SQLTransformer(SQL转换器)是一种数据预处理方法,允许您使用SQL语句对数据进行转换和操作。SQL转换器通常用于数据清洗、特征工程和数据聚合等任务,以提高数据分析和机器学习模型的性能。它可以与各种数据处理和存储系统(如关系型数据库、大数据平台和数据仓库)结合使用,实现灵活高效的数据处理。
SQL转换器的主要优点是可以利用SQL的强大功能和广泛支持来处理复杂的数据任务。例如,您可以使用SQL查询来筛选数据、计算新特征、连接数据表和分组聚合数据。此外,SQL转换器可以与各种数据源和API(如JDBC、ODBC和SQLAlchemy)集成,从而实现跨平台和跨语言的数据处理。
然而,SQL转换器的缺点是它可能受到SQL语法和性能的限制,尤其是在处理大规模数据和复杂任务的情况下。为了解决这些问题,可以考虑使用其他数据处理方法(如Pandas、Dask和Apache Spark)或分布式计算框架(如Hadoop和MapReduce)进行更高效的数据处理。
在实际应用中,SQL转换器通常与其他数据预处理方法(如特征缩放、特征选择和特征编码)和机器学习模型(如线性回归、决策树和神经网络)结合使用,以提高数据分析和模型的性能。在处理不同数据源和任务时,需要根据实际需求选择合适的数据处理方法。
SQL 转换器 #
SQLTransformer 实现由 SQL 语句定义的转换。
目前只支持SELECT ... FROM __THIS__ ...where __THIS__代表输入表的SQL语法,不能修改。
select 子句指定要在输出中显示的字段、常量和表达式。除了下面注释部分描述的情况,它可以是 Flink SQL 支持的任何 select 子句。用户也可以使用 Flink SQL 的内置函数和 UDF 来对这些选中的列进行操作。
例如,SQLTransformer 支持如下语句:
SELECT a, a + b AS a_b FROM __THIS__
SELECT a, SQRT(b) AS b_sqrt FROM __THIS__ where a > 5
SELECT a, b, SUM(c) AS c_sum FROM __THIS__ GROUP BY a, b
注意:此运算符仅生成仅附加/仅插入表作为其输出。如果输出表可能包含撤回消息(例如,SELECT ... FROM __THIS__ GROUP BY ...以流模式对表执行操作),此运算符将汇总所有更改日志并仅输出最终状态。
Parameters #

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.ml.feature.sqltransformer.SQLTransformer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.util.Arrays;
/** Simple program that creates a SQLTransformer instance and uses it for feature engineering. */
public class SQLTransformerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromCollection(
Arrays.asList(Row.of(0, 1.0, 3.0), Row.of(2, 2.0, 5.0)),
new RowTypeInfo(Types.INT, Types.DOUBLE, Types.DOUBLE));
Table inputTable = tEnv.fromDataStream(inputStream).as("id", "v1", "v2");
// Creates a SQLTransformer object and initializes its parameters.
SQLTransformer sqlTransformer =
new SQLTransformer()
.setStatement("SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__");
// Uses the SQLTransformer object for feature transformations.
Table outputTable = sqlTransformer.transform(inputTable)[0];
// Extracts and displays the results.
outputTable.execute().print();
}
}
Python
# Simple program that creates a SQLTransformer instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.sqltransformer import SQLTransformer
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(env)
# Generates input data.
input_data_table = t_env.from_data_stream(
env.from_collection([
(0, 1.0, 3.0),
(2, 2.0, 5.0),
],
type_info=Types.ROW_NAMED(
['id', 'v1', 'v2'],
[Types.INT(), Types.DOUBLE(), Types.DOUBLE()])))
# Creates a SQLTransformer object and initializes its parameters.
sql_transformer = SQLTransformer() \
.set_statement('SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__')
# Uses the SQLTransformer object for feature transformations.
output_table = sql_transformer.transform(input_data_table)[0]
# Extracts and displays the results.
output_table.execute().print()
StandardScaler(标准化缩放器)是一种特征预处理方法,用于将特征缩放到均值为0、方差为1的标准正态分布。标准化缩放器通过将特征值减去均值,然后除以标准差,从而将特征缩放到一个相对稳定的范围。它通常用于处理具有不同尺度和分布的特征,以提高机器学习模型的性能。
标准化缩放器的工作原理是将特征值减去均值,然后除以标准差,从而将特征缩放到均值为0、方差为1的标准正态分布。例如,对于特征向量(x1, x2, x3),标准化缩放器将其转换为以下形式:
(x1 - mean(x1)) / std(x1),
(x2 - mean(x2)) / std(x2),
(x3 - mean(x3)) / std(x3)
标准化缩放器的主要优点是可以适应不同尺度和分布的特征,提高模型的训练和预测性能。此外,标准化缩放器可以减小特征之间的权重差异,从而提高机器学习模型的稳定性和泛化能力。
然而,标准化缩放器的缺点是它可能受到异常值和离群点的影响,导致性能下降。在处理具有异常值和离群点的数据时,可以考虑使用其他特征缩放方法(如最小-最大缩放器和鲁棒缩放器)进行更鲁棒的数据预处理。
在实际应用中,标准化缩放器通常与其他预处理方法(如特征选择和规范化)结合使用,以提高模型的性能。在处理不同尺度和分布的特征时,需要根据实际需求选择合适的特征缩放方法。
σ表示特征的标准差。标准差是一个衡量数据点与均值之间差异的度量,它可以帮助我们了解数据的离散程度。计算标准差的过程如下:
计算特征的均值(mean):首先,对于给定的特征,计算所有数据点的均值。均值是所有数据点之和除以数据点的数量。
公式:μ = Σx_i / n
其中,x_i表示第i个数据点的值,n表示数据点的总数。
计算每个数据点与均值之间的差值:接下来,对于每个数据点,计算其值与均值之间的差值。
公式:d_i = x_i - μ
其中,d_i表示第i个数据点与均值之间的差值。
计算差值的平方:将每个差值的平方相加。
公式:Σ(d_i)^2
其中,(d_i)^2表示第i个差值的平方。
计算方差(variance):将差值平方之和除以数据点的数量(或数量减1,这取决于是否使用样本方差或总体方差)。
公式(样本方差):s^2 = Σ(d_i)^2 / (n - 1)
公式(总体方差):σ^2 = Σ(d_i)^2 / n
计算标准差:最后,计算方差的平方根以得到标准差。
公式:σ = √s^2 或 σ = √σ^2
通过这个过程,我们可以计算出特征的标准差σ。然后,在StandardScaler中使用这个值来对特征进行缩放。
StandardScaler 是一种通过去除均值并将每个维度缩放为单位方差来标准化输入特征的算法。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
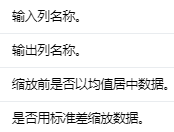
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.standardscaler.StandardScaler;
import org.apache.flink.ml.feature.standardscaler.StandardScalerModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that trains a StandardScaler model and uses it for feature engineering. */
public class StandardScalerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(Vectors.dense(-2.5, 9, 1)),
Row.of(Vectors.dense(1.4, -5, 1)),
Row.of(Vectors.dense(2, -1, -2)));
Table inputTable = tEnv.fromDataStream(inputStream).as("input");
// Creates a StandardScaler object and initializes its parameters.
StandardScaler standardScaler = new StandardScaler();
// Trains the StandardScaler Model.
StandardScalerModel model = standardScaler.fit(inputTable);
// Uses the StandardScaler Model for predictions.
Table outputTable = model.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector inputValue = (DenseVector) row.getField(standardScaler.getInputCol());
DenseVector outputValue = (DenseVector) row.getField(standardScaler.getOutputCol());
System.out.printf("Input Value: %s\tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that trains a StandardScaler model and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.standardscaler import StandardScaler
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(-2.5, 9, 1),),
(Vectors.dense(1.4, -5, 1),),
(Vectors.dense(2, -1, -2),),
],
type_info=Types.ROW_NAMED(
['input'],
[DenseVectorTypeInfo()])
))
# create a standard-scaler object and initialize its parameters
standard_scaler = StandardScaler()
# train the standard-scaler model
model = standard_scaler.fit(input_data)
# use the standard-scaler model for predictions
output = model.transform(input_data)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(standard_scaler.get_input_col())]
output_value = result[field_names.index(standard_scaler.get_output_col())]
print('Input Value: ' + str(input_value) + ' \tOutput Value: ' + str(output_value))
StopWordsRemover(停用词过滤器)是一种文本预处理方法,用于去除语言中常见但对文本分类和挖掘无意义的单词。停用词通常是像“the”、“is”、“and”、“a”、“an”等这样的单词,它们不包含有关文本内容的重要信息,但在文本处理中占据大量的单词频率。停用词过滤器通过使用停用词列表来过滤文本中的这些单词,以提高文本分析和机器学习模型的性能。
停用词过滤器的主要优点是可以减少文本噪声和冗余信息,提高文本分类和挖掘任务的准确性和可靠性。此外,停用词过滤器可以适应不同语言和文本类型的数据,通过调整停用词列表来平衡模型的训练和评估。
然而,停用词过滤器的缺点是它可能会去除某些在特定上下文中具有重要意义的单词。在某些情况下,停用词过滤器可能会导致信息损失和模型性能下降。为了解决这些问题,可以考虑使用基于语法和语义的文本处理方法(如词干提取、词形还原和命名实体识别)和机器学习方法(如深度学习和自然语言处理模型)进行更高级的文本处理。
在实际应用中,停用词过滤器通常与其他文本预处理方法(如词干提取和词形还原)和特征提取方法(如词袋模型、TF-IDF和词嵌入)结合使用,以提高自然语言处理和文本挖掘任务的性能。在处理不同语言和文本类型的数据时,需要根据实际需求选择合适的文本预处理方法。
停用词删除器 #
从输入中过滤掉停用词的特征转换器。
注意:输入数组中的空值将被保留,除非明确地将空值添加到 stopWords。
另请参阅:停用词(维基百科)
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
包含要删除的停用词的字符串数组。
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
删除了停用词的字符串数组。
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
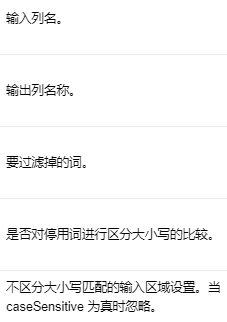
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.stopwordsremover.StopWordsRemover;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** Simple program that creates a StopWordsRemover instance and uses it for feature engineering. */
public class StopWordsRemoverExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of((Object) new String[] {"test", "test"}),
Row.of((Object) new String[] {"a", "b", "c", "d"}),
Row.of((Object) new String[] {"a", "the", "an"}),
Row.of((Object) new String[] {"A", "The", "AN"}),
Row.of((Object) new String[] {null}),
Row.of((Object) new String[] {}));
Table inputTable = tEnv.fromDataStream(inputStream).as("input");
// Creates a StopWordsRemover object and initializes its parameters.
StopWordsRemover remover =
new StopWordsRemover().setInputCols("input").setOutputCols("output");
// Uses the StopWordsRemover object for feature transformations.
Table outputTable = remover.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
String[] inputValues = row.getFieldAs("input");
String[] outputValues = row.getFieldAs("output");
System.out.printf(
"Input Values: %s\tOutput Values: %s\n",
Arrays.toString(inputValues), Arrays.toString(outputValues));
}
}
}
Python
# Simple program that creates a StopWordsRemover instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.stopwordsremover import StopWordsRemover
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_table = t_env.from_data_stream(
env.from_collection([
(["test", "test"],),
(["a", "b", "c", "d"],),
(["a", "the", "an"],),
(["A", "The", "AN"],),
([None],),
([],),
],
type_info=Types.ROW_NAMED(
['input'],
[Types.OBJECT_ARRAY(Types.STRING())])))
# create a StopWordsRemover object and initialize its parameters
remover = StopWordsRemover().set_input_cols('input').set_output_cols('output')
# use the StopWordsRemover for feature engineering
output_table = remover.transform(input_table)[0]
# extract and display the results
field_names = output_table.get_schema().get_field_names()
for result in t_env.to_data_stream(output_table).execute_and_collect():
input_value = result[field_names.index('input')]
output_value = result[field_names.index('output')]
print('Input Value: ' + str(input_value) + '\tOutput Value: ' + str(output_value))
StringIndexer(字符串索引器)是一种数据预处理方法,用于将分类变量(如文本标签)转换为数值变量(如整数索引)。字符串索引器通常用于机器学习模型的训练和预测,以便处理分类变量和数值变量的混合数据类型。
字符串索引器的工作原理是将每个分类变量映射到唯一的整数索引,从而将分类变量转换为数值变量。例如,对于标签列中的文本标签("red","green","blue"),字符串索引器将其转换为整数索引(0,1,2)。这些整数索引可以被机器学习模型处理和使用。
字符串索引器的主要优点是可以将分类变量转换为数值变量,以便于机器学习模型的训练和预测。此外,字符串索引器可以适应不同分类变量的数据类型和范围,通过调整索引映射来平衡模型的训练和评估。
然而,字符串索引器的缺点是它可能会将相似但不完全相同的分类变量映射到不同的整数索引,导致模型性能下降。在某些情况下,可以考虑使用其他数据预处理方法(如词嵌入和one-hot编码)来处理分类变量和数值变量的混合数据类型。
在实际应用中,字符串索引器通常与其他数据预处理方法(如特征缩放和特征选择)和机器学习模型(如逻辑回归、决策树和神经网络)结合使用,以提高模型的性能。在处理分类变量和数值变量的混合数据类型时,需要根据实际需求选择合适的数据预处理方法。
字符串索引器 #
StringIndexer 将输入的一列或多列(字符串/数值)映射到一列或多列索引输出列(整数值)。当且仅当它们对应的输入列相同时,两个数据点的输出索引相同。索引位于 [0,numDistinctValuesInThisColumn] 中。
IndexToStringModel 使用 StringIndexer 计算的模型数据将输入索引列转换为字符串列。它是 StringIndexerModel 的反向操作。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
字符串/数值的索引。
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
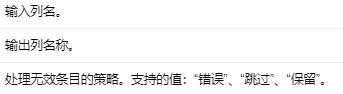
编辑
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
'arbitrary' 表示任意顺序。
'frequencyDesc' 表示频率降序。
'frequencyAsc' 表示频率升序。
'alphabetDesc' 表示字典顺序降序。
'alphabetAsc' 表示字典顺序升序。
Java
import org.apache.flink.ml.feature.stringindexer.StringIndexer;
import org.apache.flink.ml.feature.stringindexer.StringIndexerModel;
import org.apache.flink.ml.feature.stringindexer.StringIndexerParams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** Simple program that trains a StringIndexer model and uses it for feature engineering. */
public class StringIndexerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input training and prediction data.
DataStream<Row> trainStream =
env.fromElements(
Row.of("a", 1.0),
Row.of("b", 1.0),
Row.of("b", 2.0),
Row.of("c", 0.0),
Row.of("d", 2.0),
Row.of("a", 2.0),
Row.of("b", 2.0),
Row.of("b", -1.0),
Row.of("a", -1.0),
Row.of("c", -1.0));
Table trainTable = tEnv.fromDataStream(trainStream).as("inputCol1", "inputCol2");
DataStream<Row> predictStream =
env.fromElements(Row.of("a", 2.0), Row.of("b", 1.0), Row.of("c", 2.0));
Table predictTable = tEnv.fromDataStream(predictStream).as("inputCol1", "inputCol2");
// Creates a StringIndexer object and initializes its parameters.
StringIndexer stringIndexer =
new StringIndexer()
.setStringOrderType(StringIndexerParams.ALPHABET_ASC_ORDER)
.setInputCols("inputCol1", "inputCol2")
.setOutputCols("outputCol1", "outputCol2");
// Trains the StringIndexer Model.
StringIndexerModel model = stringIndexer.fit(trainTable);
// Uses the StringIndexer Model for predictions.
Table outputTable = model.transform(predictTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Object[] inputValues = new Object[stringIndexer.getInputCols().length];
double[] outputValues = new double[stringIndexer.getInputCols().length];
for (int i = 0; i < inputValues.length; i++) {
inputValues[i] = row.getField(stringIndexer.getInputCols()[i]);
outputValues[i] = (double) row.getField(stringIndexer.getOutputCols()[i]);
}
System.out.printf(
"Input Values: %s \tOutput Values: %s\n",
Arrays.toString(inputValues), Arrays.toString(outputValues));
}
}
}
Python
# Simple program that trains a StringIndexer model and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.stringindexer import StringIndexer
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input training and prediction data
train_table = t_env.from_data_stream(
env.from_collection([
('a', 1.),
('b', 1.),
('b', 2.),
('c', 0.),
('d', 2.),
('a', 2.),
('b', 2.),
('b', -1.),
('a', -1.),
('c', -1.),
],
type_info=Types.ROW_NAMED(
['input_col1', 'input_col2'],
[Types.STRING(), Types.DOUBLE()])
))
predict_table = t_env.from_data_stream(
env.from_collection([
('a', 2.),
('b', 1.),
('c', 2.),
],
type_info=Types.ROW_NAMED(
['input_col1', 'input_col2'],
[Types.STRING(), Types.DOUBLE()])
))
# create a string-indexer object and initialize its parameters
string_indexer = StringIndexer() \
.set_string_order_type('alphabetAsc') \
.set_input_cols('input_col1', 'input_col2') \
.set_output_cols('output_col1', 'output_col2')
# train the string-indexer model
model = string_indexer.fit(train_table)
# use the string-indexer model for feature engineering
output = model.transform(predict_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
input_values = [None for _ in string_indexer.get_input_cols()]
output_values = [None for _ in string_indexer.get_input_cols()]
for result in t_env.to_data_stream(output).execute_and_collect():
for i in range(len(string_indexer.get_input_cols())):
input_values[i] = result[field_names.index(string_indexer.get_input_cols()[i])]
output_values[i] = result[field_names.index(string_indexer.get_output_cols()[i])]
print('Input Values: ' + str(input_values) + '\tOutput Values: ' + str(output_values))
Tokenizer(分词器)是一种文本预处理方法,用于将文本数据拆分为单词或子字符串的序列,以便于后续的文本处理和特征提取。分词器通常用于自然语言处理和文本挖掘任务中,以提高文本数据的可读性和机器学习模型的性能。
分词器的工作原理是将文本数据拆分为单词或子字符串的序列,通常使用空格、标点符号、数字和特殊字符等标记进行分隔。例如,对于句子("This is a tokenizer"),分词器将其拆分为单词序列("This","is","a","tokenizer")。
分词器的主要优点是可以将文本数据拆分为单词或子字符串的序列,以便于后续的文本处理和特征提取。此外,分词器可以适应不同语言和文本类型的数据,通过调整分词规则和参数来平衡模型的训练和评估。
然而,分词器的缺点是它可能会将某些复合单词或专有名词拆分为多个子字符串,导致信息损失和模型性能下降。在某些情况下,可以考虑使用基于语法和语义的文本处理方法(如命名实体识别和语言模型)和机器学习方法(如深度学习和自然语言处理模型)进行更高级的文本处理。
在实际应用中,分词器通常与其他文本预处理方法(如停用词过滤器和词干提取器)和特征提取方法(如词袋模型、TF-IDF和词嵌入)结合使用,以提高自然语言处理和文本挖掘任务的性能。在处理不同语言和文本类型的数据时,需要根据实际需求选择合适的文本预处理方法。
分词器 #
Tokenizer 是一种将输入字符串转换为小写,然后按空格拆分的算法。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
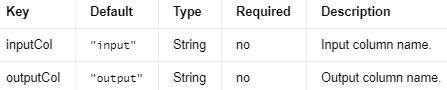
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.tokenizer.Tokenizer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** Simple program that creates a Tokenizer instance and uses it for feature engineering. */
public class TokenizerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(Row.of("Test for tokenization."), Row.of("Te,st. punct"));
Table inputTable = tEnv.fromDataStream(inputStream).as("input");
// Creates a Tokenizer object and initializes its parameters.
Tokenizer tokenizer = new Tokenizer().setInputCol("input").setOutputCol("output");
// Uses the Tokenizer object for feature transformations.
Table outputTable = tokenizer.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
String inputValue = (String) row.getField(tokenizer.getInputCol());
String[] outputValues = (String[]) row.getField(tokenizer.getOutputCol());
System.out.printf(
"Input Value: %s \tOutput Values: %s\n",
inputValue, Arrays.toString(outputValues));
}
}
}
Python
# Simple program that creates a Tokenizer instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.tokenizer import Tokenizer
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(env)
# Generates input data.
input_data_table = t_env.from_data_stream(
env.from_collection([
('Test for tokenization.',),
('Te,st. punct',),
],
type_info=Types.ROW_NAMED(
['input'],
[Types.STRING()])))
# Creates a Tokenizer object and initializes its parameters.
tokenizer = Tokenizer() \
.set_input_col("input") \
.set_output_col("output")
# Uses the Tokenizer object for feature transformations.
output = tokenizer.transform(input_data_table)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(tokenizer.get_input_col())]
output_value = result[field_names.index(tokenizer.get_output_col())]
print('Input Value: ' + str(input_value) + '\tOutput Values: ' + str(output_value))
UnivariateFeatureSelector(单变量特征选择器)是一种特征选择方法,用于从单个特征和目标变量之间的关系中选择重要的特征。单变量特征选择器通常用于机器学习模型的训练和预测,以便于减少特征维度和提高模型性能。
单变量特征选择器的工作原理是根据每个特征和目标变量之间的关系评估其重要性,通常使用统计方法和机器学习方法进行计算和排序。例如,对于二元分类任务,可以使用卡方检验、t检验、F检验等
方法计算每个特征的p值和显著性水平,从而选择最相关的特征。其他常用的单变量特征选择方法包括皮尔逊相关系数、互信息和最大信息系数等。
卡方检验、t检验和F检验是三种常用的统计假设检验方法,它们用于比较不同数据集之间的差异或关系。以下是它们的简要概述和主要应用:
卡方检验(Chi-square Test):
卡方检验是一种用于评估两个分类变量之间关系的非参数检验方法。它基于观察频数与期望频数之间的差异来计算卡方统计量,并根据卡方分布确定观察到的差异是否具有统计显著性。卡方检验通常用于:
判断观察到的分类变量的频数分布与理论或期望的频数分布是否有显著差异。
检验两个分类变量之间是否独立,即它们之间是否存在关联。
t检验(t-Test):
t检验是一种用于比较两个样本均值之间差异的参数检验方法。它假设数据服从正态分布并且具有相同的方差(尽管有些t检验的变种可以处理不同方差的情况)。t检验主要有三种类型:
单样本t检验:比较单个样本的均值与已知或假设的总体均值之间的差异。
独立样本t检验:比较两个独立样本的均值之间的差异,以确定两个总体的均值是否有显著差异。
配对样本t检验:比较两个相关样本(例如,在同一群体中进行重复测量或实验的前后测量)的均值之间的差异。
F检验(F-Test):
F检验是一种用于比较两个或多个样本方差之间差异的参数检验方法。它基于F分布来确定观察到的方差之间的差异是否具有统计显著性。F检验的主要应用包括:
检验两个总体的方差是否相等,以确定它们是否具有相同的变异性。
方差分析(ANOVA),用于比较三个或更多组的均值之间的差异。在这种情况下,F检验用于确定组间变异是否显著大于组内变异,从而判断不同组之间是否存在显著差异。
选择合适的检验方法取决于研究目的和数据的类型。例如,如果需要比较两个样本的均值差异,可以使用t检验;如果需要比较多个组的均值差异,可以使用F检验(ANOVA)。如果要检验分类变量之间的关联性或观察到的频数分布与期望频数分布之间的差异,可以使用卡方检验。
每种检验方法都有其特定的应用场景和假设前提。在选择检验方法时,需要考虑数据的分布特征、样本大小、独立性等因素。此外,在进行假设检验时,需要谨慎地确定显著性水平(如0.05或0.01),以便正确地拒绝或接受原假设。不同的检验方法和显著性水平可能会导致不同的结论,因此选择合适的方法对于获得可靠的统计推断至关重要。
皮尔逊相关系数(Pearson Correlation Coefficient):
皮尔逊相关系数是一种衡量两个连续变量之间线性关系的参数度量。它的取值范围在-1(完全负相关)到1(完全正相关)之间,0表示两个变量之间无线性关系。皮尔逊相关系数只能捕捉线性关系,对于非线性关系可能不准确。
公式:r = Σ[(x_i - μ_x)(y_i - μ_y)] / [√Σ(x_i - μ_x)^2 * √Σ(y_i - μ_y)^2]
其中,x_i和y_i分别表示变量X和Y的第i个数据点,μ_x和μ_y表示它们的均值。
互信息(Mutual Information):
互信息是一种衡量两个随机变量之间依赖关系的非参数度量,它基于两个变量的联合概率分布和边缘概率分布。互信息可以捕捉任意类型的关系(线性和非线性),其值越大,两个变量之间的关系越强。互信息的值在0(独立)到较大的正值(强关联)之间变化。
公式:I(X;Y) = ΣΣp(x_i, y_j) * log(p(x_i, y_j) / (p(x_i) * p(y_j)))
其中,p(x_i, y_j)表示X和Y的联合概率分布,p(x_i)和p(y_j)表示它们的边缘概率分布。
最大信息系数(Maximal Information Coefficient, MIC):
最大信息系数是一种基于互信息的非参数度量,用于衡量两个连续变量之间的任意关系(线性和非线性)。MIC通过对数据进行分箱并计算不同分箱情况下的最大归一化互信息来得到。MIC的取值范围在0(独立)到1(完全相关)之间,它可以捕捉各种复杂的关系。
总之,皮尔逊相关系数、互信息和最大信息系数都可以用来衡量两个变量之间的关系,但它们在捕捉不同类型关系(线性、非线性)和适用场景(连续、离散变量)方面有所不同。根据实际数据和分析目标,可以选择合适的度量方法来评估变量之间的关系。
单变量特征选择器的主要优点是可以快速准确地选择与目标变量最相关的特征,从而减少特征维度和提高模型性能。此外,单变量特征选择器可以适应不同类型和分布的数据,通过调整特征选择方法和参数来平衡模型的训练和评估。
然而,单变量特征选择器的缺点是它可能会忽略不同特征之间的相互作用和相关性,导致特征选择不完全和模型性能下降。在某些情况下,可以考虑使用其他特征选择方法(如递归特征消除和L1正则化)和机器学习方法(如深度学习和集成学习)进行更高级的特征选择。
在实际应用中,单变量特征选择器通常与其他特征选择方法(如递归特征消除和L1正则化)和机器学习模型(如逻辑回归、决策树和神经网络)结合使用,以提高模型的性能。在处理不同类型和分布的数据时,需要根据实际需求选择合适的特征选择方法。
单变量特征选择器 #
UnivariateFeatureSelector 是一种基于针对标签的单变量统计测试来选择特征的算法。
目前,Flink 支持三种 UnivariateFeatureSelectors:卡方、方差分析 F-test 和 F-值。featureType用户可以通过设置和 来选择 UnivariateFeatureSelector labelType,Flink 会根据指定的featureType和来选择评分函数labelType。
支持以下featureType和的组合:labelType
`featureType` `categorical` 和 `labelType` `categorical`:Flink 使用卡方,即 sklearn 中的 chi2。
`featureType` `continuous` 和 `labelType` `categorical`:Flink 使用 ANOVA F-test,即 sklearn 中的 f_classif。
`featureType` `continuous` 和 `labelType` `continuous`:Flink 使用的是 F-value,即 sklearn 中的 f_regression。
UnivariateFeatureSelector 支持不同的选择模式:
numTopFeatures:根据假设选择固定数量的顶级特征。
percentile:与 numTopFeatures 类似,但选择所有特征的一部分而不是固定数量。
fpr:选择p值低于阈值的所有特征,从而控制选择的误报率。
fdr:使用Benjamini-Hochberg 程序选择错误发现率低于阈值的所有特征。
fwe:选择 p 值低于阈值的所有特征。阈值按 1/numFeatures 缩放,从而控制选择的家庭错误率。
默认情况下,选择模式为numTopFeatures。
Input Columns #
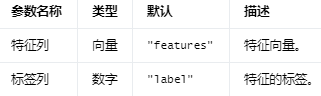
编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
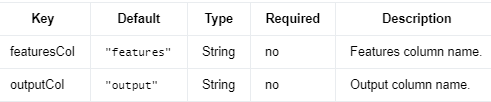
编辑
添加图片注释,不超过 140 字(可选)
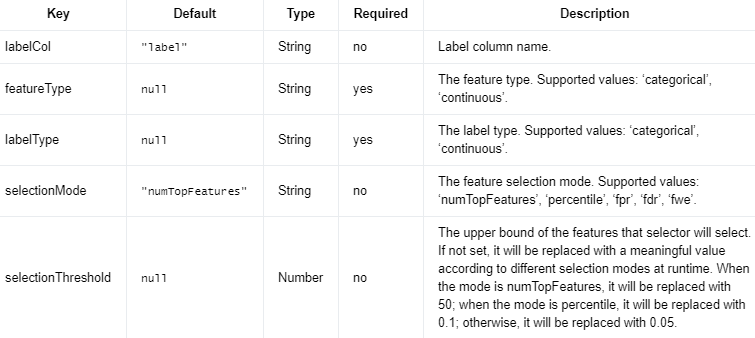
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.univariatefeatureselector.UnivariateFeatureSelector;
import org.apache.flink.ml.feature.univariatefeatureselector.UnivariateFeatureSelectorModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/**
* Simple program that trains a {@link UnivariateFeatureSelector} model and uses it for feature
* selection.
*/
public class UnivariateFeatureSelectorExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input training and prediction data.
DataStream<Row> trainStream =
env.fromElements(
Row.of(Vectors.dense(1.7, 4.4, 7.6, 5.8, 9.6, 2.3), 3.0),
Row.of(Vectors.dense(8.8, 7.3, 5.7, 7.3, 2.2, 4.1), 2.0),
Row.of(Vectors.dense(1.2, 9.5, 2.5, 3.1, 8.7, 2.5), 1.0),
Row.of(Vectors.dense(3.7, 9.2, 6.1, 4.1, 7.5, 3.8), 2.0),
Row.of(Vectors.dense(8.9, 5.2, 7.8, 8.3, 5.2, 3.0), 4.0),
Row.of(Vectors.dense(7.9, 8.5, 9.2, 4.0, 9.4, 2.1), 4.0));
Table trainTable = tEnv.fromDataStream(trainStream).as("features", "label");
// Creates a UnivariateFeatureSelector object and initializes its parameters.
UnivariateFeatureSelector univariateFeatureSelector =
new UnivariateFeatureSelector()
.setFeaturesCol("features")
.setLabelCol("label")
.setFeatureType("continuous")
.setLabelType("categorical")
.setSelectionThreshold(1);
// Trains the UnivariateFeatureSelector model.
UnivariateFeatureSelectorModel model = univariateFeatureSelector.fit(trainTable);
// Uses the UnivariateFeatureSelector model for predictions.
Table outputTable = model.transform(trainTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector inputValue =
(DenseVector) row.getField(univariateFeatureSelector.getFeaturesCol());
DenseVector outputValue =
(DenseVector) row.getField(univariateFeatureSelector.getOutputCol());
System.out.printf("Input Value: %-15s\tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that creates a UnivariateFeatureSelector instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.univariatefeatureselector import UnivariateFeatureSelector
from pyflink.table import StreamTableEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(env)
# Generates input training and prediction data.
input_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(1.7, 4.4, 7.6, 5.8, 9.6, 2.3), 3.0,),
(Vectors.dense(8.8, 7.3, 5.7, 7.3, 2.2, 4.1), 2.0,),
(Vectors.dense(1.2, 9.5, 2.5, 3.1, 8.7, 2.5), 1.0,),
(Vectors.dense(3.7, 9.2, 6.1, 4.1, 7.5, 3.8), 2.0,),
(Vectors.dense(8.9, 5.2, 7.8, 8.3, 5.2, 3.0), 4.0,),
(Vectors.dense(7.9, 8.5, 9.2, 4.0, 9.4, 2.1), 4.0,),
],
type_info=Types.ROW_NAMED(
['features', 'label'],
[DenseVectorTypeInfo(), Types.FLOAT()])
))
# Creates an UnivariateFeatureSelector object and initializes its parameters.
univariate_feature_selector = UnivariateFeatureSelector() \
.set_features_col('features') \
.set_label_col('label') \
.set_feature_type('continuous') \
.set_label_type('categorical') \
.set_selection_threshold(1)
# Trains the UnivariateFeatureSelector Model.
model = univariate_feature_selector.fit(input_table)
