一. ICL的背景
大型语言模型(LLM)如GPT-3是在大规模的互联网文本数据上训练,以给定的前缀来预测生成下一个token(Next token prediction)。这样简单的训练目标,大规模数据集以及高参数量模型相结合,产生了性能极强的LLM,它可以“理解”任何文本输入,并在其基础上进行“写作”,除此以外,GPT-3的论文发现[1],大规模的训练数据会产生一种有趣的新兴行为,称为In-Context Learning(又称上下文学习,语境学习, ICL),他并不需要调整模型参数,仅用几条下游任务的示例就可以取得极佳的结果。
1.1 什么是ICL
上下文学习是在原始GPT-3论文中作为一种大语言模型学习任务的方式而被推广的[2]。在上下文学习中,我们给LLM一组演示样例(输入-输出对)。在样例的末尾我们添加一个测试输入,并允许LM仅通过条件化演示样例,进行预测。
为了正确回答以下两个提示,模型需要理解ICL的演示示例,以确定输入分布(财经或一般新闻)、输出分布(积极/消极或主题)、输入-输出映射(情感或主题分类)以及格式。

1.2 ICL的应用
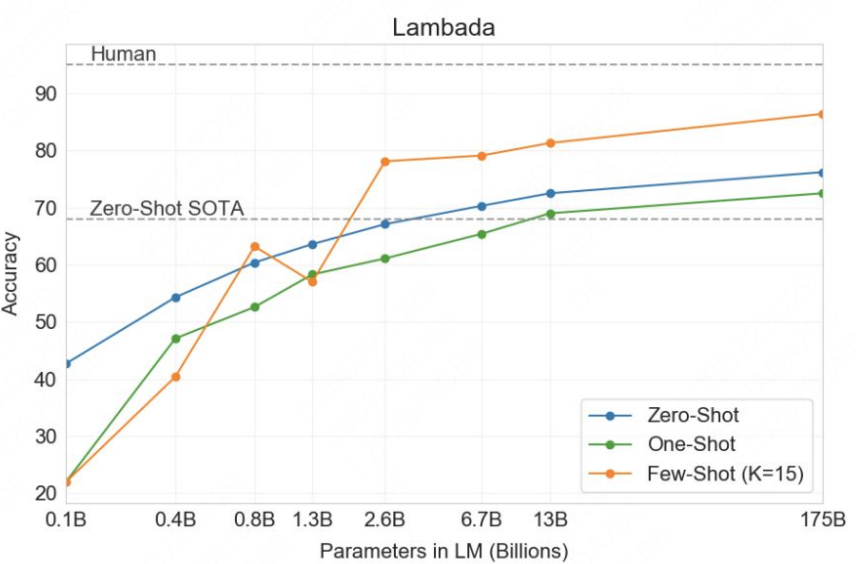
上下文学习在许多NLP 的benchmark测试中,已经媲美甚至超过全资源微调的方法,例如在 LAMBADA(常识句子补全)和 TriviaQA(问答)上达到SOTA的。更令人意外的是上下文学习使人们能够在短短几个小时内启动的一系列应用程序,包括根据自然语言描述编写代码、帮助设计应用程序模型以及概括电子表格功能:
ICL示例提示下的情感分析任务
根据自然语言描述编写代码:
1.3 ICL vs Prompt learning vs Fine-tuning
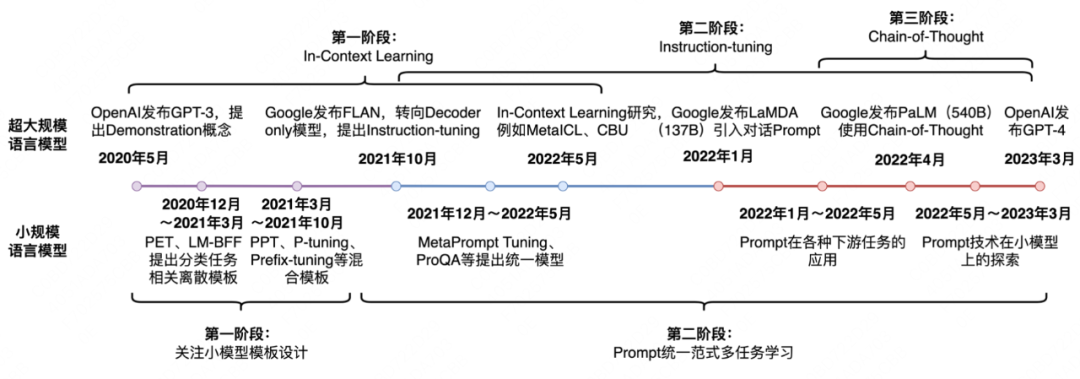
近年来,从“Pretrain & Fine-tune-> Prompt learning-> P-tuning -> Instruction tuning -> Demonstration learning ->Chain-of-thought-> ICL”等概念得提出让人眼花撩乱,其实他们之间存在着包含关系,且这些技术也是随着模型的框架演变趋势(判别->生成)及模型参数量的增大而演变 [3]。
广义上讲,In-Context learning属于Prompt learning的一种,我们更应关注其特异性:
不需要对模型参数更新(Fine-tuning基于梯度更新模型,Prompt learning中有部分Soft Prompt方法需要微调参数)
