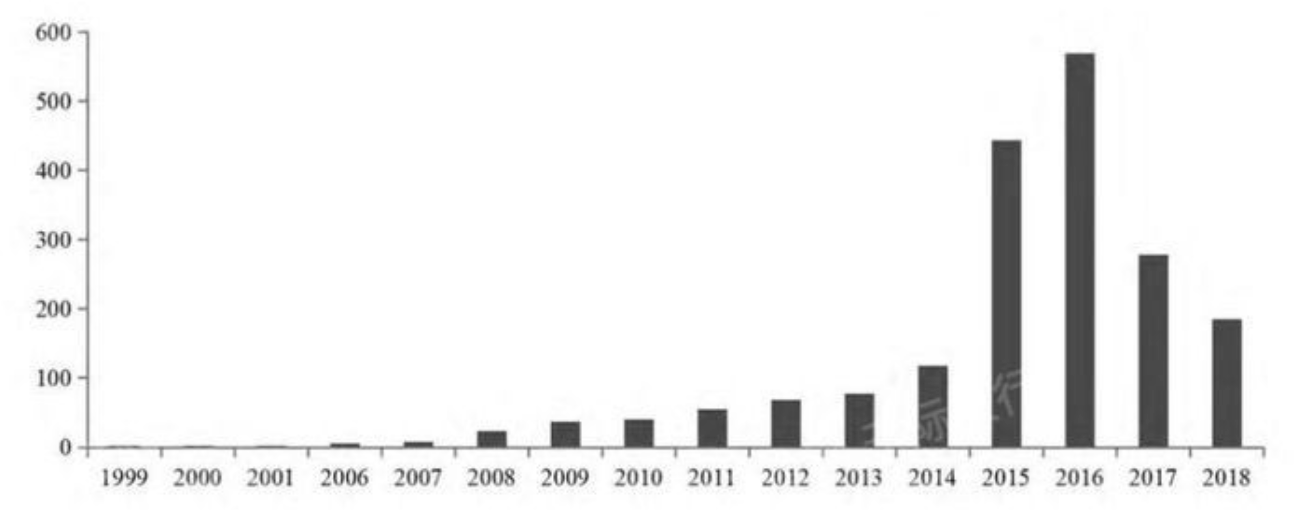
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共700人左右 1 + 2)。
最近有人问,从ORACLE 迁移项目到POSTGRESQL 在之前的项目中有将表insert into select 的操作,对比之前的ORACLE 的操作到 PG 上,对于这个操作相对的操作的时间较长。另外询问不是有并行的方式来进行数据的导入导出的操作。
POSTGRESQL 目前常用的导入导出的数据方式是 COPY ,但基于目前的COPY 命令本身并没有并行的操作。那么我们有没有办法将数据的导入和导出的方式进行并行,并且在问这个问题的时候,她还隐喻的提出这个命令在运行的时候是否履行了事务执行方式的限定。
首先我们先熟悉copy命令本身和数据库进行交互的方式也是基于PG的通信协议,此协议基于TCP/IP的协议,同时在这套协议上是支持UNIX 套接字的方式来调用这个协议的。
Copy命令中关于事务的部分, copy in 是基于类事务的,如果你的操作中途打断,那么你的表中是不会有你导入的数据记录的, copy out 不是基于事务的所以在操作中如果你中断了,那么中断前的数据会保留在外部的文件中。

所以基于导入数据是基本能保证一个完整性的部分。
在数据的导入导出中除了并行以外,实际上还有一个影响性能的部分,就是shared buffer 和 wal 日志,这两个部分也是影响POSTGRESQL 数据导入和导出的一个性能的瓶颈点。
所以PG 有了一些解决这些问题的插件,其中pg_bulkload 是一个解决数据加载速度的方式,他需要进行安装,并使用他自己的命令来进行数据的加载,通过本身的设计,跳过shared buffer 和 wal buffer 的部分。

