Linux
基础知识
基础
启动过程: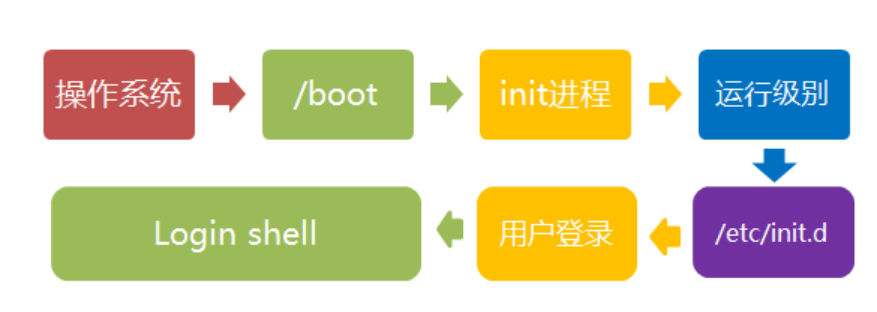
- 内核的引导。
- 运行 init。
- 系统初始化。
- 建立终端 。
- 用户登录系统。
命令介绍
磁盘
#文件
#a:相当於 -pdr 的意思,至於 pdr 请参考下列说明;(常用);f:为强制(force)进行;i:交互模式进行;l:进行硬式连结(hard link)的连结档创建;p:连带操作(例如连通属性一起复制、将子目录所有空文件一并删除等);r:递归操作;s:符号连结档 (symbolic link),亦即『捷径』文件
ls #(英文全拼:list files): 列出目录及文件名
cd #(英文全拼:change directory):切换目录
pwd #(英文全拼:print work directory):显示目前的目录
mkdir [-mp] 目录名称 #创建目录
rmdir [-p] 目录名称 #(英文全拼:make directory):创建一个新的目录
rmdir #(英文全拼:remove directory):删除一个空的目录
cp [-adfilprsu] 来源档(source) 目标档(destination) #(英文全拼:copy file): 复制文件或目录
rm [-fir] 文件或目录 #(英文全拼:remove): 删除文件或目录
mv #(英文全拼:move file): 移动文件与目录,或修改文件与目录的名称
#文件
#文件阅读
cat:#顺序打开这个文件(按行);
tac:#倒叙打开整个文件(按行);
more:#按页打开文件(可通过空格换页、enter下放一行、/查找、?查找);
less:#类似more,可通过上下键盘上下翻页、q退出、/查找、?向上查找;
tail 20 #(最后20行)
head 20 #(头20行)
# option包括:-user <name>:查找用户xxx的文件; -mtime n:查找n天内修改过的文件 -newer <name>:查找比xxx文件新的文件 -name <name> 查找名为name的文件
find [PATH] [option] [action] #
#磁盘管理命令:df:列出文件系统的整体磁盘使用量、du:检查磁盘空间使用量、fdisk:用于磁盘分区
# k\m:以k\m为单位显示,h以人性化格式(KB,MB,GB等),H十进制人性化格式,
df [-ahikHTm] [目录或文件名]
du [-ahskm] 文件或目录名称
#tar和gz
gzip [options][文件或者目录] #命令压缩文件或文件夹为 .gz文件
# z:解压.gz包成tar包;同理j:解压bz2文件、J:解压xz文件 x:解压选项 v:显示进度 f:使用档案文件
# c:打包选项
tar # 解压/打包tar包
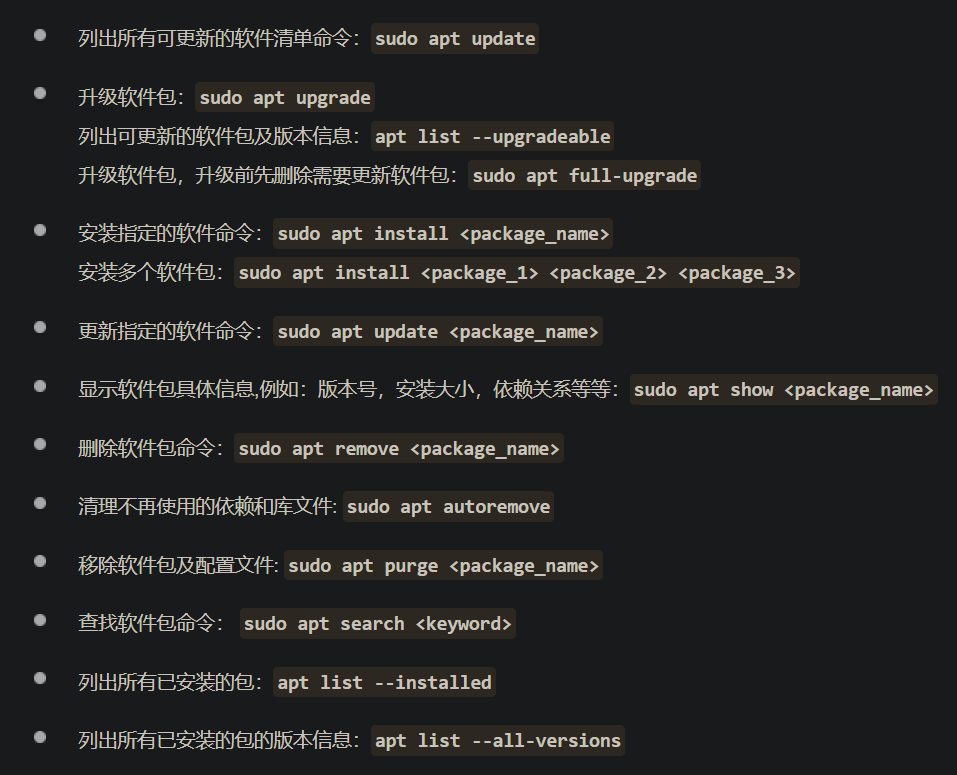
yum #yum 提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。
#options:即-xxxx,可选的有:y:安装过程全部选 yes;q:不显示安装过程
# command:执行的操作,包括:check-update:检查更新;update:更新 <name>; install <name>:安装
# search <name>:查找; remove <name>:移除 list:列出当前所有可安装yum包
yum [options] [command] [package ...]
apt #apt和yum类似同样是进行安装的工具
apt [options] [command] [package ...]
管道
#管道命令就是加上 |
#下面为常用的搭配管道命令使用的命令
#命令是查找,是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
# v:反向选择(选择不符合正则匹配的部分)
grep [options] [string]
进程线程
#进程命令
# e/A:显示所有进程; u [name]:显示某一用户(name为空着所有用户的进程)的所有进程; x:无终端的进程 w:加宽显示更多资讯 f:扩展输出
ps [options] #显示进程
pstree [options] #显示进程树
kill
ps的显示结果如下:

- USER:进程所属用户名
- PID:父进程id
- CPU/MEN:CPU和内存的使用率
- VSZ:占用的虚拟记忆体大小
- RSS: 占用的记忆体大小
- TTY:终端的装置号码
- STAT: 该行程的状态:
- D: 无法中断的休眠状态 (通常 IO 的进程)
- R: 正在执行中
- S: 静止状态
- T: 暂停执行
- Z: 不存在但暂时无法消除
- W: 没有足够的记忆体分页可分配
- <: 高优先序的行程
- N: 低优先序的行程
- L: 有记忆体分页分配并锁在记忆体内 (实时系统或捱A I/O)
- START: 行程开始时间
- TIME: 执行的时间
- COMMAND:所执行的指令
系统状态
#内存使用情况
#-b 以Byte为单位显示内存使用情况。-k 以KB为单位显示内存使用情况。-m 以MB为单位显示内存使用情况。-h 以合适的单位显示内存使用情况,最大为三位数,自动计算对应的单位值。
#-o 不显示缓冲区调节列。-s<间隔秒数> 持续观察内存使用状况。-t 显示内存总和列。-V 显示版本信息。
free [-bkmotV][-s <间隔秒数>]
#网络状态 t:tcp端口使用情况 u:udp端口使用情况 a:所有端口使用情况 p:使用Socket的程序识别码和程序名称。 s:显示网络工作信息统计表。
netstat [-acCeFghilMnNoprstuvVwx][-A<网络类型>][--ip]
#获取和解析网页
curl [options...] <url>
常用命令
ps
ps <options>
- PS命令常用在查看进程状态
常用输出
#输出运行的进程的详细信息
ps -ef
#输出进程全部信息(CPU使用率、使用者,开始时间等等)
ps -aux
排序输出
#pid降序排序输出
ps -ef --sort=-pid
#指定输出格式,按cpu使用率降序输出
ps -eo pid,pmem,pcpu,user --sort=-pcpu
du和wc
- 常用语统计文件(文件夹大小),wc只支持bytes计数,du则可以转化为k、m等单位;
#以kB的形式输出文件大小
du -sk filename或者目录名
find