使用下游任务的的演示信息学习并推理,通常是“实例-标签”形式(Fine tuning与Prompt Learning 仍需在大量训练数据中的学习类别表示等)
二. ICL的框架
2.1 ICL的基本框架
【ICLR 2022】An Explanation of In-context Learning as Implicit Bayesian Inference
链接:https://openreview.net/pdf?id=RdJVFCHjUMI
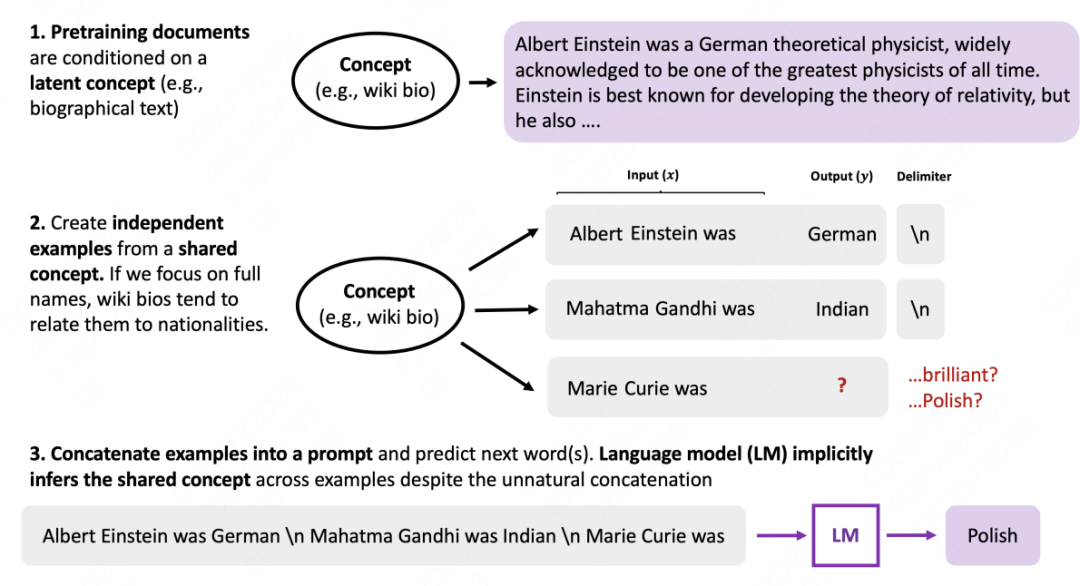
以斯坦福大学在ICLR2022 [4] 工作中的In-Context Learning框架为例,ICL聚焦于在大规模预料上进行了预训练的大模型(例如GPT3,GPT3.5),并允许LLM 在训练时建模一组不同的概念(Concept)
概念是什么?我们可以将一个概念视为包含文本统计信息的潜在变量。例如,“新闻-主题 摘要”任务的概念包含:
词的分布(新闻及其主题)
格式(新闻文章的写作方式)
新闻与主题之间的关系,单词之间的其他语义和句法关系。
一般来说,概念可能是许多潜在变量的组合,但是在本文中用一个概念变量``将它们简化。如下图所示:
Pretrain: 在预训练期间(执行Next Token Prediction),语言模型(LM) 利用前面句子隐含地学习推断一个潜在概念(例如,名称(阿尔伯特·爱因斯坦)→国籍(德语)→职业(物理学家)→...)。
ICL: 在推理时,尽管示例以非连续的方式拼接。LM仍然可以通过共享概念(名称→国籍)来执行预测,这也意味着发生了上下文学习。
2.2 贝叶斯的视角下的ICL
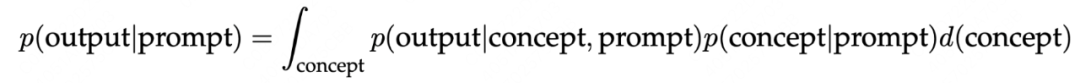
ICL的推理过程可以视为对示例的一个共享概念(shared concept)进行贝叶斯推断,如果模型能够推断出共享概念,那么它就可以用于在测试示例上做出正确的预测。
其中 P(concept|prompt)可以视为我们从一系列演示的示例中推理出共享概念(shared concept)的条件概率,在数学上讲,prompt为模型 (P) 提供了evidence,以加强概念的后验分布P(concept|prompt)。
以下为细致的建模流程,感兴趣可以阅读原文:

2.3 Prompt 在贝叶斯推断中带来的噪声
由于ICL中的Prompt将独立的训练示例以分隔符的形式拼接在一起,这使得其与连续的预训练语料存在一定的Distribution Gap。有趣的是,该文章证明尽管预训练和提示分布不匹配,但LM仍然可以进行贝叶斯推断,并引出以下为几点结论:

ICL示例的概念带来了信号:如绿色箭头所示,输入分布(新闻句内的转换)、输出分布(主题词)、格式(新闻句的语法)和输入-输出映射(新闻与主题之间的关系) ,这些都为贝叶斯推断提供了信号。
ICL示例间的建模存在噪声:由于红色箭头表示示例之间低概率转换产生了噪音。
ICL对示例间噪声具有鲁棒性:不同于监督学习,该文章发现如果有足够强的信号,一定程度的噪声(例如示例间的低概率转换,移除部分输入输出映射)是可以容忍。
三. ICL演示示例选择
如前文所述,ICL的效果与演示示例(demonstrations)有很强的相关性,以下分享几种学术界常见的demonstration选择方式:
3.1 基于相似度检索的方法
【DeeLIO 2022】What Makes Good In-Context Examples for GPT-3?
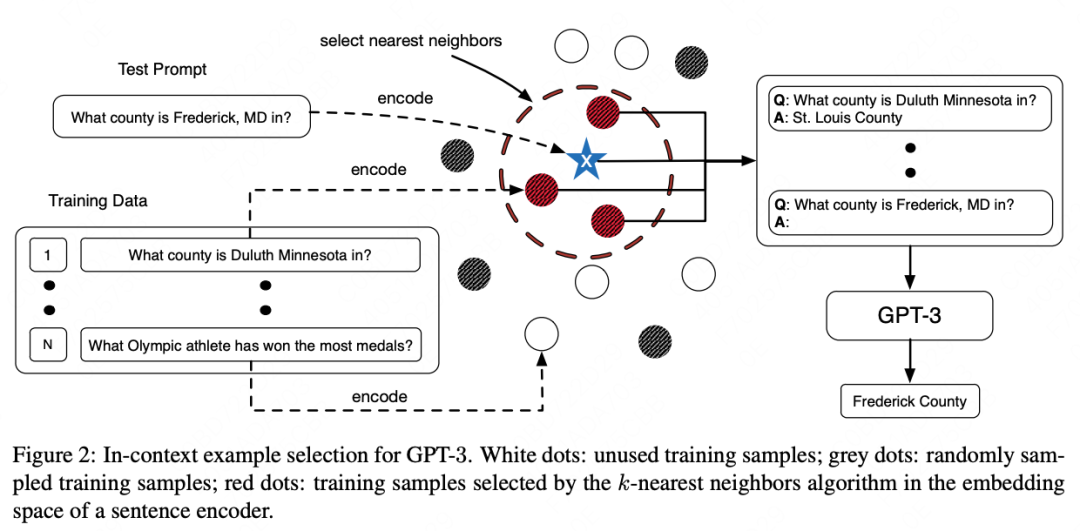
作者[5] [15]用Roberta CLS计算demonstration和测试数据的距离,并发现使用距离小的Top10作为demonstration,其效果远好于使用距离大的。故引出检索式demonstration的方式:

KNN增强ICL选择(KATE):对于测试集样例,作者基于过Encoder后的embedding距离,选出最近的K个train data,作为demonstration。
【NAACL 2022】Learning To Retrieve Prompts for In-Context Learning
本文[6]提出了一种使用标注数据训练dense retriever,用以检索demonstration的有效方法。
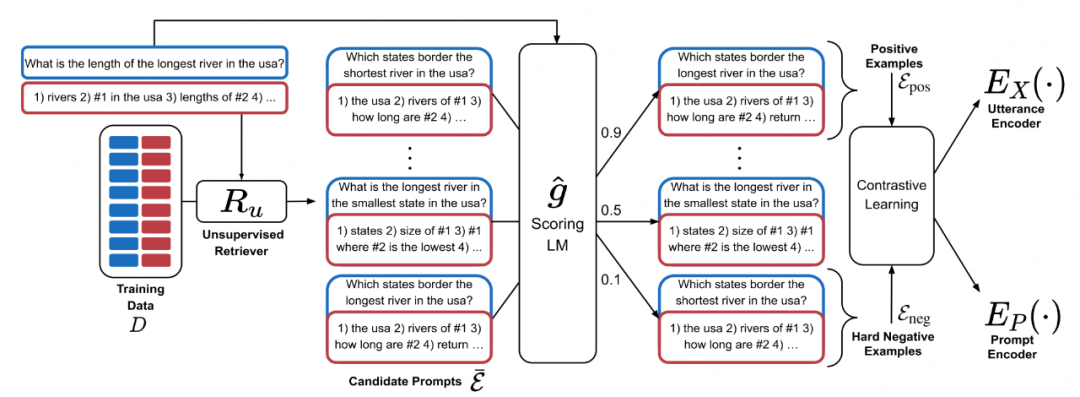
方法:
为了训练dense retriever:
首先基于无监督检索(BM25,SBERT)得到demonstration候选集合。
对候选集合中每一个demonstration进行打分。打分方式为该demonstration拼接预测的输入x后,模型能做出正确预测的概率。
将top-k分数的demonstration作为positive data,bottom-k的作为negative data,与x一起做对比学习,训练一个dense retriver。dense retriver包含一个context encoder用来编码x,和一个demonstration encoder用来编码demonstration,由两个encoder得到的表示cosine similarity作为demonstration和x的相似度。
在inference时,基于该dense retriver,选择demonstration。通过两个encoder,根据相似度选择相近的demonstration并排序。
