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-remote_2.11</artifactId>
<version>2.3.14</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<!-- Scala编译插件-->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<includes>
<include>**/*.scala</include>
</includes>
</configuration>
</execution>
<execution>
<id>scala-test-compile</id>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- maven编译插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
- 代码实现
package com.lee
import scala.actors.Actor
// 1) actor的入门案例
object Demo01 {
/*
需求: 创建两个actor, 一个actor打印 1~10 一个actor打印 11~20
1、定义一个class/object继承Actor特质,注意导包import scala.actors.Actor
2、重写对应的act方法
3、调用Actor的start方法执行Actor
4、当act方法执行完成,整个程序运行结束
*/
class Actor1 extends Actor {
override def act(): Unit = (1 to 10).foreach(println(_))
}
class Actor2 extends Actor {
override def act(): Unit = (11 to 20).foreach(println(_))
}
def main(args: Array[String]): Unit = {
new Actor1().start()
new Actor2().start()
}
}
基于actor模拟消息发送和接收
package com.lee
import scala.actors.Actor
object Demo02 {
/*
需求: 实现两个actor之间数据发送和接收操作
1、创建两个Actor(ActorSender、ActorReceiver)
2、ActorSender发送一个异步字符串消息给ActorReceiver
3、ActorReceive接收到该消息后,打印出来
*/
// 发送者
object ActorSender extends Actor {
override def act(): Unit = {
println("发送者执行数据发送:")
ActorReceiver ! "我是发送者, 你收到了吗?" // 中缀调用法
receive{
case message:String => println("接收到消息:"+ message)
}
}
}
//接收者
object ActorReceiver extends Actor {
override def act(): Unit = {
receive {
case i:String =>
println("我已经接收到消息了,消息为:"+ i)// 偏函数
// 响应我已经接收到了数据
ActorSender ! "我已经接收到了...."
}
}
}
def main(args: Array[String]): Unit = {
ActorSender.start()
ActorReceiver.start()
}
}
发现的问题: receiver操作 只能接收到一次消息, 整个actor直接退出了
如何进行循环的接收消息呢?
只需要 在receiver的方法外面套上 while(true) 让其一直不断的接收消息即可
while(true){
receive {
case i:String =>
println("我已经接收到消息了,消息为:"+ i)// 偏函数
// 响应我已经接收到了数据
ActorSender ! "我已经接收到了...."
}
}
说明: 在使用receiver方法在接收消息的时候, actor默认 每接收一次消息, 相当于就是重新创建一个线程
存在弊端: 如果消息比较多, 导致线程被频繁的创建和销毁, 对执行效率 以及资源都是一种浪费
那么如何解决呢? scala为了解决这个问题, 提供一种: loop和react 优化消息的接收模型
// 持续接收消息
loop {
react {
case msg:String => println("接收到消息:" + msg)
}
}
基于actor实现自定义消息传递
package com.lee
import scala.actors.{Actor, Future}
//3 模拟自定义的数据 消息传递工作
object Demo03 {
// 样例类: 用于封装数据操作
case class MessageData(id:Int,msg:String)
object Actor01 extends Actor {
override def act(): Unit = {
receive {
case MessageData(x,y) =>
println("接收到消息: "+x +" "+y)
Thread.sleep(5000)
sender ! MessageData(2,"我很好...")
