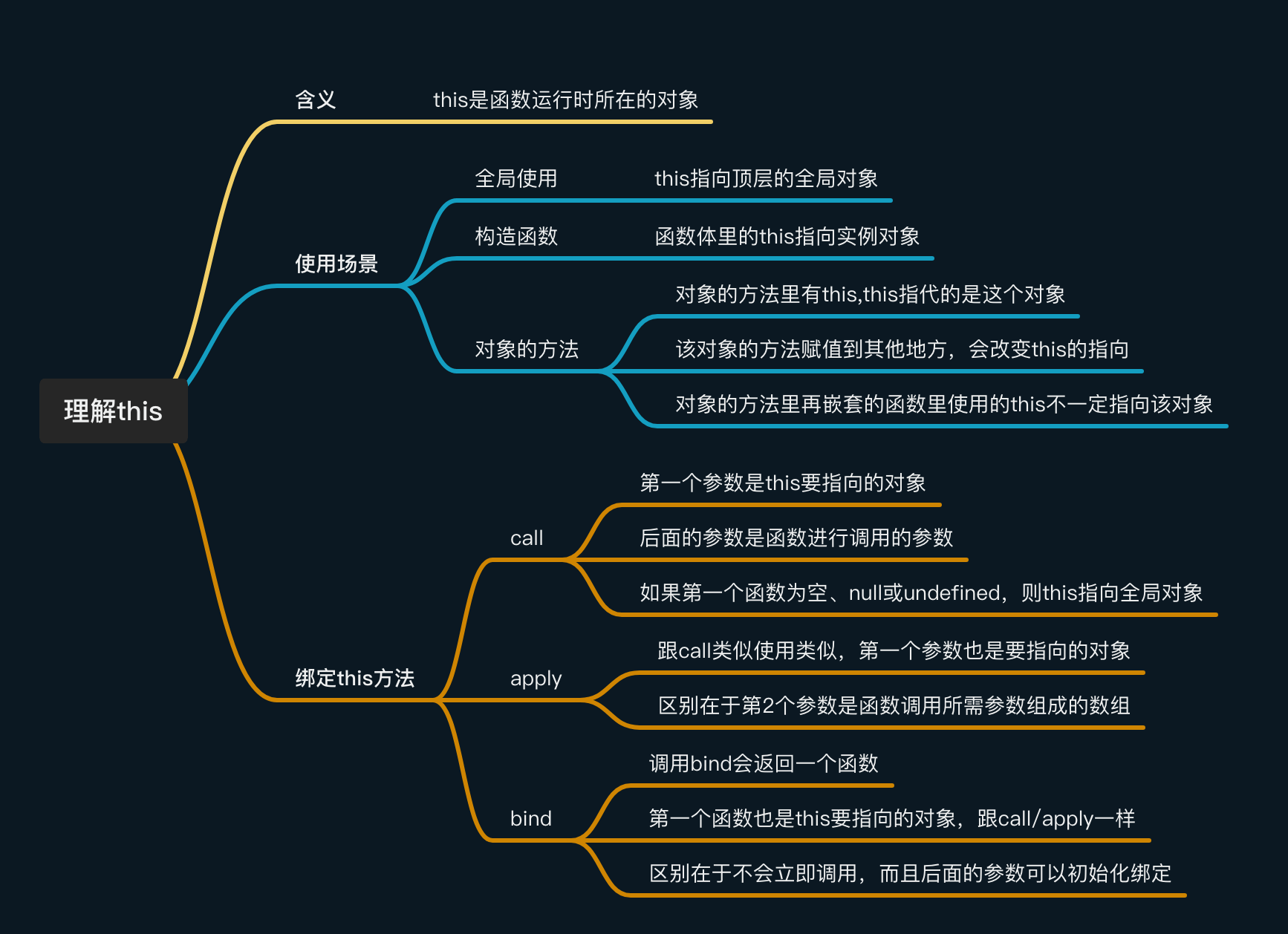
Python 学习曲线 从 Python新手到 Pro
使用代码片段介绍:
Python 是世界上最通用和使用最广泛的编程语言之一,以其简单性、可读性和多功能性而闻名。
在本文中,我们将探讨一系列示例场景,其中代码由具有三个不同专业知识水平的程序员开发:初学者、中级和专家。
中间人和专家通常使用以下方法:
列表推导:使用单行代码创建列表的简洁方法。
squares = [x**2 for x in range(1, 6)]
print(squares)
# Output: [1, 4, 9, 16, 25]
字典理解:类似于列表推导,但用于创建字典。
squares_dict = {x: x**2 for x in range(1, 6)}
print(squares_dict)
# Output: {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
λ函数:
用于简单操作的匿名函数,通常与map,filter,reduce等函数结合使用。
nums = [1, 2, 3, 4, 5]
doubles = list(map(lambda x: x * 2, nums))
print(doubles)
# Output: [2, 4, 6, 8, 10]
装饰:修改或增强其他函数或类的行为的函数或类。
def greet_decorator(func):
def wrapper():
print("Hello!")
func()
print("Welcome!")
return wrapper
@greet_decorator
def greet_name():
print("John")
greet_name()
# Output:
# Hello!
# John
# Welcome!
上下文管理器:与语句一起使用以管理资源(例如:with文件处理)并在使用后自动清理。
with open("file.txt", "r") as file:
content = file.read()
print(content)
类型注释和类型提示:提供有关函数和变量的预期输入和输出类型的显式信息。
from typing import List
def sum_elements(elements: List[int]) -> int:
return sum(elements)
result = sum_elements([1, 2, 3, 4, 5])
print(result)
# Output: 15
生成器和迭代器:用于以节省内存的方式创建和操作可迭代序列。
def fibonacci_gen(n: int):
a, b = 0, 1
for _ in range(n):
yield a
a, b = b, a + b
for num in fibonacci_gen(5):
print(num, end=" ")
# Output: 0 1 1 2 3
正则表达式: 用于模式匹配和文本操作。
import re
text = "The email addresses are john@example.com and jane@example.org"
pattern = r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b"
emails = re.findall(pattern, text)
print(emails) # Output: ['john@example.com', 'jane@example.org']
异常处理:用于优雅地处理错误和异常,确保程序的稳定性和健壮性。
try:
result = 10 / 0
except ZeroDivisionError as e:
print(f"An error occurred: {e}")
# Output: An error occurred: division by zero
模块和软件包: 将代码组织到可重用的模块和包中,以实现更好的结构和代码管理。
# Importing the 'math' module
# and using its 'sqrt' function
import math
sqrt_result = math.sqrt(25)
print(sqrt_result)
# Output: 5.0
多线程和多处理:并发和并行执行的技术,以提高程序性能
#Multithreading and multiprocessing:
# Techniques for concurrent and parallel
# execution to improve program performance.
# 多线程和多处理:并发和并行执行的技术,以提高程序性能。
import threading
def print_square(num):
print(f"Square: {num * num}")
def print_cube(num):
print(f"Cube: {num * num * num}")
thread1 = threading.Thread(target=print_square, args=(4,))
thread2 = threading.Thread(target=print_cube, args=(4,))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
# Output:
# Square: 16
# Cube: 64
内置函数和标准库:
熟练使用Python的内置函数:
zip enumerate all any
和标准库模块:
collections
itertools
functools
bisect
#Built-in functions
numbers = [2, 4, 1, 6, 3, 8, 5, 7]
max_num = max(numbers) # Find the maximum number in the list
min_num = min(numbers) # Find the minimum number in the list
sorted_nums = sorted(numbers) # Sort the list in ascending order
reversed_nums = list(reversed(numbers)) # Reverse the list
print("Maximum number:", max_num)
print("Minimum number:", min_num)
print("Sorted numbers:", sorted_nums)
print("Reversed numbers:", reversed_nums)
# Standard library modules
from collections import Counter
from itertools import combinations
# Counter (from collections module)
word = "mississippi"
counter = Counter(word) # Count the occurrences of each character
print("Character count:", counter)
# Combinations (from itertools module)
combos = list(combinations(numbers, 2)) # Find all combinations of size 2
print("Combinations of size 2:", combos)
元类和元编程:
在运行时动态地生成或修改类和代码的高级技术。
PEP 8和编码风格遵守Python的官方风格指南(PEP 8)和其他关于代码可读性和一致性的最佳实践。
# PEP 8 compliant code snippet
def calculate_area(radius):
"""Calculate the area of a circle given its radius.
Args:
radius (float): The radius of the circle.
Returns:
float: The area of the circle.
"""
pi = 3.14159
return pi * radius**2
def main():
# Collect user input for the radius
radius = float(input("Enter the radius of the circle: "))
# Calculate the area using the defined function
area = calculate_area(radius)
# Display the result with appropriate formatting
print(f"The area of the circle with radius {radius} is {area:.2f}")
if __name__ == "__main__":
main()
Testing and debugging: Writing unit tests, using debugging tools, and ensuring code quality and correctness.
import unittest
def add_numbers(a, b):
return a + b
class TestAddition(unittest.TestCase):
def test_addition(self):
self.assertEqual(add_numbers(2, 3), 5)
if __name__ == '__main__':
unittest.main(argv=['first-arg-is-ignored'], exit=False)
# Output: .
# ----------------------------------------------------------------------
# Ran 1 test in 0.002s
#
# OK
让我们深入了解一下。
-
计算一个给定的整数列表中所有偶数的总和:
初学者:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
even_sum = 0
for num in numbers:
if num % 2 == 0:
even_sum += num
print("The sum of even numbers is:", even_sum)
使用一个基本的for循环来迭代数字列表
使用模数运算符检查一个数字是否是偶数
将偶数添加到sum变量中
中级:
def is_even(num):
return num % 2 == 0
def even_sum(numbers):
result = 0
for num in numbers:
if is_even(num):
result += num
return result
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
result = even_sum(numbers)
print("The sum of even numbers is:", result)
定义一个函数来检查数字是否偶数is_even
创建一个函数来计算偶数之和even_sum
代码更模块化,更易于维护
专家:
def even_sum(numbers):
return sum(filter(lambda num: num % 2 == 0, numbers))
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
result = even_sum(numbers)
print("The sum of even numbers is:", result)
利用内置和功能sum和filter 采用 lambda 函数对偶数进行简洁高效的过滤 代码更紧凑,利用了Python的函数式编程功能
图片来源:作者
-
计算字符串中每个字符的出现次数:
初学者:
text = "hello world"
char_count = {}
for char in text:
if char in char_count:
char_count[char] += 1
else:
char_count[char] = 1
print("Character counts:", char_count)
#Character counts: {'h': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'w': 1, 'r': 1, 'd': 1}
使用一个基本的for循环来迭代字符串中的字符;
检查一个字符是否已经在字典中,并相应地更新计数;
中级:
def count_characters(text):
char_count = {}
for char in text:
char_count[char] = char_count.get(char, 0) + 1
return char_count
text = "hello world"
result = count_characters(text)
print("Character counts:", result)
定义了一个计算字符出现次数的函数: .count_characters
使用该方法来简化代码:.dict.get()
专家:
from collections import Counter
def count_characters(text):
return Counter(text)
text = "hello world"
result = count_characters(text)
print("Character counts:", result)
从模块Countercollections中导入该类;
利用内置来有效地计算字符出现的次数。
图片由作者提供
-
计算平均值
Calculating the average of a list of numbers:
Beginner:
numbers = [1, 2, 3, 4, 5]
total = 0
for num in numbers:
total += num
average = total / len(numbers)
print("The average is:", average)
使用基本的 for 循环遍历列表并计算总和;
将总和除以列表的长度以计算平均值;
中级水平:
def calculate_average(numbers):
return sum(numbers) / len(numbers)
numbers = [1, 2, 3, 4, 5]
average = calculate_average(numbers)
print("The average is:", average)
定义用于计算平均值的函数calculate_average 使用内置函数简化代码sum
专家:
from statistics import mean
def calculate_average(numbers):
return mean(numbers)
numbers = [1, 2, 3, 4, 5]
average = calculate_average(numbers)
print("The average is:", average)
从模块导入函数meanstatistics 利用内置函数计算平均值mean

-
反转字符串:
初学者:
text = "hello"
reversed_text = ""
for char in text:
reversed_text = char + reversed_text
print("Reversed text:", reversed_text)
#text = "Hello"
#Reversed text: olleH
使用一个基本的for循环来迭代字符串中的字符 按相反的顺序串联字符,建立反转的字符串
中级:
def reverse_string(text):
return "".join(reversed(text))
text = "hello"
reversed_text = reverse_string(text)
print("Reversed text:", reversed_text)
定义了一个函数来反转输入的字符串reverse_string
使用函数和方法来反转字符串reversed和join
专家:
def reverse_string(text):
return text[::-1]
text = "hello"
reversed_text = reverse_string(text)
print("Reversed text:", reversed_text)
利用Python的切片语法,以简洁的方式逆转字符串

-
Finding the largest number in a list: Beginner:
numbers = [1, 3, 7, 2, 5]
max_number = numbers[0]
for num in numbers:
if num > max_number:
max_number = num
print("The largest number is:", max_number)
#The largest number is: 7
使用一个基本的for循环来迭代数字列表
将每个数字与当前的最大值相比较,并相应地更新最大值
中级:
def find_max(numbers):
return max(numbers)
numbers = [1, 3, 7, 2, 5]
max_number = find_max(numbers)
print("The largest number is:", max_number)
定义了一个查找列表中最大数字的函数find_max 使用内置函数查找最大数字max
专家:
from functools import reduce
def find_max(numbers):
return reduce(lambda x, y: x if x > y else y, numbers)
numbers = [1, 3, 7, 2, 5]
max_number = find_max(numbers)
print("The largest number is:", max_number)
从内置库functools中导入reduce函数
利用函数的lambda函数来寻找最大的数字reduce

-
去重
Removing duplicates from a list: Beginner:
original_list = [1, 2, 3, 1, 2, 3, 4, 5]
unique_list = []
for item in original_list:
if item not in unique_list:
unique_list.append(item)
print("Unique list:", unique_list)
使用一个基本的for循环来迭代这个列表
检查一个项目是否不在唯一的列表中,如果不存在,就把它添加进去
中级:
def remove_duplicates(items):
return list(set(items))
original_list = [1, 2, 3, 1, 2, 3, 4, 5]
unique_list = remove_duplicates(original_list)
print("Unique list:", unique_list)
定义了一个从列表中删除重复数据的函数remove_duplicates
使用内置的数据结构删除重复的内容,并将其转换为一个列表集。
专家:
def remove_duplicates(items):
return list(dict.fromkeys(items))
original_list = [1, 2, 3, 1, 2, 3, 4, 5]
unique_list = remove_duplicates(original_list)
print("Unique list:", unique_list)
利用该方法删除重复的内容,同时保留原始的orderdict.fromkeys
图片由作者提供
-
Squaring all numbers in a list: Beginner:
numbers = [1, 2, 3, 4, 5]
squared_numbers = []
for num in numbers:
squared_numbers.append(num ** 2)
print("Squared numbers:", squared_numbers)
#Squared numbers: [1, 4, 9, 16, 25]
使用一个基本的for循环来迭代数字列表,将每个数字的平方附加到平方的数字列表中
中级:
def square_numbers(numbers):
return [num ** 2 for num in numbers]
numbers = [1, 2, 3, 4, 5]
squared_numbers = square_numbers(numbers)
print("Squared numbers:", squared_numbers)
定义了一个函数,对列表中的所有数字进行平方运算quare_numbers 使用列表理解来创建平方的数字列表
专家:
def square_numbers(numbers):
return list(map(lambda x: pow(x, 2), numbers))
numbers = [1, 2, 3, 4, 5]
squared_numbers = square_numbers(numbers)
print("Squared numbers:", squared_numbers)

-
将一个列表向右旋转一定数量的位置:
初学者:
numbers = [1, 2, 3, 4, 5]
positions = 2
rotated_list = numbers[-positions:] + numbers[:-positions]
print("Rotated list:", rotated_list)
#Rotated list: [4, 5, 1, 2, 3]
使用 Python 的切片语法,将列表旋转指定的位置。
中级:
def rotate_list(numbers, positions):
return numbers[-positions:] + numbers[:-positions]
numbers = [1, 2, 3, 4, 5]
positions = 2
rotated_list = rotate_list(numbers, positions)
print("Rotated list:", rotated_list)
定义一个函数,将一个列表旋转给定的位置数rotate_list
使用Python 的切片语法,按指定的位置数旋转列表。
专家:
from collections import deque
def rotate_list(numbers, positions):
rotated_numbers = deque(numbers)
rotated_numbers.rotate(positions)
return list(rotated_numbers)
numbers = [1, 2, 3, 4, 5]
positions = 2
rotated_list = rotate_list(numbers, positions)
print("Rotated list:", rotated_list)
module: deque collections中导入该类。 利用该类和它的方法,按指定的位置数有效地旋转列表。

-
寻找两个列表中的共同元素:
初学者:
list1 = [1, 2, 3, 4, 5]
list2 = [4, 5, 6, 7, 8]
common_elements = []
for num in list1:
if num in list2:
common_elements.append(num)
print("Common elements:", common_elements)
#Common elements: [4, 5]
使用一个基本的for循环来迭代第一个列表中的元素
检查一个元素是否存在于第二个列表中,如果发现,则将其追加到公共元素列表中。
中级:
def find_common_elements(list1, list2):
return [num for num in list1 if num in list2]
list1 = [1, 2, 3, 4, 5]
list2 = [4, 5, 6, 7, 8]
common_elements = find_common_elements(list1, list2)
print("Common elements:", common_elements)
定义了一个函数来寻找两个列表中的共同元素find_common_elements 使用列表理解来创建一个共同元素的列表
专家:
def find_common_elements(list1, list2):
return list(set(list1) & set(list2))
list1 = [1, 2, 3, 4, 5]
list2 = [4, 5, 6, 7, 8]
common_elements = find_common_elements(list1, list2)
print("Common elements:", common_elements)
利用集合运算找到两个列表的交集(共同元素)。 将结果转换为一个列表

转置矩阵(二维列表):
初学者:
matrix = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
transposed_matrix = []
#转置的矩阵
for i in range(len(matrix[0])):
transposed_row = []
# 初始化矩阵中的行
for row in matrix:
transposed_row.append(row[i])
transposed_matrix.append(transposed_row)
print("Transposed matrix:", transposed_matrix)
使用嵌套的for循环来遍历矩阵的行和列
附加原始矩阵中每一行的元素以创建转置矩阵
中级:
def transpose_matrix(matrix):
return [[row[i] for row in matrix] for i in range(len(matrix[0]))]
matrix = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
transposed_matrix = transpose_matrix(matrix)
print("Transposed matrix:", transposed_matrix)
定义一个函数来转置给定矩阵transpose_matrix 使用嵌套列表推导创建转置矩阵
专家
def transpose_matrix(matrix):
return list(zip(*matrix))
matrix = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
transposed_matrix = transpose_matrix(matrix)
print("Transposed matrix:", transposed_matrix)
利用带有解包运算符的功能,以简洁的方式转置矩阵zip*


-
检查字符串是否为回文。
初学:
string = "madam"
is_palindrome = True
for i in range(len(string) // 2):
if string[i] != string[-(i + 1)]:
is_palindrome = False
break
print(f"Is '{string}' a palindrome?:", is_palindrome)
#Is 'madam' a palindrome?: True
使用基本的 for 循环循环访问字符串中字符的前半部分
将每个字符与字符串末尾的相应字符进行比较,如果它们不匹配,则为False。
is_palindrome 中级/专家:
def is_palindrome(string):
return string == string[::-1] 。
string = "madam"
result = is_palindrome(string)
print(f "Is '{string}' a palindrome?:", result)
定义一个函数来检查一个给定的字符串是否是回文:is_palindrome
使用Python的切片语法来反转字符串,并将其与原始字符串进行比较。

图片由作者提供
-
寻找一个数字的质因数
初学者:
num = 60
prime_factors = []
for i in range(2, num + 1):
while num % i == 0:
prime_factors.append(i)
num = num // i
print("Prime factors:", prime_factors)
#质因数: [2, 2, 3, 5]
使用一个基本的for循环来迭代可能的因子;
使用一个while循环来重复除以一个因子,当它可以被除掉时;
将质因数添加到列表中;
中级:
def prime_factors(num):
factors = []
for i in range(2, num + 1):
while num % i == 0:
factors.append(i)
num = num // i
return factors
num = 60
result = prime_factors(num)
print("Prime factors:", result)
定义一个函数来寻找一个给定数字的质因数prime_factors
使用嵌套循环来识别质因数,并将其追加到列表中
专家:
def prime_factors(num):
factors = []
i = 2
while i * i <= num:
if num % i:
i += 1
else:
num //= i
factors.append(i)
if num > 1:
factors.append(num)
return factors
num = 60
result = prime_factors(num)
print("Prime factors:", result)
定义一个函数,使用优化的方法来寻找质因数sprime_factors;
使用一个单次的while循环来重复地用最小的除数来除数;
将质因数添加到列表中,并检查剩余的数字是否大于1,以考虑到最后的质因数

图片由作者提供
-
扁平化一个嵌套的列表:
初学者:
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] 。
flat_list = []
for sublist in nested_list:
for item in sublist:
flat_list.append(item)
print("Flat list:", flat_list)
#列表扁平:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
使用嵌套的for循环来迭代嵌套列表中的子列表和项目;
将每个项目追加到新的扁平列表中;
中级:
def flatten_list(nested_list):
return [item for sublist in nested_list for item in sublist]
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
flat_list = flatten_list(nested_list)
print("Flat list:", flat_list)
定义了一个函数来平坦一个嵌套列表flatten_list
使用嵌套列表的理解力来创建扁平列表
专家:
from itertools import chain
def flatten_list(nested_list):
return list(chain.from_iterable(nested_list))
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] 。
flat_list = flatten_list(nested_list)
print("flat list:", flat_list)
从模块chainitertools中导入该函数;
定义了一个函数,使用该函数来平铺嵌套的列表flatten_listchain.from_iterable

作者的图片
-
计算一个句子中单词的频率:
初学者:
sentence = "apple banana apple kiwi banana apple"
word_count = {}
for word in sentence.split():
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
print("Word count:", word_count)
使用该方法将句子标记为单词split
使用基本的 for 循环遍历单词并计算它们在字典中的出现次数
中级:
from collections import Counter
def count_words(sentence):
return Counter(sentence.split())
sentence = "apple banana apple kiwi banana apple"
word_count = count_words(sentence)
print("字数:", word_count)
从模块导入类Countercollections;
定义一个函数,该函数使用该类来计算句子中单词的频率count_wordsCounter。
专家:
from collections import defaultdict
def count_words(sentence):
word_count = defaultdict(int)
for word in sentence.split():
word_count[word] += 1
return word_count
sentence = "apple banana apple kiwi banana apple"
word_count = count_words(sentence)
print("Word count:", word_count)
从collections模块导入defaultdict类;
定义一个函数,该函数使用具有整体数值的默认字典来计算单词的频率count_words。使用该方法标记句子,使用为循环增加字数split

图片来源:作者
-
合并两个词典
初学者:
def merge_dicts(d1, d2):
merged_dict = d1.copy()
merged_dict.update(d2)
返回merged_dict
dict1 = {'a': 1, 'b': 2, 'c': 3}
dict2 = {'d': 4, 'e': 5}
result = merge_dicts(dict1, dict2)
print("merged dictionary:", result)
#合并后的字典:
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
定义了一个函数来合并两个字典merge_dicts;
使用方法来创建第一个字典的副本,并使用方法用第二个字典的键值对来更新字典copyupdate
中间的:
def merge_dicts(d1, d2):
merged_dict = d1.copy()
merged_dict.update(d2)
return merged_dict
dict1 = {'a': 1, 'b': 2, 'c': 3}
dict2 = {'d': 4, 'e': 5}
result = merge_dicts(dict1, dict2)
print("Merged dictionary:", result)
#Merged dictionary:
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
定义了一个函数来合并两个字典merge_dicts; 使用字典解包()来合并字典**d1, **d2
专家:
from collections import ChainMap
def merge_dicts(d1, d2):
返回 dict(ChainMap(d1, d2))
dict1 = {'a': 1, 'b': 2, 'c': 3}
dict2 = {'d': 4, 'e': 5}
result = merge_dicts(dict1, dict2)
print("merged dictionary:", result)
从模块ChainMapcollections中导入该类;
定义了一个函数来合并两个字典merge_dicts;
使用该类来创建两个字典的合并视图,并将结果转换为一个 dictionaryChainMap。

作者的图片
-
寻找两个列表之间的差异:
初学者:
def list_difference(lst1, lst2):
difference = []
for item in lst1:
if item not in lst2:
difference.append(item)
return difference
lst1 = [1, 2, 3, 4, 5]
lst2 = [4, 5, 6, 7, 8]
result = list_difference(lst1, lst2)
print("List difference:", result)
#List difference: [1, 2, 3]
#列表中的差异: [1, 2, 3]
定义了一个函数来查找在第一个列表中但不在第二个列表中的元素 listlist_difference;
使用一个基本的for循环来遍历第一个列表中的元素,并检查每个元素是否在第二个列表中不存在;
将唯一的元素追加到差异列表中;
中级:
def list_difference(lst1, lst2):
return list(set(lst1) - set(lst2))
lst1 = [1, 2, 3, 4, 5]
lst2 = [4, 5, 6, 7, 8]
result = list_difference(lst1, lst2)
print("List difference:", result)
定义了一个函数来查找在第一个列表中,但不在第二个列表中的元素 listlist_difference
将结果转换回列表
专家:
def list_difference(lst1, lst2):
return [item for item in lst1 if item not in set(lst2)]
lst1 = [1, 2, 3, 4, 5]
lst2 = [4, 5, 6, 7, 8]
result = list_difference(lst1, lst2)
print("List difference:", result)
定义了一个函数来查找在第一个列表中但不在第二个列表中的元素 listlist_difference;
使用带有条件的列表理解来创建一个唯一元素的列表;
将第二个列表转换为一个集合,以优化成员测试

作者的图片
-
从两个列表(键和值)创建一个 dictionary: 初学者:
def create_dict(keys, values):
result = {}
for key, value in zip(keys, values):
result[key] = value
return result
keys = ['name', 'age', 'gender']
values = ['Alice', 25, 'Female']
result = create_dict(keys, values)
print("Dictionary:", result)
#Dictionary: {'name': 'Alice', 'age': 25, 'gender': 'Female'}
定义一个函数,从两个列表(key和values)中创建一个字典; create_dict使用函数的for循环来同时遍历键和值,zip; 通过将每个值分配给其相应的键来构造字典
中间的:
def create_dict(keys, values):
return dict(zip(keys, values))
keys = ['name', 'age', 'gender']
values = ['Alice', 25, 'Female']
result = create_dict(keys, values)
print("Dictionary:", result)
定义一个函数,从两个列表 key和values中创建一个字典, create_dict 使用函数来配对 keys 和 values,然后使用构造函数来创建 dictionaryzipdict
专家:
def create_dict(keys, values):
return {key: value for key, value in zip(keys, values)}
keys = ['name', 'age', 'gender']
# '姓名', '年龄', '性别'
values = ['Alice', 25, 'Female']
# 'Alice', 25, 'Female'
result = create_dict(keys, values)
print("Dictionary:", result)
定义了一个函数,从两个列表 key和values中创建一个字典,create_dict 使用函数的字典理解来创建字典zip

图片由作者提供
-
替换句子中出现的所有单词:
初学者:
def replace_word(sentence, old_word, new_word):
return sentence.replace(old_word, new_word)
sentence = "我喜欢苹果。苹果很好吃。"
old_word = "苹果"
new_word = "橙子"
print(replace_word(sentence, old_word, new_word))
#我喜欢橙子。苹果很好吃。
中级/专家:
import re
def replace_word(sentence, old_word, new_word):
return re.sub(r'\b' + old_word + r'\b', new_word, sentence, flags=re.IGNORECASE)
sentence = "I like apples. Apples are tasty."
old_word = "apples"
new_word = "oranges"
print(replace_word(sentence, old_word, new_word))

图片由作者提供
-
计算一串数字的标准差:
初学者:
def mean(numbers):
return sum(numbers) / len(numbers)
def standard_deviation(numbers):
avg = mean(numbers)
return (sum((x - avg) ** 2 for x in numbers) / len(numbers)) ** 0.5
numbers = [1, 2, 3, 4, 5]
print(standard_deviation(numbers))
#1.4142135623730951
中级/专家:
import numpy as np
numbers = [1, 2, 3, 4, 5]
print(np.std(numbers))

图片由作者提供
-
创建分类数据的单热编码表示法:
初学者:
from sklearn.preprocessing import OneHotEncoder
data = [['apple'], ['banana'], ['orange'], ['apple'], ['banana'] ]
encoder = OneHotEncoder()
one_hot_encoded = encoder.fit_transform(data).toarray()
print(one_hot_encoded)
中级/专家:
import pandas as pd
data = pd.DataFrame({'fruit': ['apple', 'banana', 'orange', 'apple', 'banana']})
one_hot_encoded = pd.get_dummies(data, columns=['fruit'])
print(one_hot_encoded)

图片由作者提供
-
按数字的奇偶性(偶数或奇数)对一个列表进行分组:
初学者:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9] 。
even_numbers = []
odd_numbers = []
for num in numbers:
如果num % 2 == 0:
even_numbers.append(num)
否则:
odd_numbers.append(num)
grouped_numbers = {'偶数': even_numbers, '奇数': odd_numbers}.
print("分组的数字:", grouped_numbers)
#分组后的数字: {'偶数': [2, 4, 6, 8], '奇数': [1, 3, 5, 7, 9]}
使用一个基本的for循环来迭代列表中的数字;
将偶数的数字添加到列表中,将奇数的数字添加到列表中ven_numbersodd_numbers;
将数字分组到一个字典中;
中级:
def group_by_parity(numbers):
返回 {
'偶数': [num for num in numbers if num % 2 == 0]、
'奇数': [num for num in numbers if num % 2 != 0]、
}
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9].
grouped_numbers = group_by_parity(numbers)
print("分组的数字:", grouped_numbers)
定义了一个函数,将一列数字按奇偶性分组group_by_parity;
使用字典理解和列表理解来创建分组的字典;
专家:
from collections import defaultdict
def group_by_parity(numbers):
grouped_numbers = defaultdict(list)
for num in numbers:
key = 'even' if num % 2 == 0 else 'odd'
grouped_numbers[key].append(num)
return grouped_numbers
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
grouped_numbers = group_by_parity(numbers)
print("Grouped numbers:", grouped_numbers)
从模块导入类defaultdictcollections
定义一个函数,该函数使用defaultdict 按奇偶校验对数字进行分组group_by_parity。
迭代数字并将它们附加到分组字典中的相应键("偶数 "或 "奇数")

图片来源:作者
-
在列表中查找最常见的元素。
初学者:
numbers = [1, 2, 2, 3, 4, 4, 4, 5, 5]
element_count = {}
for num in numbers:
if num in element_count:
element_count[num] += 1
else:
element_count[num] = 1
most_common_element = max(element_count, key=element_count.get)
print("Most common element:", most_common_element)
#Most common element: 4
print("最常见的元素:", most_common_element)
#最常见的元素: 4
使用基本的为 循环遍历列表中的元素,并计算它们在字典中的出现次数 将函数与参数一起使用以查找最常见的元素(max,key=)
中间:
from collections import Counter
def most_common_element(lst):
return Counter(lst).most_common(1)[0][0]
numbers = [1, 2, 2, 3, 4, 4, 4, 5, 5]
result = most_common_element(numbers)
print("最常见的元素:", result)
从 "集合 "模块导入 "计数器 "类
定义一个函数 "most_common_element",该函数使用 "Counter "类来计算列表中元素的出现次数;
专家:
从统计数据中导入模块
def most_common_element(lst):
return mode(lst)
numbers = [1, 2, 2, 3, 4, 4, 5, 5].
result = most_common_element(numbers)
print("最常见元素:", result)
从模块导入函数modestatistics
定义一个函数,该函数使用该函数查找列表中最常见的元素most_common_elementmode
该函数返回列表中最常见的元素mode

图片来源:作者
-
将字典转换为元组列表
初学者:
def dict_to_tuples(d):
return [(key, value) for key, value in d.items()]
dictionary = {'a': 1, 'b': 2, 'c': 3}
result = dict_to_tuples(dictionary)
print("List of tuples:", result)
# List of tuples: [('a', 1), ('b', 2), ('c', 3)]
列表中的图元: [('a', 1), ('b', 2), ('c', 3)]
定义将字典转换为元组列表的函数dict_to_tuples;
使用列表推导和字典的方法创建元组列表items;
中间:
def dict_to_tuples(d):
return list(d.items())
dictionary = {'a': 1, 'b': 2, 'c': 3}
result = dict_to_tuples(dictionary)
print("列表中的图元:", result)
定义将字典转换为元组列表的函数dict_to_tuples;
使用字典的方法获取键值对作为元组,并将结果转换为列表items 专家;
from operator import itemgetter
def dict_to_tuples(d):
return sorted(d.items(), key=itemgetter(0))
dictionary = {'a': 1, 'b': 2, 'c': 3}
result = dict_to_tuples(dictionary)
print("List of tuples:", result)
从模块itemgetteroperator中导入函数;
定义一个函数,将 dictionary 转换为 tuples 的列表dict_to_tuples;
使用 dictionary 的方法来获取作为图元的键值对,并根据键值对结果进行排序