【Arxiv】Few-Shot Natural Language Inference Generation with PDD: Prompt and Dynamic Demonstration
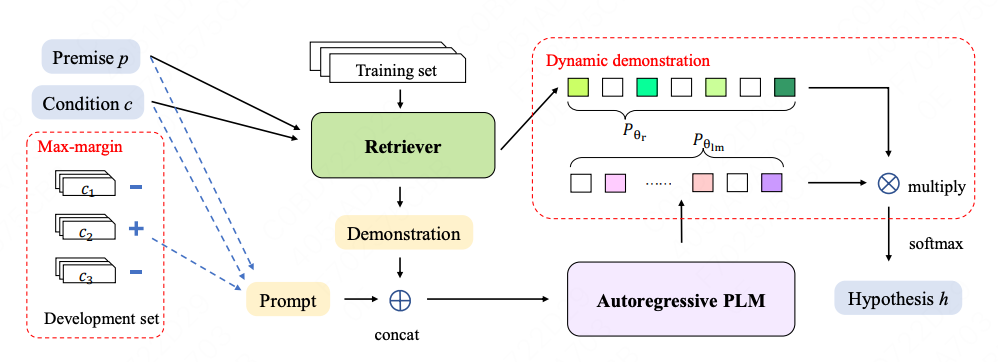
本文[7]综合考虑基于检索式的Demonstration,并通过生成式的方法生成模板格式的condition,这是因为NLI任务的模板应对契合condition(即Entailment,Neutral,Contradiction敏感)。
基于此作者设计了兼顾检索(前半部分Pr)与生成式(后半部分Plm)的训练目标,来优化retriever如下:
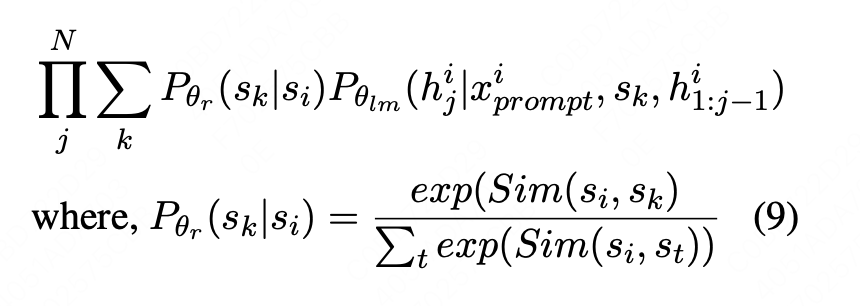
最后在预测Test集时,使用训练好的retriever来检索Train与Dev集的数据构建Demonstration。
【Arxiv】In-Context Learning with Many Demonstration Examples
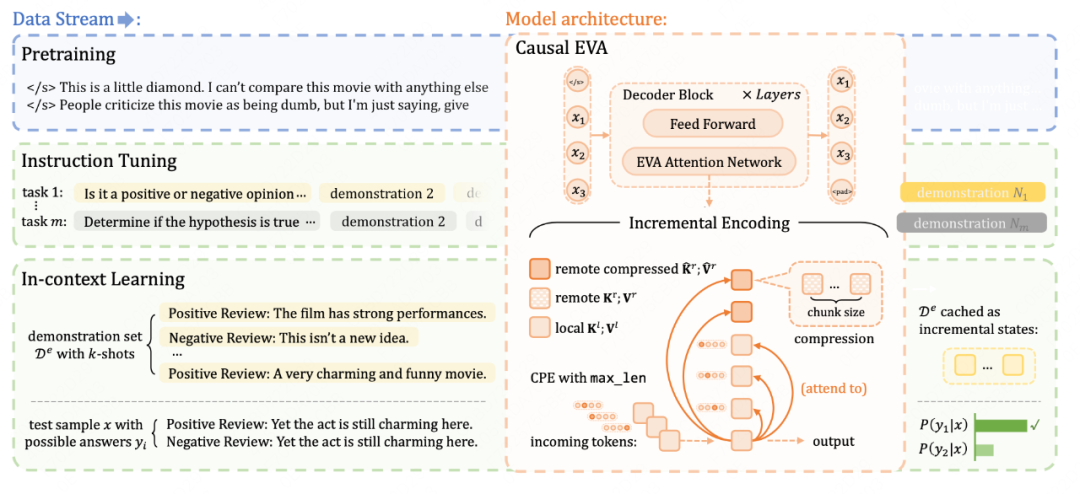
本文[8]包含instance-level与dataset-level两种demonstration选择方式:
instance level:基于test sample与训练集样本的语义相似度选择Topk个样本
dataset level:随机选择数据集中的samples作为演示示例。
总结:检索式方法优点在于简单且可解释性强,但是很依赖于Demonstration retriever的准确性。
3.2 基于验证集分数的选择
【ACL 2022】Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER
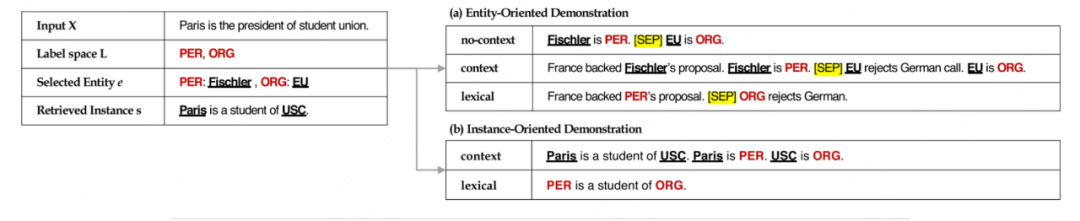
本文[9]包含一个实体级与实例级的演示策略,其中实例级demonstration以双塔模型相似度检索模式召回,而实体级的search策略为dev集的分数选择
实体级演示
对于训练集中的所有实体及其标签,作者首先构建一个标签到实体的字典 [Li:(e1,e2...en)]。然后对于标签空间中的每个标签,作者根据不同的策略,从字典中为每个标签选取一个实体,并把这些实体填到不同的演示模板中,得到不同的演示。作者采取从字典中选取实体的3种策略分别是:
(1)random:随机从列表中选择;
(2)popular:选择字典中出现频率最高的实体;
