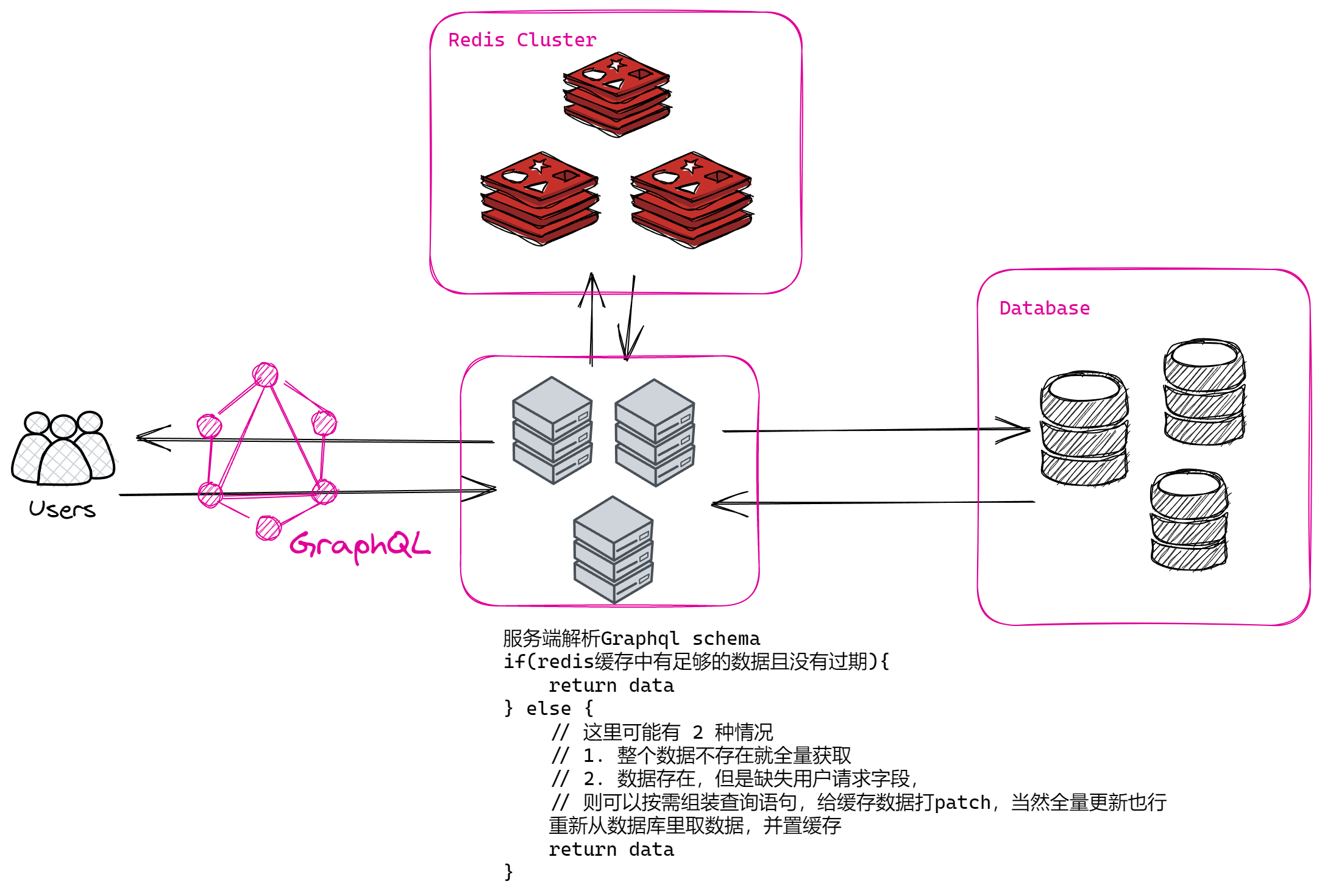
Flink Join
一、Fink IntervalJoin
1、简要说明
Flink 中基于 DataStream 的join,只能实现在同一个窗口的两个数据流进行Join。但是实际中会存在数据乱序或者延时情况,导致两个流的数据进度不一致。无法在同一个窗口内Join。
Flink 基于 KeyedStream 提供interval join机制 ,intervaljoin 连接两个KeyedStream,按照相同的Key在一个相对数据时间的时间段内进行连接。
SingleOutputStreamOperator<Object> process = vinNS.intervalJoin(vinESD0).between(Time.milliseconds(-5), Time.milliseconds(5))
.process(new ProcessJoinFunction<String, String, Object>() {
@Override
public void processElement(String s, String s2, Context context, Collector<Object> collector) throws Exception {
System.out.println("res"+s + ":" + s2);
collector.collect(s + ":" + s2);
}
});
vinNS和vinESDO 两个topic通过 keyby vin码 得到两个 KeyedStream,再进行intervalJoin操作,between方法传递两个参数 lowerBound和upperBound,用来判断右边的流可以与那个时间范围内的左边的流进行关联(leftElement.timestamp + lowerBound <= rightElement.timestamp <= leftElement.timestamp + upperBoundBound)即:是以右边流为基表关联左边的流。
2、简要源码
@Deprecated //表示当前接口已经不推荐使用
@PublicEvolving //当前接口实现时需要指定生产者所要传输的对象类型
1、Interval join必须指定的时间类型为EventTime,否则直接抛出 UnsupportedTimeCharacteristicException 异常

2、两个KeyedStream在进行IntervalJoin调用between方法(默认是闭区间,可以通过下面设置为开区间 exclusive)

3、使用proess 实现 ProcessJoinFunction 入参是 两个流的类型和出参的类型,IntervalJoined left.connect(right).keyBy(keySelector1,keySelector2) 因为left.connect(right)返回的是 ConnectedStreams, keySelector1/2是指demo中两个数据流的keyBy条件,类似与flinksql join中的 on换类了,现在是IntervalJoinOperator类中了,重点也就在IntervalJoinOperator中


4、IntervalJoin接口继承了AbstractUdfStreamOperator抽象类,实现了TwoInputStreamOperator和Triggerable(触发器)接口。
/** @param <K>键的类型,我们根据它来连接元素。
@param <T1>左流元素的类型。
@param <T2>右流中元素的类型。
@param <OUT>用户自定义函数创建的输出类型。*/

IntervalJoinOperator覆盖了AbstractUdfStreamOperator(StreamOperator定义)的open、initializeState方法,它在open方法里头创建了InternalTimerService,传递的Triggerable参数为this,即自身实现的Triggerable接口;在initializeState方法里头创建了leftBuffer和rightBuffer两个MapState

IntervalJoinOperator实现了TwoInputStreamOperator接口定义的processElement1、processElement2方法(TwoInputStreamOperator接口定义的其他一些方法在AbstractUdfStreamOperator的父类AbstractStreamOperator中有实现);processElement1、processElement2方法内部都调用了processElement方法,只是传递的relativeLowerBound、relativeUpperBound、isLeft参数不同以及leftBuffer和rightBuffer的传参顺序不同。

processElement方法里头实现了intervalJoin的时间匹配逻辑,它会从internalTimerService获取currentWatermark,然后判断element是否late,如果late直接返回,否则继续往下执行;之后就是把element的value添加到ourBuffer中(对于processElement1来说ourBuffer为leftBuffer,对于processElement2来说ourBuffer为rightBuffer);之后就是遍历otherBuffer(去遍历另一条流的MapState)中的每个元素,挨个判断时间是否满足要求(即ourTimestamp + relativeLowerBound <= timestamp <= ourTimestamp + relativeUpperBound)将数据输出给ProcessJoinFunction调用,ourTimestamp表示流入的数据时间,timestamp表示对应join的数据时间,不满足要求的直接跳过,满足要求的就调用collect方法(collect方法里头执行的是userFunction.processElement,即调用用户定义的ProcessJoinFunction的processElement方法);


若左右两个流都能从对方取到值,以结果 Timestamp 为两边流最大的执行processElement方法

之后就是计算cleanupTime,调用internalTimerService.registerEventTimeTimer注册清理该element的timer,定时的清理时间,就是当下流入的数据的时间+relativeUpperBound,当watermark大于该时间就需要清理。
前面取到值后遍历对方流的时间戳。对于左边的流 遍历规则左边流时间戳+1s<=右边时间戳<=左边流时间戳+5s
右边的流:右边时间戳-5s<=左边流时间戳<=右边时间戳-1s
a。如果为左边流数据到达,调用processElement1方法
此时relativeUpperBound为5,relativeLowerBound为1,relativeUpperBound>0,所以定时清理时间为10+5即15s
当时间达到15s时,清除左边流数据,即看右边流在15s时,需要查找的左边流时间范围
10s<=左边流时间戳<=14s,所以watermark>15s时可清除10s的数据。
b。如果为右边流数据到达,调用processElement2方法
此时relativeUpperBound为-1,relativeLowerBound为-5,relativeUpperBound<0,所以定时清理时间为10s
当时间达到10s时,清除右边流数据,即看左边流在10s时,需要查找的右边流时间范围
11s<=右边流时间戳<=15s,所以可以清除10s的数据。


/**
@param lowerBound计算元素是否应该连接的下限
@param upperBound计算元素是否应该连接的上限
@param lowerBoundInclusive—是否包含时间戳与下限匹配的元素
@param upperBoundInclusive -是否包含时间戳与上界匹配的元素
@param udf一个用户定义的{@link ProcessJoinFunction},当两个元素被调用时*/

3、学习文档
1、 TypeSerializer Flink的序列化器
Flink 数据类型与序列化
2、Flink的Process Function 侧输出流
Flink的Process Function
3、AbstractUdfStreamOperator 介绍
https://zhuanlan.zhihu.com/p/466333577
4、本文参照文档
https://blog.csdn.net/weixin_34247155/article/details/87993564?ops_request_misc=&request_id=&biz_id=102&utm_term=CLEANUP_TIMER_NAME&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-87993564.142v86control,239v2insert_chatgpt&spm=1018.2226.3001.4187