要详细的了解pg_bulkload 的同学可以访问,下面的网站来进行更多内容的了解。https://ossc-db.github.io/pg_bulkload/pg_bulkload.html
安装中需要有PG的变量环境,否则无法进行编译,或者你使用RPM包的方式安装也可以,具体的安装就不在多说。
pg_bulkload 安装后,还需要进行create extenison 的操作,将需要 pg_bulkload 的部分加载到对应的数据库中。

那么我们废话不说,看疗效,我们通过传统的 COPY 命令和 pg_bulkload 在加载数据的情况下,到底有多大的差距。
我们产生一个测试来比较 COPY 和 PG_BULKLOAD 的效果区别,我们产生一个一个亿的数据表,然后将数据导出变成 CSV 文件
截图1 下面的截图中,从CSV 文件到数据库中,我们大约使用了 7分30秒的时间

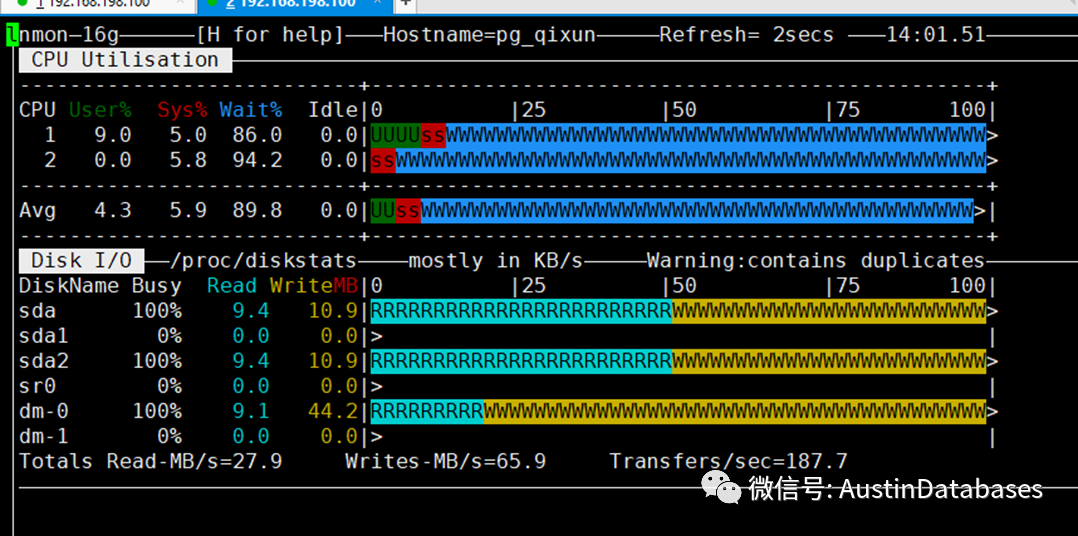
整体从NMON 查看系统的状态,总体的系统都在满负荷的而工作。
更换了 pg_bulkload 后,整体的进行重复性的工作,工作中系统满负荷的工作时间不是太长,工作时间缩短到 4分钟。
对比整体提高了接近 50%的时间。

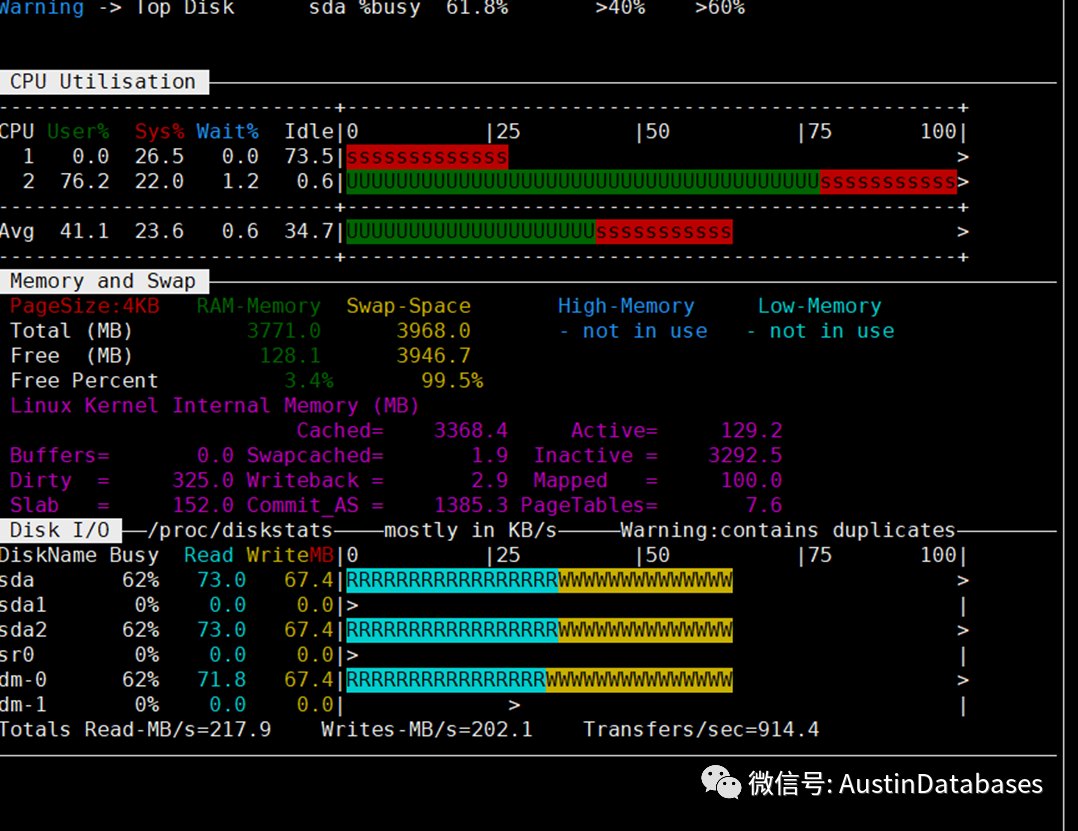
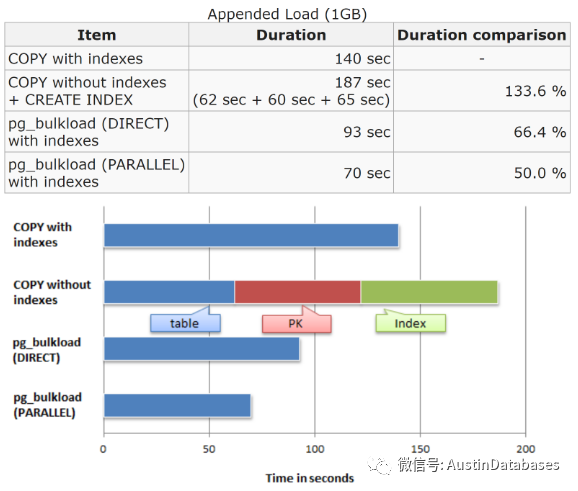
这里找到pg_bulkload 自己的压力测试图,在这里标称的结果与上面的测试结果类似。
下面在说说 pg_bulkload 的参数和常用的使用方式

这里 -i 为你数据文本文件的位置, -O是你的数据库中的表的文件 -l 为数据的日志文件 -u 为遇到重复数据对重复数据进行记录 -o 是相关的程序的选择项
pg_bulkload -i /pgdata/account.csv -O pgbench_accounts_new -l /pgdata/output.log -P /home/postgres/error_bad.txt -o "TYPE=CSV" -o "DELIMITER=|" -d postgres -U postgres -h 127.0.0.1
其中的 -o 为操作中的各种现在如 导入的数据的类型 以及 文件中的间隔符号等
实际上在上面的操作中我们并没有进行并行的开启,pg_bulkload是支持并行的,那么我们将并行打开后,再次测试相关的执行同样数据的导入的速度。在打开并行后,整体的插入速度为 1分43秒,相对于不开并行导入的速度,提高了百分之 65% 左右。

所以,pg_bulkload 的确是在导入数据提高速度方面在硬件不变的情况下,有了很大的提升。