-
寻找数字列表中的最大值和最小值:
初学者:
def find_max_min(numbers):
max_value = max(numbers)
min_value = min(numbers)
return max_value, min_value
numbers = [1, 2, 3, 4, 5]
max_value, min_value = find_max_min(numbers)
print("Maximum value:", max_value)
print("Minimum value:", min_value)
# Maximum value: 5
# Minimum value: 1
print("最大值:", max_value)
print("最小值:", min_value)
# 最大值:5
# 最小值:1
定义了一个函数来查找数字列表中的最大值和最小值sfind_max_min;
使用内置的和函数来寻找最大值和最小值maxmin;
中级:
def find_max_min(numbers):
return max(numbers), min(numbers)
numbers = [1, 2, 3, 4, 5]
max_value, min_value = find_max_min(numbers)
print("Maximum value:", max_value)
print("Minimum value:", min_value)
定义了一个函数来查找数字列表中的最大值和最小值sfind_max_min;
使用内置的和函数来查找最大和最小值,并以元组形式返回maxmin;
专家:
from functools import reduce
def find_max_min(numbers):
return reduce(lambda acc, x: (max(acc[0], x), min(acc[1], x)), numbers, (float('-inf'), float('inf') )
numbers = [1, 2, 3, 4, 5].
max_value, min_value = find_max_min(numbers)
print("最大值:", max_value)
print("最小值:", min_value)
从functools中导入函数
定义了一个函数来查找数字列表中的最大值和最小值sfind_max_min;
使用带有lambda函数的函数,通过比较每个元素和累积值,计算出最大和最小值reduce;
用负数和正数的无穷大初始化累积器,以处理边缘情况

