课程推荐:09.多分类问题_哔哩哔哩_bilibili
目录
1. 多分类模型
2. softmax函数模型
3. Loss损失函数
4.实战MNIST Dataset
之前,在逻辑斯蒂回归中我们提到了二分类任务,现在我们讨论多分类问题。
1. 多分类模型
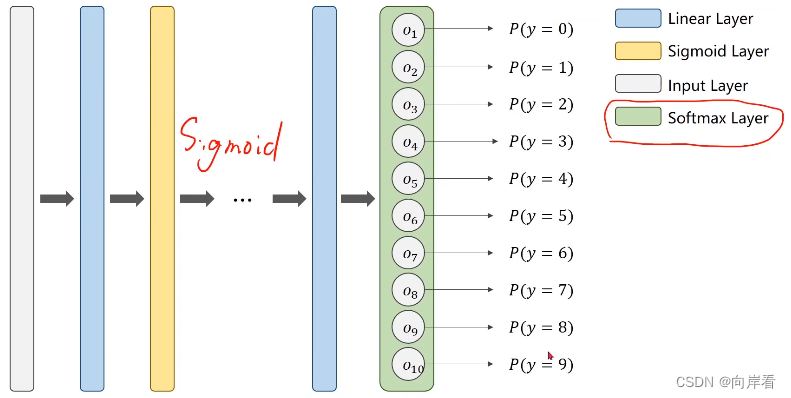
与二分类不同的是多分类有多个输出概率,由softmax层完成。
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类。
softmax层的前一层是线性层,也就是说softmax之前的一层不需要再做Sigmoid,Sigmoid在输入softmax之前已经做过了。线性层输出的值是一般值,还不是概率值。经过sotfmax层之后才能变成概率值。
2. softmax函数模型
softmax函数的作用:softmax两个作用,如果在进行softmax前的input有负数,通过指数变换,得到正数。所有分类的概率求和为1。

softmax函数模型:
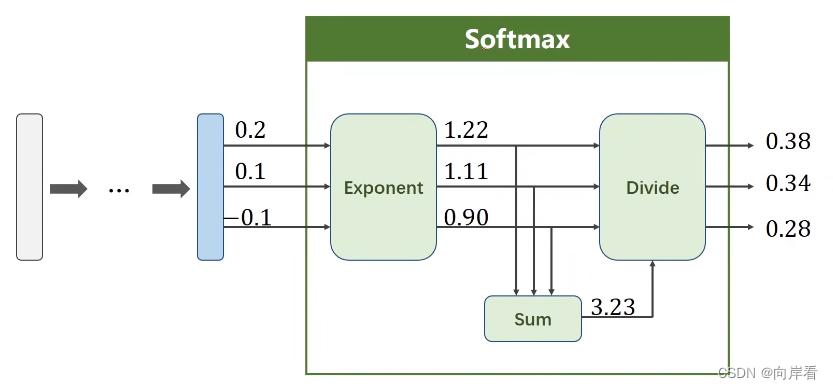
softmax实现过程:Exponent为求指数,sum为求和,Divide为求除数。最后得到的概率值为。
代码实现:
import numpy as np
y = np.array([1, 0, 0])
z = np.array([0.2, 0.1, -0.1])
y_pred = np.exp(z) / np.exp(z).sum()
loss = (-y * np.log(y_pred)).sum()
print(loss)3. Loss损失函数
Loss损失函数计算公式:
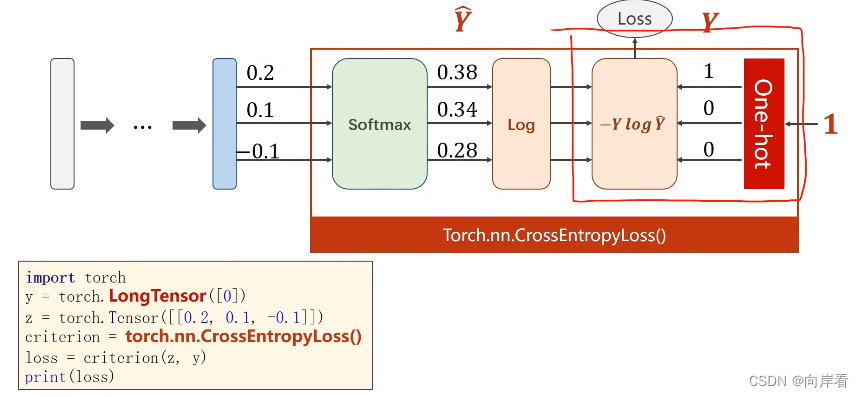
交叉熵损失CrossEntropyLoss <==> LogSoftmax + NLLLoss。LogSoftmax用于得到预测概率值,NLLLoss用于
和y损失值计算。NLLLoss可单独使用,可以思考一下CrossEntropyLoss与NLLLoss区别,方便日后灵活应用。
代码实现:
import torch
# 长整形的张量,LongTensor[0]是指索引为0 的(就是第一个元素)为1,其余为0
y = torch.LongTensor([0])
z = torch.Tensor([[0.2, 0.1, -0.1]])
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss)4.实战MNIST Dataset

将MNIST Dataset中的手写图像映射到一个28*28的矩阵中,颜色越深数值越大,矩阵中的数值在[0,1]之间。把像素值0-255转化为图像张量0-1。
将PIL图像转化为张量:
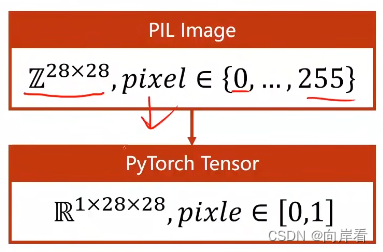
transforms.ToTensor()将PIL图像由单通道转变为多通道再取值[1,0]之间,单变多28*28 =>1*28*28,W*H => C*W*H , C:channel通道,W:宽,H:高,C*W*H。
标椎化处理:
Normalize计算公式
![]() Normalize函数将转化后的张量映射到[0,1]之间
Normalize函数将转化后的张量映射到[0,1]之间
# 把像素值0-255转化为图像张量0-1
transform = transforms.Compose([
# transforms.ToTensor()转化张量,Normalize映射到[0,1]之间
transforms.ToTensor(),
# (均值,标准差)
transforms.Normalize((0.1307, ), (0.381, ))
])完整代码:
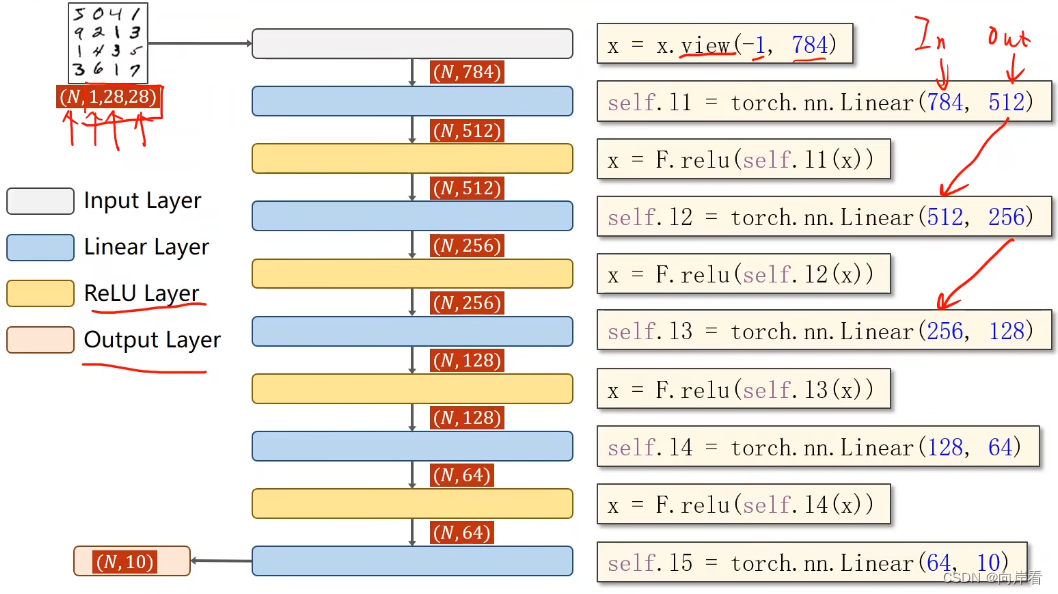
这是一种全连接的神经网络。
1.把像素值0-255转化为图像张量0-1
2.准备数据:view()函数,改变张量形状,参数为-1,根据后一个数,自动调整张量的形状和大小。
3.模型结构:线性层(降维) => 激活层(relu激活) => …… => 线性层(维度为10)
view()参考博客
老四步:
1.数据准备
2.设计模型
3.构造损失函数和优化器
4.训练周期(前馈—>反馈—>更新)