find 目录 命令和命令参数
- 常用:
-type、-name、-ctime、atime find /目录 -name "文件/文件夹名的正则表达式"
#查找xxx.docker文件
find / -name "*.docker"
#查找修改时间是7天内的文件
find / -type f -mtime +7
lsof
-
任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符;所以可以通过lsof查看端口使用情况;
- -i<条件> 列出符合条件的进程。(4、6、协议、:端口、 @ip )
- -p<进程号> 列出指定进程号所打开的文件
https://www.jianshu.com/p/a3aa6b01b2e1
#80端口
lsof -i:80
lsof -p
sort和uniq
sort用于排序,uniq去除相邻的重复的行,一般uniq会和sort一起使用;
sort
- -n 按数字进行排序
- -d 按字典序进行排序
- -r 逆序排序
- -k N 指定按第N列排序
uniq
- -c:每列旁边(前)显示该行重复出现的次数
- -d:仅显示重复出现的行列。
sort filename -nrk 2 | uniq
sort fiename -d | uniq -c
tr
- 几乎是最常用的命令之一,可以对文本字符进行删除或者转化:
- 替换:
tr [字符集1] [字符集2]- 字符集:
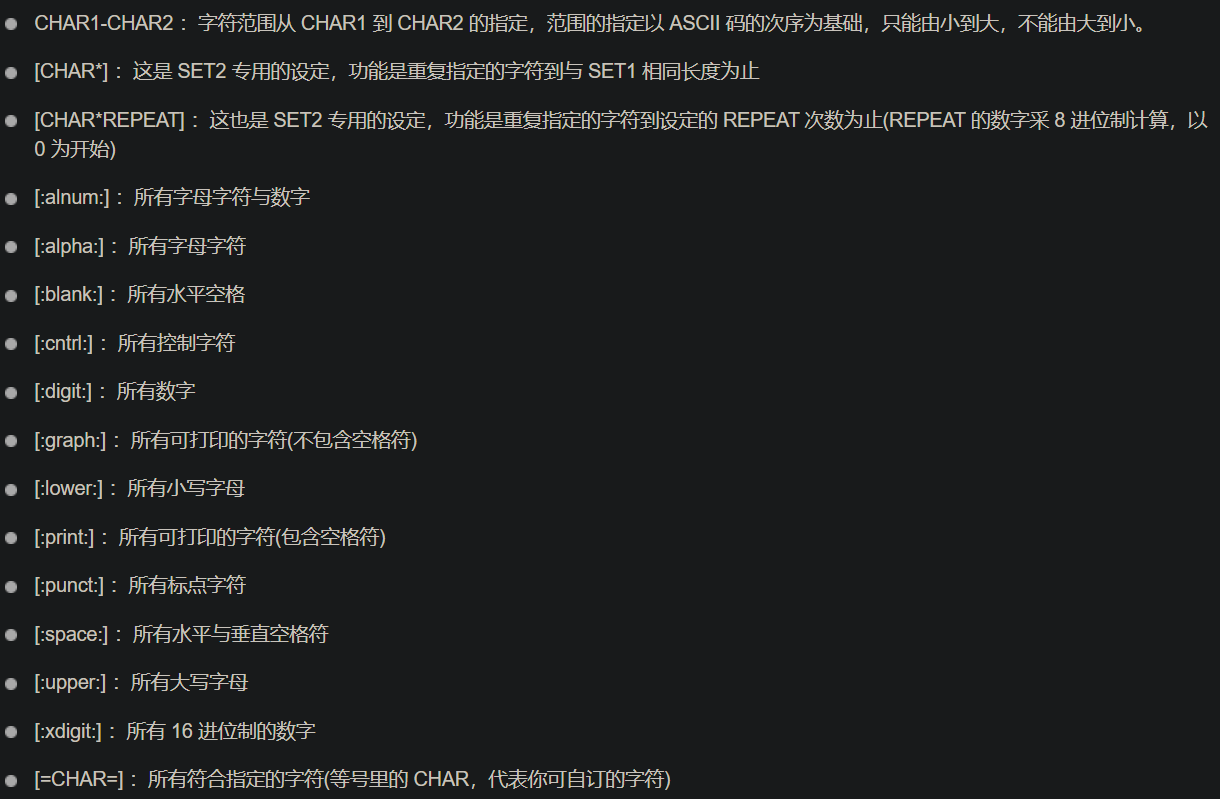
- 字符集:
- 删除指令字符(\n、\r、\t等):-d
- 压缩:-s
- 替换:
- -c:翻转(即不符合的进行操作)
#将a替换为A,b替换为B,c替换为C
tr "abc" "ABC"
#将a替换为A,b替换为B,c替换为C……
tr [a-z] [A-Z]
#删除windows编辑的文本出现不可见的^M
tr -d "\r"
#将PATH环境变量的:替换为\n
echo $PATH | tr : "\n"
#删除相邻重复的字符
tr -s [a-zA-Z]
netstat
shell
规范
规范:一般使用.sh作为文件后缀名;
# 执行方法
chmod +x ./[name.sh] #使脚本具有执行权限
[./name.sh] #直接进入sh文件,执行脚本
#表示注释,但是#!表示Bourne shell解释器所在的位置,所以一般shell第一行就是 #!/bin/sh
#但是对于bash这是:Bash是Bourne shell的替代品,属GNU Project,二进制文件路径通常是/bin/bash。
#在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 #!/bin/sh,它同样也可以改成
#!/bin/bash
#!/bin/sh
#多行注释
:<<!
注释内容
!
#或
:<<'
注释内容...
'
#或
:<<EOF
注释内容...
注释内容...
注释内容...
EOF
基础
快速入门
变量
-
变量:命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。不能使用bash里的关键字
-
基础
-
定义:变量名 = 变量内容;
-
使用:${变量名}
-
删除:unset 变量名 ######不能删除只读变量
-
name="1234" echo ${name} unset name
-
-
只读变量(定义后通过readonly设置)
-
readonly 变量名
-
name="1234" readonly name echo ${name}
-
-
变量类型
- 1) 局部变量 局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
- 2) 环境变量 所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
-
- 3) shell变量 shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
-
字符串变量:可以是单引号也可以是双引号,或者没有双引号
-
区别
- 单引号不允许转义,单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
-
字符串(数组)操作:shell只有一维数组
-
拼接:
-
#字符串定义 name='111' #下面三个拼接等效 name1='2222'${name} name3="2222${name}" name3="2222"${name} #数组定义 array_name=(value0 value1 value2 value3)
-
-
字符串转数组
-
#借用tr指令 tr [OPTION]…SET1[SET2] #通过:分割字符串 arrayName=(`echo $name | tr ':' ' '` )
-
-
获取字符串(数组)长度:${#}
-
#获取字符串长度,字符串等于一个字符数组 name='111' ${#name} #获取数组长度 ${#name[0]}
-
-
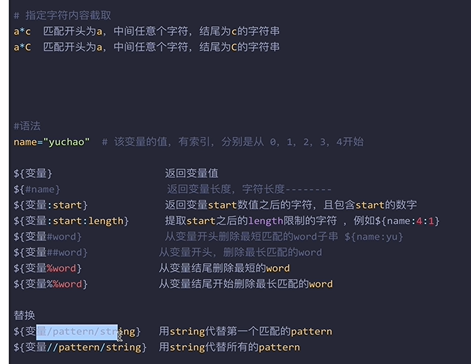
截取字符串(数组)部分内容
-
${name:from:end} #from和end均为索引例如1 2 3等 ${name[*]} -
使用@ 或 * 可以获取数组中的所有元素
-
-
-
传入变量
-
很多时候执行脚本语言的时候可以尾部传入变量实现动态的编程
-
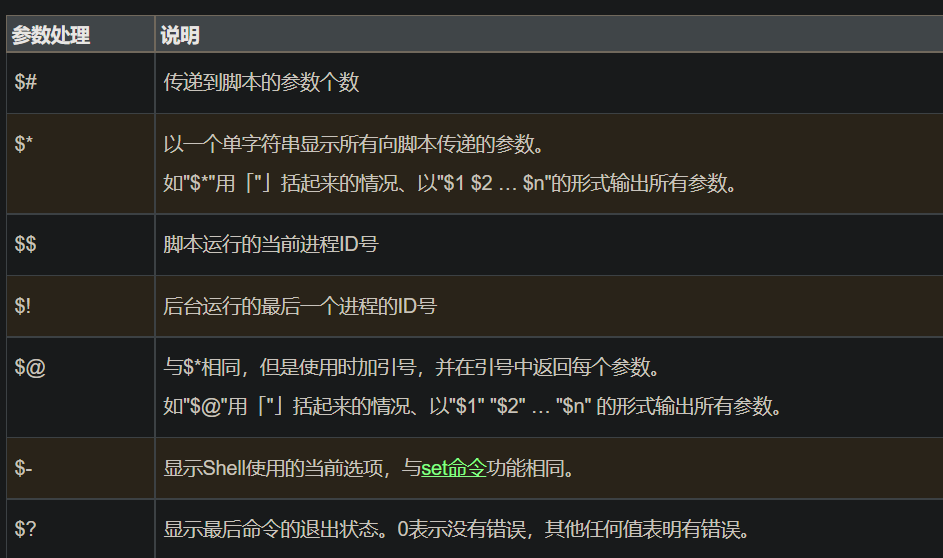
通过$S{number}获取,其中小于10可以不加大括号;
-
$S0默认为文件名
-
#执行test.sh时 ./test.sh args1 args2
-
-
执行脚本是参数
-
-

运算
原生bash不支持简单的数学运算,但是可以通过其他命令来实现,例如 awk 和 expr,expr 最常用。
-
算术运算
-
expr 是一款表达式计算工具,使用它能完成表达式的求值操作。
-
#expr:可以进行算术运算:+ - * \ % =(赋值运算) == != #表达式通过`` 反引号包裹 #算数运算需要通过空格隔开 # *运算必须加入转义字符 name=`expr 1 + 2` name=`expr 2 \* 3`
-
-
关系运算
-
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
-
num1=1 num2=2 if [ ${num1} -gt ${num2} ] then # xxxx else # xxxx fi -
运算符 说明 举例 -eq 检测两个数是否相等,相等返回 true。 [ $a -eq $b ] 返回 false。 -ne 检测两个数是否不相等,不相等返回 true。 [ $a -ne $b ] 返回 true。 -gt 检测左边的数是否大于右边的,如果是,则返回 true。 [ $a -gt $b ] 返回 false。 -lt 检测左边的数是否小于右边的,如果是,则返回 true。 [ $a -lt $b ] 返回 true。 -ge 检测左边的数是否大于等于右边的,如果是,则返回 true。 [ $a -ge $b ] 返回 false。 -le 检测左边的数是否小于等于右边的,如果是,则返回 true。 [ $a -le $b ] 返回 true。
-
-
逻辑运算和布尔运算
-
#逻辑运算 &&:并且; ||:或; #布尔运算 -a:与;-o:或;!:非; if [ $a -lt 100 -a $b -gt 15 && $b -gt 100 ] then echo "$a 小于 100 且 $b 大于 15 : 返回 true" else echo "$a 小于 100 且 $b 大于 15 : 返回 false" fi
-
-
字符串运算
-
运算符 说明 举例 = 检测两个字符串是否相等,相等返回 true。 [ $a = $b ] 返回 false。 != 检测两个字符串是否不相等,不相等返回 true。 [ $a != $b ] 返回 true。 -z 检测字符串长度是否为0,为0返回 true。 [ -z $a ] 返回 false。 -n 检测字符串长度是否不为 0,不为 0 返回 true。 [ -n “$a” ] 返回 true。 $ 检测字符串是否为空,不为空返回 true。 [ $a ] 返回 true。 -
if [ $a || -z $a ] then # else # fi
-
-
文件运算
-
检查文件各种属性(权限、存在)
-
操作符 说明 举例 -b file 检测文件是否是块设备文件,如果是,则返回 true。 [ -b $file ] 返回 false。 -c file 检测文件是否是字符设备文件,如果是,则返回 true。 [ -c $file ] 返回 false。 -d file 检测文件是否是目录,如果是,则返回 true。 [ -d $file ] 返回 false。 -f file 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 [ -f $file ] 返回 true。 -g file 检测文件是否设置了 SGID 位,如果是,则返回 true。 [ -g $file ] 返回 false。 -k file 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 [ -k $file ] 返回 false。 -p file 检测文件是否是有名管道,如果是,则返回 true。 [ -p $file ] 返回 false。 -u file 检测文件是否设置了 SUID 位,如果是,则返回 true。 [ -u $file ] 返回 false。 -r file 检测文件是否可读,如果是,则返回 true。 [ -r $file ] 返回 true。 -w file 检测文件是否可写,如果是,则返回 true。 [ -w $file ] 返回 true。 -x file 检测文件是否可执行,如果是,则返回 true。 [ -x $file ] 返回 true。 -s file 检测文件是否为空(文件大小是否大于0),不为空返回 true。 [ -s $file ] 返回 true。 -e file 检测文件(包括目录)是否存在,如果是,则返回 true。 [ -e $file ] 返回 true。
-
流程控制
shell所有流程没有大括号这说法
-
if
-
if-else
#if使用 [] if[ conditions ] then xxxx xxxx else xxxxx fi -
if-elif-else
-
if[ conditions ] then xxxx xxxx elif then xxxxx else xxxxx fi
-
-
for:支持break和continue
-
#方法1 和java的for几乎一样除了:(()) for ((var;conditions;command1)) do done #方法2 for var in item1 item2 ... itemN do command1 command2 ... commandN done
-
-
while:支持break和continue
-
#同理while也是(()) while ((condition)) do command done
-
-
util:支持break和continue
-
until condition do command done
-
-
case
-
case 值 in 模式1) command1 command2 ... commandN ;; 模式2) command1 command2 ... commandN ;; esac
-
练习
- 如果没有输出文件则创建,有则清空;然后在文件打印9*9乘法表
#!/bin/bash
if [ -f fifo.file ]
then
printf > $PWD/fifo.file
else
touch $PWD/fifo.file
fi
for(( i=1;$i<=9;i++)) do
for(( j=1;j<=$i;j++)) do
printf "%d " `expr $i \* $j ` >> $PWD/fifo.file
done
echo "" >> $PWD/fifo.file
done
函数
function name(){
#下面分别表示取出传入的第i个参数
echo "第一个参数为 $1 !"
echo "第二个参数为 $2 !"
echo "第十个参数为 $10 !"
echo "第十个参数为 ${10} !"
echo "第十一个参数为 ${11} !"
echo "参数总数有 $# 个!"
echo "作为一个字符串输出所有参数 $* !"