# Uses the UnivariateFeatureSelector Model for predictions.
output = model.transform(input_table)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_index = field_names.index(univariate_feature_selector.get_features_col())
output_index = field_names.index(univariate_feature_selector.get_output_col())
print('Input Value: ' + str(result[input_index]) +
'\tOutput Value: ' + str(result[output_index]))
VarianceThresholdSelector(方差阈值选择器)是一种特征选择方法,用于从特征方差较小的特征中选择重要的特征。方差阈值选择器通常用于机器学习模型的训练和预测,以便于减少特征维度和提高模型性能。
方差阈值选择器的工作原理是根据每个特征的方差大小评估其重要性,从而选择方差较大的特征。具体地,方差阈值选择器计算每个特征的方差,并根据预先设置的方差阈值将其分类为高方差特征和低方差特征。通常情况下,方差阈值选择器会保留高方差特征,从而减少特征维度和提高模型性能。
方差阈值选择器的主要优点是可以快速准确地选择方差较大的特征,从而减少特征维度和提高模型性能。此外,方差阈值选择器可以适应不同类型和分布的数据,通过调整方差阈值来平衡模型的训练和评估。
然而,方差阈值选择器的缺点是它可能会忽略特征之间的相互作用和相关性,导致特征选择不完全和模型性能下降。在某些情况下,可以考虑使用其他特征选择方法(如递归特征消除和L1正则化)和机器学习方法(如深度学习和集成学习)进行更高级的特征选择。
在实际应用中,方差阈值选择器通常与其他特征选择方法(如递归特征消除和L1正则化)和机器学习模型(如逻辑回归、决策树和神经网络)结合使用,以提高模型的性能。在处理不同类型和分布的数据时,需要根据实际需求选择合适的特征选择方法。
方差阈值选择器 #
VarianceThresholdSelector 是一个移除低方差特征的选择器。方差不大于 varianceThreshold 的特征将被删除。如果未设置,varianceThreshold 默认为 0,这意味着只有方差为 0 的特征(即在所有样本中具有相同值的特征)将被删除。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
缩放的geatures
Parameters #
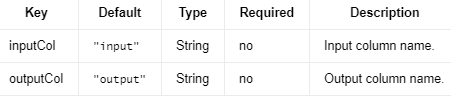
编辑
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
方差不大于此阈值的特征将被删除
Java
import org.apache.flink.ml.feature.variancethresholdselector.VarianceThresholdSelector;
import org.apache.flink.ml.feature.variancethresholdselector.VarianceThresholdSelectorModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/**
* Simple program that trains a {@link VarianceThresholdSelector} model and uses it for feature
* selection.
*/
public class VarianceThresholdSelectorExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input training and prediction data.
DataStream<Row> trainStream =
env.fromElements(
Row.of(1, Vectors.dense(5.0, 7.0, 0.0, 7.0, 6.0, 0.0)),
Row.of(2, Vectors.dense(0.0, 9.0, 6.0, 0.0, 5.0, 9.0)),
Row.of(3, Vectors.dense(0.0, 9.0, 3.0, 0.0, 5.0, 5.0)),
Row.of(4, Vectors.dense(1.0, 9.0, 8.0, 5.0, 7.0, 4.0)),
Row.of(5, Vectors.dense(9.0, 8.0, 6.0, 5.0, 4.0, 4.0)),
Row.of(6, Vectors.dense(6.0, 9.0, 7.0, 0.0, 2.0, 0.0)));
Table trainTable = tEnv.fromDataStream(trainStream).as("id", "input");
// Create a VarianceThresholdSelector object and initialize its parameters
double threshold = 8.0;
VarianceThresholdSelector varianceThresholdSelector =
new VarianceThresholdSelector()
.setVarianceThreshold(threshold)
.setInputCol("input");
// Train the VarianceThresholdSelector model.
VarianceThresholdSelectorModel model = varianceThresholdSelector.fit(trainTable);
// Uses the VarianceThresholdSelector model for predictions.
Table outputTable = model.transform(trainTable)[0];
// Extracts and displays the results.
System.out.printf("Variance Threshold: %s\n", threshold);
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector inputValue =
(DenseVector) row.getField(varianceThresholdSelector.getInputCol());
DenseVector outputValue =
(DenseVector) row.getField(varianceThresholdSelector.getOutputCol());
System.out.printf("Input Values: %-15s\tOutput Values: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that trains a VarianceThresholdSelector model and uses it for feature
# selection.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.variancethresholdselector import VarianceThresholdSelector
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input training and prediction data
train_data = t_env.from_data_stream(
env.from_collection([
(1, Vectors.dense(5.0, 7.0, 0.0, 7.0, 6.0, 0.0),),
(2, Vectors.dense(0.0, 9.0, 6.0, 0.0, 5.0, 9.0),),
(3, Vectors.dense(0.0, 9.0, 3.0, 0.0, 5.0, 5.0),),
(4, Vectors.dense(1.0, 9.0, 8.0, 5.0, 7.0, 4.0),),
(5, Vectors.dense(9.0, 8.0, 6.0, 5.0, 4.0, 4.0),),
(6, Vectors.dense(6.0, 9.0, 7.0, 0.0, 2.0, 0.0),),
],
type_info=Types.ROW_NAMED(
['id', 'input'],
[Types.INT(), DenseVectorTypeInfo()])
))
# create a VarianceThresholdSelector object and initialize its parameters
threshold = 8.0
variance_thread_selector = VarianceThresholdSelector()\
.set_input_col("input")\
.set_variance_threshold(threshold)
# train the VarianceThresholdSelector model
model = variance_thread_selector.fit(train_data)
# use the VarianceThresholdSelector model for predictions
output = model.transform(train_data)[0]
# extract and display the results
print("Variance Threshold: " + str(threshold))
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(variance_thread_selector.get_input_col())]
output_value = result[field_names.index(variance_thread_selector.get_output_col())]
print('Input Values: ' + str(input_value) + ' \tOutput Values: ' + str(output_value))
VectorAssembler(向量组合器)是一种数据预处理方法,用于将多个特征列组合成一个向量列,以便于后续的特征转换和机器学习模型的训练和预测。向量组合器通常用于数据集的准备阶段,以便于处理多个特征列和提高模型性能。
向量组合器的工作原理是将多个特征列组合成一个稠密或稀疏的向量列,通常使用Spark中的MLlib或ML库进行计算和转换。例如,对于数据集中的三个特征列("feature1","feature2","feature3"),向量组合器将其转换为一个向量列("features")。
向量组合器的主要优点是可以快速准确地组合多个特征列,从而减少特征维度和提高模型性能。此外,向量组合器可以适应不同类型和分布的数据,通过调整组合规则和参数来平衡模型的训练和评估。
然而,向量组合器的缺点是它可能会忽略特征之间的相互作用和相关性,导致特征组合不完全和模型性能下降。在某些情况下,可以考虑使用其他特征转换方法(如交叉特征、多项式扩展和词嵌入)和机器学习方法(如深度学习和集成学习)进行更高级的特征转换和组合。
在实际应用中,向量组合器通常与其他数据预处理方法(如特征缩放和特征选择)和机器学习模型(如逻辑回归、决策树和神经网络)结合使用,以提高模型的性能。在处理多个特征列和数据类型时,需要根据实际需求选择合适的向量组合方法和库。
矢量汇编器 #
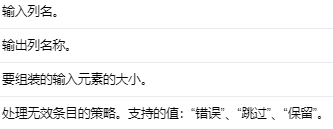
将给定的输入列列表组合成向量列的 Transformer。输入列可以是数字或向量,其大小由 {@link #INPUT_SIZES} 参数指定。具有空值或大小错误的值的无效输入数据将根据 {@link HasHandleInvalid} 参数指定的策略进行处理,如下所示:
keep:如果输入列数据为空,将创建一个具有指定大小和 NaN 值的向量。该向量将在组装过程中用于表示输入列数据。如果输入列数据是向量,则即使数据大小错误,也会在组装过程中使用该数据。
skip:如果输入列数据为空或大小错误的向量,则输入行将被过滤掉,不会发送给下游运算符。
error:如果输入列数据为空或大小错误的向量,将抛出异常。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.vectorassembler.VectorAssembler;
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** Simple program that creates a VectorAssembler instance and uses it for feature engineering. */
public class VectorAssemblerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(
Vectors.dense(2.1, 3.1),
1.0,
Vectors.sparse(5, new int[] {3}, new double[] {1.0})),
Row.of(
Vectors.dense(2.1, 3.1),
1.0,
Vectors.sparse(
5,
new int[] {4, 2, 3, 1},
new double[] {4.0, 2.0, 3.0, 1.0})));
Table inputTable = tEnv.fromDataStream(inputStream).as("vec", "num", "sparseVec");
// Creates a VectorAssembler object and initializes its parameters.
VectorAssembler vectorAssembler =
new VectorAssembler()
.setInputCols("vec", "num", "sparseVec")
.setOutputCol("assembledVec")
.setInputSizes(2, 1, 5);
// Uses the VectorAssembler object for feature transformations.
Table outputTable = vectorAssembler.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Object[] inputValues = new Object[vectorAssembler.getInputCols().length];
for (int i = 0; i < inputValues.length; i++) {
inputValues[i] = row.getField(vectorAssembler.getInputCols()[i]);
}
Vector outputValue = (Vector) row.getField(vectorAssembler.getOutputCol());
System.out.printf(
"Input Values: %s \tOutput Value: %s\n",
Arrays.toString(inputValues), outputValue);
}
}
}
Python
# Simple program that creates a VectorAssembler instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo, SparseVectorTypeInfo
from pyflink.ml.feature.vectorassembler import VectorAssembler
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(2.1, 3.1),
1.0,
Vectors.sparse(5, [3], [1.0])),
(Vectors.dense(2.1, 3.1),
1.0,
Vectors.sparse(5, [1, 2, 3, 4],
[1.0, 2.0, 3.0, 4.0])),
],
type_info=Types.ROW_NAMED(
['vec', 'num', 'sparse_vec'],
[DenseVectorTypeInfo(), Types.DOUBLE(), SparseVectorTypeInfo()])))
# create a vector assembler object and initialize its parameters
vector_assembler = VectorAssembler() \
.set_input_cols('vec', 'num', 'sparse_vec') \
.set_output_col('assembled_vec') \
.set_input_sizes(2, 1, 5) \
.set_handle_invalid('keep')
# use the vector assembler for feature engineering
output = vector_assembler.transform(input_data_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
input_values = [None for _ in vector_assembler.get_input_cols()]
for result in t_env.to_data_stream(output).execute_and_collect():
for i in range(len(vector_assembler.get_input_cols())):
input_values[i] = result[field_names.index(vector_assembler.get_input_cols()[i])]
output_value = result[field_names.index(vector_assembler.get_output_col())]
print('Input Values: ' + str(input_values) + '\tOutput Value: ' + str(output_value))
VectorIndexer(向量索引器)是一种特征转换方法,用于自动识别和转换数值特征中的类别特征,并将其编码为索引标签。向量索引器通常用于机器学习模型的训练和预测,以便于处理包含类别特征的数据集。
向量索引器的工作原理是通过设置一个最大离散度参数和一个最小支持度参数来自动识别和转换数值特征中的类别特征。具体地,向量索引器计算每个特征的唯一值数量,并将其与最大离散度参数进行比较。如果唯一值数量小于或等于最大离散度参数,则将该特征视为类别特征,并使用Spark的StringIndexer或OneHotEncoder将其编码为索引标签。如果唯一值数量大于最大离散度参数,则将该特征视为数值特征,并不进行编码。
向量索引器的主要优点是可以自动识别和转换数值特征中的类别特征,从而减少特征工程的工作量和提高模型性能。此外,向量索引器可以适应不同类型和分布的数据,通过调整参数来平衡模型的训练和评估。
然而,向量索引器的缺点是它可能会将一些数值特征错误地视为类别特征,导致编码不准确和模型性能下降。在某些情况下,可以考虑使用其他特征转换方法(如离散化和多项式扩展)和机器学习方法(如深度学习和集成学习)进行更高级的特征转换和组合。
离散化(Discretization):
离散化是将连续特征转换为离散特征的过程。在离散化过程中,连续特征的值被分成若干区间,每个区间内的值都被替换为相应的离散标签。离散化可以帮助简化数据结构,降低模型复杂度,并提高某些算法(如决策树和朴素贝叶斯分类器)的性能。离散化的方法包括等宽离散化、等频离散化和基于聚类的离散化等。
多项式扩展(Polynomial Expansion):
多项式扩展是一种从原始特征生成高阶多项式和交互项的方法。例如,给定两个特征X和Y,可以通过多项式扩展生成X^2、Y^2、XY等新特征。多项式扩展可以帮助捕捉特征之间的非线性关系和相互作用,从而提高模型的预测能力。多项式扩展通常与线性模型(如线性回归和逻辑回归)结合使用,以实现非线性模型的效果。
在实际应用中,向量索引器通常与其他特征转换方法(如特征缩放和特征选择)和机器学习模型(如逻辑回归、决策树和神经网络)结合使用,以提高模型的性能。在处理包含类别特征的数据集时,需要根据实际需求选择合适的向量索引器和库。
矢量索引器 #
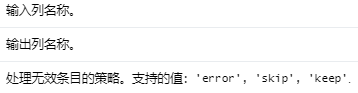
VectorIndexer 是一种实现矢量索引算法的算法。向量索引器将输入向量的每一列映射到连续/分类特征。一个特征是转换为连续特征还是分类特征取决于此列中不同值的数量。如果一列中不同值的数量大于指定参数(即 maxCategories),则相应的输出列不变。否则,它被转换为分类值。对于分类输出,索引位于 [0, numDistinctValuesInThisColumn] 中。
输出模型按升序组织,除了 0.0 始终映射到 0(用于稀疏性)。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
分类特征可以采用的值数量的阈值 (>= 2)。如果发现某个特征具有 > maxCategories 值,则它被声明为连续的。
Java
import org.apache.flink.ml.common.param.HasHandleInvalid;
import org.apache.flink.ml.feature.vectorindexer.VectorIndexer;
import org.apache.flink.ml.feature.vectorindexer.VectorIndexerModel;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
import java.util.List;
/** Simple program that creates a VectorIndexer instance and uses it for feature engineering. */
public class VectorIndexerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
List<Row> trainInput =
Arrays.asList(
Row.of(Vectors.dense(1, 1)),
Row.of(Vectors.dense(2, -1)),
Row.of(Vectors.dense(3, 1)),
Row.of(Vectors.dense(4, 0)),
Row.of(Vectors.dense(5, 0)));
List<Row> predictInput =
Arrays.asList(
Row.of(Vectors.dense(0, 2)),
Row.of(Vectors.dense(0, 0)),
Row.of(Vectors.dense(0, -1)));
Table trainTable = tEnv.fromDataStream(env.fromCollection(trainInput)).as("input");
Table predictTable = tEnv.fromDataStream(env.fromCollection(predictInput)).as("input");
// Creates a VectorIndexer object and initializes its parameters.
VectorIndexer vectorIndexer =
new VectorIndexer()
.setInputCol("input")
.setOutputCol("output")
.setHandleInvalid(HasHandleInvalid.KEEP_INVALID)
.setMaxCategories(3);
// Trains the VectorIndexer Model.
VectorIndexerModel model = vectorIndexer.fit(trainTable);
// Uses the VectorIndexer Model for predictions.
Table outputTable = model.transform(predictTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
System.out.printf(
"Input Value: %s \tOutput Value: %s\n",
row.getField(vectorIndexer.getInputCol()),
row.getField(vectorIndexer.getOutputCol()));
}
}
}
Python
# Simple program that trains a VectorIndexer model and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.vectorindexer import VectorIndexer
from pyflink.table import StreamTableEnvironment
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates input training and prediction data.
train_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(1, 1),),
(Vectors.dense(2, -1),),
(Vectors.dense(3, 1),),
(Vectors.dense(4, 0),),
(Vectors.dense(5, 0),)
],
type_info=Types.ROW_NAMED(
['input', ],
[DenseVectorTypeInfo(), ])))
predict_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(0, 2),),
(Vectors.dense(0, 0),),
(Vectors.dense(0, -1),),
],
type_info=Types.ROW_NAMED(
['input', ],
[DenseVectorTypeInfo(), ])))
# Creates a VectorIndexer object and initializes its parameters.
vector_indexer = VectorIndexer() \
.set_input_col('input') \
.set_output_col('output') \
.set_handle_invalid('keep') \
.set_max_categories(3)
# Trains the VectorIndexer Model.
model = vector_indexer.fit(train_table)
# Uses the VectorIndexer Model for predictions.
output = model.transform(predict_table)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
print('Input Value: ' + str(result[field_names.index(vector_indexer.get_input_col())])
+ '\tOutput Value: ' + str(result[field_names.index(vector_indexer.get_output_col())]))
VectorSlicer(向量切片器):
VectorSlicer是一种选择性地从向量特征中提取特定子集的工具。它可以基于特征的索引值来选择感兴趣的特征。例如,如果原始数据包含10个特征,你可能只对其中的第2、5和8个特征感兴趣,那么可以使用VectorSlicer从原始向量中提取这些特征。VectorSlicer通常在特征选择阶段使用,以便从原始特征中筛选出对模型性能影响较大的特征。
VectorAssembler(向量组合器):
VectorAssembler是一种将多个单一特征列合并成一个向量特征列的工具。例如,如果你有一个包含多个特征列的数据集(如"age"、"income"和"education"等),你可以使用VectorAssembler将这些特征组合成一个特征向量。这在预处理阶段非常有用,因为大多数机器学习算法需要一个特征向量作为输入。VectorAssembler可以将原始数据集中的多个特征列组合成一个新的向量特征列,以便在后续的机器学习模型中使用。矢量切片器 #
VectorSlicer 将向量转换为新特征,它是原始特征的子数组。它对于从给定向量中提取特征很有用。
请注意,不允许重复的特征,因此所选索引之间不能有重叠。如果索引的最大值大于输入向量的大小,它会抛出 IllegalArgumentException
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
用于从向量列中选择特征的索引数组。
Java
import org.apache.flink.ml.feature.vectorslicer.VectorSlicer;
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that creates a VectorSlicer instance and uses it for feature engineering. */
public class VectorSlicerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(Vectors.dense(2.1, 3.1, 1.2, 3.1, 4.6)),
Row.of(Vectors.dense(1.2, 3.1, 4.6, 2.1, 3.1)));
Table inputTable = tEnv.fromDataStream(inputStream).as("vec");
// Creates a VectorSlicer object and initializes its parameters.
VectorSlicer vectorSlicer =
new VectorSlicer().setInputCol("vec").setIndices(1, 2, 3).setOutputCol("slicedVec");
// Uses the VectorSlicer object for feature transformations.
Table outputTable = vectorSlicer.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Vector inputValue = (Vector) row.getField(vectorSlicer.getInputCol());
Vector outputValue = (Vector) row.getField(vectorSlicer.getOutputCol());
System.out.printf("Input Value: %s \tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that creates a VectorSlicer instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.vectorslicer import VectorSlicer
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data_table = t_env.from_data_stream(
env.from_collection([
(1, Vectors.dense(2.1, 3.1, 1.2, 2.1)),
(2, Vectors.dense(2.3, 2.1, 1.3, 1.2)),
],
type_info=Types.ROW_NAMED(
['id', 'vec'],
[Types.INT(), DenseVectorTypeInfo()])))
# create a vector slicer object and initialize its parameters
vector_slicer = VectorSlicer() \
.set_input_col('vec') \
.set_indices(1, 2, 3) \
.set_output_col('sub_vec')
# use the vector slicer model for feature engineering
output = vector_slicer.transform(input_data_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(vector_slicer.get_input_col())]
output_value = result[field_names.index(vector_slicer.get_output_col())]
print('Input Value: ' + str(input_value) + '\tOutput Value: ' + str(output_value))
Swing算法是一种用于推荐系统的基于相似度的算法,它使用用户-项目图的拓扑结构来计算项目之间的相似度和用户与项目之间的关系。Swing算法的主要思想是将用户-项目图的结构描述为用户-项目-用户或项目-用户-项目的“摆动”形式,并根据用户与项目之间的共同关系和相似性来计算推荐结果。
具体来说,Swing算法使用一种基于邻域的方法来计算项目之间的相似度,即对于每个项目,找到与其最相似的一组项目作为其邻居。然后,通过计算用户与邻居之间的交集,来预测用户与该项目之间的关系。最后,根据用户与该项目之间的预测关系和其他项目的相似度来计算推荐结果。
Swing算法的主要优点是它可以处理大规模稀疏数据,并且计算简单,因此具有较高的效率和可扩展性。此外,Swing算法可以适应不同类型和分布的数据,通过调整参数来平衡模型的训练和评估。
然而,Swing算法的缺点是它可能会忽略一些关键的因素,如用户偏好和用户活跃度,导致推荐结果不完全和模型性能下降。在某些情况下,可以考虑使用其他推荐算法(如基于矩阵分解的算法和基于深度学习的算法)进行更高级的推荐和个性化建模。
在实际应用中,Swing算法通常与其他推荐算法和评估方法结合使用,以提高推荐的准确性和效率。在选择合适的推荐算法和库时,需要根据实际需求和数据类型进行选择。
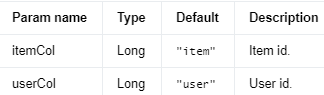
实现 Swing 算法的 AlgoOperator。
Swing 是一种项目召回算法。用户-项目图的拓扑结构通常可以描述为用户-项目-用户或项目-用户-项目,类似于'swing'。例如,如果用户u和用户v 都购买了相同的商品i,他们就会形成一个类似于秋千的关系图。如果 u和v除了i之外还购买了商品j,则认为i 和j是相似的。
参见Xiaoyong Yang、Yadong Zhu 和 Yi Zhang 的“电子商务推荐的大规模产品图构建”。https://arxiv.org/pdf/2010.05525.pdf
Input Columns #
编辑
添加图片注释,不超过 140 字(可选)
Output Columns #
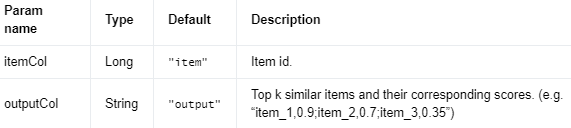
编辑
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
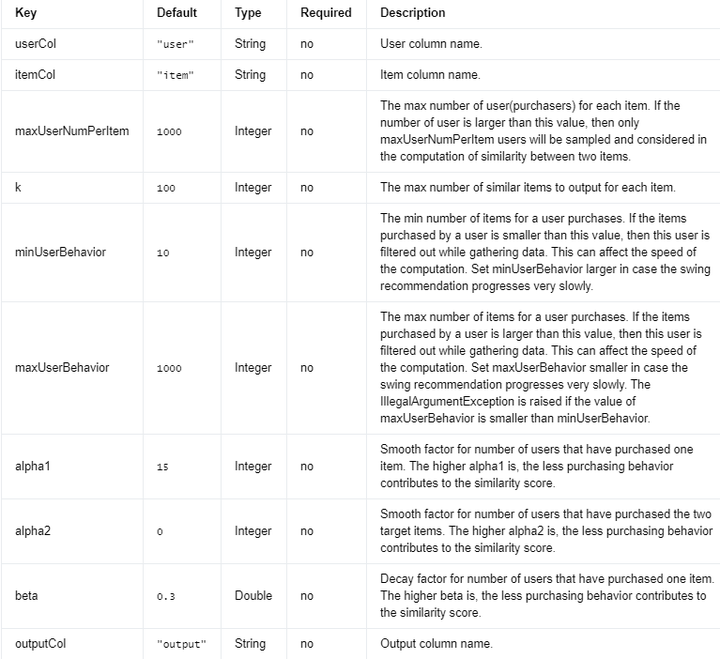
平滑因子(Smooth factor):alpha1
平滑因子主要用于避免计算相似度时出现极端值。当用户购买单个物品的数量较少时,它可以起到稳定相似度得分的作用。alpha1越大,购买行为对相似度得分的影响越小。换句话说,alpha1值较大时,相似度得分更不依赖于购买行为,从而更加稳定。
衰减因子(Decay factor):beta
衰减因子用于减小购买行为对相似度得分的影响。衰减因子通过对购买数量施加一个指数函数来实现这一目标。beta值越高,购买行为对相似度得分的影响越小。这意味着,当beta值较大时,购买行为对相似度得分的贡献会逐渐减小。
总之,平滑因子(alpha1)和衰减因子(beta)都可以影响相似度得分,但它们的作用方式和目的不同。平滑因子主要用于避免极端值,稳定相似度得分,而衰减因子则用于降低购买行为对相似度得分的影响。在实际应用中,可以根据需求和数据特点调整这两个参数,以得到合适的相似度得分。
Java
package org.apache.flink.ml.examples.recommendation;
import org.apache.flink.ml.recommendation.swing.Swing;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/**
* Simple program that creates a Swing instance and uses it to generate recommendations for items.