import torch
# 用于图像映射到矩阵中
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
# 把像素值0-255转化为图像张量0-1
transform = transforms.Compose([
# transforms.ToTensor()转化张量,Normalize映射到[0,1]之间
transforms.ToTensor(),
# (均值,标准差)
transforms.Normalize((0.1307, ), (0.381, ))
])
# 训练集
train_dataset = datasets.MNIST(root="../dataset/mnist",
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True)
test_dataset = datasets.MNIST(root="../dataset/mnist",
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
batch_size=batch_size,
shuffle=False)
#…2.设计模型………………………………………………………………………………………………………………………………………#
# 继承torch.nn.Module,定义自己的计算模块,neural network
class Net(torch.nn.Module):
# 构造函数
def __init__(self):
# 调用父类构造
super(Net, self).__init__()
# 从784维降到10维
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
# 前馈函数
def forward(self, x):
# 改变张量形状,784表示确定的列数,自动调整行数
x = x.view(-1, 784)
# 激活
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
# 最后传入一个线性层
return self.l5(x)
#……3.构造损失函数和优化器………………………………………………………………………………………………………#
model = Net()
# 实例化损失函数,返回损失值
criterion = torch.nn.CrossEntropyLoss()
# 优化器,momentum冲量
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
#……4.训练和测试……………………………………………………………………………………………………………………………#
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 1.准备数据
inputs, labels = data
optimizer.zero_grad()
# 2.正向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 3.反向传播
loss.backward()
# 4.更新权重w
optimizer.step()
# 损失求和
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
# with torch.no.grad():内部代码不会再计算梯度
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
# dim沿着第一个纬度(行)找最大值,返回(最大值,最大值下标)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
# 预测值与标签对比,正确则相加
correct += (predicted == labels).sum().item()
# 输出精确率
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()_, predicted = torch.max(outputs.data, 1):返回与样本对比后,相似度最大的样本下标
_, predicted = torch.max(outputs.data, 1)的理解
训练结果: