本文仅对自适应噪声完备集合经验模态分解(CEEMDAN)的原理简单介绍和重点介绍模型的应用。
1. CEEMDAN原理
CEEMDAN(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise)的中文名称是自适应噪声完备集合经验模态分解,
要注意这个方法并不是在CEEMD方法上改进而来的,而是从EMD的基础上加以改进,
同时借用了EEMD方法中加入高斯噪声和通过多次叠加并平均以抵消噪声的思想
2. CEEMDAN 实战应用
简介
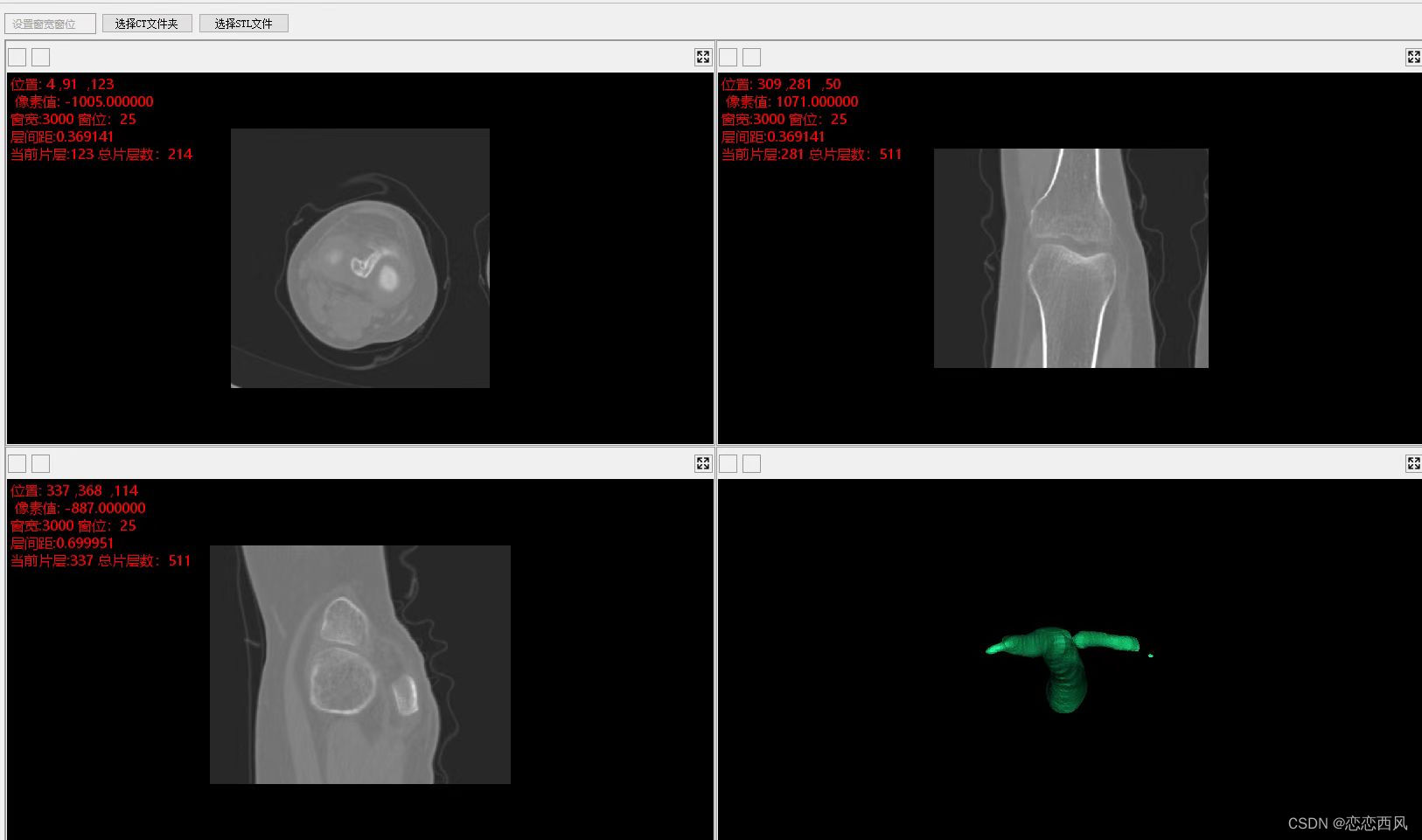
目前的研究方向是时间序列数据预测,采用的数据都是时间序列数据,本次实验的数据集是海浪高度数据信息,没有进行数据的预处理,实验可能会出现一些意想不到的结果,每个人根据自己的研究方向加以修改即可。
2.1 数据集
链接:https://pan.baidu.com/s/1PQtdld221EGu-t2w677uUw
提取码:i9b2
如果无法获取,留言、私聊,发数据集。
2.2 实验
实验代码演示
import pandas as pd
import numpy as np
##载入时间序列数据
def get_data(path,i):
data = pd.read_csv(path,usecols=[i])