(3)search:每个标签出现频率最高的top-k个实体作为候选实体,根据这些实体的组合在Dev集上的 f1 分数,进行网格搜索。
总结:基于验证集筛选的方法优点在效果可靠,但是资源耗费极大。
3.3 基于梯度的方法
【Arxiv】Large Language Models Are Implicitly Topic Models: Explaining and Finding Good Demonstrations for In-Context Learning
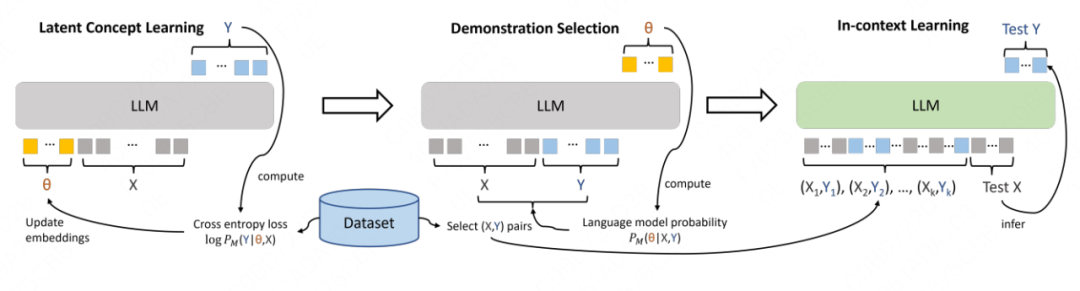
本文的demonstration选取共分为以下三步[10]
构建任务的concept token(例如情感分析任务初始化<1>,序列标注任务初始化<2>),通过拼接该concept token与对应任务数据(x,y)来获得一个concept token。
进一步从dataset中构建demonstrations,其label为concept token,在训练中观察基于梯度选择契合任务的demonstrations。
拼接选择的demonstration,进行基于ICL的预测。
总结:基于梯度的方法在效果与资源耗费较均衡。
四. ICL的实验效果
结论1:ICL中非 Ground Truth 信息仍可以带来稳定的性能增益
【EMNLP 2022】Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
链接:https://aclanthology.org/2022.emnlp-main.759/
任务:分类与多选任务
No Demos:LMs直接进行零样本预测,无提示
Demos w gold:依赖于K个标注的examples进行提示,进行预测
Demos w random labels:抽样K个examples提示,但样本labels在标签集中随机采样,而非groundtruth。
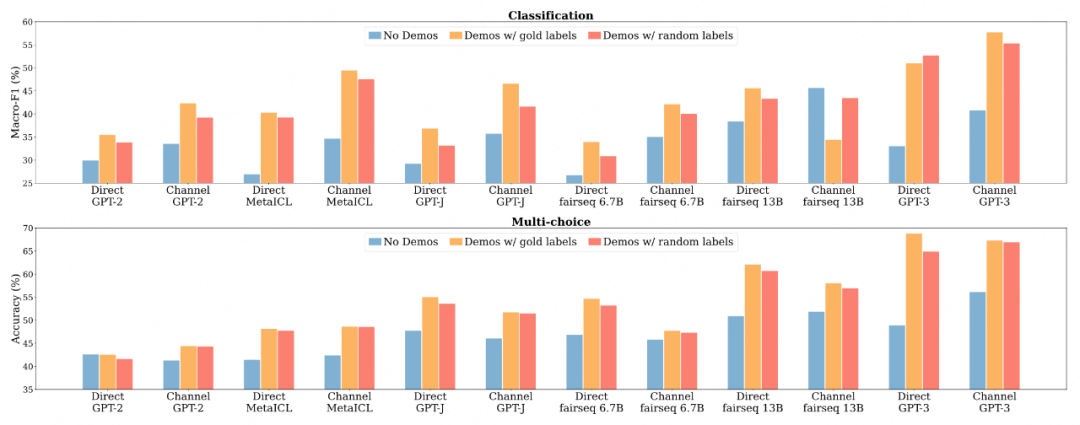
本文[11]发现,用random label替换gold label只会轻微影响性能(0-5%)。这一趋势在几乎所有的模型(700M->175B)上都是一致的:
这一结果表明,Ground Truth 信息输入标签对并不是实现性能提高的必要条件。这是违反直觉的.
结论2:ICL的性能收益主要来自独立规范的“输入空间”和“标签空间” ,以及“正确一致的演示格式”
作者分别从以下四个维度探究In-Context Learning效果增益的影响 [12]
The input-label mapping:即每个输入xi是否与正确的标签yi配对