*/
public class SwingExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(0L, 10L),
Row.of(0L, 11L),
Row.of(0L, 12L),
Row.of(1L, 13L),
Row.of(1L, 12L),
Row.of(2L, 10L),
Row.of(2L, 11L),
Row.of(2L, 12L),
Row.of(3L, 13L),
Row.of(3L, 12L));
Table inputTable = tEnv.fromDataStream(inputStream).as("user", "item");
// Creates a Swing object and initializes its parameters.
Swing swing = new Swing().setUserCol("user").setItemCol("item").setMinUserBehavior(1);
// Transforms the data.
Table[] outputTable = swing.transform(inputTable);
// Extracts and displays the result of swing algorithm.
for (CloseableIterator<Row> it = outputTable[0].execute().collect(); it.hasNext(); ) {
Row row = it.next();
long mainItem = row.getFieldAs(0);
String itemRankScore = row.getFieldAs(1);
System.out.printf("item: %d, top-k similar items: %s\n", mainItem, itemRankScore);
}
}
}
Python
# Simple program that creates a Swing instance and gives recommendations for items.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
from pyflink.ml.recommendation.swing import Swing
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates input data.
input_table = t_env.from_data_stream(
env.from_collection([
(0, 10),
(0, 11),
(0, 12),
(1, 13),
(1, 12),
(2, 10),
(2, 11),
(2, 12),
(3, 13),
(3, 12)
],
type_info=Types.ROW_NAMED(
['user', 'item'],
[Types.LONG(), Types.LONG()])
))
# Creates a swing object and initialize its parameters.
swing = Swing()
.set_item_col('item')
.set_user_col("user")
.set_min_user_behavior(1)
# Transforms the data to Swing algorithm result.
output_table = swing.transform(input_table)
# Extracts and display the results.
field_names = output_table[0].get_schema().get_field_names()
results = t_env.to_data_stream(
output_table[0]).execute_and_collect()
for result in results:
main_item = result[field_names.index(swing.get_item_col())]
item_rank_score = result[1]
print(f'item: {main_item}, top-k similar items: {item_rank_score}')
线性回归 #
线性回归是一种通过对标量响应与一个或多个解释变量之间的关系建模的回归分析。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑
添加图片注释,不超过 140 字(可选)
编辑切换为居中
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
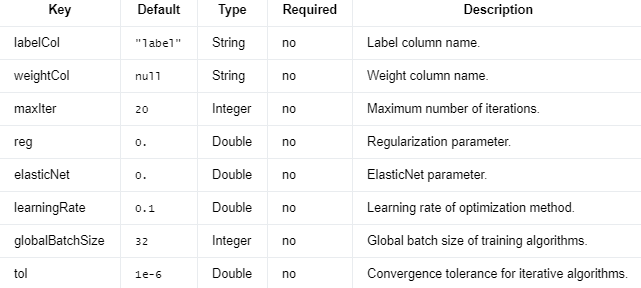
正则化参数(Regularization parameter)是用于控制模型复杂度的超参数。它的主要目的是在模型复杂度和拟合误差之间找到平衡,以降低过拟合风险。正则化是通过将一个惩罚项添加到损失函数中来实现的,这个惩罚项取决于模型参数的大小。常见的正则化方法有L1正则化(Lasso)、L2正则化(Ridge)和Elastic Net正则化。
正则化参数的具体含义和作用依赖于所使用的正则化方法。在L1和L2正则化中,正则化参数通常表示为λ(lambda)。在Elastic Net中,除了λ之外,还有一个混合参数α(alpha)用于控制L1和L2正则化的权重。
λ(lambda):正则化强度
λ是一个非负数,它控制正则化项的权重。当λ增大时,正则化效果更强,模型变得更简单,从而减少过拟合的风险。当λ较小时,正则化效果减弱,模型可能更容易过拟合。需要注意的是,过大的λ可能导致欠拟合。因此,在实际应用中,需要通过交叉验证或其他方法来选择合适的λ值。
α(alpha):混合参数
α是一个介于0和1之间的参数,仅在Elastic Net正则化中使用。α用于控制L1和L2正则化项的权重。当α = 0时,Elastic Net等价于Ridge回归;当α = 1时,Elastic Net等价于Lasso回归。通过调整α值,可以在Lasso和Ridge之间找到适当的折中方案。
总之,正则化参数是控制模型复杂度的关键因素。选择合适的正则化参数可以帮助找到模型复杂度和拟合误差之间的平衡,从而降低过拟合风险。
Elastic Net是一种用于线性回归模型的正则化方法,它结合了L1和L2正则化项。Elastic Net旨在解决特征选择问题,以及在存在多重共线性的情况下提高模型的稳定性和预测性能。
在Elastic Net中,损失函数是最小化目标函数的和,包括数据拟合误差、L1正则化项(Lasso)和L2正则化项(Ridge):
损失函数 = 数据拟合误差 + λ * [(1 - α) * L2正则化项 + α * L1正则化项]
其中,λ是正则化强度参数,它决定了正则化项的权重。当λ增大时,正则化效果更强,模型变得更简单,从而减少过拟合的风险。λ较小时,正则化效果减弱,模型可能更容易过拟合。
α是一个在0和1之间的混合参数,它决定了L1和L2正则化项的权重。当α = 0时,Elastic Net等价于Ridge回归;当α = 1时,Elastic Net等价于Lasso回归。通过调整α值,可以在Lasso和Ridge之间找到适当的折中方案。
Elastic Net的优点:
结合了Lasso和Ridge的优点,可以处理多重共线性问题,并进行特征选择。
对于具有很多特征的数据集,Elastic Net可以有效地缩减模型,使其更易于解释。
可以通过调整λ和α参数找到适当的正则化强度和正则化类型,从而实现模型优化。
Elastic Net的缺点:
计算复杂度较高,尤其在存在大量特征时。
需要调整两个超参数(λ和α),可能需要大量的计算资源和时间来找到最优参数组合。
总之,Elastic Net是一种有效的正则化方法,适用于线性回归模型。它结合了Lasso和Ridge的优点,可以处理多重共线性和特征选择问题。通过调整λ和α参数,可以找到最佳的正则化策略以提高模型性能。
在迭代算法中,收敛容差(convergence tolerance)是一个预设的阈值,用于确定算法是否已经收敛。收敛容差用于控制迭代次数,从而平衡计算精度和计算时间之间的关系。
迭代算法通常通过重复应用某种操作来逐步逼近最优解。在每次迭代过程中,模型参数会发生变化。如果模型参数在连续迭代之间的变化小于收敛容差,我们认为算法已经收敛,可以停止迭代。收敛容差越小,表示所需的收敛精度越高,但这可能需要更多的迭代次数,从而增加计算时间。相反,较大的收敛容差可以减少迭代次数,缩短计算时间,但可能导致较低的收敛精度。
例如,在梯度下降算法中,收敛容差可以用于判断梯度的大小。如果梯度的大小小于收敛容差,我们可以认为算法已经找到了一个局部最优解,可以停止迭代。
在实际应用中,选择合适的收敛容差取决于问题的特点以及对计算精度和计算时间的需求。通常,可以通过交叉验证或其他方法来选择合适的收敛容差值。需要注意的是,过小的收敛容差可能导致算法很难收敛,从而增加计算时间;而过大的收敛容差可能导致算法提前停止,从而降低模型性能。
Java
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.ml.regression.linearregression.LinearRegression;
import org.apache.flink.ml.regression.linearregression.LinearRegressionModel;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that trains a LinearRegression model and uses it for regression. */
public class LinearRegressionExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(Vectors.dense(2, 1), 4.0, 1.0),
Row.of(Vectors.dense(3, 2), 7.0, 1.0),
Row.of(Vectors.dense(4, 3), 10.0, 1.0),
Row.of(Vectors.dense(2, 4), 10.0, 1.0),
Row.of(Vectors.dense(2, 2), 6.0, 1.0),
Row.of(Vectors.dense(4, 3), 10.0, 1.0),
Row.of(Vectors.dense(1, 2), 5.0, 1.0),
Row.of(Vectors.dense(5, 3), 11.0, 1.0));
Table inputTable = tEnv.fromDataStream(inputStream).as("features", "label", "weight");
// Creates a LinearRegression object and initializes its parameters.
LinearRegression lr = new LinearRegression().setWeightCol("weight");
// Trains the LinearRegression Model.
LinearRegressionModel lrModel = lr.fit(inputTable);
// Uses the LinearRegression Model for predictions.
Table outputTable = lrModel.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector features = (DenseVector) row.getField(lr.getFeaturesCol());
double expectedResult = (Double) row.getField(lr.getLabelCol());
double predictionResult = (Double) row.getField(lr.getPredictionCol());
System.out.printf(
"Features: %s \tExpected Result: %s \tPrediction Result: %s\n",
features, expectedResult, predictionResult);
}
}
}
Python
# Simple program that trains a LinearRegression model and uses it for
# regression.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.regression.linearregression import LinearRegression
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(2, 1), 4., 1.),
(Vectors.dense(3, 2), 7., 1.),
(Vectors.dense(4, 3), 10., 1.),
(Vectors.dense(2, 4), 10., 1.),
(Vectors.dense(2, 2), 6., 1.),
(Vectors.dense(4, 3), 10., 1.),
(Vectors.dense(1, 2), 5., 1.),
(Vectors.dense(5, 3), 11., 1.),
],
type_info=Types.ROW_NAMED(
['features', 'label', 'weight'],
[DenseVectorTypeInfo(), Types.DOUBLE(), Types.DOUBLE()])
))
# create a linear regression object and initialize its parameters
linear_regression = LinearRegression().set_weight_col('weight')
# train the linear regression model
model = linear_regression.fit(input_table)
# use the linear regression model for predictions
output = model.transform(input_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
features = result[field_names.index(linear_regression.get_features_col())]
expected_result = result[field_names.index(linear_regression.get_label_col())]
prediction_result = result[field_names.index(linear_regression.get_prediction_col())]
print('Features: ' + str(features) + ' \tExpected Result: ' + str(expected_result)
+ ' \tPrediction Result: ' + str(prediction_result))
ChiSqTest是一种统计检验方法,用于检验两个变量之间的独立性或相关性。ChiSqTest基于卡方分布,可以用于分析分类变量之间的关系,例如,统计两个变量之间的关联程度或检验分类变量与响应变量之间的独立性。
在机器学习中,ChiSqTest通常用于特征选择和特征工程,以确定哪些特征对于预测任务是最重要的。具体来说,ChiSqTest可以通过比较每个特征和响应变量之间的卡方统计量来评估特征的重要性。卡方统计量越大,特征与响应变量之间的关系就越强,因此这些特征对于预测任务更加重要。
ChiSqTest的主要优点是它可以处理多类别分类变量和稀疏数据,并且计算简单、可解释性强。此外,ChiSqTest可以适应不同类型和分布的数据,通过调整参数来平衡模型的训练和评估。
然而,ChiSqTest的缺点是它假定变量之间的关系是线性的,忽略了非线性和复杂的关系,可能导致特征选择不完全和模型性能下降。在某些情况下,可以考虑使用其他特征选择方法(如互信息和Lasso回归)和机器学习方法(如深度学习和集成学习)进行更高级的特征选择和建模。
在实际应用中,ChiSqTest通常与其他数据预处理方法(如特征缩放和特征变换)和机器学习模型(如逻辑回归、决策树和神经网络)结合使用,以提高模型的性能。在选择合适的统计检验方法和库时,需要根据实际需求和数据类型进行选择。
ChiSq测试 #
卡方检验计算列联表中变量独立性的统计数据,例如每个输入特征的 p 值和 DOF(自由度)。列联表是根据观察到的分类值构建的。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #
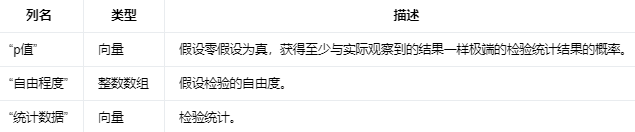
如果输出结果没有被展平,则输出列如下。
If the output result is not flattened, the output columns are as follows.
编辑切换为居中
添加图片注释,不超过 140 字(可选)
零假设假定观察到的数据是由随机因素导致的,而不是某种潜在的关联或因果关系。
在假设检验中,我们首先提出零假设(null hypothesis),通常表示不存在显著差异或效果。然后,我们计算一个检验统计量(test statistic),这是一个基于样本数据的数值,用于帮助我们评估零假设是否成立。
P值表示在零假设成立的情况下,观察到至少和实际观察到的检验统计量一样极端的结果的概率。换句话说,P值衡量了实际观察到的检验统计量与零假设之间的一致性。较低的P值意味着在零假设成立的情况下,观察到如此极端的检验统计量是非常罕见的,这可能表明零假设是不成立的。相反,较高的P值意味着在零假设成立的情况下,观察到如此极端的检验统计量是相对常见的,这可能表明零假设是成立的。
为了确定是否拒绝零假设,我们通常将P值与预先设定的显著性水平(significance level,通常表示为α)进行比较。如果P值小于α(例如,α = 0.05),我们拒绝零假设,认为存在显著差异或效果。如果P值大于或等于α,我们无法拒绝零假设,认为不存在显著差异或效果。
总之,P值是一个衡量观察到的检验统计量与零假设之间一致性的概率。它帮助我们在假设检验中确定是否拒绝零假设。
“自由度”(degree of freedom),它是假设检验中的一个重要概念。自由度表示在进行统计分析时,独立变化的数据点的数量。简而言之,自由度是指用于估计参数或测试假设的独立信息的数量。
在假设检验中,自由度通常与检验统计量的分布有关。例如,当使用t检验、χ²检验(卡方检验)或F检验等方法进行假设检验时,自由度是计算检验统计量的分布所需的一个关键参数。
以下是一些自由度的例子:
在单样本t检验中,自由度为 n - 1,其中n表示样本大小。因为我们需要估计总体均值和标准差,所以有一个数据点被“消耗”了,剩下n - 1个数据点是独立的。
在独立双样本t检验中,自由度为 n1 + n2 - 2,其中n1和n2分别为两个样本的大小。每个样本都需要估计一个均值,所以总共消耗了2个数据点,剩下n1 + n2 - 2个数据点是独立的。
在χ²检验中,自由度通常为 (行数 - 1) × (列数 - 1)。因为行和列的总和分别受到约束,所以需要减去1。
自由度是指在进行统计分析时,能够自由变化的数据点的数量。想象一下,你在一间房子里有一些可移动的家具。房间的墙壁和门限制了你可以放置家具的方式。自由度就像是你能够自由摆放家具的空间。在统计学中,自由度类似于你拥有的独立信息量。
如果输出结果被拉平,则输出列如下。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
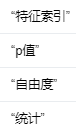
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
如果布尔值为false,那么返回的表格只包含一行(single row)数据。
如果布尔值为true,那么返回的表格将包含多行数据,每个特征(feature)对应一行。
Java
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.ml.stats.chisqtest.ChiSqTest;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that creates a ChiSqTest instance and uses it for statistics. */
public class ChiSqTestExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
Table inputTable =
tEnv.fromDataStream(
env.fromElements(
Row.of(0., Vectors.dense(5, 1.)),
Row.of(2., Vectors.dense(6, 2.)),
Row.of(1., Vectors.dense(7, 2.)),
Row.of(1., Vectors.dense(5, 4.)),
Row.of(0., Vectors.dense(5, 1.)),
Row.of(2., Vectors.dense(6, 2.)),
Row.of(1., Vectors.dense(7, 2.)),
Row.of(1., Vectors.dense(5, 4.)),
Row.of(2., Vectors.dense(5, 1.)),
Row.of(0., Vectors.dense(5, 2.)),
Row.of(0., Vectors.dense(5, 2.)),
Row.of(1., Vectors.dense(9, 4.)),
Row.of(1., Vectors.dense(9, 3.))))
.as("label", "features");
// Creates a ChiSqTest object and initializes its parameters.
ChiSqTest chiSqTest =
new ChiSqTest().setFlatten(true).setFeaturesCol("features").setLabelCol("label");
// Uses the ChiSqTest object for statistics.
Table outputTable = chiSqTest.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
System.out.printf(
"Feature Index: %s\tP Value: %s\tDegree of Freedom: %s\tStatistics: %s\n",
row.getField("featureIndex"),
row.getField("pValue"),
row.getField("degreeOfFreedom"),
row.getField("statistic"));
}
}
}
Python
# Simple program that creates a ChiSqTest instance and uses it for statistics.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.stats.chisqtest import ChiSqTest
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_table = t_env.from_data_stream(
env.from_collection([
(0., Vectors.dense(5, 1.)),
(2., Vectors.dense(6, 2.)),
(1., Vectors.dense(7, 2.)),
(1., Vectors.dense(5, 4.)),
(0., Vectors.dense(5, 1.)),
(2., Vectors.dense(6, 2.)),
(1., Vectors.dense(7, 2.)),
(1., Vectors.dense(5, 4.)),
(2., Vectors.dense(5, 1.)),
(0., Vectors.dense(5, 2.)),
(0., Vectors.dense(5, 2.)),
(1., Vectors.dense(9, 4.)),
(1., Vectors.dense(9, 3.))
],
type_info=Types.ROW_NAMED(
['label', 'features'],
[Types.DOUBLE(), DenseVectorTypeInfo()]))
)
# create a ChiSqTest object and initialize its parameters
chi_sq_test = ChiSqTest().set_flatten(True)
# use the ChiSqTest object for statistics
output = chi_sq_test.transform(input_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
print("Feature Index: %s\tP Value: %s\tDegree of Freedom: %s\tStatistics: %s" %
(result[field_names.index('featureIndex')], result[field_names.index('pValue')],
result[field_names.index('degreeOfFreedom')], result[field_names.index('statistic')]))
功能 #
Flink ML 为用户提供了一些用于数据转换的内置表函数。
向量到数组 #
该函数将一列 Flink ML 稀疏/密集向量转换为一列双精度数组。
Java
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.ml.linalg.typeinfo.VectorTypeInfo;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
import java.util.List;
import static org.apache.flink.ml.Functions.vectorToArray;
import static org.apache.flink.table.api.Expressions.$;
/** Simple program that converts a column of dense/sparse vectors into a column of double arrays. */
public class VectorToArrayExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input vector data.
List<Vector> vectors =
Arrays.asList(
Vectors.dense(0.0, 0.0),
Vectors.sparse(2, new int[] {1}, new double[] {1.0}));
Table inputTable =
tEnv.fromDataStream(env.fromCollection(vectors, VectorTypeInfo.INSTANCE))
.as("vector");
// Converts each vector to a double array.
Table outputTable = inputTable.select($("vector"), vectorToArray($("vector")).as("array"));
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Vector vector = row.getFieldAs("vector");
Double[] doubleArray = row.getFieldAs("array");
System.out.printf(
"Input vector: %s\tOutput double array: %s\n",
vector, Arrays.toString(doubleArray));
}
}
}
Python
# Simple program that converts a column of dense/sparse vectors into a column of double arrays.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
from pyflink.ml.linalg import Vectors, VectorTypeInfo
from pyflink.ml.functions import vector_to_array
from pyflink.table.expressions import col
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input vector data
vectors = [
(Vectors.dense(0.0, 0.0),),
(Vectors.sparse(2, [1], [1.0]),),
]
input_table = t_env.from_data_stream(
env.from_collection(
vectors,
type_info=Types.ROW_NAMED(
['vector'],
[VectorTypeInfo()])
))
# convert each vector to a double array
output_table = input_table.select(vector_to_array(col('vector')).alias('array'))
# extract and display the results
output_values = [x for x in
t_env.to_data_stream(output_table).map(lambda r: r).execute_and_collect()]
output_values.sort(key=lambda x: x[0])
field_names = output_table.get_schema().get_field_names()
for i in range(len(output_values)):
vector = vectors[i][0]
double_array = output_values[i][field_names.index("array")]
print("Input vector: %s \t output double array: %s" % (vector, double_array))
数组到向量 #
此函数将一列数值类型数组转换为一列 DenseVector 实例。
Java
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
import java.util.List;
import static org.apache.flink.ml.Functions.arrayToVector;
import static org.apache.flink.table.api.Expressions.$;
/** Simple program that converts a column of double arrays into a column of dense vectors. */
public class ArrayToVectorExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input double array data.
List<double[]> doubleArrays =
Arrays.asList(new double[] {0.0, 0.0}, new double[] {0.0, 1.0});
Table inputTable = tEnv.fromDataStream(env.fromCollection(doubleArrays)).as("array");
// Converts each double array to a dense vector.
Table outputTable = inputTable.select($("array"), arrayToVector($("array")).as("vector"));
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Double[] doubleArray = row.getFieldAs("array");
Vector vector = row.getFieldAs("vector");
System.out.printf(
"Input double array: %s\tOutput vector: %s\n",
Arrays.toString(doubleArray), vector);
}
}
}
Python
# Simple program that converts a column of double arrays into a column of dense vectors.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.functions import array_to_vector
from pyflink.table import StreamTableEnvironment
from pyflink.table.expressions import col
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input double array data
double_arrays = [
([0.0, 0.0],),
([0.0, 1.0],),
]
input_table = t_env.from_data_stream(
env.from_collection(
double_arrays,
type_info=Types.ROW_NAMED(
['array'],
[Types.PRIMITIVE_ARRAY(Types.DOUBLE())])
))
# convert each double array to a dense vector
output_table = input_table.select(array_to_vector(col('array')).alias('vector'))
# extract and display the results
field_names = output_table.get_schema().get_field_names()
output_values = [x[field_names.index('vector')] for x in
t_env.to_data_stream(output_table).execute_and_collect()]
output_values.sort(key=lambda x: x.get(1))
for i in range(len(output_values)):
double_array = double_arrays[i][0]
vector = output_values[i]
print("Input double array: %s \t output vector: %s" % (double_array, vector))
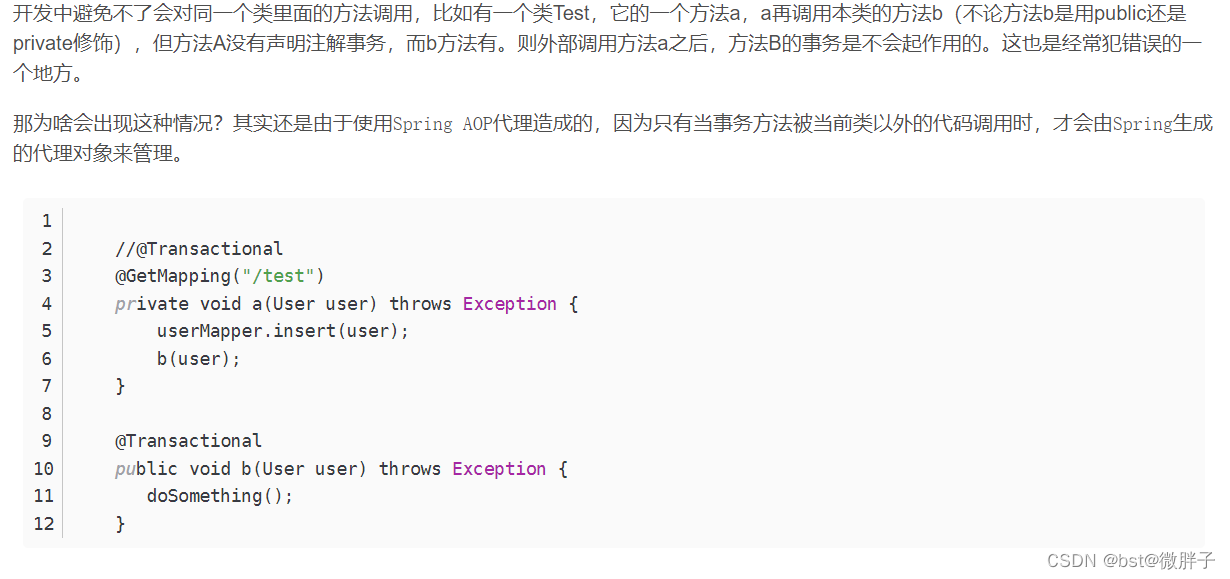
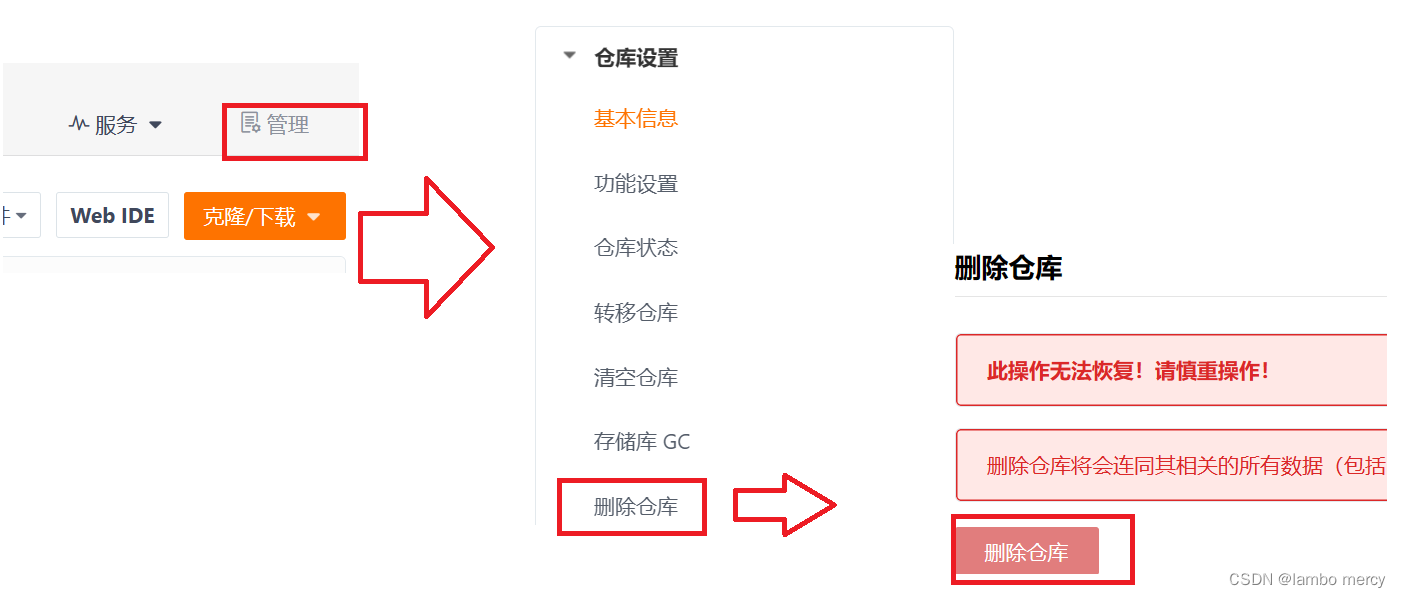
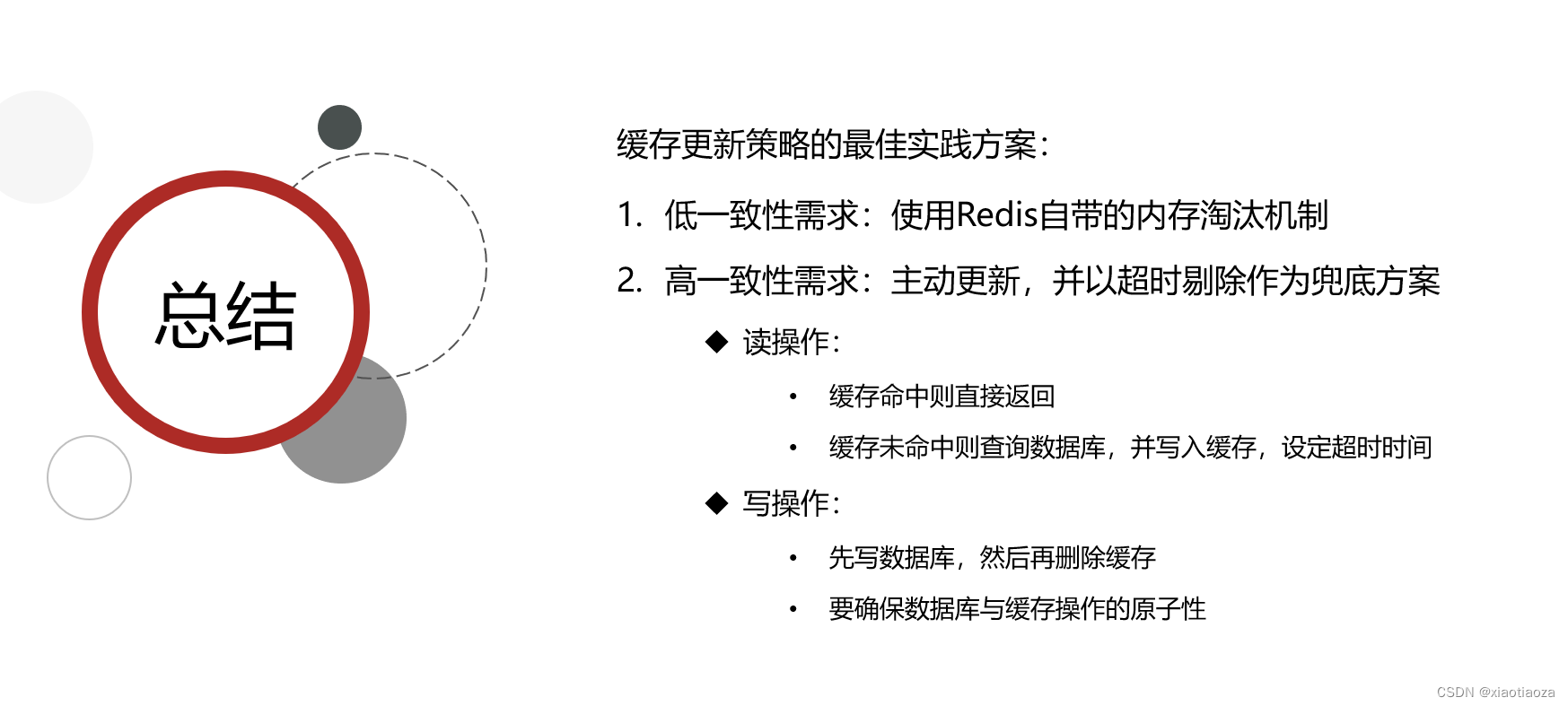


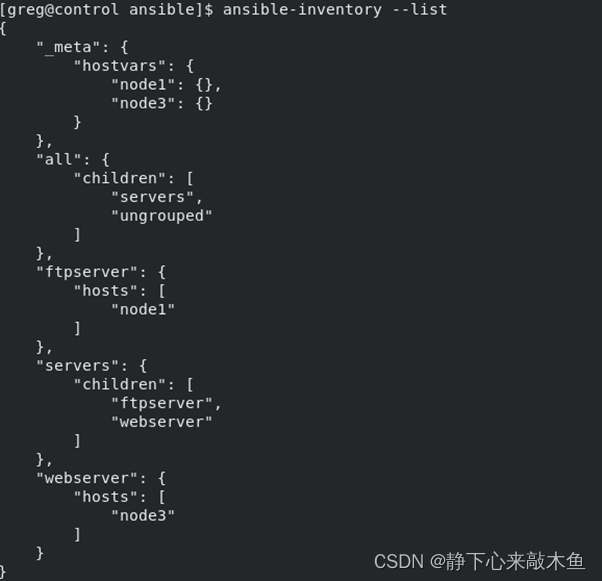

![[Netty] Mpsc Queue (十七)](https://img-blog.csdnimg.cn/1c6a4e36701e4fd6a6094eaff89a3fbf.png)