return true
}
res=name 1 2 3 4 5 6 7 8 9 34 73
文件包含
#Shell 也可以包含外部脚本,通过 . 文件目录名引入
#引入/usr/bin/test.sh文件
. /usr/bin/test.sh
输入输出
-
read:
-
echo和printf
-
# echo用于字符串的输出。\n:换行 \c 后面输出拼接在本行 echo "aaaa\n" #date日期 echo `date` #默认的 printf 不会像 echo 自动添加换行符,我们可以手动添加 \n -
printf制表符
-
序列 说明 \a 警告字符,通常为ASCII的BEL字符 \b 后退 \c 抑制(不显示)输出结果中任何结尾的换行字符(只在%b格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略 \f 换页(formfeed) \n 换行 \r 回车(Carriage return) \t 水平制表符 \v 垂直制表符 \ 一个字面上的反斜杠字符 \ddd 表示1到3位数八进制值的字符。仅在格式字符串中有效 \0ddd 表示1到3位的八进制值字符
-
-
输入输出重定向
-
命令 说明 command > file 将输出重定向到 file。 command < file 将输入重定向到 file。 command >> file 将输出以追加的方式重定向到 file。 n > file 将文件描述符为 n 的文件重定向到 file。 n >> file 将文件描述符为 n 的文件以追加的方式重定向到 file。 n >& m 将输出文件 m 和 n 合并。 n <& m 将输入文件 m 和 n 合并。 << tag 将开始标记 tag 和结束标记 tag 之间的内容作为输入。
-
文件操作
awk和sed
- 两者都是主要对文件或者流进行操作的命令
- sed全名叫stream editor,流编辑器,用程序的方式来编辑文本;sed的核心是正则;
- awk,经常用于格式化输出,也就是将数据按照我们想要的方式来显示,并且可以做一些基本的统计工作。运作模式是“预处理+逐行处理+最终处理”
sed命令
- 非交互式的流编辑器。它修改文件的输出但不会修改源文件,除非使用shell重定向获取i来保存结果。默认情况下,所有的输出行都被打印到屏幕上。
- sed实现是基于Buffer的概念,类似IO 的通道:首先sed把当前正在处理的行保存在一个临时缓存区中(也称为模式空间),然后处理临时缓冲区中的行,完成后把该行发送到屏幕上,并读取下一行到缓存中。
使用方式
sed [options] 'command' file(s)
# scriptfile:即执行的shell文本,保存了编写的想要执行的sed命令
sed [options] -f scriptfile file(s)
options
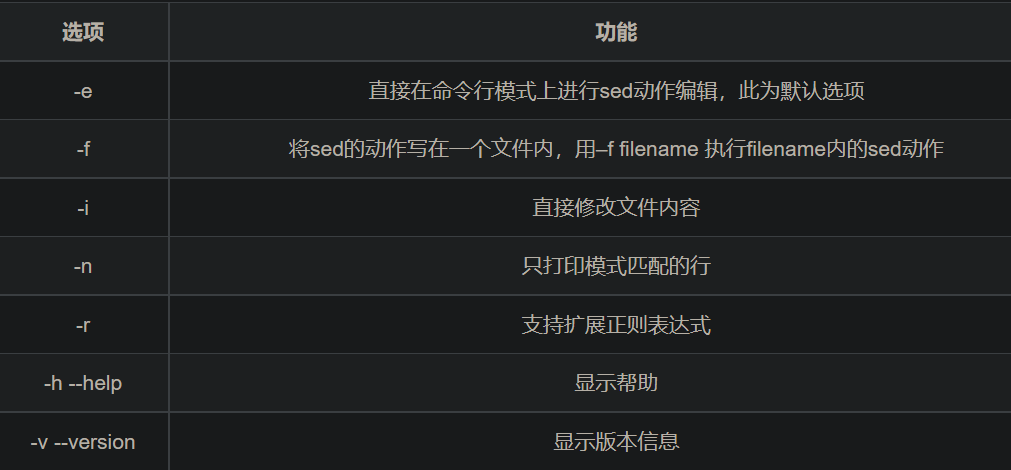
- 经常会用到的:
- -i:将修改保存到文件中
- -n:只打印匹配的行
- -f:执行sed动作的shell脚本
command
- 主要包括增删改三部分、以及辅助操作:显示行号等;其中增删改又包括:buffer、行、单词三部分;换句话说可以对buffer、行、单词进行相关操作
- 增
- buffer:H、G
- 行:a、i
- 单词(单词的插入相当于原单词+插入单词):s
- 删
- buffer:D
- 行:d
- 单词(单词删除相当于替换空串):s