The distribution of the input text:即x1...xk的分布是否一致
The label space:y1*...yk所覆盖的标签空间*
The format:使用输入标签配对作为格式。

通过用random word替换的方法消融这四个维度,发现输入空间的分布、标签空间、演示格式均起到至关重要的作用。
本文更细致的实验分析可见https://zhuanlan.zhihu.com/p/603650082[17]
结论3. ICL性能与预训练期间的术语频率高度相关
本文[13]在各种数学任务(加法、乘法和单位转换)上评估 GPT-J,发现ICL性能与每个实例中的术语(数字和单位)在 GPT-J(The PILE)的预训练数据中出现的次数高度相关。

上图表示:术语频率(x 轴)和上下文学习性能(y 轴)之间的相关性。
从左到右:加法、乘法、提示中无任务指示的加法和提示中无任务指示的乘法。k代表k shots。
这在不同类型的数字任务和不同的 k 值(提示中标记示例的数量)之间是一致的。一个有趣的事实是,当输入没有明确说明任务时也是如此——例如,而不是使用“问:3 乘以 4 是多少?A:12”,用“问:3#4是什么?答:12”。
与贝叶斯框架的联系
这项工作视为另一个证据,表明上下文学习主要是关于定位在预训练期间学习的潜在概念。特别是,如果特定实例中的术语在预训练数据中多次出现,则模型可能会更好地了解输入的分布。根据贝叶斯推理,这将为定位潜在概念以执行下游任务提供更好的证据。而 Razeghi 等人。特别关注模型特定实例的词频,例如输入-输出相关性的频率、格式(或文本模式) 和更多。
结论X:学术界中的其他声音
【Arxiv】 Larger language models do in-context learning differently
链接:https://arxiv.org/abs/2303.03846
谷歌近期的一篇文章,似乎得出了与之前ICL不同的结论。作者从语义先验知识与输入-标签映射两个角度入手,探究以下三种ICL设置:
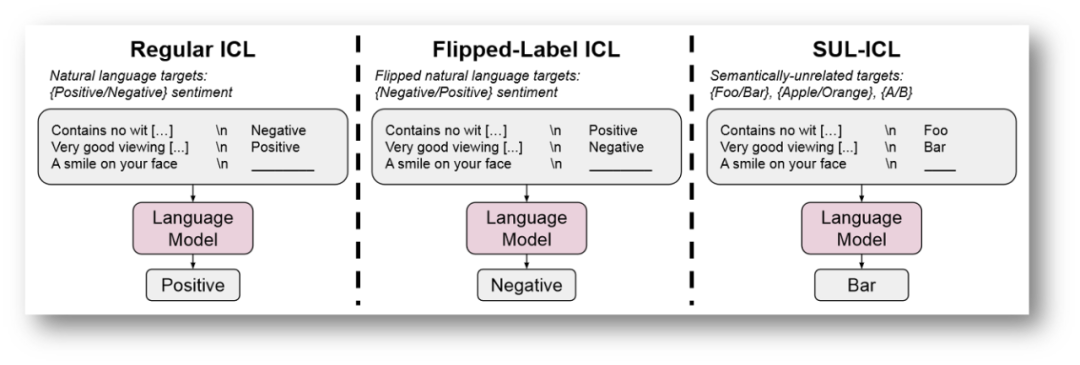
Reglar ICL: 预训练语义先验和ICL的输入标签映射都允许模型进行上下文学习。
Flipped-label ICL(翻转标签的ICL):ICL示例中的所有标签都是翻转的,这意味着语义先验知识和输入-标签映射不一致。
SUL-ICL(语义不相关的标签ICL):标签与任务无关(例如,对于情绪分析,我们使用“foo/bar”而不是“负/正”),即删除了ICL示例标签中的语义先验知识。
结论1: LLM中的ICL示例的输入-标签映射会覆盖语义先验知识。