data = data.values
return data
def get_ceemdan(data):
"""
信号参数:
N:采样频率500Hz
tMin:采样开始时间
tMax:采样结束时间 2*np.pi
"""
def plot_imf(data_value,E_IMFs):
t = np.arange(0,len(data_value),1) # t 表示横轴的取值范围
vis = Visualisation()
# 分量可视化
# 频率可视化
# 保存分量
def save_imf(E_IMFs):
def test():
path = "sample.csv"
data = get_data(path,0)
E_IMFs = get_ceemdan(data)
plot_imf(data,E_IMFs)
save_imf(E_IMFs)
if __name__ =="__main__":
test()
2.3 结果
分量可视化
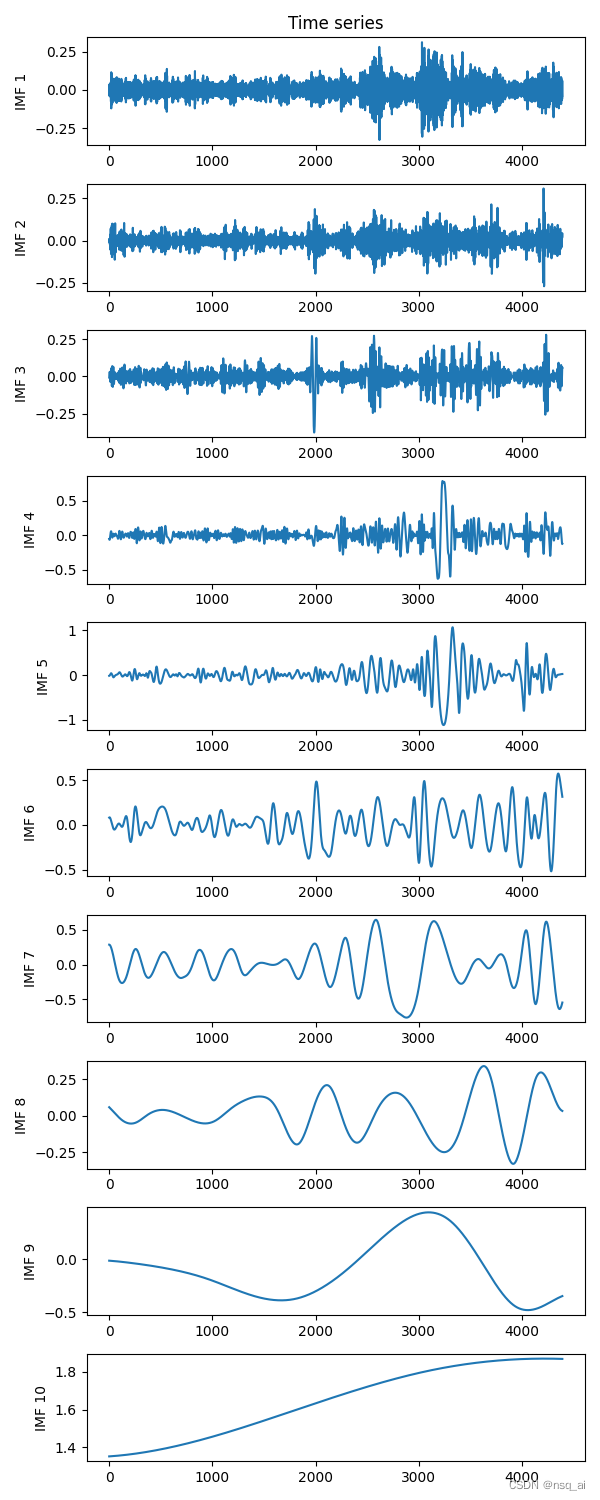
频率可视化
3. 总结
首先,确定数据集中的数据形式;
其次,找到相关的代码模型,进行调试;
接着,将你的数据集输入到模型中,进行实验;
最后,根据实验结果进行相关分析。
注意
要代码私信我,会发的。