- 改(替换)
- buffer:g
- 行:c
- 单词:s
例子
s命令
s/被修改单词/目标单词/单词位置或者fromLine,endLines/被修改单词/目标单词/单词位置
#基本使用:
#将第一行第二个hello后所有hello替换为bye
sed "s/hello/bye/2g"
#将第三个hello删除
sed "s/hello//3"
#在所有hello后插入s
sed "s/hello/hellos/g"
#将第一到第三行的所有hello后插入s
sed "1,3s/hello/hellos/g"
#多模式(即多条匹配命令)
sed -e "1,3s/my/your/g" -e "3,$s/a/b/g"
#或者
sed "1,3s/my/your/g; 3,$s/a/b/g"
-
自定义输出和正则表达式
-n + p:-n取消默认输出、p:打印匹配的模式圆括号输出:通过
\num获取使用()括起来的内容正则表达式:下面的例子获取表达式的
cat fifo.file | sed -n 's/^\.\([a-zA-Z0-9\-]*\) \.\([a-ZA-Z0-9\-]*\){\([a-zA-Z0-9\-]*\):\([0-9]*\)px}$/\1 \2 \3\ \4/gp'
#正则表达式:.[a-zA-Z0-9\-]* .[a-zA-Z0-9\-]*{.[a-zA-Z0-9\-]*:.[0-9]*px}
#圆括号:通过转移字符括起来了四个正则表达式的内容,然后通过/1 /2等输出
#-n p:输出指定内容
a、i、d、c命令
- 四个命令基本格式相同
a或者/匹配行/a获取指定行 a
#在包含/new-pmd的行后面添加 >>>>>>>>>
sed '/new-pmd/a >>>>>>>'
#所有行添加
sed 'a >>>>>>>>>>'
#指定第三行
sed '3 a >>>>>>>>>>'
Buffer命令
H、h、G、g:命令
#对于文本
##
# one
# two
# three
$ sed 'H;g' t.txt
#输出结果
one
one
two
one
two
three
正则表达式

awk命令
awk options 'condition{command} condition{command} ... ...' 文件名或者awk -f scriptfile file(s);总体和sed类似,不过其具有更强大的能力;
- awk在格式化输出和列处理能力非常强;
- awk本质是一个for循环,循环读入当前行,并设置一系列内置变量;
- awk语法格式类似于c语言,所以可编程能力非常强;
- 支持变量(支持数组)
- 支持流程控制(循环和跳转)
- 内置函数(允许自定义、内置时间、字符串等函数)
- 内置变量(包括分隔符、行列变量)
变量
内置变量
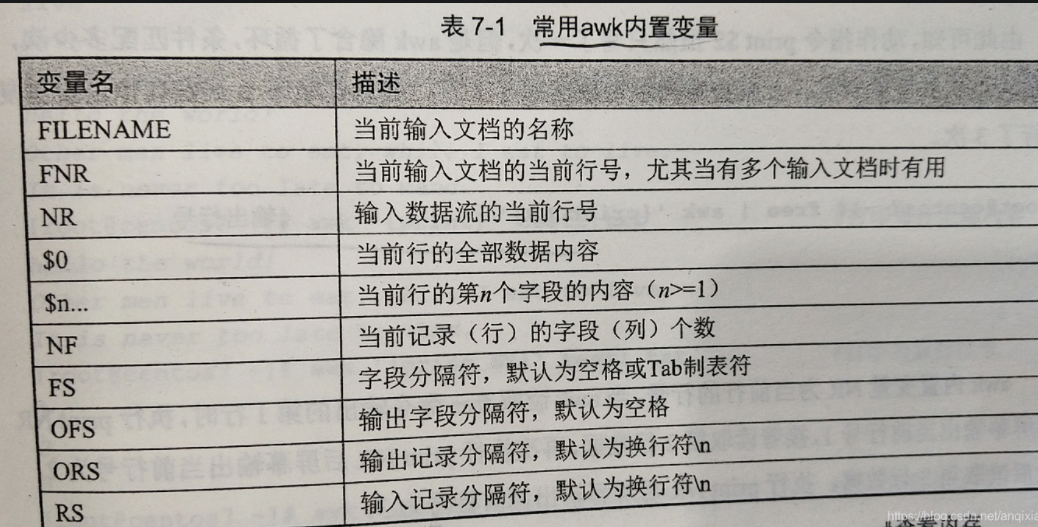
- 最常用的是:
- 行变量
- $num
- NF
- 列变量
- RN
- 分隔符
- RS:行与行之间的分隔符
- FS:同一行单词间的分隔符
- ORS:输出行与行之间的分隔符
- OFS:输出同一行单词间的分隔符
- 其他
- 文件名:FILENAME
- 带行号输出:FNR
- 行变量
例子
#输出每行的最后一列
awk '{print $NF}' fifo.file
#输出每行的倒数第二列,并带输出行号和文件行号
awk '{printf "%d %d %-8s\n",NR,FNR,$(NF-1)}' fifo.file