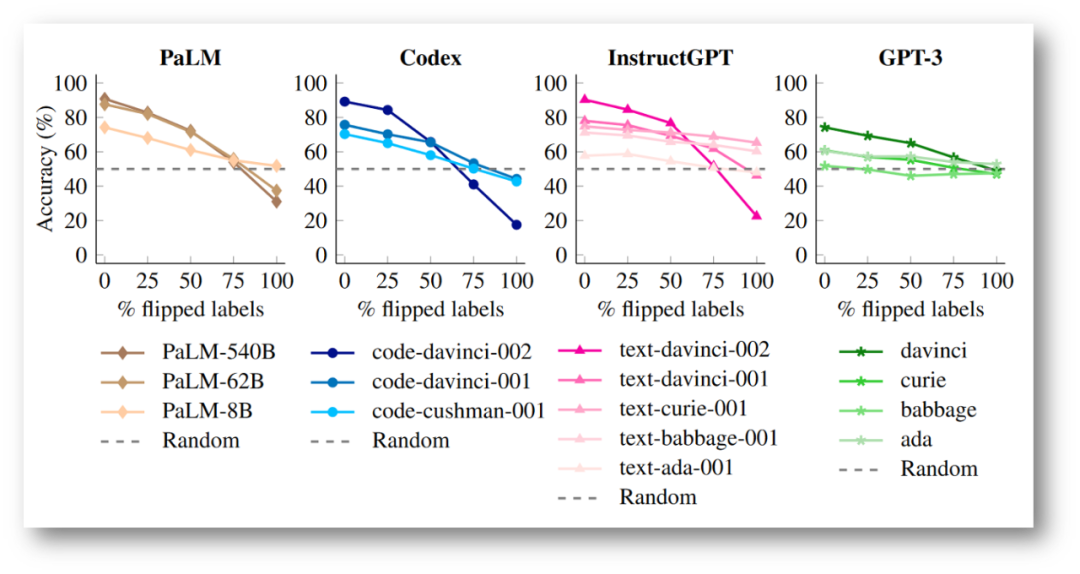
这其实与结论1产生了相悖的结论,随着ICL示例中翻转输入-标签映射增加,LLM的表现均有所下滑,且随着模型参数量的增加,翻转的misleading更剧烈,甚至会低于random baseline。
结论2: 语义上不相关的标签的ICL学习能力随着模型规模而涌现
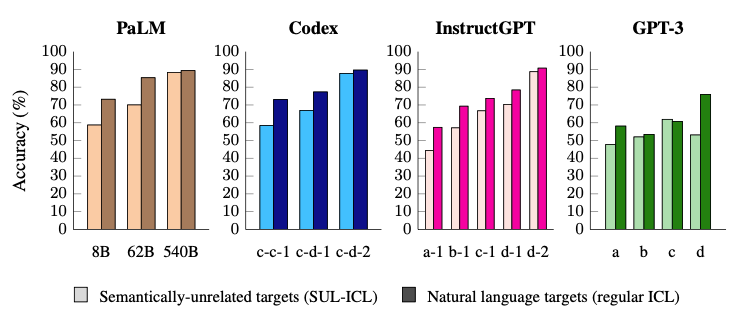
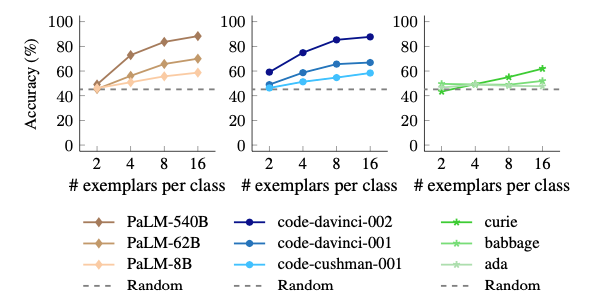
左图:模型规模可以提高常规上下文学习和SUL-ICL的性能。与大型模型相比,使用语义无关的目标会导致对小型模型受到更严重的性能下降。因此得出小模型更依赖ICL样本的语义,而大模型有能力在ICL示例中学习输入-标签映射,且能力随着模型规模而涌现。
右图:随着ICL样本数量的增加,对ICL有正向作用,且能力随着模型规模而涌现。
除此之外,还有一些其他结论,感兴趣可以阅读原文。
五. 讨论与展望
1. 为什么ICL会有效果?
从上文的框架来看,LLM从训练数据中学习到了多样的concept(人名->国家,输入输出词分布,格式,句间关系等),而ICL的示例为贝叶斯推断提供信号,提示大模型关注特定concept来生成答案。
2. ICL的能力在LLM的哪个流程获得?
以下只是我的猜测,我认为SFT部分(或者是预训练中instruction tuning相关部分),其实有文章讨论到LLM的参数量相比于训练数据是过大的,所以其实LLM在overfitting一种模式,而SFT这种模式会让LLM严格遵循instruction来生成,这样的模式也会使得LLM十分关注ICL示例的提示。
3. 一些自己认为ICL仍值得探究的点(开脑洞啦)
ICL框架下concept的可解释性?
ICL框架下concept的拆解,细化探究?
大模型与小模型,ICL能力差异的解释?
判别式与生成式模型,ICL能力的差异?
如何弥补pretrain与ICL形式的gap,提升ICL能力?
具体NLP子任务中,ICL的能力的探究?
ICL论文总结分享
ICL近期论文总结:
https://github.com/dongguanting/In-Context-Learning_PaperList
自己总结的ICL相关论文:
https://foremost-beechnut-8ed.notion.site/978f395e34234abd98cee9228a83e3c5

卡比的Scholar: https://scholar.google.com/citations?user=amozZDkAAAAJ&hl=zh-CN
参考文献
[1] Language Models are Few-Shot Learners
[2] http://ai.stanford.edu/blog/understanding-incontext/
[3]https://wjn1996.blog.csdn.net/article/details/120607050
[4] [ICLR 2022] An Explanation of In-context Learning as Implicit Bayesian Inference
[5] [DeeLIO 2022] What Makes Good In-Context Examples for GPT-3?
[6] [NAACL 2022] Learning To Retrieve Prompts for In-Context Learning
[7] [Arxiv]Few-Shot Natural Language Inference Generation with PDD: Prompt and Dynamic Demonstration
[8] [Arxiv] In-Context Learning with Many Demonstration Examples
[9] [ACL 2022] Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER
[10] [Arxiv] Large Language Models Are Implicitly Topic Models: Explaining and Finding Good Demonstrations for In-Context Learning
[11] [EMNLP 2022] Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
[12] https://zhuanlan.zhihu.com/p/603650082
[13] [EMNLP 2022] Impact of Pretraining Term Frequencies on Few-Shot Numerical Reasoning
[14] [Arxiv] Larger language models do in-context learning differently
[15]https://zhuanlan.zhihu.com/p/605449857
[17] https://zhuanlan.zhihu.com/p/603650082

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「卡比又帅又肝 」
」