}
}
}
def main(args: Array[String]): Unit = {
Actor01.start()
// Actor01 ! MessageData(1,"你好吗? 我是main") // 异步无返回值, 适用于发送过去 接受者不需要返回消息情况
//val a: Any = Actor01 !? MessageData(1,"你好吗? 我是main") // 当使用同步方式, 会阻塞等待接收者返回消息
val a: Future[Any] = Actor01 !! MessageData(1, "你好吗? 我是main") // 异步有返回值 ,发送过去 立即就会返回, 不去等待返回值
// 如果是立即返回, 那么就有可能出现接受者还没有讲消息返回来, 此时 返回值 Future类型, 此对象可以用来获取返回的状态信息
// 如果获取数据
// asInstanceOf 用于进行类型的转换操作
val data: MessageData = a.apply().asInstanceOf[MessageData]
println(data.id + " "+data.msg)
}
}
说明:
通过Future的apply方法获取返回数据的时候,如果数据没有返回回来, 此时apply方法会自动阻塞 直到有数据返回
Future的isset的方法, 用于判断数据是否已经返回, 如果返回就会为true 如果没有返回就为false
wordCount整体实现操作
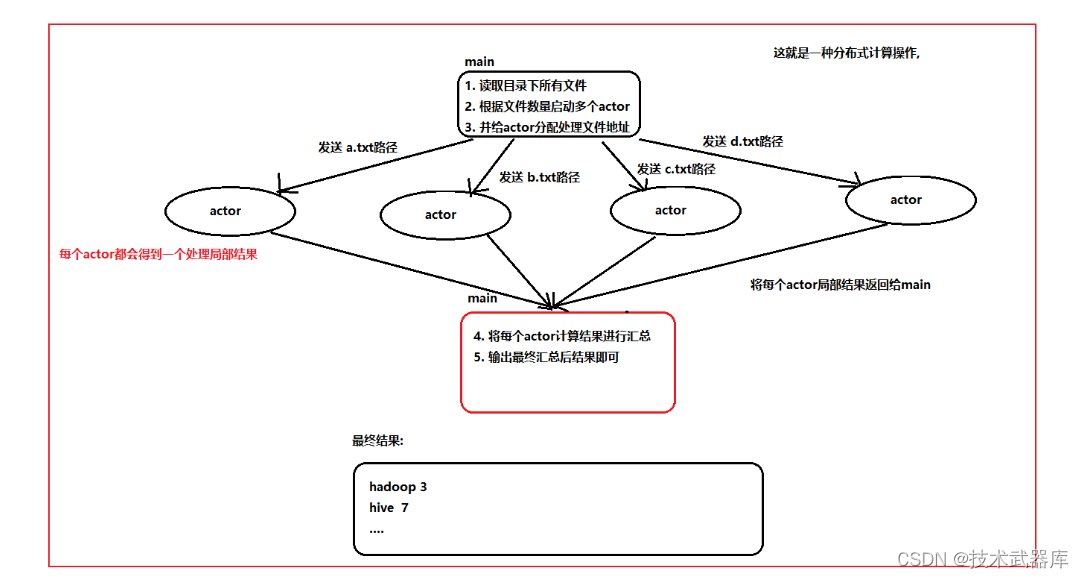
- 代码实现
package com.lee.actor
import java.io.File
import scala.actors.Actor
import scala.io.Source
object WordCountDemo06 {
def main(args: Array[String]): Unit = {
//1.创建一个File对象, 指定对应目录位置
val file = new File("D:\\scala\\data")
//2. 从这个file对象中,获取所有的文件
val files: Array[File] = file.listFiles()
//3. 获取每一个文件对应的路径
val filePaths: Array[String] = files.map(_.getPath)
//4. 根据文件的数量, 创建对应多个actor, 并将文件路径配置一对一的分配给actor操作(分配任务)
val actorsAndFilePath: Array[(WordCountActor, String)] = filePaths.map(fileName => new WordCountActor -> fileName)
//5. 启动每一个actor, 将文件路径传递给对应actor操作
val futureArray = actorsAndFilePath.map(actorAndFilePath => {
actorAndFilePath._1.start() // 启动actor
actorAndFilePath._1 !! actorAndFilePath._2
})
//7. 进行最终聚合统计操作
/*
Map(elk -> 3, kafka -> 3, hbase -> 3, redis -> 6)
Map(hadoop -> 2, impala -> 2, hive -> 1, flume -> 1)
Map(hue -> 4, hive -> 8, flume -> 8, hbase -> 4)
Map(hue -> 1, hadoop -> 1, spark -> 1, hive -> 1, scala -> 1, kudu -> 1)
*/
//7.1: 获取每一个actor返回的结果
//最终想要的结果:
// Array((hadoop,2), (impala,2), (hive,1), (flume,1), (hue,1), (hadoop,1), (spark,1), (hive,1), (scala,1), (kudu,1), (elk,3), (kafka,3), (hbase,3), (redis,6), (hue,4), (hive,8), (flume,8), (hbase,4))
val wordsAndNums = futureArray.flatMap(future => future.apply().asInstanceOf[Map[String,Int]])
//7.2 按照元组的第一个进行分组, 然后统计计算即可
//Map( hadoop->List((hadoop,2),(hadoop,1)) ,impala->List((impala,2)), hive->List((hive,1),(hive,1),(hive,8)) ...)