#指定行分隔符为"<"
awk -v FS="<" '{printf "%d %d %-8s\n",NR,FNR,$(NF-1)}' fifo.file
内置指令
- BEGIN:动作指令仅在读取任何数据记录之前执行一次
- END:动作指令仅在读取完所有数据记录后执行一次
例子
#输出文件的行数
awk 'BEGIN{print "文件的行数"} END{print FNR}' fifo.file
自定义变量
-v设置变量或者在表达式中定义;-v一般用于修改内置变量;
- 特别注意的是其数组本质是一个hash表,所以通过in遍历将可能得到结果不是想要的顺序;
#-v修改内置变量
awk -v RS="." '{print $1}' /tmp/hosts #指定.作为行分隔符
#二维数组
awk 'BEGIN { \
array["0,0"] = 100;\
array["0,1"] = 200;\
array["0,2"] = 300;\
array["1,0"] = 400;\
array["1,1"] = 500;\
array["1,2"] = 600;\
}'
#hash
awk 'BEGIN {sites["runoob"]="www.runoob.com";}'
变量运算
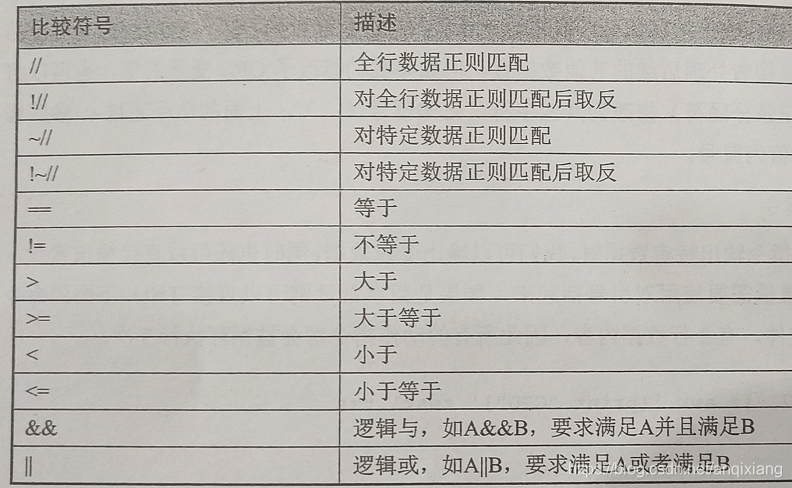
- 除此之外:
+、-、*、**、/、++、+=、-=等均支持
例子
流程控制
- 支持``if、if-else、if-else-if、for、while`:且heC语言的使用没有区别
- 支持
continue、break、exit退出循环
#while if continue例子
awk 'BEGIN{ \
i=0;
while(i<=5) { \
i++; \
if(i==3) {continue;} \
print i; \
} \
} \
END {print "END"}'
#for;
awk -v a= 'BEGIN{ \
for(i=1;i<=5;i++) {a[i]=i} \
}\
for(i in a) {print i} \
END {print "END"}'
内置函数
系统调用函数
- 输入
- getline和next
- getline:获取当前的下一行;前面说到,awk本质是一个for函数,会自动进行i++;,getline相当于用户执行i++,会跳过一行;
- next:跳转到下一行,不再当前行继续执行后续语句;next相当于用户执行continue,当前行不再继续执行;
- getline和next
- 输出
printf和print- print:直接输出,自动换行
- printf:格式化输出(类似C语言,可以指定%d、%s、%t等,需要通过\n换行)
- 调用shell命令:``system(命令)`
- 系统时间:``systime()`
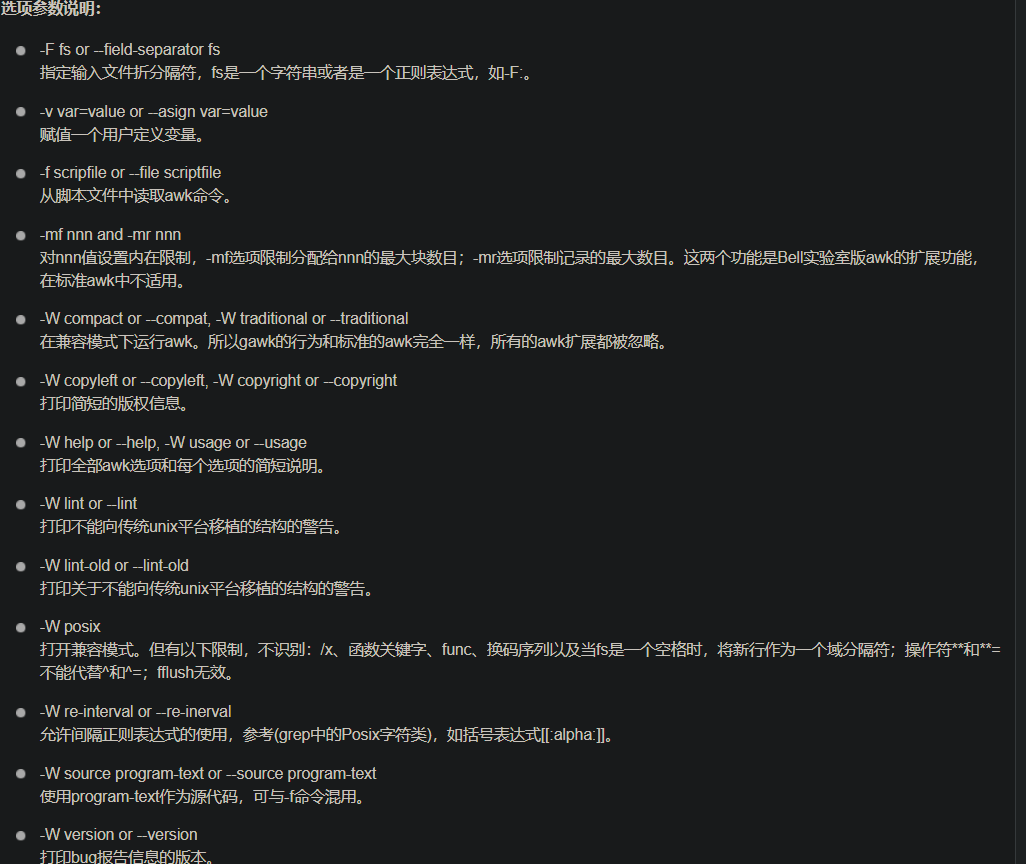
options
condition
command
grep
- grep 命令,擅长查找字符串,正向查找,反向查找,正则查找,多文件查找,递归查找等。
- 支持正则表达式
grep options 匹配语句 filename
options
- ``-v`:显示不包含匹配文本的所有行。
-e<正则表达式>:进行正则表达式匹配- -a:不忽略二进制数据
- -c:计算符合的列数
- -i:忽略大小写
- –color:auto:关键字高亮
- -r:当指定要查找的是目录而非文件