图片由作者提供
-
计算一串数字的平均数、中位数和模式:
初学者:
def calculate_mean(numbers):
返回 sum(numbers) / len(numbers)
def calculate_median(numbers):
numbers.sort()
n = len(numbers)
如果n % 2 == 0:
返回(number[n // 2 - 1] + numbers[n // 2])/ 2
否则:
返回 numbers[n // 2]
def calculate_mode(numbers):
counts = {}。
for num in numbers:
如果num在counts中:
counts[num] += 1
否则:
counts[num] = 1
返回 max(counts, key=counts.get)
numbers = [4, 6, 4, 7, 4, 5, 6, 4, 7, 8, 5, 4] 。
输出结果:
平均数 = calculate_mean(numbers)
中位数 = calculate_median(numbers)
模式 = calculate_mode(numbers)
print(f "Mean: {mean}, Median: {median}, Mode: {mode}")
#Mean: 5.33333333333, 中位数: 5.0, 模式: 4
这段代码定义了三个独立的函数来计算一串数字的平均数、中位数和模式。
该函数通过将数字的总和除以列表的长度来找到平均值。
该函数对列表进行排序,并找到中间的元素来计算中位数。
该函数使用一个字典来计算每个数字的出现次数,并找到计数最高的数字。
中级:
从统计学中导入平均数、中位数、模式
from statistics import mean, median, mode
def calculate_mean_median_mode(numbers):
return mean(numbers), median(numbers), mode(numbers)
numbers = [4, 6, 4, 7, 4, 5, 6, 4, 7, 8, 5, 4]
mean, median, mode = calculate_mean_median_mode(numbers)
print(f"Mean: {mean}, Median: {median}, Mode: {mode}")
平均数、中位数、模式 = calculate_mean_median_mode(numbers)
该代码使用该模块来计算数字列表的平均值、中位数和众数。
该函数以元组的形式返回平均值、中位数和众数。Calculate_mean_median_mode
专家:
从统计学中导入平均数、中位数、模式
from statistics import mean, median, mode
from typing import List, Tuple
def calculate_mean_median_mode(numbers: List[float]) -> Tuple[float, float, float]:
return mean(numbers), median(numbers), mode(numbers)
def main():
numbers = [4, 6, 4, 7, 4, 5, 6, 4, 7, 8, 5, 4]
mean_val, median_val, mode_val = calculate_mean_median_mode(numbers)
print(f"Mean: {mean_val}, Median: {median_val}, Mode: {mode_val}")
if __name__ == "__main__":
main()
该代码包括用于指定输入和返回类型的函数的类型注释。calculate_mean_median_mode
该函数使用该模块来计算平均值、中位数和众数。
代码被组织成一个函数,该函数在执行脚本时调用。
-
合并两个排序列表
初学者:
def merge_sorted_lists(list1, list2):
result = []
i = j = 0
while i < len(list1) and j < len(list2):
if list1[i] < list2[j]:
result.append(list1[i])
i += 1
else:
result.append(list2[j])
j += 1
result.extend(list1[i:])
result.extend(list2[j:])
return result
list1 = [1, 3, 5, 7]
list2 = [2, 4, 6, 8]
merged_list = merge_sorted_lists(list1, list2)
print(merged_list)
该代码定义了一个 merge_sorted_lists 函数,该函数将两个排序列表合并为一个。
该函数使用两个指针(i 和 j)循环访问两个输入列表,并比较元素以生成合并列表。
任一列表中的其余元素将追加到结果中。
中级/专家:
from heapq import merge
from typing import List
def merge_sorted_lists(list1: List[int], list2: List[int]) -> List[int]:
return list(merge(list1, list2))
def main():
list1 = [1, 3, 5, 7]
list2 = [2, 4, 6, 8]
merged_list = merge_sorted_lists(list1, list2)
print(merged_list)
if __name__ == "__main__":
main()
该代码使用函数来有效地合并两个已排序的列表 heapq.merge
对输入参数和返回类型进行了类型注释
代码被组织成一个函数,当脚本被执行时,该函数被调用
-
阶乘:
初学者:
def factorial(n):
if n == 0:
return 1
return n * factorial(n - 1)
number = 5
result = factorial(number)
print(f"The factorial of {number} is {result}.")
#The factorial of 5 is 120.
该代码定义了一个递归函数来计算一个非负整数的阶乘factorial n
该函数包括一个基本情况,当为零时,返回1.n
递归情况下,通过与.n-1的阶乘来计算阶乘。
中级/专家:
from functools import lru_cache
from typing import Optional
@lru_cache(maxsize=None)
def factorial(n: int) -> Optional[int]:
if n < 0:
print("Error: Factorial is not defined for negative numbers.")
return None
if n == 0:
return 1
return n * factorial(n - 1)
def main():
number = 5
result = factorial(number)
if result is not None:
print(f"The factorial of {number} is {result}.")
else:
print("Could not calculate factorial.")
if __name__ == "__main__":
main()
该代码包括对函数的输入参数和返回类型的类型注解。
装饰器用于备忘阶乘函数,缓存中间结果以提高性能。
该函数检查负的输入值,并为无效的输入提供一个错误信息。
代码使用该函数进行代码组织,并处理阶乘不能被计算的可能情况。
-
将一个CSV文件加载到一个DataFrame中:
初学者:
import pandas as pd
def load_csv(file_path):
return pd.read_csv(file_path)
file_path = "data.csv"
df = load_csv(file_path)
print(df.head())
导入库并将其别名为 pd
定义一个函数,使用 load_csvread_csvpandas 的方法将 CSV 文件加载到 DataFrame 中。
使用 methodhead 打印 DataFrame 的前几行。
中级/专家:
import pandas as pd
def load_csv(file_path, use_cols=None, parse_dates=None):
return pd.read_csv(file_path, usecols=use_cols, parse_dates=parse_dates)
file_path = "data.csv"
selected_columns=['column1', 'column3']
date_columns = ['date_column']。
df = load_csv(file_path, use_cols=selected_columns, parse_dates=date_columns)
print(df.head())
导入库,并将其别名为 pd
定义了一个带有可选参数的函数,分别用于选择列和解析日期列,load_csvuse_colsparse_dates
从CSV文件中加载指定的列,将日期列解析为日期时间对象。
打印DataFrame的前几行
-
寻找数组中两个整数的最大乘积:
def max_product(arr):
max_product = float('-inf')
for i in range(len(arr)):
for j in range(i + 1, len(arr)):
product = arr[i] * arr[j]
if product > max_product:
max_product = product
return max_product
arr = [1, 3, 5, 2, 6, 4]
max_product_result = max_product(arr)
print("Maximum product of two integers:", max_product_result)
#30
#两个整数的最大乘积:", max_product_result)
#30
该代码定义了一个函数,该函数查找到定数组中两个整数的最大乘积。max_product
该函数使用嵌套循环来考虑数组中所有可能的整数对
对于每对,计算产品,并相应地更新最大产品值
中间:
from typing import List
def max_product(arr: List[int]) -> int:
arr.sort(reverse=True)
return arr[0] * arr[1]
def main():
arr = [1, 3, 5, 2, 6, 4]
max_product_result = max_product(arr)
print("Maximum product of two integers:", max_product_result)
if __name__ == "__main__":
main()
该代码包括输入参数和返回类型的类型注释。
该函数按降序对数组进行排序,并返回前两个元素的乘积,这两个元素最大。
代码使用一个函数进行组织,以获得更好的结构和可读性。
专家:
from typing import List
from heapq import nlargest
def max_product(arr: List[int]) -> int:
largest_nums = nlargest(2, arr)
return largest_nums[0] * largest_nums[1]
def main():
arr = [1, 3, 5, 2, 6, 4]
max_product_result = max_product(arr)
print("Maximum product of two integers:", max_product_result)
if __name__ == "__main__":
main()
该代码使用该函数有效地查找数组中最大的两个整数,而无需对整个数组进行排序 heapq.nlargest
该函数返回两个最大整数的乘积
代码被组织成一个函数,该函数在执行脚本时调用
30.二叉搜索 初学者:
def binary_search(arr, target):
low, high = 0, len(arr) - 1
while low <= high:
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1
arr = [1, 2, 4, 5, 6, 7, 9, 10]
target = 7
index = binary_search(arr, target)
print(f"Index of {target}:", index)
该代码定义了一个函数,该函数执行二叉搜索以查找排序数组中目标值的索引。
该函数使用循环根据中间元素的值重复缩小搜索范围。
如果找到目标值,该函数返回中间元素的索引;否则,它返回-1。
中级/专家:
from typing import List
from bisect import bisect_left
def binary_search(arr: List[int], target: int) -> int:
index = bisect_left(arr, target)
return index if index != len(arr) and arr[index] == target else -1
def main():
arr = [1, 2, 4, 5, 6, 7, 9, 10]
target = 7
index = binary_search(arr, target)
print(f"Index of {target}:", index)
if __name__ == "__main__":
main()
该代码使用内置模块中的函数来有效地查找排序数组中目标值的插入点。
该函数检查找到的索引中是否存在目标值,如果与目标匹配,则返回索引;
否则,它返回-1。
代码被组织成一个函数,当脚本被执行时,它被调用。
总结:
初级程序员专注于基本语法和基础概念,中级程序员引入优化和模块化代码,而专家程序员则利用高级技术、错误处理、代码组织和整体健壮性。要了解更多信息,请查看参考资料。
References:
Python.org Official Documentation: Link: https://docs.python.org/3/tutorial/index.html
Codecademy’s Python Course: Link: https://www.codecademy.com/learn/learn-python-3
Coursera’s Python for Everybody: Link: https://www.coursera.org/specializations/python
Google’s Python Class: Link: https://developers.google.com/edu/python
leetcode: https://leetcode.com
hackrrank: https://www.hackerrank.com/domains/tutorials/10-days-of-python
codewars: https://www.codewars.com
stackoverflow:
https://stackoverflow.com/questions/tagged/python
Python Reddit Community (r/Python):
链接: https://www.reddit.com/r/Python/ Python Discord Community:
链接:https://pythondiscord.com
本文由 mdnice 多平台发布