val groupVal = wordsAndNums.groupBy(_._1)
// 7.3 进行统计操作
val wordCount = groupVal.map(wordAndNum => {
//
val sum = wordAndNum._2.map(num => num._2).sum
wordAndNum._1 -> sum
})
//7.4 进行打印最终结果
wordCount.foreach(println(_))
}
// 此actor用于处理每个文件的局部统计操作
class WordCountActor extends Actor{
override def act(): Unit = {
//6. 接收到分配过来filePath
receive{
case filePath:String =>
//6.1. 根据文件路径读取文件数据 (一行一行读取)
// hadoop hive impala hadoop
val lineData = Source.fromFile(filePath).getLines()
//6.2. 切割数据, 将其变更为一个个单词
// [hadoop,hive,impala,hadoop]
val words: Iterator[String] = lineData.flatMap(_.split(" "))
//6.3. 将每一个单词, 设置为 (单词,1) ,(单词,1) 方案
// [(hadoop->1),(hive->1),(impala->1),(hadoop->1)]
val wordNum: Iterator[(String, Int)] = words.map( _ -> 1 )
//6.4. 执行分组操作, 将相同单词聚合在一起
// map( hadoop -> [(hadoop->1),(hadoop->1)] , hive -> [(hive -> 1)],impala -> [(impala ->1)] )
val groupData: Map[String, List[(String, Int)]] = wordNum.toList.groupBy( _._1 )
//6.5. 进行求和操作
// [(hadoop->2),(hive->1),(impala ->1)]
val wordCount = groupData.map(wordAndNum => {
//
val sum = wordAndNum._2.map(num => num._2).sum
wordAndNum._1 -> sum
})
//6. 打印:
//println(wordCount)
// 6.6. 将计算完的结果, 返回给main方法
sender ! wordCount
}
}
}
}
akka
akka的基本介绍
Akka是一个用于构建高并发、分布式和可扩展的基于事件驱动的应用的工具包。Akka是使用scala开发的库,同时可以使用scala和Java语言来开发基于Akka的应用程序。
-
提供基于异步非阻塞、高性能的事件驱动编程模型
-
内置容错机制,允许Actor在出错时进行恢复或者重置操作
-
超级轻量级的事件处理(每GB堆内存几百万Actor)
-
使用Akka可以在单机上构建高并发程序,也可以在网络中构建分布式程序
单机高并发: 在一个节点上 有多个线程的操作
网络构造高并发程序: 在多个节点上, 基于进程通信构建
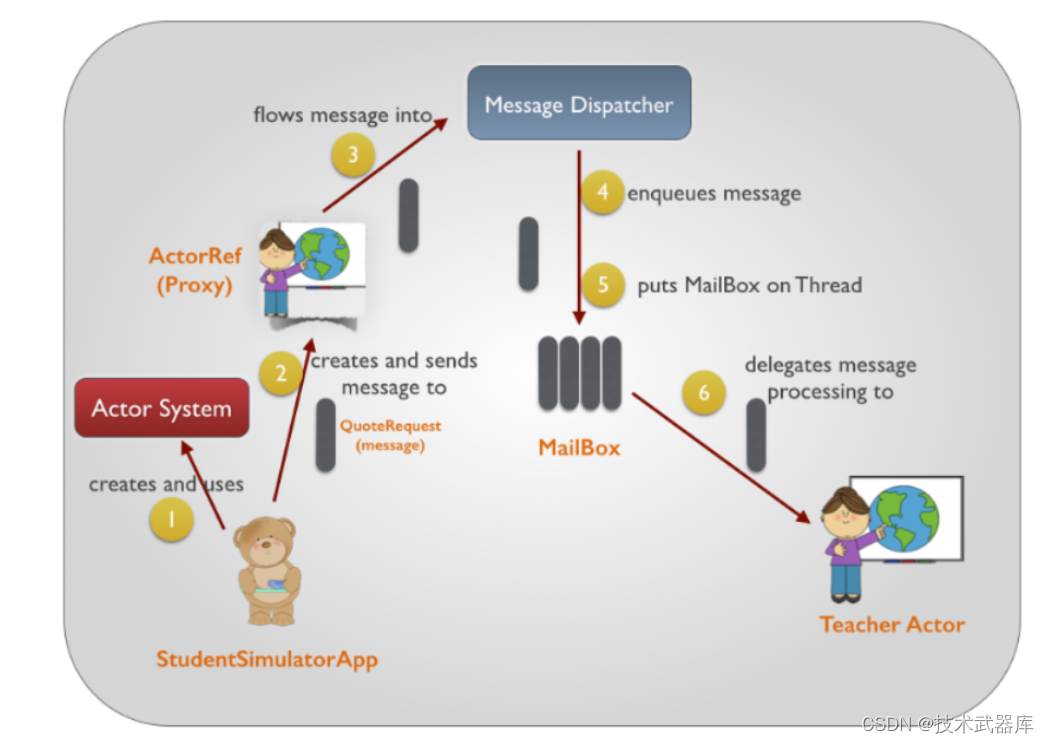
- 核心的API
1) 如何获取ActorSystem对象 :
context.system 获取
2) 如何获取actor的引用:
ActorSystem.actorOf(Props(Actor对象), "Actor名字")
3) 如何实现一个akka的actor:
3.1) 创建一个类, 继承 Actor (Actor需要导入akka下的包)
3.2) 重写 receiver方法, 在这个方法内接受消息即可 (akka默认实现循环接收操作)
3.3) 可选: 重写preStart() 方法, 这个方法是当actor被创建后, 此方法会被自动调用, 而且只会调用一次
4) akka的定时周期执行:
4.1 导入相关的隐式转换
import scala.concurrent.duration._ // 设置时间间隔的隐式转换
import context.dispatcher // 这是定时器必须导入隐式转换
4.2 使用定时器:
context.system.scheduler.schedule(延迟多久执行0 millis, 每隔多久执行15000 millis, 给谁发self, 定期执行的函数CheckTimeOutWorker)
5) 远端地址(URL):
本地Actor: akka://actorSystem名称/user/Actor名称 示例: akka://SimpleAkkaDemo/user/senderActor
远程Actor: akka.tcp://my-sys@ip地址:port/user/Actor名称 示例: akka.tcp://192.168.10.17:5678/user/service-b
基于akka实现进程之间的通信
基于Akka实现在两个进程间发送、接收消息。Worker启动后去连接Master,并发送消息,Master接收到消息后,再回复Worker消息。
操作步骤
-
- 创建两个maven的项目: 一个叫 akka-master 一个叫akka-worker
-
- 导入相关的依赖 : 此依赖于在actor导入依赖是一致的
<properties>
<project.build.source.Encoding>UTF-8</project.build.source.Encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!--<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.11</version>
</dependency>-->
<!-- 演示Scala-actor并发编程时需要的依赖,因为过期了在2.12中被移除了,所以引入2.11的-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-actors</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_2.11</artifactId>
<version>2.3.14</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-remote_2.11</artifactId>
<version>2.3.14</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<!-- Scala编译插件-->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<includes>
<include>**/*.scala</include>
</includes>
</configuration>
</execution>
<execution>
<id>scala-test-compile</id>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- maven编译插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
-
- 在项目中创建scala的目录, 创建后选择maven进行一下刷新即可
- 在项目中创建scala的目录, 创建后选择maven进行一下刷新即可
-
- 导入akka的配置文件(两个项目都需要创建): application.conf
将这个配置文件导入到项目的resources目录下 导入后, 不要忘记修改端口号
master
akka.actor.provider = "akka.remote.RemoteActorRefProvider"
akka.remote.netty.tcp.hostname = "127.0.0.1"
akka.remote.netty.tcp.port = "7000"
worker
akka.actor.provider = "akka.remote.RemoteActorRefProvider"
akka.remote.netty.tcp.hostname = "127.0.0.1"
akka.remote.netty.tcp.port = "7001"
-
- 在master项目中完成akka的基础环境准备
创建一个MasterActor线程:
import akka.actor.Actor
/**
* @Author: lwh
* @Date: 2022/11/29
* @Description:
**/
object MasterActor extends Actor {
override def receive: Receive = {
case msg: String => {
println("master接受的消息:" + msg)
val selection = context.actorSelection("akka.tcp://actorSystem@127.0.0.1:7001/user/workerActor")
selection ! "success"
}
}
}
创建一个MasterMain 入口类
import akka.actor.{ActorSystem, Props}
import com.typesafe.config.ConfigFactory
/**
* @Author: lwh
* @Date: 2022/11/29
* @Description:
**/
object MasterMain {
def main(args: Array[String]): Unit = {
val masterSystem = ActorSystem("actorSystem", ConfigFactory.load())
val masterActor = masterSystem.actorOf(Props(MasterActor), "masterActor")
}
}
-
- 在worker项目中完成akka的基础环境准备
创建WrokerActor
import akka.actor.Actor
/**
* @Author: lwh
* @Date: 2022/11/29
* @Description:
**/
object WorkerActor extends Actor{
override def receive: Receive = {
case "setup" =>
println("接收到setup消息")
val selection = context.actorSelection("akka.tcp://actorSystem@127.0.0.1:7000/user/masterActor")
selection ! "connect"
case "success" =>
println("接收到成功注册消息....")
}
}
创建WorkerMain 入口类
import akka.actor.{ActorSystem, Props}
import com.typesafe.config.ConfigFactory
/**
* @Author: lwh
* @Date: 2022/11/29
* @Description:
**/
object WorkerMain {
def main(args: Array[String]): Unit = {
val actorSystemSystem = ActorSystem("actorSystem",ConfigFactory.load())
val workerActor = actorSystemSystem.actorOf(Props(WorkerActor),"workerActor")
workerActor ! "setup"
}
}
-
- 分别启动master 和 worker的入口类, 如果启动没有报错 说明基础环境配置成功了
基于akka实现一个spark内部通信案例
通信的流程
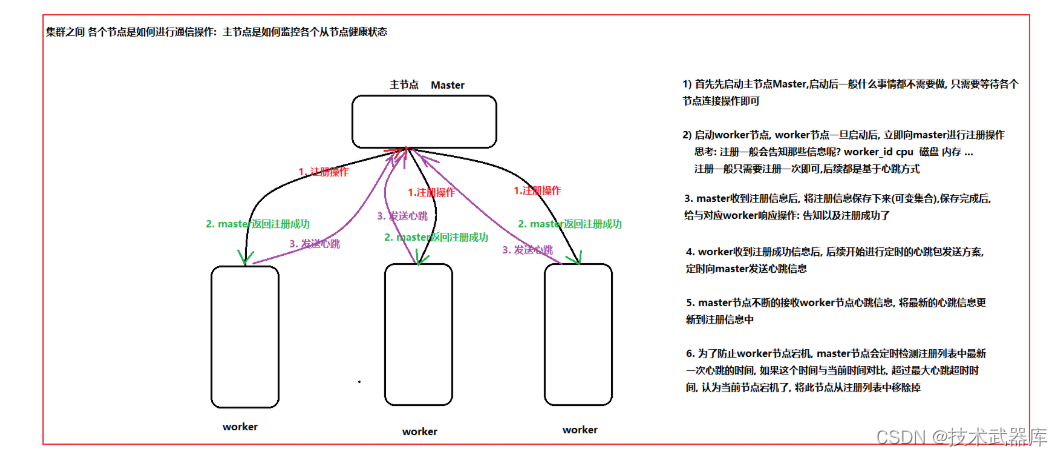
准备工作
- 创建三个maven的项目: 一个项目为 spark-master 一个项目为: spark-slave 一个项目为: spark-common
common项目 主要是用于放置一些公共的样例类和配置信息 - 让 spark-master 和 spark-slave 都要依赖于 spark-common
在spark-master和 spark-slave分别 导入以下依赖
<dependencies>
<dependency>
<groupId>com.lee</groupId>
<artifactId>scala_spark_common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
- spark-master 和 spark-slave 导入和 akka入门案例一致的依赖信息(此处放置包含上面依赖所有内容)
<properties>
<project.build.source.Encoding>UTF-8</project.build.source.Encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!--<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.11</version>
</dependency>-->
<!-- 演示Scala-actor并发编程时需要的依赖,因为过期了在2.12中被移除了,所以引入2.11的-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-actors</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_2.11</artifactId>
<version>2.3.14</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-remote_2.11</artifactId>
<version>2.3.14</version>
</dependency>
<dependency>
<groupId>com.lee</groupId>
<artifactId>scala_spark_common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<!-- Scala编译插件-->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<includes>
<include>**/*.scala</include>
</includes>
</configuration>
</execution>
<execution>
<id>scala-test-compile</id>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- maven编译插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
- 在spark-common中导入相关依赖:
<properties>
<project.build.source.Encoding>UTF-8</project.build.source.Encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<!-- Scala编译插件-->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<includes>
<include>**/*.scala</include>
</includes>
</configuration>
</execution>
<execution>
<id>scala-test-compile</id>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- maven编译插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
- 分别在每个项目中创建scala目录结构
- 在每个项目中创建包结构: com.lee.akka.spark
- 将样例类和配置文件导入到对应的项目中: pom除外
- 编写akka的基本入门准备工作: 与 入门案例的akka准备工作是一致的
代码操作
spark-master
- 入口类
package com.lee.akka.spark
import akka.actor.{ActorSystem, Props}
import com.typesafe.config.ConfigFactory
object SparkMasterMain {
def main(args: Array[String]): Unit = {
//1. 创建ActorSystem对象
val actorSystem = ActorSystem("sparkMasterActorSystem",ConfigFactory.load())
//2. 获取自己的actor引用对象
val actorRef = actorSystem.actorOf(Props(SparkMasterActor),"sparkMasterActor")
//3. 对于master启动后,目前什么都不需要做
}
}
- actor类
package com.lee.akka.spark
import java.util.Date
import akka.actor.Actor
import scala.collection.mutable
object SparkMasterActor extends Actor{
private val regWorkerMap = mutable.Map[String, WorkerInfo]()
//此方法 一启动 就会执行 :定时检测注册列表中是否有超时的从节点注册信息
override def preStart(): Unit = {
import scala.concurrent.duration._
import context.dispatcher
// 定时执行心跳操作:
context.system.scheduler.schedule(0 second,ConfigUtil.`master.check.heartbeat.interval` second){
//1. 从注册列表中 过滤出已经超时的注册列表
val timeOutRegData: mutable.Map[String, WorkerInfo] = regWorkerMap.filter(regData => (new Date().getTime - regData._2.lastHeartBeatTime)/1000 > ConfigUtil.`master.check.heartbeat.timeout`)
//2. 将这些数据从 regWorkerMap 清理出去
timeOutRegData.foreach(timeoutData => regWorkerMap -= timeoutData._1 )
//3.遍历打印当前还剩余那些slave
regWorkerMap.foreach(regWork =>println("当前注册的slave有: "+regWork._2))
}
}
override def receive = {
case WorkerRegisterMessage(workerid,cpu,mem) =>
println("注册信息为:"+workerid+" "+cpu+" "+mem)
//1. 接收到注册信息后, 然后将注册信息保存到注册列表
regWorkerMap += workerid -> WorkerInfo(workerid,cpu,mem,new Date().getTime)
//2. 通知slave, 告知注册成功了
sender() ! RegisterSuccessMessage
case WorkerHeartBeatMessage(workerid,cpu,mem) =>
println("接收到心跳包消息")
// 只要key相同, 直接覆盖了
regWorkerMap += workerid -> WorkerInfo(workerid,cpu,mem,new Date().getTime)
}
}
spark-slave
- 入口类
package com.lee.akka.spark
import akka.actor.{ActorSystem, Props}
import com.typesafe.config.ConfigFactory
object SparkSlaveMain {
def main(args: Array[String]): Unit = {
/*val props = new Properties()
props.setProperty("akka.actor.provider","akka.remote.RemoteActorRefProvider")
props.setProperty("akka.remote.netty.tcp.hostname","127.0.0.1")
props.setProperty("akka.remote.netty.tcp.port","8101")*/
//1. 创建 actorSystem对象
val actorSystem = ActorSystem("sparkSlaveActorSystem",ConfigFactory.load())
//2. 获取自己actor引用对象
val actorRef = actorSystem.actorOf(Props(SparkSlaveActor) , "sparkSlaveActor")
//3. 发送消息: 表示从节点以及启动了
//actorRef ! "setup"
}
}
- actor类
package com.lee.akka.spark
import java.util.UUID
import akka.actor.{Actor, ActorSelection}
import scala.util.Random
object SparkSlaveActor extends Actor{
private var workerid:String = _
private var cpu:Int = _
private var mem:Int = _
private val cpuList = List(2,4,8,12,16,24)
private val memList = List(4,8,12,16,24,28,32,64)
private var masterActorRef: ActorSelection = _
override def preStart(): Unit = {
// 向master发送注册信息
//0 初始化注册信息:
workerid = UUID.randomUUID().toString
cpu = cpuList(Random.nextInt(cpuList.size))
mem = memList(Random.nextInt(memList.size))
//1. 获取到master的地址引用
masterActorRef= context.actorSelection("akka.tcp://sparkMasterActorSystem@127.0.0.1:8000/user/sparkMasterActor")
//2. 执行发送数据
masterActorRef ! WorkerRegisterMessage(workerid,cpu,mem)
}
override def receive = {
case RegisterSuccessMessage =>
println("收到注册成功消息")
import scala.concurrent.duration._
import context.dispatcher
// 定时执行心跳操作:
context.system.scheduler.schedule(0 second,ConfigUtil.`worker.heartbeat.interval` second){
masterActorRef ! WorkerHeartBeatMessage(workerid,cpu,mem)
}
}
}




![[附源码]SSM计算机毕业设计新冠疫苗线上预约系统JAVA](https://img-blog.csdnimg.cn/19572828ebfd4181923e74dc9a38652c.png)